1、GGUF格式中的量化类型详解
在各种大模型的具体信息中,可以看到不同的参数的Type是Q4_0、FP32和Q6_K是GGUF(GPT-Generated Unified Format)文件中的量化类型标识,这反映了llama.cpp采用的分层混合量化策略。
1.1 量化类型定义
| 类型 | 全称 | 位宽 | 特点 | 典型压缩率 |
|---|---|---|---|---|
| Q4_0 | 4位量化(块大小32) | 4位 | 最简单的4位量化,32元素共享一个缩放因子 | 约75%压缩 |
| FP32 | 32位浮点数 | 32位 | 全精度,无量化 | 无压缩 |
| Q6_K | 6位量化(K-quants) | 6位 | 更精细的分组量化,精度更高 | 约62.5%压缩 |
1.2 技术细节解析
1.2.1 Q4_0(4位量化):
-
使用对称均匀量化,无零点偏移(zero point)
-
块大小32:每32个权重共享一个缩放因子(scale)
-
量化公式:
Q = round(weight / scale) -
存储每个权重仅需0.5字节(4位)+ 共享的缩放因子
1.2.2 Q6_K(6位K-quants):
-
llama.cpp中较新的量化方法
-
使用更小的块大小(通常为16或8),允许更精细的缩放因子调整
-
支持不同数值分布的分组,为不同分布的数据使用不同的量化参数
-
在精度和压缩率间取得更好平衡
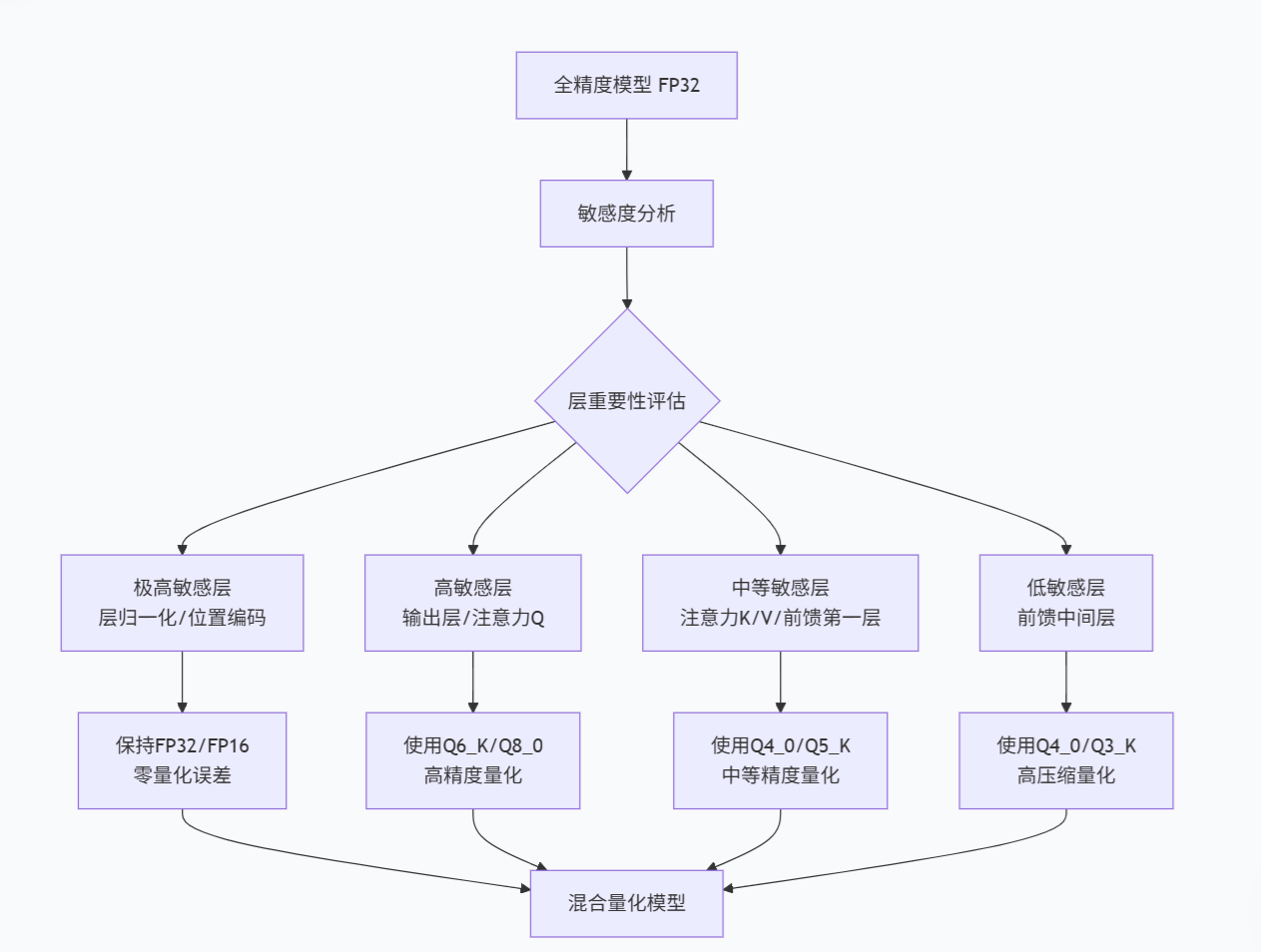
2、为什么Type会不一样?------混合量化的设计哲学
这是刻意设计的混合精度策略,而非错误。其背后的逻辑基于三个核心原则:
2.1. 敏感度分层原则
不同层对量化的敏感度差异巨大:
| 层类型 | 量化敏感度 | 原因 | 典型策略 |
