博主介绍:java高级开发,从事互联网行业六年,熟悉各种主流语言,精通java、python、php、爬虫、web开发,已经做了多年的设计程序开发,开发过上千套设计程序,没有什么华丽的语言,只有实实在在的写点程序。
🍅文末点击卡片获取联系🍅
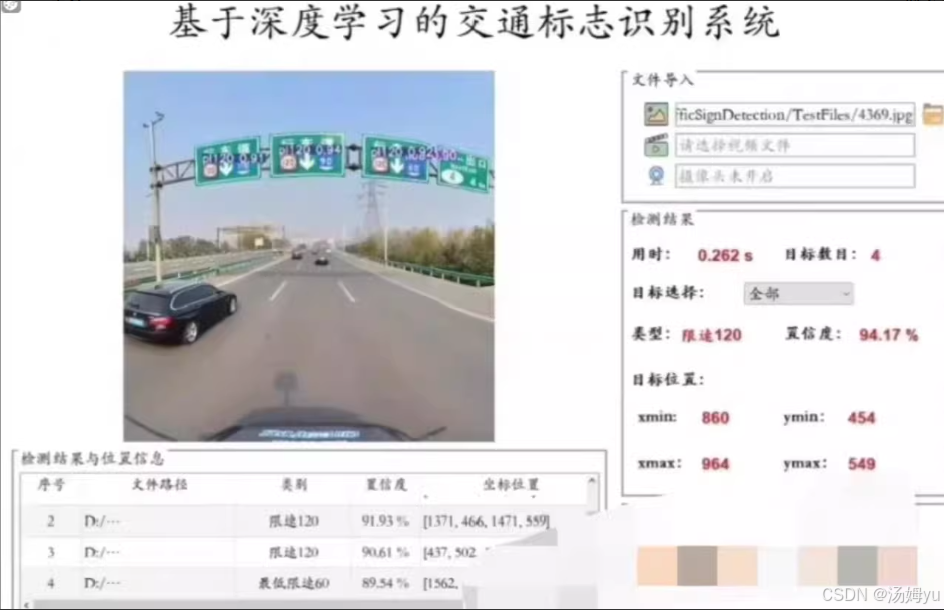
技术:python+yolov8
1、研究背景
随着城市化进程的加速与汽车保有量的持续攀升,道路交通流量急剧增长,交通标志作为保障道路交通安全、规范交通秩序的关键信息载体,其准确识别对于驾驶者做出正确驾驶决策、避免交通事故至关重要。然而,传统交通标志识别方法多依赖人工特征提取与简单分类算法,在复杂多变的实际交通场景中,如光照变化强烈(强光直射、夜间昏暗)、天气条件恶劣(暴雨、浓雾、大雪)、标志遮挡(被树木、车辆部分遮挡)以及视角倾斜(因拍摄角度导致标志变形)等情况下,识别准确率大幅下降,难以满足智能交通系统对高效、精准识别的需求。与此同时,深度学习技术凭借其强大的自动特征学习能力与层次化特征表示优势,在计算机视觉领域取得了突破性进展,能够从海量数据中自动学习到交通标志的深层次特征,有效应对复杂场景下的识别挑战。尤其是卷积神经网络(CNN)及其衍生模型,通过堆叠卷积层、池化层等结构,可逐步提取交通标志的边缘、纹理、形状等特征,显著提升识别精度与鲁棒性。在此背景下,基于深度学习的交通标志识别系统应运而生,其旨在利用先进的深度学习算法,实现对交通标志的高效、准确、实时识别,为智能交通系统的发展提供关键技术支撑,助力提升道路交通安全水平与交通管理效率。
2、研究意义
在交通领域不断智能化发展的当下,基于深度学习的交通标志识别系统具有多方面至关重要的研究意义。从交通安全层面来看,交通标志是引导车辆安全行驶、规范交通秩序的关键指引。准确且及时的交通标志识别能帮助驾驶员提前了解路况信息,如限速、禁止通行、前方施工等,从而做出正确的驾驶决策,有效避免因忽视交通标志而引发的超速、违规变道、闯入危险区域等危险行为,大大降低交通事故的发生概率,保障驾乘人员以及其他道路使用者的生命财产安全。在智能交通系统建设方面,该系统是其中的核心组成部分。它能够与自动驾驶、智能导航等系统深度融合,为车辆提供精准的环境感知信息。自动驾驶汽车依靠它准确识别交通标志,以实现自动调整车速、规划行驶路线等操作;智能导航系统结合其识别结果,能为用户提供更精准、贴合实际路况的导航指引,提升出行效率与体验,推动智能交通系统向更高水平发展。从技术发展角度而言,研究基于深度学习的交通标志识别系统,有助于推动深度学习技术在交通领域的创新应用与拓展。通过不断优化算法模型,提升系统在复杂场景下的识别准确率与鲁棒性,能为其他类似的目标识别任务提供宝贵经验与技术借鉴,促进计算机视觉、人工智能等学科在交通领域的交叉融合,推动整个交通行业的技术革新与进步。
3、研究现状
技术演进:从传统方法到深度学习主导
早期研究主要依赖传统图像处理技术,如颜色分割(HSV/RGB空间转换)、形状分析(霍夫变换检测圆形/三角形)及手工特征提取(HOG、SIFT),但这类方法在复杂场景(如光照突变、遮挡、形变)下鲁棒性不足。2012年AlexNet在ImageNet竞赛中突破后,深度学习成为主流。卷积神经网络(CNN)通过自动学习多层次特征,显著提升识别精度。例如,ResNet-50在GTSRB数据集上达到99.2%的准确率,较传统方法提升超20个百分点。YOLO系列算法(如YOLOv8)进一步优化实时性,通过无锚框机制、多尺度特征融合等技术,在保持高精度的同时实现视频流实时处理(NVIDIA RTX 3060环境下达35FPS以上)。
应用落地:自动驾驶与智能交通双轮驱动
