
在当今数据驱动的世界中,Python 已成为数据处理和分析的强大工具。我们经常需要将程序中处理好的数据,特别是以列表形式组织的数据,导出到 Excel 文件中,以便于共享、可视化或进一步分析。然而,如何高效、灵活地将这些列表数据写入 Excel,并确保格式的准确性和美观性,是许多开发者面临的痛点。
Python 生态系统为此提供了多种解决方案,从内置的 CSV 模块到第三方库,各有千秋。本文将深入探讨如何利用 Spire.XLS for Python 库,一个功能强大且易于使用的 Excel 处理库,来优雅地解决这一问题。它不仅能满足基础的数据写入需求,更能应对复杂的格式化和大规模数据处理场景,帮助您轻松实现数据自动化和报表生成。
环境配置
Spire.XLS for Python 是一个专业的 Python Excel 库,专为创建、读取、编辑、转换和打印 Excel 文件而设计。它的核心优势在于无需依赖 Microsoft Office 即可独立运行,支持 .xls、.xlsx、.xlsm、.xlt 等多种 Excel 文件格式。对于开发者而言,这意味着在服务器端部署时无需额外安装 Office 软件,大大降低了部署成本和复杂性。
该库提供了丰富的 API 接口,可以操作 Excel 的各种元素,包括工作簿、工作表、单元格、格式、图表、公式、批注等。在将列表数据写入 Excel 的场景中,Spire.XLS for Python 能够让您灵活控制数据的写入位置、样式,并支持多种数据类型的自动转换,从而实现高度定制化的 Excel 输出。
安装指南:
在开始之前,请确保您的 Python 环境已安装 Spire.XLS for Python。您可以通过 pip 命令轻松安装:
bash
pip install Spire.XLS安装完成后,您就可以在 Python 项目中导入并使用它了。
从列表到Excel:基础数据写入实践
首先,我们来看一个最基础的场景:将一个简单的列表数据写入 Excel 文件。假设我们有一个包含学生姓名和分数的列表。
场景设定:
我们有一个这样的列表,其中每个子列表代表一行数据:
python
data = [
["部门", "预算金额(元)", "实际支出(元)", "差额"],
["市场部", 80000, 76500, -3500],
["技术部", 150000, 162300, 12300],
["行政部", 50000, 48200, -1800]
]代码示例:
python
from spire.xls import *
from spire.xls.common import *
def write_simple_list_to_excel(data_list, file_path="simple_data.xlsx"):
"""
将简单的列表数据写入Excel文件。
:param data_list: 包含数据的列表,每个子列表代表一行。
:param file_path: 输出Excel文件的路径。
"""
# 创建一个工作簿对象
workbook = Workbook()
# 获取第一个工作表
sheet = workbook.Worksheets[0]
# 遍历列表数据,并写入工作表
for row_idx, row_data in enumerate(data_list):
for col_idx, cell_value in enumerate(row_data):
# 将列表中的值赋给对应的单元格
sheet.Range[row_idx + 1, col_idx + 1].Value = str(cell_value) # spire.xls 默认接受字符串或数字
# 保存工作簿到指定文件
workbook.SaveToFile(file_path, FileFormat.Version2016) # 保存为xlsx格式
workbook.Dispose() # 释放资源
print(f"数据已成功写入:{file_path}")
# 调用函数
write_simple_list_to_excel(data)写入效果预览:
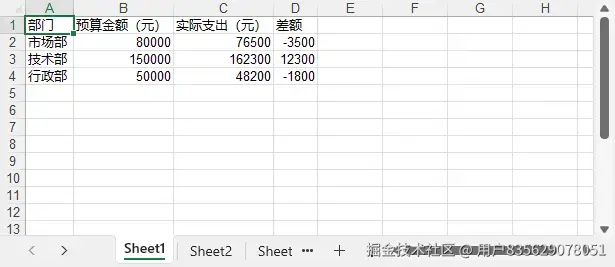
关键步骤解释:
Workbook(): 创建一个新的 Excel 工作簿实例。workbook.Worksheets[0]: 获取工作簿中的第一个工作表(默认创建)。sheet.Range[row_idx + 1, col_idx + 1].Value = str(cell_value): 这是核心的写入操作。Range对象代表一个或一组单元格。Range[row, column]使用基于 1 的索引来指定单元格位置。我们将列表中的每个元素cell_value赋给对应的单元格的Value属性。为了通用性,这里将所有值转换为字符串,但spire.xls也能自动处理数字类型。workbook.SaveToFile(file_path, FileFormat.Version2016): 将修改后的工作簿保存到磁盘上的指定路径。FileFormat.Version2016表示保存为.xlsx格式。workbook.Dispose(): 释放工作簿对象占用的资源,这是一个良好的编程习惯,尤其是在处理大量文件时。