|---|---|---|---|
| 注意力K/V权重 | 中等 | 主要影响信息检索,中等敏感 | Q4_0或Q8_0 |
| 层归一化参数 | 极高 | 影响激活值分布,微小变化会放大 | FP32或FP16 |
| 输出层权重 | 高 | 直接影响预测质量 | Q6_K或Q8_0 |
| 前馈网络中间层 | 低 | 非线性变换,冗余度较高 | Q4_0或更低 |
2.2. 误差传播分析
python
# 概念性说明:量化误差如何在网络中传播
def forward_pass_with_quantization_error():
# 输入传播到注意力层(Q4_0量化:中等误差)
attention_output = quantized_attention(input, error_medium)
# 经过层归一化(FP32:无额外误差)
normalized = layer_norm_fp32(attention_output)
# 误差被归一化层放大或缩小
# 如果归一化层本身有误差,会指数级放大后续误差
# 因此保持FP32至关重要
# 输出层(Q6_K量化:较小误差)
final_output = quantized_output_layer(normalized, error_small)
return final_output2.3. 性能-精度权衡优化
3、Llama3的量化策略
以最后一个block为例:
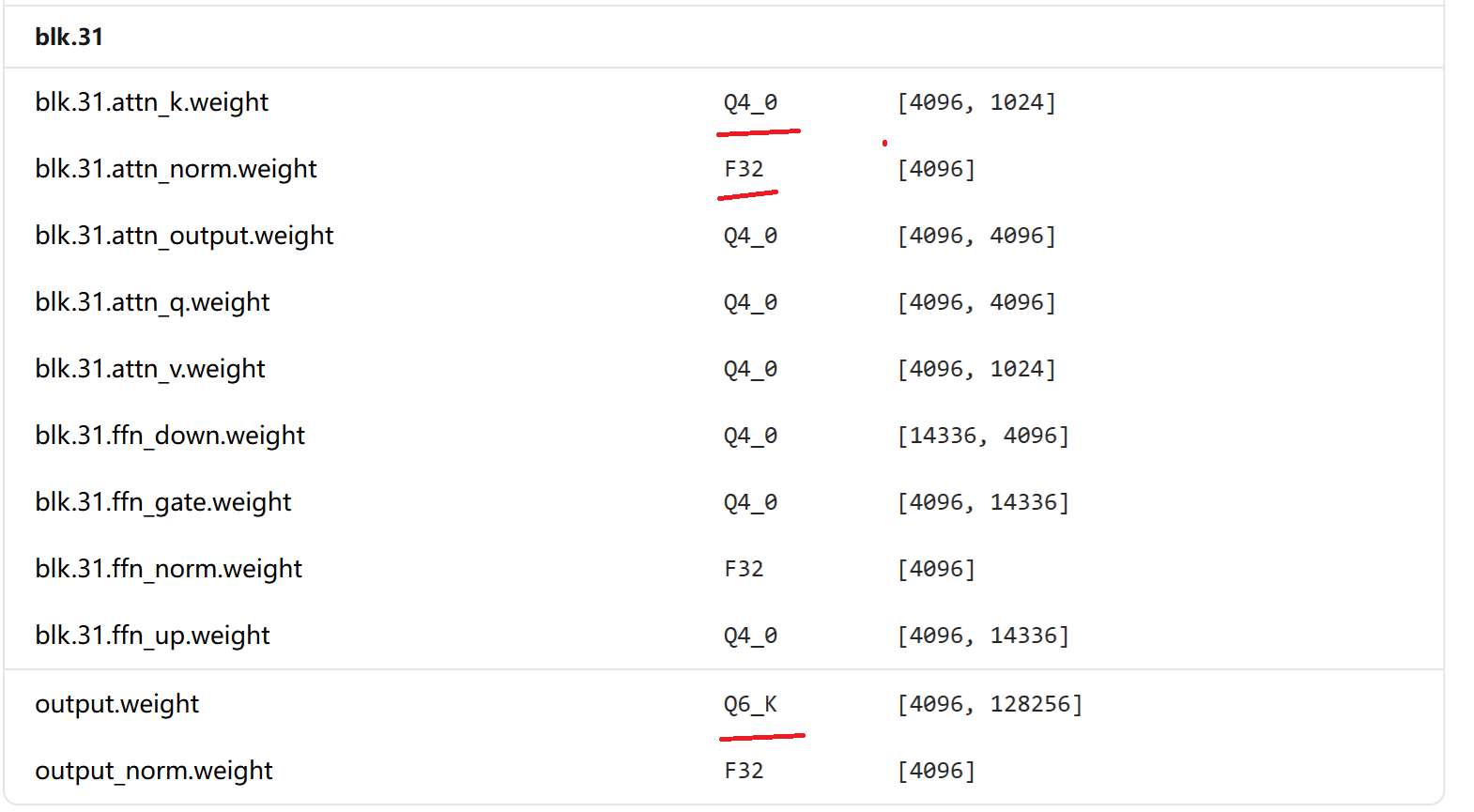
3.1 blk.31.attn_k.weight = Q4_0
-
原因:注意力机制中的Key权重相对Value和Query更不敏感
-
技术考虑:Key矩阵主要用于计算注意力分数,对绝对精度要求稍低
-
实际影响:4位量化能显著减少内存带宽需求,加速矩阵乘法
