大家好!我是大聪明-PLUS!
我们团队开发并实现了一个基于 FUSE 的文件系统 (FS),作为分布式邮件队列项目的一部分。该项目需要实现一个网络文件系统,将数据存储在三个不同的数据中心。目标是提高容错能力,确保即使一个数据中心完全故障也不会导致服务级别协议 (SLA) 违约。本文面向所有对文件系统和数据存储感兴趣的人。我们将讨论以下内容:
-
为什么要自己编写文件系统?
-
如何使用 FUSE 框架编写自己的文件系统;
-
在生产环境中使用 FUSE 有哪些弊端?
本文是FS三年研发的成果。现在正是泡杯茶的好时机;接下来会讲一个很长的故事。
一、如何使用 FUSE 框架开发文件系统
在 Linux 系统中,多个文件系统可以同时运行。每个文件系统 负责管理自己的文件子树。该子树的根目录称为挂载点。要查看 Linux 系统中已挂载的文件系统列表,请运行`findmnt`命令。
要启动一个新的文件系统,需要使用`mount`系统调用来挂载它。它的参数指定要挂载的文件系统、路径以及挂载选项。`mount` 是一个特权系统调用,它会影响其他用户在文件树中看到的内容。因此,执行 `mount` 需要CAP_SYS_ADMIN 权限------实际上就是超级用户权限。
如果您决定编写自己的文件系统,您有两种选择:开发操作系统内核模块或使用 FUSE (用户空间文件系统)框架编写应用程序。后一种选择具有以下几个优点:
-
文件系统可以作为用户空间程序进行开发,无需在操作系统内核中编写代码。
-
FUSE 支持非特权文件系统挂载;运行文件系统不需要超级用户权限。
这意味着 FUSE 的开发速度更快,调试也更容易。让我们更详细地了解一下这个框架。
隆重推出 FUSE
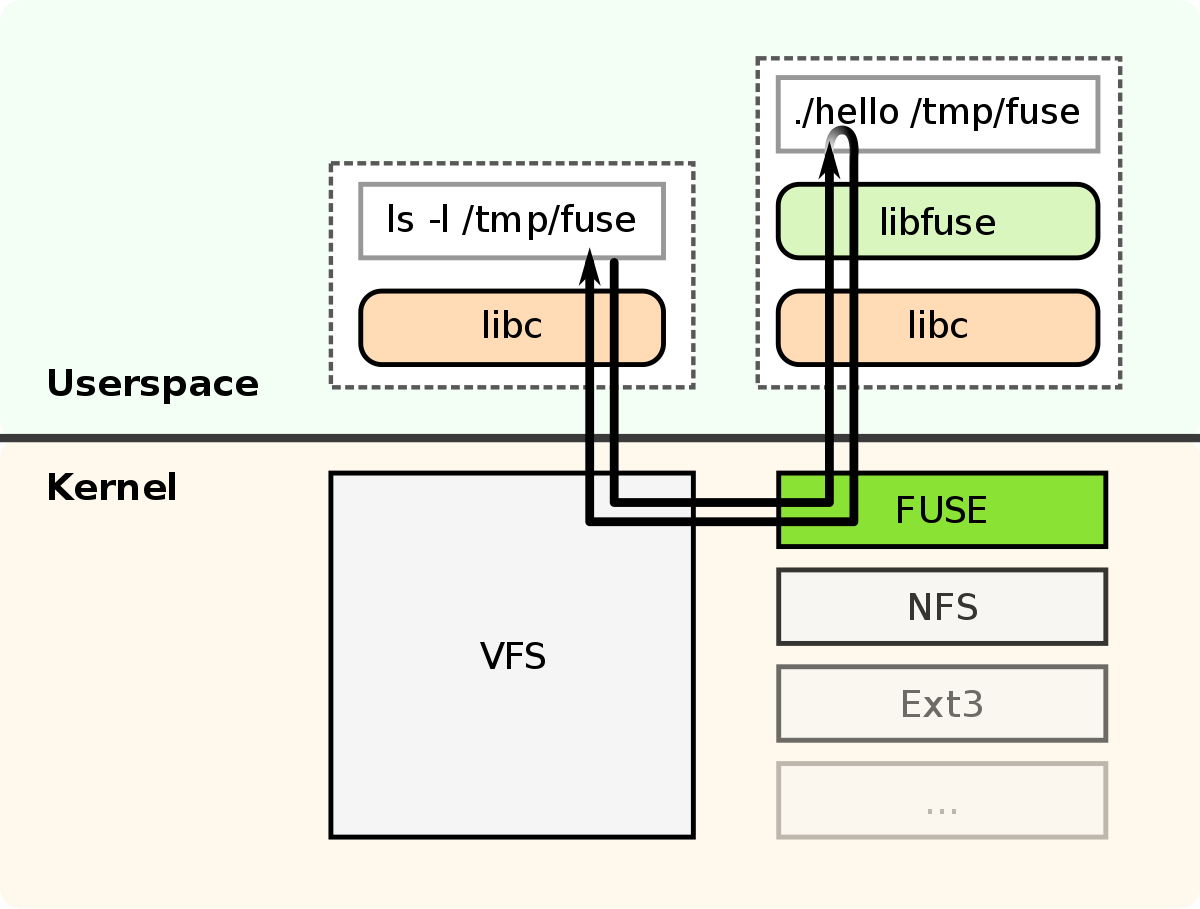
从 FUSE 的角度来看,文件系统是一个名为文件系统驱动程序的用户空间守护进程。Linux 中的文件系统实现了相同的接口。这是 Linux 内核子系统vfs的职责。vfs 充当路由器,将客户端请求定向到文件系统实例。
FUSE内核模块:
-
收到来自 vfs 的请求;
-
将其转发给 FS 驱动程序;
-
等待司机回复;
-
将结果返回给 vfs。
该过程如图所示。
FUSE框架操作流程图。
操作系统内核的 FUSE 模块和文件系统驱动程序通过 RPC 协议进行通信。在挂载过程中,驱动程序通过`/dev/fuse`设备与操作系统内核的 FUSE 模块建立连接。数据包以请求-响应模式在 FUSE 连接上传输。文件系统驱动程序的响应顺序可能与请求的发送顺序不同。每个响应都通过 ID 引用请求,从而允许文件系统驱动程序并行处理请求。
接下来我们将研究文件系统驱动程序架构。
文件系统驱动程序的工作原理
FS驱动程序是一个RPC服务器,用于处理来自FUSE内核模块的请求。通信协议由libfuse库实现,该库负责FUSE连接的生命周期管理、请求解析和响应序列化。
Libfuse 包含一个高级 API 和一个低级 API。前者是对后者的封装,它简化了接口,但降低了性能。后者直接处理来自操作系统内核的请求。主要区别在于,在高级 API 中,文件系统通过路径名来操作文件,而在低级 API 中,它直接操作 inode 和 dentry。我们稍后会详细讨论这一点。