注意事项:
- 确保
file_path指定的目录存在且有写入权限。 spire.xls的行和列索引都是从 1 开始,而不是 Python 列表的从 0 开始,这一点在row_idx + 1和col_idx + 1中体现。
深度定制:复杂数据结构与Excel格式化
在实际应用中,数据往往更复杂,并且对 Excel 的呈现效果有更高的要求,比如添加标题、设置样式、调整列宽等。
场景设定:
- 带标题的列表数据: 假设我们希望列表的第一行作为 Excel 的标题行,并对其进行加粗、设置背景色。
- 多维列表: 如果列表数据包含日期或其他特殊类型,我们也希望它们能够正确显示。
代码示例:
python
from spire.xls import *
import datetime
def write_advanced_list_to_excel(data_list, file_path="advanced_data.xlsx"):
"""
将包含标题和复杂数据类型的列表写入Excel,并进行格式化。
:param data_list: 包含数据的列表,第一行是标题。
:param file_path: 输出Excel文件的路径。
"""
workbook = Workbook()
sheet = workbook.Worksheets[0]
# 写入标题行并设置样式
header_data = data_list[0]
for col_idx, header_text in enumerate(header_data):
header_cell = sheet.Range[1, col_idx + 1]
header_cell.Value = header_text
# 设置字体加粗
header_cell.Style.Font.IsBold = True
# 设置背景色 (RGB颜色)
header_cell.Style.KnownColor = ExcelColors.LightYellow
# 居中对齐
header_cell.Style.HorizontalAlignment = HorizontalAlignType.Center
# 写入数据行
for row_idx, row_data in enumerate(data_list[1:]): # 从第二行开始遍历数据
for col_idx, cell_value in enumerate(row_data):
current_cell = sheet.Range[row_idx + 2, col_idx + 1] # 数据从第二行开始写
if isinstance(cell_value, datetime.date):
current_cell.DateTimeValue = DateTime.Parse(str(cell_value)) # 写入日期/时间对象
current_cell.Style.NumberFormat = "yyyy-mm-dd" # 设置日期格式
if isinstance(cell_value, datetime.datetime):
current_cell.DateTimeValue = DateTime.Parse(str(cell_value))
current_cell.Style.NumberFormat = "yyyy-mm-dd hh:mm"
else:
current_cell.Value = str(cell_value)
# 自动调整列宽以适应内容
sheet.AutoFitColumn(1) # 自动调整第一列
sheet.AutoFitColumn(2) # 自动调整第二列
sheet.AutoFitColumn(3) # 自动调整第三列
sheet.AutoFitColumn(4) # 自动调整第四列
# 保存文件
workbook.SaveToFile(file_path, FileFormat.Version2016)
workbook.Dispose()
print(f"高级数据已成功写入:{file_path}")
# 示例数据,包含日期
advanced_data = [
["订单编号", "客户名称", "订单金额(元)", "下单时间"],
["SO-20231026001", "深圳智联科技", 32800, datetime.date(2023, 10, 26)],
["SO-20231025002", "北京锐达信息", 15600, datetime.datetime(2023, 10, 25, 14, 30)],
["SO-20231027003", "上海启明系统", 48900, datetime.date(2023, 10, 27)],