3.2 blk.31.attn_norm.weight = FP32
-
原因:LayerNorm的缩放参数(γ)和偏移参数(β)极其敏感
-
数学原因:
# LayerNorm公式 y = (x - mean(x)) / sqrt(var(x) + ε) * γ + β # γ和β的微小变化会被输入方差放大 # 假设输入方差为σ²,则输出变化:Δy ≈ Δγ * σ # 因此必须保持高精度 -
实践经验:即使将γ/β量化为16位浮点,也可能导致模型崩溃
3.2 output.weight = Q6_K
-
原因:输出层直接决定词元预测概率分布
-
关键性:输出层误差直接影响困惑度(PPL)和生成质量
-
Q6_K的优势:
-
相比Q4_0:显著更高的精度(≈2-5% PPL改善)
-
相比FP16:约2.7倍压缩,仍保持较好精度
-
-
典型应用场景:在模型尺寸和生成质量间寻求最佳平衡。
4、GGUF量化类型全览
以下是llama.cpp支持的常见量化类型及其适用场景:
| 类型 | 位宽 | 块大小 | 适用场景 | 精度排序 |
|---|---|---|---|---|
| Q2_K | 2位 | 16 | 极度压缩,探索性研究 | 最低 |
| Q3_K | 3位 | 32 | 高压缩,质量尚可 | 低 |
| Q4_0 | 4位 | 32 | 平衡选择,广泛使用 | 中下 |
| Q4_K | 4位 | 16/32 | Q4_0改进版,精度更高 | 中等 |
| Q5_0 | 5位 | 32 | 平衡精度与压缩 | 中上 |
| Q5_K | 5位 | 32 | Q5_0改进版 | 高 |
| Q6_K | 6位 | 16/32 | 高质量推理 | 很高 |
| Q8_0 | 8位 | 32 | 近乎无损 | 接近FP16 |
5、如何选择量化策略?
