java基础
1、泛型
泛型(Generics)是一种参数化类型的概念,允许你在定义类、接口和方法时使用一个或多个类型参数。
通过泛型,可以编写出更加通用和类型安全的代码,减少代码重复并提高代码的可读性和健壮性。
泛型的优势:
- 提高代码的重用性:可以编写更通用的类、接口和方法。
- 类型安全:编译器可以在编译时发现类型错误。
- 减少强制类型转换:避免在代码中频繁进行类型转换操作。
通过使用泛型,可以使代码更加灵活、通用,并且提高代码的可维护性和可读性。
多线程
1.多线程有什么用?
1)发挥多核CPU 的优势
随着工业的进步,现在的笔记本、台式机乃至商用的应用服务器至少也都是双核的,4 核、8 核甚至 16 核的也都不少见,如果是单线程的程序,那么在双核 CPU 上 就浪费了 50%, 在 4 核 CPU 上就浪费了 75%。单核 CPU 上所谓的"多线程"那是假的多线程,同一时间处理器只会处理一段逻辑,只不过线程之间切换得比较快, 看着像多个线程"同时"运行罢了。多核 CPU 上的多线程才是真正的多线程,它能让你的多段逻辑同时工作,多线程,可以真正发挥出多核CPU 的优势来,达到充分利用CPU 的目的。
2)防止阻塞
从程序运行效率的角度来看,单核 CPU 不但不会发挥出多线程的优势,反而会因为在单核CPU 上运行多线程导致线程上下文的切换,而降低程序整体的效率。但
是单核 CPU 我们还是要应用多线程,就是为了防止阻塞。试想,如果单核 CPU 使用单线程,那么只要这个线程阻塞了,比方说远程读取某个数据吧,对端迟迟未返回又没有设置超时时间,那么你的整个程序在数据返回回来之前就停止运行了。多线程可以防止这个问题,多条线程同时运行,哪怕一条线程的代码执行读取数据阻塞,也不会影响其它任务的执行。
3)便于建模
这是另外一个没有这么明显的优点了。假设有一个大的任务 A,单线程编程,那么就要考虑很多,建立整个程序模型比较麻烦。但是如果把这个大的任务 A 分解成几个小任务,任务B、任务 C、任务 D,分别建立程序模型,并通过多线程分别运行这几个任务,那就简单很多了。
2.线程和进程的区别是什么?
-
进程(Process):
- 进程是正在执行的程序实例,它具有独立的内存空间和系统资源。一个进程可以包含多个线程。
- 操作系统通过创建、调度和管理进程来实现多任务处理。
- 进程之间相互独立,拥有各自的地址空间和资源,通信需要使用特定的机制(如进程间通信,IPC)。
- 进程之间的切换开销较大,因为需要切换地址空间和上下文环境。
- 例如,每个打开的应用程序(如浏览器、文本编辑器)都是一个独立的进程。
-
线程(Thread):
- 线程是进程内的执行单元,可以看作是进程中的一个独立控制流。
- 线程共享其所属进程的地址空间和资源,因此线程之间的通信和数据共享更加方便和高效。
- 线程是操作系统调度的基本单位,操作系统通过线程调度算法来分配 CPU 时间片给不同的线程。
- 同一进程内的多个线程共享进程的上下文环境,切换开销相对较小。
- 例如,浏览器中的每个标签页可以是一个独立的线程,用于并行加载和渲染网页。
总结(记忆点):
进程 表示程序的执行实例 ,具有独立的资源 ,而线程 是进程内部的执行单元 ,共享进程的资源。
进程之间通信相对复杂,线程之间通信和数据共享相对简单高效。
进程切换开销较大,线程切换开销较小。
3、volatile和synchronized的区别?
①volatile只能修饰实例变量和类变量,而synchronized可以修饰方法以及代码块。
②volatile只能保证数据的可见性 ,但是不保证原子性,synchronized是一种排它机制,可以保证原子性。i++操作
③volatile是一种轻量级的同步机制 ,在访问volatile修饰的变量时并不会执行加锁操作,线程不会阻塞,使用synchronized加锁会阻塞线程。
4、synchronized和ReentrantLock有哪些区别?