["SO-20231028004", "杭州云创数据", 21450, datetime.datetime(2023, 10, 28, 9, 15)]
]
write_advanced_list_to_excel(advanced_data)写入效果预览:
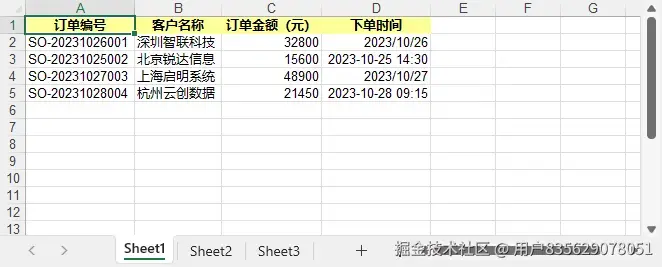
关键特性:
CellStyle: 通过cell.Style属性,您可以访问单元格的样式对象,进而设置字体、颜色、对齐方式、边框等。header_cell.Style.Font.IsBold = True:设置字体加粗。header_cell.Style.KnownColor = ExcelColors.LightYellow:设置背景色。ExcelColors枚举提供了多种预定义的颜色。header_cell.Style.HorizontalAlignment = HorizontalAlignType.Center:设置水平居中对齐。
DateTimeValue与NumberFormat: 对于日期和时间对象,直接赋值给cell.DateTimeValue属性,并使用cell.Style.NumberFormat设置显示格式,Excel 会自动识别并正确显示。sheet.AutoFitColumn(column_index): 自动调整指定列的宽度,使其内容完全显示,避免了手动调整的麻烦,尤其对于动态数据非常有用。
稳健之道:错误处理与写入优化建议
在实际的数据处理流程中,错误处理和性能优化同样重要,它们决定了程序的健壮性和效率。
常见错误及其解决方案:
- 文件路径错误/权限问题 :
- 错误 :
FileNotFoundError或PermissionError。 - 解决方案 : 确保目标文件夹存在,并且程序有权限在该文件夹下创建或修改文件。可以使用
os.makedirs()创建不存在的目录。
- 错误 :
- 数据类型不匹配 :
- 错误: 写入 Excel 时出现非预期的数据格式。
- 解决方案 :
spire.xls会尝试自动转换数据类型,但对于特殊类型(如datetime对象),最好使用其特定的属性(如DateTimeValue)进行赋值,并配合NumberFormat设置显示格式。
- 内存溢出 (大规模数据) :
- 错误: 处理超大型数据集时,程序可能因为内存不足而崩溃。
- 解决方案 :
spire.xls内部对内存使用进行了优化,但如果数据量极其庞大(例如数百万行),可以考虑分批写入,或者优化数据结构,避免一次性加载所有数据到内存。
try-except-finally 结构:
在文件操作中,使用 try-except-finally 结构是最佳实践,可以确保即使发生错误,资源也能被正确释放。
python
try:
workbook = Workbook()
# ... 进行Excel操作 ...
workbook.SaveToFile(file_path, FileFormat.Version2016)
except Exception as e:
print(f"写入Excel文件时发生错误: {e}")
finally:
if 'workbook' in locals() and workbook is not None:
workbook.Dispose() # 确保在任何情况下都释放资源性能考量与优化:
对于大规模数据写入,以下建议可以帮助提升性能:
- 避免频繁保存: 尽量将所有数据写入操作完成后,一次性保存工作簿,而不是每写入一部分数据就保存一次。
- 批量操作 : 如果需要对大量单元格应用相同的样式,尽量使用
Range对象的一次性操作,而不是逐个单元格设置。例如,sheet.Range["A1:D1"].Style.Font.IsBold = True比循环设置每个单元格的样式效率更高。 - 数据预处理 : 在将数据传递给
spire.xls之前,尽可能完成所有的数据清洗、转换和格式化工作,减少在 Excel 库内部的计算量。 Dispose()的重要性 : 务必在操作完成后调用workbook.Dispose(),及时释放内存和文件句柄,防止资源泄露。
代码可读性与维护:
- 注释: 为复杂的逻辑或关键步骤添加清晰的注释。
- 函数化: 将不同的功能封装到独立的函数中,提高代码的模块化和可重用性。
- 变量命名: 使用有意义的变量名,增强代码的可读性。
结语
本文的介绍如何使用 Spire.XLS for Python 库将 Python 列表数据写入 Excel 文件。从基础的数据导入到复杂的格式化和样式设置,Spire.XLS for Python 都展现了其强大的功能和灵活的控制力。它不仅简化了数据导出的过程,更使得自动化报表生成、数据分析结果呈现等任务变得触手可及。
在数据处理和自动化日益普及的今天,掌握这样的工具无疑能极大地提升工作效率。进一步探索 Spire.XLS for Python 的更多高级功能,例如图表生成、公式计算、数据验证等,将其融入数据工作流,解锁更多自动化潜力。