技术成果已广泛渗透至自动驾驶与智能交通领域。特斯拉、Waymo等企业将交通标志识别集成至自动驾驶系统,实现限速、禁行等标志的实时感知与决策支持;欧洲多国交通管理部门利用该技术进行道路巡检,自动识别损坏或遮挡标志,提升维护效率;国内华为、百度等企业通过Apollo平台部署相关功能,结合高精度地图与V2X通信,优化交通流量控制与预警系统。
4、研究技术
YOLOv8介绍
YOLOv8是Ultralytics公司于2023年发布的YOLO系列最新目标检测模型,在继承前代高速度与高精度优势的基础上,通过多项技术创新显著提升了性能与灵活性。其核心改进包括:采用C2f模块优化骨干网络,增强多尺度特征提取能力并降低计算量;引入Anchor-Free检测头,简化推理步骤,提升小目标检测精度;使用解耦头结构分离分类与回归任务,优化特征表示;结合VFL Loss、DFL Loss和CIOU Loss改进损失函数,平衡正负样本学习效率。此外,YOLOv8支持多尺度模型(Nano、Small、Medium、Large、Extra Large),适应不同硬件平台需求,并扩展了实例分割、姿态估计等任务能力。在COCO数据集上,YOLOv8n模型mAP达37.3,A100 TensorRT上推理速度仅0.99毫秒,展现了卓越的实时检测性能。其开源库"ultralytics"不仅支持YOLO系列,还兼容分类、分割等任务,为计算机视觉应用提供了高效、灵活的一体化框架。
Python介绍
Python是一种高级、解释型编程语言,以其简洁易读的语法和强大的生态系统成为数据科学、人工智能及通用编程领域的首选工具。在深度学习领域,Python凭借丰富的库支持(如PyTorch、TensorFlow、OpenCV)和活跃的社区,成为YOLOv8等模型开发的核心语言。通过Python,开发者可快速实现模型训练、推理及部署:使用ultralytics库直接加载YOLOv8预训练模型,通过几行代码完成图像或视频的目标检测;结合NumPy、Matplotlib进行数据预处理与可视化;利用ONNX Runtime或TensorRT优化模型推理速度,实现跨平台部署。Python的跨平台特性(支持Windows、Linux、macOS)和丰富的第三方工具链,进一步降低了深度学习应用的开发门槛。无论是学术研究还是工业落地,Python均以其高效、灵活的特点,为YOLOv8等先进模型的实践提供了强有力的支持。
数据集标注过程
数据集标注是构建基于 YOLOv8 的垃圾分类检测系统至关重要的一环,精准的标注能确保模型学习到有效的特征,提升检测性能。以下是详细的数据集标注过程:
前期准备
首先,收集大量包含各类垃圾的图像,来源可以是实际场景拍摄、网络资源等,确保图像涵盖不同角度、光照条件和背景,以增强模型的泛化能力。接着,根据垃圾分类标准确定标注类别,如可回收物、有害垃圾、厨余垃圾和其他垃圾等。同时,选择合适的标注工具,如 LabelImg、CVAT 等,这些工具支持 YOLO 格式标注,能方便地生成模型训练所需的标签文件。
标注实施
打开标注工具并导入图像,使用矩形框精确框选图像中的每个垃圾目标。在框选时,要保证矩形框紧密贴合目标,避免包含过多无关背景信息,也不能遗漏目标部分。框选完成后,为每个矩形框分配对应的类别标签,确保标签准确无误。对于遮挡、重叠的垃圾目标,需仔细判断其类别和边界,尽可能完整标注。每标注完一张图像,及时保存标注文件,通常为与图像同名的.txt 文件,文件中记录了矩形框的坐标和类别信息。
质量审核
完成初步标注后,进行严格的质量审核。检查标注的准确性,查看是否存在错标、漏标情况,以及矩形框的坐标和类别是否正确。同时,检查标注的一致性,确保同一类垃圾在不同图像中的标注风格和标准统一。对于审核中发现的问题,及时修正,保证数据集的高质量,为后续 YOLOv8 模型的训练提供可靠的数据支持。
5、系统实现