①synchronized是隐式锁,ReentrantLock是显式锁,使用时必须在finally代码块中进行释放锁的操作。
②synchronized是一个关键字,是JVM级别,ReentrantLock是一个接口,是API级别。
③synchronized采用悲观并发策略,ReentrantLock采用的是乐观并发策略,会先尝试以CAS方式获取锁。
④synchronized是非公平锁,ReentrantLock可以实现公平锁。
⑤ReentrantLock可响应中断,可轮回,为处理锁提高了更多灵活性。
5、讲一讲乐观锁和悲观锁
①乐观锁采用乐观的思想处理数据,在每次读取数据时都认为别人不会修改该数据,所以不会上锁。但在更新时会判断在此期间别人有没有更新该数据,通常采用在写时先读出当前版本号然后加锁的方法,具体过程为:比较当前版本号与上一次的版本号,如果一致则更新,否则重复进行读、比较、写操作。Java中的乐观锁是基于CAS操作实现的,CAS是一种原子性操作,在对数据更新之前先比较当前值和传入的值是否一样,一样则更新否则直接返回失败状态。
②悲观锁采用悲观的思想处理数据,每次读取数据时都认为别人会修改数据,所以每次都会上锁,其他线程将被阻塞。Java中的悲观锁基于AQS实现,该框架下的锁会先尝试以CAS乐观锁去获取锁,如果获取不到则会转为悲观锁。
6、创建线程池时,ThreadPoolExecutor构造器中都有哪些参数,有什么含义?
①**corePoolSize**: 线程池核心大小,即在没有任务执行时线程池的大小,并且只有在工作队列满了的情况下才会创建超出这个数量的线程。
②maximumPoolSize: 线程池最大大小,表示可同时活动的线程数量的上限。
③**keepAliveTime**:存活时间,如果某个线程的空闲时间超过了存活时间,那么将被标记为可回收的,并且当线程池的当前大小超过基本大小时,这个线程将被终止。
④**unit**: 存活时间的单位,可选的参数为TimeUnit枚举中的几个静态变量: NANOSECONDS、MICROSECONDS、MILLISECONDS、SECONDS。
⑤**workQueue**: 线程池所使用的阻塞队列。
⑥**thread factory**:线程池使用的创建线程工厂方法,可省略,将使用默认工厂。
⑦**handler:所用的拒绝执行处理策略,可省略,将使用默认拒绝执行**策略。
7、有哪些阻塞队列?
-
LinkedBlockingQueue:
- 使用链表实现的无界阻塞队列。
- 当任务提交速度远远大于任务执行速度时,可能会导致内存溢出。
- 适用于任务生产速度和消费速度相对平衡的场景。
-
ArrayBlockingQueue:
- 使用数组实现的有界阻塞队列。
- 在初始化时需要指定队列的容量。
- 可以防止任务过多导致内存溢出,但可能会导致提交任务被阻塞。
- 适用于需要限制任务数量的场景。
-
SynchronousQueue:
- 不存储元素的阻塞队列,每个插入操作必须等待一个对应的移除操作,反之亦然。
- 适用于需要严格控制任务提交和执行的场景,通常用于实现直接提交的线程池。
-
PriorityBlockingQueue:
- 优先级队列实现的无界阻塞队列。
- 任务会按照优先级顺序被执行。
- 适用于需要根据任务优先级来决定执行顺序的场景。
-
DelayQueue:
- 延迟队列,用于存储实现了
Delayed接口的元素。 - 元素只有在其指定的延迟时间到达后才能被取出。
- 适用于需要延迟执行任务的场景,比如定时任务调度。
- 延迟队列,用于存储实现了
8、线程池的拒绝执行策略有哪些选择?
-
AbortPolicy /ˈpɑːləsi/ **(默认策略)**拒绝执行策略:
- 当任务无法被接受时,会抛出
RejectedExecutionException异常。 - 这是默认的拒绝执行策略,它会立即抛出异常,不会执行任务。
- 当任务无法被接受时,会抛出
-
CallerRunsPolicy:/ˈkɔːlər/ 呼叫,访客
- 当任务无法被接受时,会在提交任务的线程中直接执行该任务。
- 这种策略可以保证任务不会丢失,但可能会导致提交任务的线程被阻塞。
-
DiscardPolicy:
- 当任务无法被接受时,会默默地丢弃该任务,不会进行任何处理。
- 这种策略会导致部分任务被丢弃,不会执行。
-
DiscardOldestPolicy:
- 当任务无法被接受时,会丢弃队列中最老的一个任务,并尝试重新提交当前任务。
- 这种策略会优先保留新提交的任务,丢弃队列中等待时间最长的任务。
JavaEE
spring
1、Spring的IOC和DI是什么?
