本文系作者 [架构精进之路] 原创,著作权归作者所有,未经授权禁止任何形式的转载、抄袭或盗用,违者必究。
弹指间,岁序更迭,又至年末,这一年我们不断奋斗,不断忙碌,真的好似一瞬间,就来到了 2025 年底的时间。
2025 年,是 AI 技术发展突飞猛进的一年。曾经只存在于想象中的智能助手,如今能精准读懂需求、高效处理任务;曾经依赖人工的繁琐工作,如今在 AI 的加持下变得简单快捷;就连创作、设计这些充满人文色彩的领域,也多了一份智能工具的助力。

这一年,AI 不再是遥远的科技概念,而是悄然融入了工作与生活的角角落落。正好跟随「掘金 · 年终技术征文」活动,一起总结记录下AI 编程的心得体会。
一、Vibe Coding 到底是个啥?
今年 AI 界有一个很潮、很酷的新词儿:"Vibe Coding",乍一听有点懵,到底啥是"Vibe Coding"?写代码还要讲究个氛围感吗?
今天我就以一个码农的视角,聊聊对 "Vibe Coding" 的理解。

1.1 什么是 Vibe Coding?
Vibe 本来就是"氛围"、"感觉"的意思,所以直译过来就是"氛围编程"或"沉浸式编程"。但这里的"沉浸"不仅仅是让你沉浸在一个有仪式感的编程环境里,更重要的是它颠覆了我们以往写代码的方式。
我直接上核心观点:就是从「计算机语言描述工作流程」到「自然语言描述工作流程」的转变。
打破编程门槛:AI 让每个人都能"编程"
Vibe Coding 压根就不关心你代码具体怎么实现的,核心关注点是代码生成的结果对不对。至于实现逻辑、底层细节这些繁琐的活,都交给 AI 去搞定。我只需要盯着效果,觉得哪里不对、哪里有问题,就直接改 Prompt,重新提需求,AI 会自动帮你调整和优化,直到最后结果完全符合你的预期为止。
整个过程你都沉浸在 "说想法--->看结果--->继续调整--->再出结果" 的循环里,效率高得飞起。
我画了个大概流程图,执行流程如下所示:
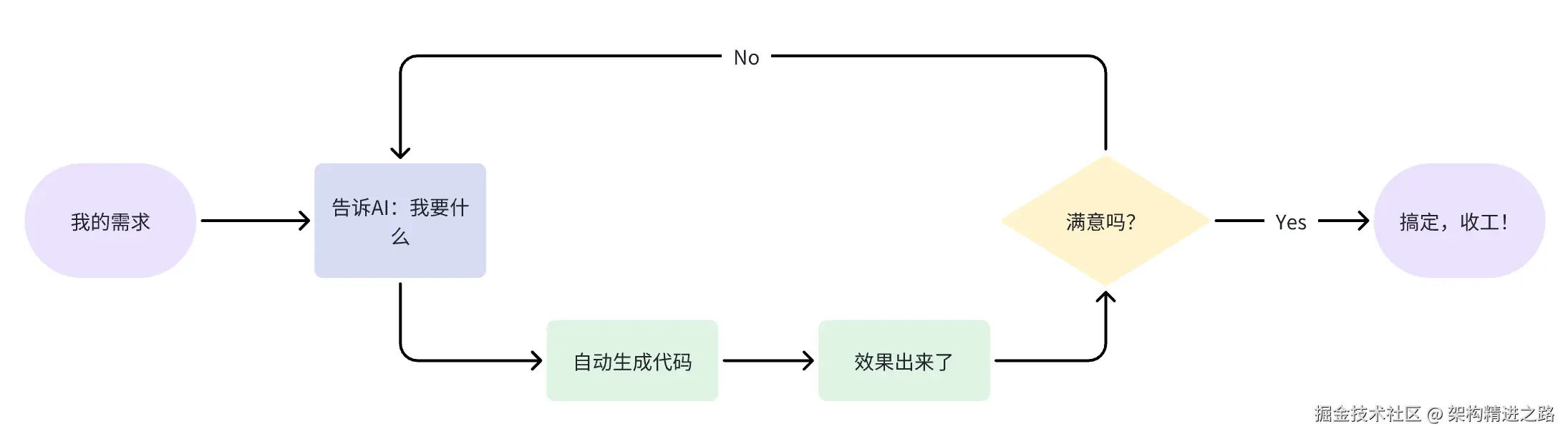