我之所以撰写关于底层 API 的文章,是因为它提供了更大的灵活性,并有助于更好地理解文件系统设计。我引用的代码是用 C 语言编写的。不过,libfuse 提供了对高级语言的绑定,以及其他库实现。或许对您来说,使用高级语言编写文件系统会更方便。
libfuse 会话
开发文件系统驱动程序首先需要调用 ` fuse_session_new() ` 函数来创建 libfuse 会话。该函数接受一个 ` struct fuse_lowlevel_ops`结构体作为输入。该结构体是文件系统的 RPC API,包含指向请求处理函数的指针。您无需实现所有处理函数;可以从一小部分开始。
如果客户端的请求不受支持,FUSE 将返回错误。
创建的 libfuse 会话使用fuse_session_mount()函数挂载到目录。此函数在后台执行非特权挂载操作。如果系统调用挂载权限不足,它将调用fusermount程序。该程序与 libfuse 捆绑在一起,由于其权限中包含SUID 位,因此以 root 权限运行。
libfuse 会话挂载后,事件循环随即启动。在此循环期间,文件系统驱动程序会读取来自 FUSE 连接的请求并执行相应的处理程序。启动事件循环的方法有多种。
-
**默认事件循环。`fuse_session_loop()**函数在当前线程中维护 FUSE 连接。文件系统卸载后,该函数返回。这是最简单的事件循环。
-
多线程事件处理。`fuse_session_loop_mt ()`函数会启动一个线程池。传入的请求将由任意空闲线程处理。请注意,多线程事件处理会引入竞态条件。使用这种方法,您需要用互斥锁封装数据结构。
-
自定义事件循环。Libfuse为其自身的循环实现提供了一个 API。`fuse_session_fd() 函数返回 FUSE 连接的文件描述符。`fuse_session_receive_buf() 函数从该描述符读取请求到缓冲区。`fuse_session_process_buf() 函数解析缓冲区中的请求,并执行在创建 libfuse 会话时`struct fuse_lowlevel_ops`中指定的处理程序。`fuse_session_exited ()`函数提供循环退出条件。
最简单的文件系统开发是从这样的代码开始的:
struct` `fuse_args` `args` `=` `FUSE_ARGS_INIT`(`0`, `NULL`);
`fuse_opt_add_arg`(`&args`, `""`);
`fuse_opt_add_arg`(`&args`, `"-odefault_permissions"`);
`fuse_opt_add_arg`(`&args`, `"-oauto_unmount"`);
`fuse_opt_add_arg`(`&args`, `"-odebug"`);
`struct` `fuse_conn_info_opts` `*opts` `=` `fuse_parse_conn_info_opts`(`&args`);
`if` (`!opts`)
`exit`(`EXIT_FAILURE`);
`struct` `fuse_lowlevel_ops` `api` `=` {