5.1. 实用指南
python
# 伪代码:自动选择量化策略的函数
def select_quantization_strategy(use_case, hardware_constraints):
if use_case == "research_experiment":
return {"most_layers": "Q4_0",
"output_layer": "Q6_K",
"norm_layers": "FP16"}
elif use_case == "mobile_deployment":
return {"most_layers": "Q4_K_M",
"critical_layers": "Q5_K_M",
"norm_layers": "FP16"}
elif use_case == "server_inference":
return {"most_layers": "Q5_K_M",
"attention_layers": "Q6_K",
"norm_layers": "FP32"}
elif use_case == "maximum_quality":
return {"most_layers": "Q8_0",
"norm_layers": "FP32"}5.2. 实际推荐配置
XML
# 针对Llama 3的推荐混合量化配置
quantization_profile:
model: "Llama-3-8B"
use_case: "平衡的质量与速度"
layer_specific_quantization:
# 注意力机制
attention_query: "Q5_K" # Q对精度要求较高
attention_key: "Q4_0" # K可以更激进压缩
attention_value: "Q4_0" # V与K类似
attention_output: "Q5_K" # 输出投影较重要
# 前馈网络
feed_forward_gate: "Q4_0" # SwiGLU的门控权重
feed_forward_up: "Q4_0" # 上投影
feed_forward_down: "Q4_0" # 下投影
# 特殊层(必须高精度)
layer_norm_gamma_beta: "FP32" # 绝对保持FP32
embedding: "Q6_K" # 输入输出嵌入
lm_head: "Q6_K" # 语言模型头
# 其他
rotary_emb: "FP32" # 旋转位置编码5.3. 查看和修改量化配置
使用llama.cpp工具
bash
# 查看模型的详细量化信息
./llama-cli -m llama-3-8b.Q6_K.gguf --verbose
# 重新量化特定层(高级使用)
./llama-quantize \
llama-3-8b.f16.gguf \
llama-3-8b.custom.gguf \
--quantize-output "Q4_0" \
--keep-norm "FP32" \
--keep-output "Q6_K"Python查看示例
python
import gguf
import numpy as np
# 读取GGUF文件
reader = gguf.GGUFReader("llama-3-8b.Q6_K.gguf")
# 遍历所有张量及其量化类型
for tensor in reader.tensors:
print(f"名称: {tensor.name}")
print(f" 形状: {tensor.shape}")
print(f" 类型: {tensor.tensor_type.name}")
print(f" 量化类型: {getattr(tensor, 'quantization', 'NONE')}")
# 如果是量化张量,查看量化参数
if hasattr(tensor, 'quantization'):
print(f" 块大小: {getattr(tensor, 'block_size', 'N/A')}")
print(f" 位宽: {getattr(tensor, 'bits', 'N/A')}")6、结论与最佳实践
模型的不同参数的量化策略的不一致是精心设计的优化结果,不是随机或错误分配。这种混合量化策略:
-
最大化压缩效率:对不敏感层使用激进量化(Q4_0)
-
保护模型核心能力:对关键层使用高精度(FP32、Q6_K)
-
实现最优精度-速度权衡:相比全模型统一量化,PPL通常降低10-30%
实践建议:
-
不要手动统一量化类型:这会破坏精心调优的平衡
-
选择预量化模型时 :优先选择
Q6_K、Q5_K_M等平衡选项 -
自行量化时 :使用
--quantize-output等高级参数保护关键层
这种分层量化思想已成为大模型部署的标准实践,反映了深度学习从"一刀切"优化到"精细化手术"的进化。