①IOC即控制反转,简单来说就是把对象的控制权委托给spring框架 ,作用是降低代码的耦合度
②DI即依赖注入,是IOC的一种具体实现方式。假设一个Car类需要Engine的对象,那么一般需要new一个Engine,利用IOC就是只需要定义一个私有的Engine引用变量,容器会在运行时创建 一个Engine的实例对象 并将引用自动注入给变量。
2、简述Spring中bean对象的生命周期
- (构造)实例化
- 属性赋值
- 完成初始化
- 使用
- 销毁
**①实例化(Instantiation):**通过构造函数或其他方法实例化been对象
②属性赋值(Population): 开始依赖注入 ,解析所有需要赋值的属性并赋值。
如果Bean类实现BeanNameAware接口,则将通过传递Bean的名称 来调用setBeanName()方法。 如果Bean类实现BeanFactoryAware接口,则将通过传递BeanFactory对象的实例来调用setBeanFactory()方法。
③初始化(Initialization) :在 Bean 的属性设置完成后,Spring 容器会调用初始化回调方法进行一些额外的初始化工作
④使用(In Use): 此时 Bean 已经被完全初始化,可以被应用程序使用。在此阶段,Bean 提供了所有的服务 和功能。
**⑤销毁(Destruction):**当应用程序关闭时,Spring 容器会调用 Bean 的销毁回调方法,进行一些清理工作。
- 如果 Bean 实现了 DisposableBean 接口,Spring 将调用其 destroy() 方法。
- 如果 Bean 配置了 destroy-method,则会调用指定的销毁方法。
Spring 容器负责管理 Bean 的生命周期,包括实例化、属性赋值、初始化、使用和销毁等阶段。通过生命周期回调方法,可以在 Bean 的不同生命周期阶段执行一些自定义的操作,例如资源的初始化和释放、日志记录等。
3、依赖注入可以注入哪些数据类型?有哪些注入方式?
①可以注入的数据类型有基本数据类型、String、Bean、以及集合等复杂数据类型。
②有三种注入方式,第一种是通过构造器 注入,通过constructor-arg标签实现,缺点是即使不需要该属性也必须注入;
第二种是通过Set方法 注入,通过property标签实现,优点是创建对象时没有明确限制,缺点是某个成员变量必须有值,在获取对象时set方法可能还没有执行;
第三种是通过注解 注入,利用@Autowired自动按类型 注入,如果有多个匹配则按照指定bean的id查找,查找不到会报错;@Qualifier在自动按照类型注入的基础之上,再按照 Bean 的 id 注入,给成员变量注入时必须搭配@Autowired,给方法注入时可单独使用;@Resource直接按照 Bean 的 id 注入;@Value用于注入基本数据类型和String。
3、spring事务的传播机制
Spring的事务传播机制(通俗易懂)_spring事务传播机制-CSDN博客
Spring的事务传播机制有7种,在枚举Propagation中有定义。
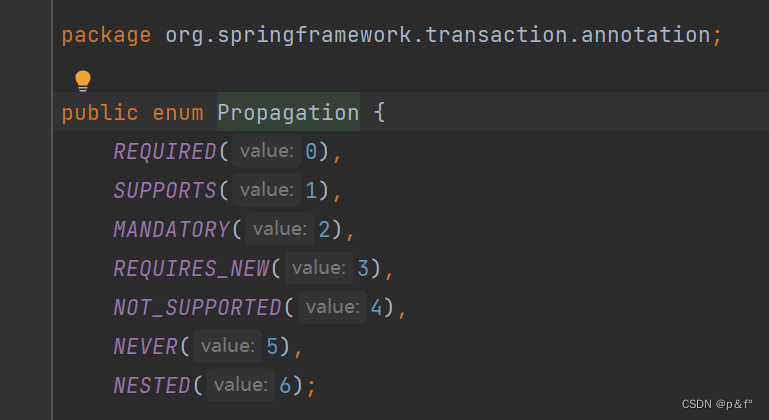
①required(必需的):如果当前没有事务,就创建一个新事务,如果当前存在事务,就加入该事务,该设置是最常用的默认设置。
②supports(支持):支持当前事务,如果当前存在事务,就加入该事务,如果当前不存在事务,就以非事务执行。