`// TODO: add filesystem handlers`
};
`struct` `fuse_session` `*se` `=` `fuse_session_new`(`&args`, `&api`, `sizeof`(`api`), `NULL`);
`if` (`!se`)
`exit`(`EXIT_FAILURE`);
`int` `err` `=` `fuse_session_mount`(`se`, `"/mnt/my-fs"`);
`if` (`err`)
`exit`(`EXIT_FAILURE`);
`fuse_session_loop`(`se`)
`文件系统数据结构
FUSE API 由三个核心数据结构构成。让我们仔细看看这些结构。
inode 是一个包含任意数据块的整数 ID,用于存储文件内容,并包含来自struct stat结构体的属性。请注意 inode 字段:除了访问权限之外,该字段还包含文件类型,例如:普通文件、目录或符号链接。不同类型的文件对 inode内容的解释可能有所不同。普通文件包含数据;目录不包含任何内容,文件通过 inode 包含在目录中;符号链接包含其指向的路径。以上仅为一般概念,具体逻辑实现可能因文件系统而异。st_mode``inode``Inode``inode``dentry``inode
目录项(Dentry inode )是文件树中的一个位置,包含文件名、IDinode和父inode目录。挂载文件系统时,必须创建inodeID 为 1 的根目录。这是一个众所周知的值;dentry文件系统中的所有文件都将是此目录项的后代inode。将文件分离为两个独立的实体------目录项和 inode------是一种优化。它允许在目录之间进行低成本的文件重命名和 inode 重定位。在这种情况下,只有目录项发生变化dentry,inodeinode 保持不变;不会复制任何数据。
文件 。打开文件上下文。当客户端打开一个文件时,文件系统可以创建一个任意结构,并将指向该结构的指针放置在 ` <file_context>` 中。FUSE 会在每次打开文件操作时将该结构传递给文件系统。此字段是可选的,可以留空。在这种情况下,文件系统实现无状态 I/O ;它会在每次打开文件操作期间搜索 ID;文件系统中不会声明文件结构。如果文件系统在 `<file_context>` 中放置了内容,则它实现有状态 I/O------ 这是一种优化,无需在每次打开文件操作期间按 ID 搜索。这可以节省处理器资源并消除搜索错误。fi->fh``fi``fi->fh``inode``fi->fh``inode
文件结构具有误导性。首先,它并非我们通常从定义中了解到的"命名字节序列"。其次,手册中使用了两个短语:
-
文件描述符------一个非负数,是程序在调用open()时接收到的已打开文件的 ID ;
-
文件描述是一个内核对象,是打开文件的上下文,这也在open()手册中进行了描述。
文件是一个对象file description。文件描述符在进程的打开文件表file中通过ID进行引用。多个文件描述符可以引用同一个文件。 description``file description.