举个生活化的例子:就像点外卖一样,你只管选菜,AI 帮你做。菜端上来不合口味?你直接点评它!AI 厨子立刻再改,直到喂到你满意。
1.2 核心提炼:工作流思维
传统编程 vs Vibe Coding:开发模式的核心变革
1、传统编程:以技术实现为核心
传统编程围绕程序、程序员、软件工程三大支柱展开,具有显著特点:
-
入门门槛高,学习周期长
-
需系统掌握编程语言语法、开发框架、调试技巧等技术细节
-
核心要求是程序员明确知道 "怎么做",通过手动编码实现功能
2、Vibe Coding:以需求描述为核心
Vibe Coding 是一种依托 AI 能力的新型开发模式,核心逻辑高度聚焦:
-
用自然语言精准描述业务需求与工作流
-
由 AI 自动完成代码生成、任务执行与细节处理
-
核心要求是使用者清晰定义 "做什么",无需纠结技术实现路径
3、Vibe Coding 核心特征总结
-
本质是 "用自然语言定义工作流"
-
摆脱编程语言语法、框架的束缚,无需专业编程基础
-
核心门槛在于对业务流程的深度理解
-
重心从 "技术实现" 转向 "需求定义"
-
-
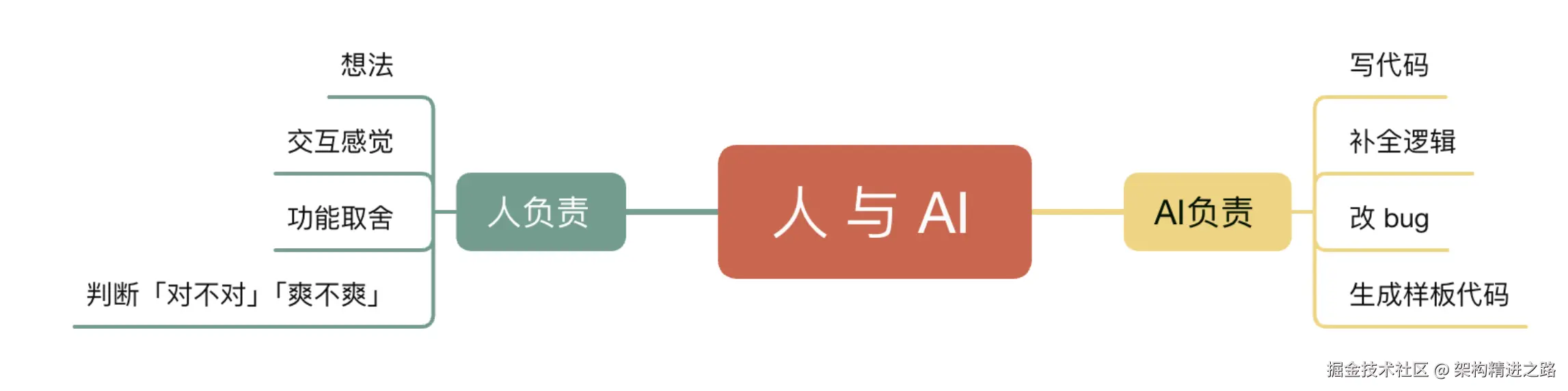
开发模式升级:从 "人做" 到 "人想,AI 做"
-
人的角色:需求提出者、流程设计者、结果审核者
-
AI的角色:代码生成器、任务执行者、细节处理者
-
-
适用场景清晰划分
-
高度适配场景:MVP 产品快速验证、内部工具开发(数据处理、文件整理等)、创意方案原型测试
-
暂不适用场景:复杂业务逻辑开发(需人工决策与逻辑校验)、性能关键路径构建(需深度人工优化)
-
二、程序员视角下的 Vibe Coding
2.1 利用 Trea 进行 Vibe Coding 的应用实践
Trae.ai 是个 AI 编程 IDE,字节跳动的产品,目前是免费使用,写代码、查文档、加接口都可以,和它对话就能改功能、查问题,事半功倍。
1、生成提示词
写不好提示词,没关系,这一步AI可以帮我们很好的搞定!