③mandatory(/ˈmændətɔːri/ 强制性的):支持当前事务,如果当前存在事务,就加入该事务,如果当前不存在事务,就抛出异常。
④requires_new(需要_新的):创建新事务,无论当前存不存在事务,都创建新事务。
⑤not_supported(不支持):以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。
⑥never(从不):以非事务方式执行操作,如果当前存在事务,则抛出异常。
⑦nested(/ˈnestɪd/内嵌的):如果当前存在事务,则在嵌套事务内执行。如果当前没有事务,则按REQUIRED属性执行。
嵌套事务,外层的事务如果回滚,会导致内层的事务也回滚;但是内层的事务如果回滚,仅仅是回滚自己的代码,不影响外层的事务的代码。
MyBatis
1、讲一讲mybatis的一级和二级缓存机制
MyBatis 是一个持久层框架,提供了一级和二级缓存来提高数据库访问的性能。
一级缓存(Local Cache)
一级缓存是指在同一个 SqlSession 中,MyBatis 默认开启的缓存机制。在同一个 SqlSession 中,如果执行了相同的查询语句,MyBatis 会将查询结果缓存起来,以便后续的查询可以直接从缓存中获取结果,而不用再次向数据库发起查询请求。一级缓存是线程级别的缓存,只在当前 SqlSession 内有效。
二级缓存(Global Cache)
二级缓存是指在多个 SqlSession 之间共享的缓存机制 。默认情况下,二级缓存是关闭的,需要在配置文件中手动开启。开启二级缓存后,MyBatis 会将查询结果缓存到二级缓存中,当有其他 SqlSession 执行相同的查询时 ,可以直接从二级缓存中获取结果,而不用再次向数据库发起查询请求。二级缓存是跨 SqlSession 的,因此可以实现多个 SqlSession 之间的数据共享。
需要注意的是,二级缓存是全局共享的,因此在并发环境下需要考虑缓存的一致性和并发控制。在一些情况下,可能需要手动清除或刷新二级缓存,以确保缓存中的数据与数据库中的数据保持一致。
2、如何防止sql注入
MyBatis 通过预编译 SQL 语句 和参数化查询 来防止 SQL 注入攻击。这是因为 MyBatis 在执行 SQL 语句时,会将 SQL 语句和参数分开处理 ,确保参数值不会被解释为 SQL 语句的一部分,从而有效地防止了 SQL 注入攻击。
#{}:参数化查询
- 使用
#{}时,MyBatis 会将参数值 替换为占位符(?),并通过 PreparedStatement 进行预编译,将参数值传递给 SQL 语句,这样可以防止 SQL 注入攻击,提高了安全性。
${}:字符串替换
- 使用
${}时,MyBatis 会直接将参数值嵌入到 SQL 语句中,不会进行预编译,因此存在 SQL 注入攻击的风险。
MySQL
1、事务的四大特性(ACID)
事务是指:由一个或多个数据库操作组成的逻辑工作单元
①Atomicity表示原子性。事务中的所有操作都是不可分割的原子单位,要么全部成功,要么全部失败。
②Consistency表示一致性。无论正常执行还是异常退出,事务执行前后数据的完整性必须保持一致,比如转账前后双方的总金额是不变的。
③Isolation表示隔离性,并发操作中不同事务是互相隔离的,之间不会互相影响。
④Durability表示持久性,事务提交完成后数据就会被持久化修改到永久存储中。
2、读取数据库时可能出现哪些问题?