inode一开始,你可以先使用 inode和 dentry来开发文件系统,dentry而无需预先定义结构file。这种折衷方案可以节省时间,并避免将来进行重大的架构变更。与将命名文件划分为 inode 和 dentry 相比,从无状态 I/O 过渡到有状态 I/O 要简单得多。接下来,我们将了解这些实体的生命周期:它们是如何创建和删除的。
文件系统数据结构的生命周期
inode 的生命周期。文件系统会inode在用户调用mknod()、mkdir()或symlink()时创建一个 inode。inode有一个引用计数器------即 `inode_count` 字段。在创建时,该值为 1。Linux 会递增该值:nlookupinode nlookupnlookup
操作系统调用lookup()函数来递增该值。当被硬链接或文件描述符引用时,该值大于 0。Linux 会递减该值:nlookupinodenlookupnlookup
在这两种情况下,Linux 都会调用forget()函数来递减nlookup 值。当 nlookup 值降至零时,文件系统会删除该值。nlookupinode
还有inode第二个引用计数器,nlink它反映指向的链接数量dentry,inode也就是硬链接的数量。通常情况下,nlink≤ nlookup,因为nlookup它统计了打开的文件和硬链接,而nlink只统计硬链接。但是,也有例外;更多内容请参见"文件系统发起的文件创建和删除"一章。
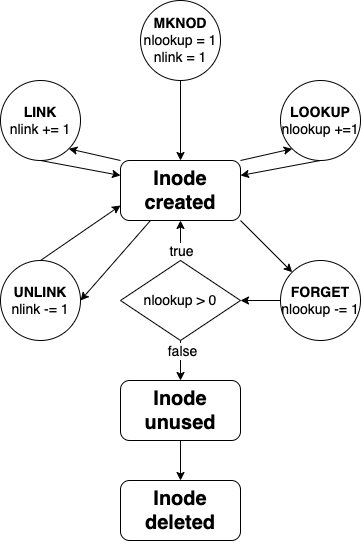
节点生命周期。
目录项的生命周期 Dentry是一个指向目标目录的硬链接。inode文件系统在执行 `get_dir()` 时创建第一个这样的链接。调用 `link()`inode函数会创建其他硬链接。调用`rename()`函数会修改硬链接,调用`unlink()`函数会移除硬链接。移除硬链接并不会立即移除目标目录,因为已打开的文件描述符可能仍然引用没有硬链接的目录项。inodeinode
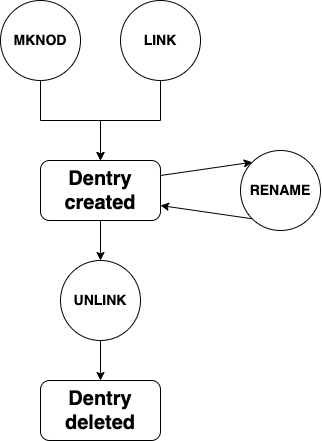
牙齿的生命周期。
文件生命周期。文件系统在调用`open()`或`opendir()`时创建一个文件。每次打开文件操作都会通过 `file_recipient` 字段传递对该文件的引用。复制文件描述符时,两个副本都指向同一个文件。Linux 会维护一个 `file_recipient` 的引用计数;文件系统内部无需再进行计数。当引用计数降至零时,Linux 会调用`release()`或`releasedir()`。此时,文件系统会删除 该文件。fi->fh``file
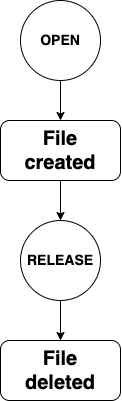
文件的生命周期。
文件系统中的标准锁
文件系统提供两种标准锁定机制。
POSIX 锁。使用fcntl()设置。支持锁定文件的部分内容。它们支持独占锁(F_WRLCK用于写入操作)和共享F_RDLCK锁(用于读取操作)。它们存储在 inode 上下文中,这意味着当设置一个锁后创建子进程时,只有父进程才能拥有该锁。
BSD 锁。使用flock()获取。仅支持整文件锁。支持独占锁和共享锁。它们存储在上下文中file,这意味着当获取锁后创建子进程时,父进程和子进程都将拥有该锁。
这两种锁都属于建议性锁。这意味着,如果进程 1 已获取锁,而进程 2 决定修改文件,操作系统会允许进程 2 进行修改。只有当进程 2 在修改文件前检查锁的存在时,锁才会生效。在这种情况下,进程被称为"尊重锁"。
你不需要自己编写锁。如果你不实现锁,操作系统会使用默认实现。自定义锁实现对于访问远程存储的网络文件系统来说是有意义的。
状态存储工具
在开始开发文件系统时,你需要回答几个问题。
-
你想解决什么问题?