movie.douban.com/top250 我希望获取这个网站的数据,帮我生成一份爬虫项目的提示词

2、生成项目代码并执行
有了提示词,可以参考它执行,生成我们需要的项目代码了。
执行过程中,可能会出现如下需要我们确认执行的步骤,一般确认运行即可。

最终生成一份可执行代码,并可执行并验证,整体效率非常高效!

3、生成可渲染展示页面
为了更直观的查看数据,生成可运行的 Web 服务来渲染这些数据。

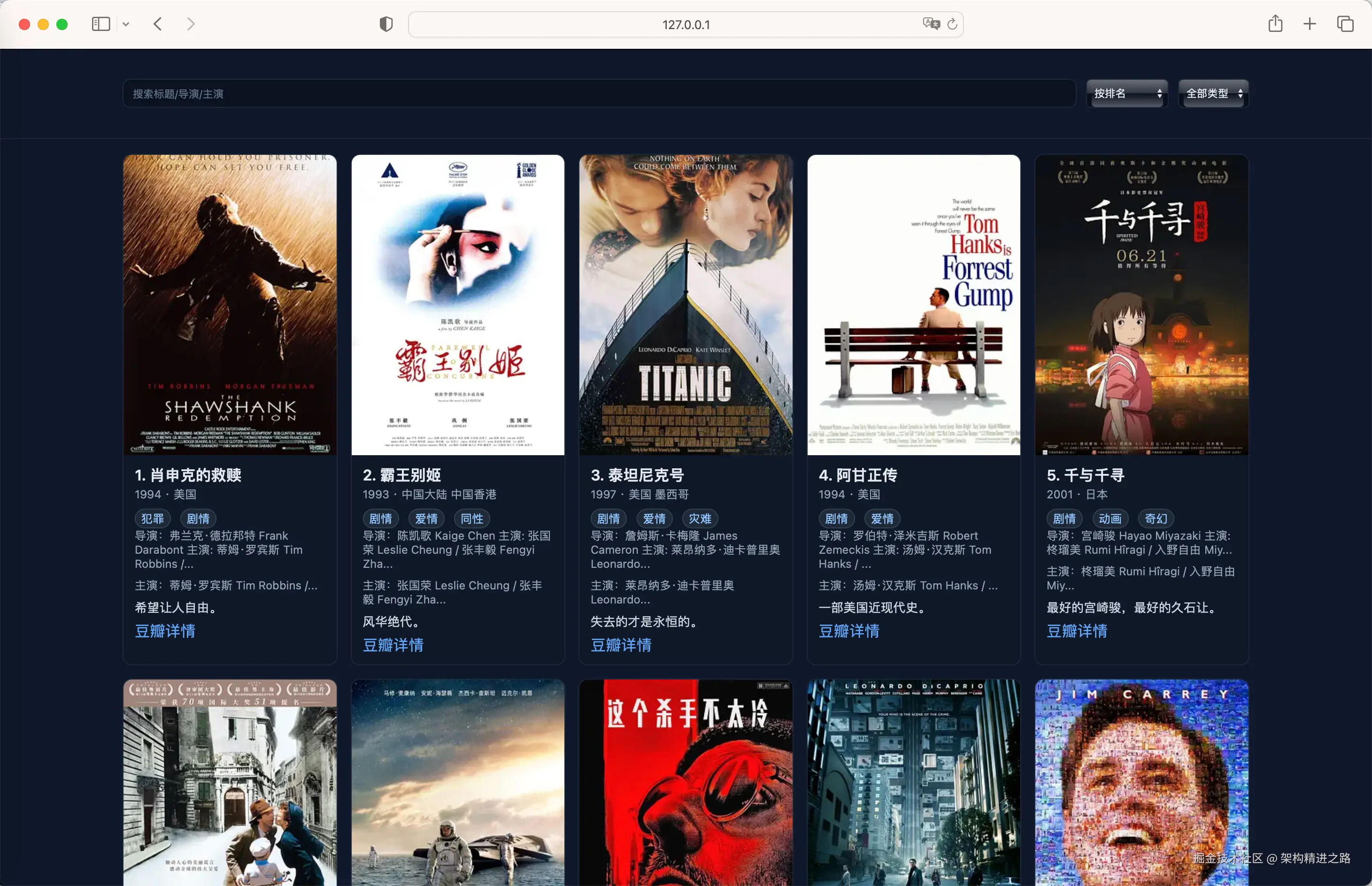
如果需要更好的查看体验,可以继续调试添加分页能力。
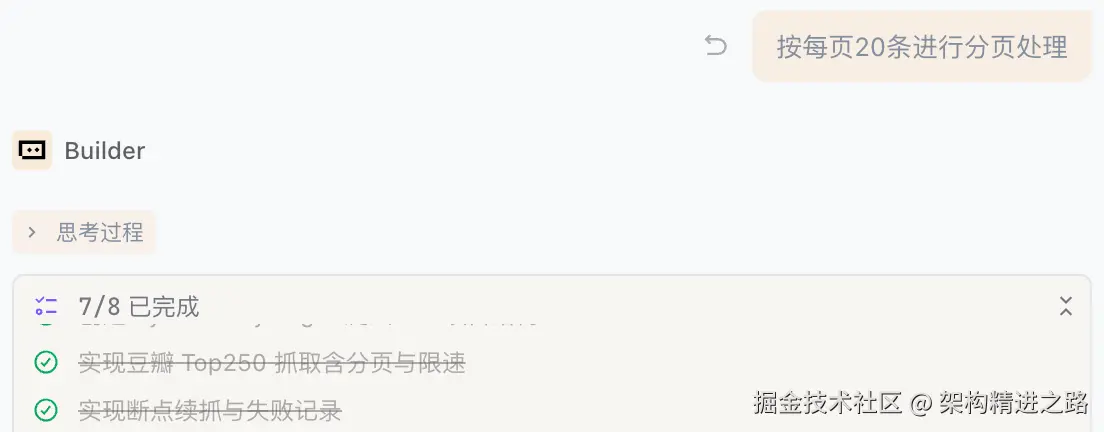
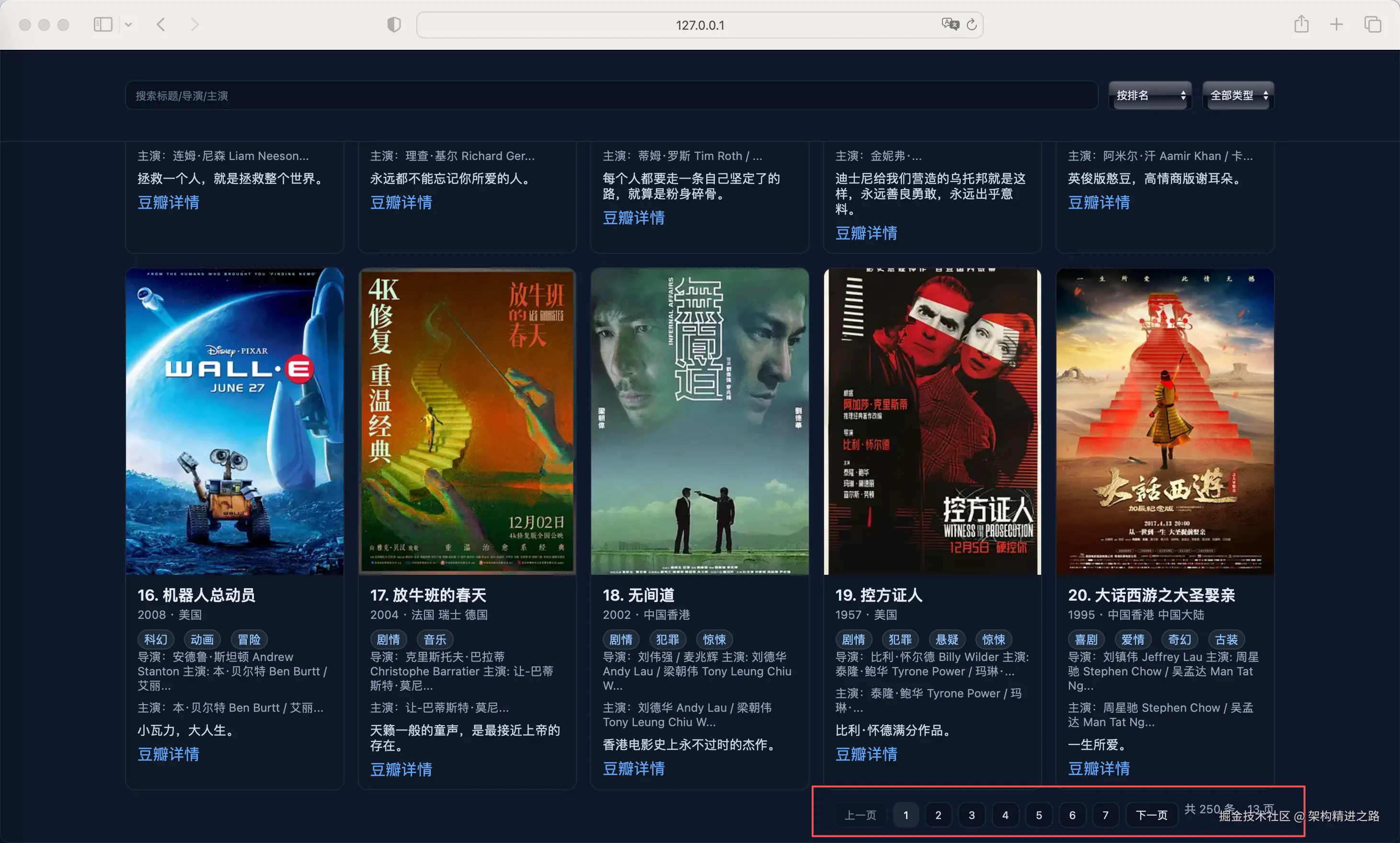
上述整体步骤非常高效,前后不过几分钟而已,Trea 堪称开发利器。
2.2 AI 编程的缺点与挑战
1、天生缺乏业务场景深度理解
- 核心现象
AI 生成的代码,经常会陷入"技术正确,业务失真"的困境------语法合规、可编译运行,但完全不符合真实业务的约束条件与核心诉求。
- 典型案例:电影数据展示列表场景
AI 仅生成通用的电影数据列表展示代码,却忽略豆瓣Top250项目的核心业务规则:
-
业务中需按"评分降序、上映时间筛选"双维度排序展示电影
-
需实现分页加载(避免一次性加载250条数据卡顿)、数据异常兜底(部分电影信息缺失时的友好展示)等核心逻辑
最终结果是"代码看似专业,实则无法满足豆瓣Top250项目的核心展示需求与用户体验要求"。