①脏读:一个事务中会读取到另一个事务中还没有提交的数据,如果另一事务最终回滚了数据,那么所读取到的数据就是无效的。
②不可重复读,一个事务中可以读取到另一个事务中已经提交的数据,在同一次事务中对同一数据读取的结果可能不同。
③幻读,一个事务在读取数据时,当另一个事务在表中插入了一些新数据时再次读取表时会多出几行,如同出现了幻觉。
3、MySQL数据库的隔离级别有哪些?分别有什么特点?
①读未提交:一个事务会读取到另一个事务没有提交的数据,存在脏读、不可重复读、幻读的问题。
②读已提交:一个事务可以读取到另一个事务已经提交的数据,解决了脏读的问题,存在不可重复读、幻读的问题。
③可重复读:MySQL默认的隔离级别,在一次事务中读取同一个数据结果是一样的,解决了不可重复读的问题,存在幻读问题。
④可串行化:每次读都需要获得表级共享锁,读写互相阻塞,效率低,解决了幻读问题。
4、Spring 事务实现原理
在应用系统调用 事务声明 的目标方法时,Spring Framework 默认使用 AOP 代理,在代码运行时生成一个代理对象,根据事务配置信息,这个代理对象决定该声明事务的目标方法是否由拦截器 TransactionInterceptor 来使用拦截,在 TransactionInterceptor 拦截时,会在目标方法开始执行之前创建并加入事务,并执行目标方法的逻辑, 最后根据执行情况是否出现异常,利用抽象事务管理器 AbstractPlatformTransactionManager 操作数据源 DataSource 提交或回滚事务。
Spring AOP 代理有 CglibAopProxy 和 JdkDynamicAopProxy 两种,以CglibAopProxy 为例,对于CglibAopProxy,需要调用其内部类的DynamicAdvisedInterceptor 的 intercept 方法。对于 JdkDynamicAopProxy,则调用其 invoke 方法。
5、sql的join原理
Mysql执行顺序&Join原理(360面试题)_mysql join的顺序-CSDN博客
join主要有3种方式:Nested-Loop(嵌套循环)、Hash Join(哈希)、Merge Join(归并)
但Mysql只支持一种join算法:Nested-Loop Join(嵌套循环连接),Nested-Loop Join(嵌套循环连接)有三种变种:
Simple Nested-Loop Join(简单嵌套循环连接),Index Nested-Loop Join(索引嵌套循环连接),Block Nested-Loop Join(阻塞嵌套循环连接)
假设r为驱动表(也叫:外表),s为匹配表(也叫:非驱动表/内表)。简单来说,驱动表就是主表,left join 中的左表就是驱动表,right join 中的右表是驱动表。
(1)Simple Nested-Loop Join(简单嵌套循环连接)
说明:从r中分别取出r1、r2、......、rn去匹配s表的左右列,然后再合并数据,对s表进行了r*n次访问,对数据库开销大。
(2)Index Nested-Loop Join(索引嵌套循环连接)---减少匹配次数
说明:这个要求非驱动表上有索引列,可以通过索引来减少匹配次数来加速查询。查询时,驱动表r会根据关联字段的索引进行查找,挡在索引上找到符合的值,再回表进行查询,也就是只有当匹配到索引以后才会进行回表查询。
(3)Block Nested-Loop Join(阻塞嵌套循环连接)---减少非驱动表的访问次数
说明:索引匹配是最高效,但现实中驱动表上不一定有索引列,这时索引列就会采用Block Nested-Loop Join。可以看到中间有个join buffer缓冲区,是将驱动表的所有join相关的列都先缓存到join buffer中,然后批量与匹配表进行匹配,将第一种多次比较合并为一次,降低了非驱动表(s)的访问频率。
jvm
1、深拷贝与浅拷贝
-
浅拷贝(Shallow Copy):
- 浅拷贝创建一个新对象,其内容与原始对象相同,但是新对象中的元素是原始对象中元素的引用。换句话说,新对象中的元素指向原始对象中的相应元素。
- 浅拷贝只复制了对象的第一层结构,对于嵌套的对象或数组,则仅复制了引用,而不是递归地复制整个嵌套结构。
-
深拷贝(Deep Copy):
- 深拷贝创建一个新对象,并且递归地复制原始对象及其所有嵌套的对象,而不仅仅是复制引用。这意味着新对象与原始对象完全独立,对新对象的修改不会影响原始对象,反之亦然。