-
你的文件系统应该是网络文件系统还是本地文件系统?
-
如何存储本地数据?
无论文件系统类型如何,存储本地数据都是架构的重要组成部分。所有状态inode(dentry包括可用状态和file可用数据)都是文件系统必须存储和维护的状态。这可以通过多种工具来实现。
一种常见的本地数据存储方法是将请求代理到底层文件系统。在这种方法中,FUSE 文件系统通过通用文件系统将数据存储在磁盘上。这种代理文件系统被称为"直通"文件系统。
直通文件系统使用opendir命令指定要挂载到的目录。这会访问底层文件系统。直通文件系统使用底层文件系统作为本地数据的存储介质。这种方法简化了开发,因为它不需要直接与硬盘设备交互。然而,这会降低性能。如果您对直通文件系统感兴趣,请考虑进行这方面的优化;更多详细信息请参见"性能"部分。
传递式文件系统就像复写纸:最上面的纸是传递式文件系统,所有记录最终都会保存到最下面的纸------底层文件系统。
如果传递机制不适合您,您需要实现自己的状态存储结构:树、哈希表等等。最简单的方法是使用嵌入式数据库管理系统,并将所有内容存储在其中inode,dentry因为必要的算法已经在其中实现。file
在我的项目中,我使用Tarantool并禁用磁盘写入来存储数据、文件和目录。对于文件内容,我使用了memfd------它的接口与 FUSE 的read()和write()请求兼容。这样,我就将所有状态都保存在 RAM 中------这是一种非常规的解决方案。它能带来高性能,但不适合长期存储。inode``dentry``file
结论
我为什么要讲这么多理论呢?因为这些信息分散在各种不同的来源,如果当初项目启动时能读到这样一篇文章,我会非常感激的。如果你想开发自己的文件系统,下一步就是从 libfuse 代码库复制并构建示例。根据你的需求修改代码,遇到问题时可以参考上面的内容。
二、FUSE文件系统开发和运行的陷阱
接下来,我们将从理论转向实践,探讨在生产环境中使用 FUSE 时遇到的问题以及我们的解决方案。如果您从头开始阅读,非常感谢您坚持到现在。或许是时候休息一下,喘口气了。
FUSE 管理工具
让我们来看看可用于利用 FUSE 漏洞的工具以及它们解决的问题。
配置 /etc/fuse.conf
/etc/fuse.conf 是用于控制对 FUSE 访问的配置文件。FUSE 文件系统的访问受到限制,以防止用户通过非特权挂载对文件树进行意外更改。此限制与文件权限无关。它在 FUSE 内核模块级别实现,可以防止诸如"在 /bin 中挂载自定义文件系统、替换可执行文件并提升权限"之类的攻击。默认情况下,只有所有者(即挂载文件系统的用户(UID/GID))才能访问 FUSE 文件系统。系统管理员可以使用 /etc/fuse.conf 中的以下选项放宽这些限制,并允许其他用户访问:
-
user_allow_root--- 允许 root 用户访问他不是所有者的 FUSE 文件系统; -
user_allow_other--- 允许所有用户访问他们不拥有的 FUSE 文件系统。
FUSE限制了同时挂载的文件系统数量。mount_max = NNN,默认设置为1000。
/etc/fuse.conf 文件允许您为所有 FUSE 文件系统指定标准挂载选项。
FUSE 控制文件系统
FUSE 控制文件系统是一个用于管理 FUSE文件系统的工具。运行mount -t fusectl none /sys/fs/fuse/connections该工具即可挂载文件系统。您将在 /sys/fs/fuse/connections 目录中看到活动 FUSE 连接的列表。
`ls -1A /sys/fs/fuse/connections
321`每个连接都是一个包含多个文件的目录。
`ls -1A /sys/fs/fuse/connections/321
abort
congestion_threshold
max_background
waiting`如何在 FUSE 控制文件系统中匹配文件系统实例和 FUSE 连接 ID?答案隐藏得很深,但确实存在:你需要查看已挂载文件系统的设备号:
`cat /proc/self/mountinfo | grep "\- fuse /dev/fuse" | awk '{print $3 " " $5}'
0:321 /var/spool/exim/input
`比较以上三个代码清单。连接 ID 为 321 的 FUSE 文件系统已挂载到 /var/spool/exim/input。
向文件 /sys/fs/fuse/connections/321/abort 写入任何数据都会断开 FUSE 连接。这是卸载文件系统最彻底的方法;即使kill -9失败也能生效。