- 解决思路
由人明确定义不可让步的业务规则与约束条件,为 AI 划定业务边界。
2、对性能问题极度不敏感
- 核心现象
AI 生成的方案逻辑无误,但工程实现成本极高;小数据量测试时表现正常,一旦上线面对真实流量便会瞬间"翻车"。
- 典型案例
案例一:列表数据加载性能崩塌
补充完"评分排序、上映时间筛选"逻辑后,AI 快速实现了数据展示功能,但方案存在致命缺陷:默认一次性加载全部250条电影数据,未做分页处理与图片懒加载优化,导致页面首次加载耗时超 8 秒,滚动时出现明显卡顿,移动端甚至直接白屏。
案例二:列表数据接口异常处理缺失
AI 给出的项目初版方案中,直接调用豆瓣公开接口获取数据,但未设计任何异常应对逻辑:当接口请求超时、返回数据格式异常或接口限流时,页面直接空白无提示,用户无法判断是网络问题还是服务问题,体验极差。
- 问题根源
AI 的优化目标是"推理逻辑正确性",而非"系统长期运行的稳定性与成本可控性",天然缺失工程化的性能考量。
- 解决思路
-
人先主导分析:明确系统性能瓶颈所在(IO、CPU、内存、模型加载等);
-
再引导 AI 优化:针对性提出缓存方案、服务常驻化设计、预加载机制、资源池搭建等性能优化需求。
3、异常与边界处理严重缺失
- 核心现象
AI 生成的代码在"理想流程(Happy Path)"下表现完美,但缺乏对异常场景的应对能力,一旦出现意外情况便直接崩溃。
-
典型缺失的异常处理场景
-
豆瓣接口请求超时、返回数据格式异常及重试策略缺失;
-
电影封面图加载失败、部分字段(如导演、演员)缺失等数据异常的兼容处理;
-
豆瓣接口限流时的降级展示逻辑(如加载本地缓存数据)。
-
-
问题本质
AI 默认预设"理想运行环境",但真实生产环境是"持续面临各类异常的复杂系统",这种认知偏差导致其无法主动构建健壮的容错机制。
- 应对方式
由人主动补充完善容错体系:明确异常分级标准、制定服务降级策略、设计超时控制与熔断机制。
核心总结:工程质量的高低,取决于你对"失败与异常"的预期深度。
三、如何正确理解重构工作流
个人对 vibecoding 加成下 重构工作流的理解
AI 不是来当主厨的,是为了让主厨不用天天切土豆

3.1 构思全自动化工作流
关键原则:摒弃"一步到位"的完美主义,先让"流程跑通"
核心目标:构建无需人工介入,即可完成从数据获取、处理到展示的全链路自动化流程
项目案例(豆瓣Top250电影数据展示):
-
程序自动化流程:AI 生成定时任务脚本(每日凌晨触发)→ 自动调用豆瓣接口获取最新Top250数据 → AI 自动处理数据格式(标准化字段、补全缺失值默认值)→ 自动同步至前端展示数据库 → 前端页面自动拉取数据并渲染
-
落地优先级:先实现"无人工干预的基础数据展示",暂不纠结细节优化(如极致加载速度、个性化筛选);待流程稳定跑通后,再针对性迭代自动化优化逻辑

3.2 人的价值不可忽视
关键原则 :人的核心价值在于 --- 决策、审核、优化
核心目标:在关键节点加入人工审核和优化,避免自动化流程"跑偏"
项目案例(豆瓣Top250电影数据展示):
-
决策环节:确定核心业务规则(如"评分降序+上映时间筛选"的排序逻辑、分页条数设置、异常数据兜底规则),为AI自动化流程划定边界;