内核的 FUSE 模块中还需要另外三个文件来管理请求队列。它们的用途是:
-
waiting--- 从文件中读取数据会显示 FUSE 队列中的请求数量。该文件不可写。 -
max_background--- 限制并行异步请求的数量(FORGET),以确保文件系统有足够的性能来处理同步请求。该文件可读写。 -
congestion_threshold--- 队列长度阈值,超过此阈值后,VFS 开始限制文件系统请求。文件可供读取和写入。
实际上,我只使用了中止文件;对于微调 FUSE 队列的好处,我无法发表任何意见。
在 Kubernetes 中挂载 FUSE
要启用此功能,您可以运行具有特权的容器,但这很危险。在这种情况下,Linux 允许您以非特权方式挂载文件系统,但除了您的进程及其子进程之外,任何其他进程都无法访问您的文件系统。
Linux 命名空间是一个复杂的话题,如果您对专门的文章感兴趣,请在评论区留言。本文仅提供一种在 Kubernetes 中安全挂载 FUSE 的解决方案,不详细解释其工作原理。您可以选择以下两种方法之一。
-
如果您使用的是旧版本的 Kubernetes,请使用unshare工具手动创建空间。然后,使用文件系统驱动程序启动容器,如下所示:
unshare -U -m -r -- /path/to/filesystem/binary --maybe-with-args
为文件系统创建单独的用户空间和挂载空间,可以让你无需其他操作即可挂载它CAP_SYS_ADMIN。
表现
在我最初启动系统时,FUSE 的性能是一个特别紧迫的问题。有人反映 FUSE 文件系统查询可能需要几秒钟------这非常长。运行 FUSE 时,系统调用次数会增加高达两倍,这是系统架构的必然结果。然而,系统调用期间的上下文切换本身耗时并不长:仅需1~2微妙。此外,如果上下文切换次数是一个问题,还有许多优化方法可供使用。
FUSE性能研究证实,在许多工作负载下,FUSE的性能下降幅度不超过5%。该研究确实包含一些性能显著下降(最高达83%)的案例,但这些案例数量很少。
即使负载模式"不佳",FUSE 本身也不会让系统卡顿几秒钟。根据我的经验,性能下降通常是由于 FUSE 请求处理程序代码的问题,而不是客户端通过内核向文件系统传输数据的问题。例如,如果你的处理程序不断等待锁或同步访问网络,那么系统确实可能会卡顿几秒钟。如果你遇到 FUSE 文件系统性能问题,请确保文件系统驱动程序高效运行。
我希望我已经消除了大家对 FUSE 性能的任何误解。下一章,我们将探讨多线程模型:如何设计文件系统架构以最大限度地减少性能问题。
多线程模型
开发自己的文件系统时最常见的三个错误:
-
僵局。
-
免费使用后即可使用。
-
性能下降。
在这三种情况下,错误数量都可以通过选择多线程模型来减少。本章我将讨论我为项目选择的模型。
我使用Tarantool来存储 inode 和 dentry 。它是一个 C/Lua 数据库管理系统和应用服务器。我的文件系统本身就是一个 Tarantool 应用,因此,在这种情况下,文件系统的多线程模型与 Tarantool 的多线程模型紧密相关。
在 Tarantool 中,只有一个线程可以访问数据。该线程执行纤程(fiber)------异步协程。纤程不会阻塞执行线程;任何阻塞操作都会将控制权转移到一个就绪的纤程。纤程调度算法是非抢占式的。这意味着,如果一个纤程获得了控制权,它可以无限期地执行,直到它决定返回控制权为止。I/O 操作被隔离到一个独立的线程池中。得益于这种多线程模型,Tarantool 保证了线性化的数据访问------伪并行纤程以相当顺序的方式执行数据操作。这为文件系统奠定了良好的基础:默认情况下消除了竞争条件,并且无需将数据结构封装在互斥锁中。
我们将 libfuse 事件循环与 Tarantool 纤维集成在一起。Libfuse 为此提供了一个自定义的事件循环 API ,我在" Libfuse 会话"一章中对此进行了更详细的描述。挂载文件系统时,我们会启动一个后台纤维来处理 FUSE 请求。它按照以下算法运行:
最终得到的模型如下:
-
FUSE 请求在一个线程中按到达顺序进行处理;
-
从 FUSE 连接读取数据是非阻塞的;
-
由于 Tarantool 的线性化数据访问,处理程序是同步的,也是非阻塞的。
该模型能够高效处理 FUSE 请求,一般情况下不会浪费时间在锁定上。
异步处理程序。
任何阻塞式处理程序都不符合上述模型:它会导致队头阻塞问题,并阻塞 libfuse 事件循环。在阻塞式处理程序中,我们会启动一个单独的 Fiber 来处理请求。
在哪些情况下处理程序会变成阻塞式处理?