-
审核环节:在"数据同步至展示数据库"前增设人工审核节点,校验AI处理后的数据准确性(如是否存在错误评分、缺失关键电影信息等),避免错误数据直接展示给用户;
-
优化环节:监控自动化流程运行状态(如接口请求成功率、页面加载性能),针对卡顿、数据异常等问题,向AI提出精准优化需求(如添加接口重试机制、优化图片加载策略),推动流程迭代升级

四、总结
回望这一年的点滴,我历经诸多变迁,在跌撞中摸索,在求索里前行。惟愿不负韶华,始终心怀热忱,向上生长,步履不停。
最后,跟大家分享下自己 AI 学习的三个观点:
1、LLM带来的不是更高层次抽象,而是不同性质的抽象
传统编程的抽象(如函数、类、框架)是确定性抽象;LLM 的抽象则是概率性抽象,其本质是基于海量文本规律统计
2、大模型把非确定性引入了软件开发的核心路径
传统软件开发的核心路径(需求→设计→编码→测试→部署)是确定性闭环,而LLM则从生成、理解、迭代环节的非确定性打破了这一闭环
3、软件工程的重心正在从写对的代码转向管理意图与结果之间的偏差
传统软件工程的核心是 "代码正确性",LLM 普及后,编码效率大幅提升,但"意图 vs 结果"偏差成为新的核心风险
·END·
希望今天的讲解对大家有所帮助,谢谢!
Thanks for reading!
作者:架构精进之路,十年研发风雨路,大厂架构师,CSDN 博客专家,专注架构技术沉淀学习及分享,职业与认知升级,坚持分享接地气儿的干货文章,期待与你一起成长。
关注并私信我回复"01",送你一份程序员成长进阶大礼包,欢迎勾搭。