在单个光纤中对 FUSE 请求进行非阻塞同步处理,并在单独的光纤中处理阻塞处理程序。这是我最终确定的模型,目前为止运行良好,可以投入使用。
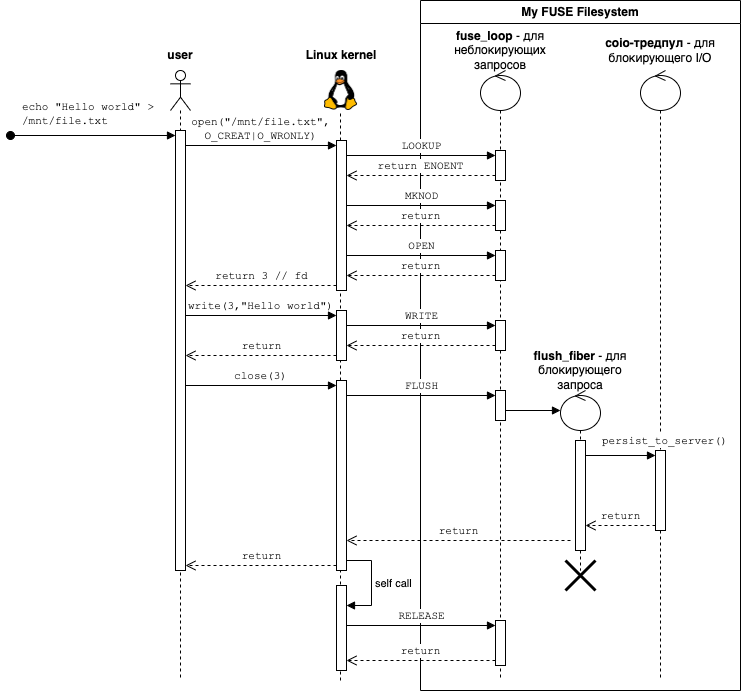
以简单的文件系统操作为例,演示多线程模型的实际应用。
两种类型的死锁
假设我们有两个进程、线程或协程:A 和 B。它们想要锁定两个资源:P1 和 P2。A 锁定了 P1,B 锁定了 P2。现在 A 和 B 都无法同时锁定这两个资源,它们将无限期地等待对方------发生了死锁。死锁是一个众所周知的问题。关于死锁的预防和处理,已经有大量的理论文献。在本节中,我们将讨论实践经验:如何检测死锁、死锁之间的区别以及如何恢复系统。
用户空间死锁
**症状:**访问文件系统时,某些进程会挂起。进程列表会显示挂起的进程,您可以查看它们的日志来确定问题是否出在文件系统上。
**如何调试?**查看文件系统日志。我的进程没有很多锁,所以我为每个锁都添加了一条日志。这些日志显示了哪个 Actor 正在等待哪个资源。
**解决方法:**重启文件系统;执行 kill 命令应该可以解决问题。针对这种情况,我重写了代码以消除死锁的可能性。
文件系统发起的文件创建和删除
网络文件系统从服务器接收文件更改信息。这意味着此类文件系统中的文件可以"由文件系统主动"创建和删除,无需本地客户端的任何操作。本节将探讨文件系统如何通知内核文件已创建或删除。
创建文件
要创建文件,只需将其保存inode到dentry本地文件系统存储即可。客户端在请求目录中的文件列表时,就能看到您的文件。
使用mknodinode创建的 inode与文件系统直接插入本地存储的 inode之间存在区别。提醒一下,inode 有两个引用计数器(更多内容请参见"文件系统数据结构的生命周期"一章):inode
创建inode和dentry使用时mknod:
当文件系统主动向本地存储插入数据inode,dentry而内核没有发出请求时
:
-
nlookup = 0--- 因为操作系统内核中没有任何数据结构引用它inode,所以内核在重新读取该目录之前不会知道它的任何信息; -
nlink = 1因为 FS 创建了一个新的dentry。
我不确定这种行为是否正确,但它在我的文件系统中有效。应该在`forget() ` 处理程序中考虑` nlink>`选项。删除操作通常在 inode 值降至零时异步发生。如果你的文件系统可能出现`>`的情况,你也应该在删除 inode 之前进行检查。nlookup``inode``nlookup``nlink``nlookup``nlink
删除文件
删除文件系统创建的文件比创建文件更复杂。操作系统内核可能仍然保留着对数据结构的引用,因此需要通知内核这些文件已被删除。删除文件系统创建的文件的算法如下:
-
选择
inode要删除的项; -
查找所有指向
dentry此页面的硬链接( )inode; -
dentry我们从本地存储中删除找到的每一个文件; -
对于每个已删除的项。
在步骤 4 之后不要删除它inode,它可能仍在被打开的文件使用。Inode当操作系统发送完所有 FORGET 请求后,它将被异步删除。
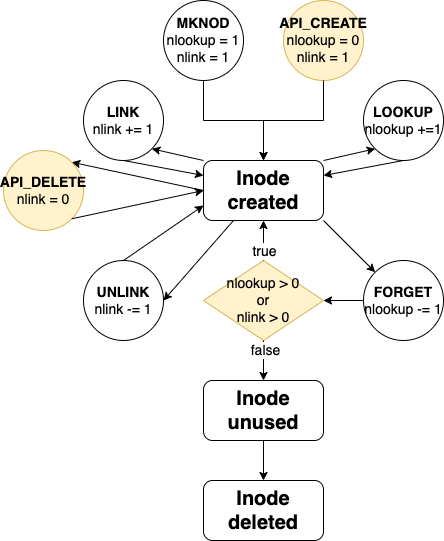
考虑到文件系统发起的 API 操作的生命周期inode,与一般生命周期的区别用黄色标记。
如何检测文件何时完成
网络文件系统会将文件内容与服务器同步。我的文件系统会在用户完成文件操作后,将所有更改合并到一个请求中发送给服务器。这种方法可以将多个write()操作的结果合并到一个网络请求中。
检测文件操作结束的一种方法是监视其关闭过程。在 FUSE 中,关闭文件分为两个请求:flush()和release()。让我们仔细看看。
FLUSH 函数会在每次文件描述符关闭时调用。文件描述符可以被复制,因此一次open()调用可能会导致多次调用flush(),例如,当一个进程打开一个文件并创建子进程时。调用close()时,操作系统会同步调用它,这样如果文件保存到服务器失败,操作系统就可以返回错误。而且,这个请求与glibc 的fflush() 函数flush()完全无关。
RELEASE 函数会在最后一个文件描述符关闭时调用一次。此调用用于删除文件描述符,也称为文件描述符。更多信息,请参阅"文件系统数据结构file"章节。始终只有一个文件描述符。虽然 API允许您返回错误,但调用 RELEASE 函数时不会返回错误。此外,在我的情况下,尝试从处理程序返回错误会导致与操作系统内核交互时出现错误。最好仅在使用有状态 I/O 时(例如文件析构函数)使用此调用。open()release()release()close()release()
我使用了一个处理程序flush()来检测文件何时处理完毕。文档中对它的描述有些吓人:
文件系统不应该假定在某些写入操作后总会调用 flush 函数,或者总会调用 flush 函数。
就我而言,客户端保证不会使用 filename mmap(),所以我将 FLUSH 视为文件处理的结束,并在处理程序中将文件保存到服务器flush()。重复调用flush()仍然可能发生,但再次更新服务器上的文件并不会造成太大问题。您可以在文件发生更改时标记 inode,并仅在文件内容发生变化时才更新服务器上的文件。