FPGA教程系列-Vivado AXI4-Full 仿真测试
还是老一套,建一个AXI-Full的IP核,看看,过程就不再赘述了。
Slave仿真
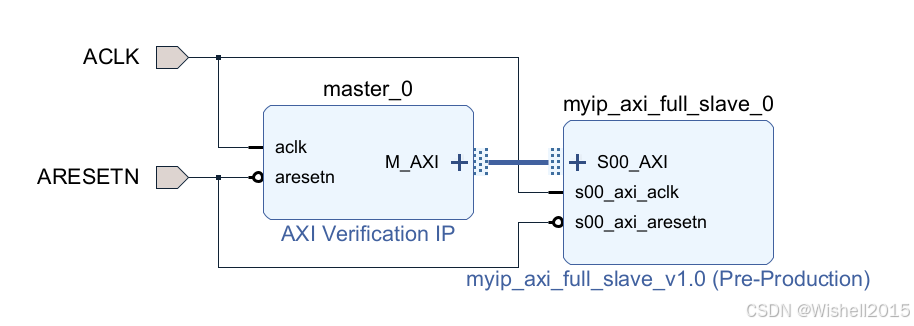
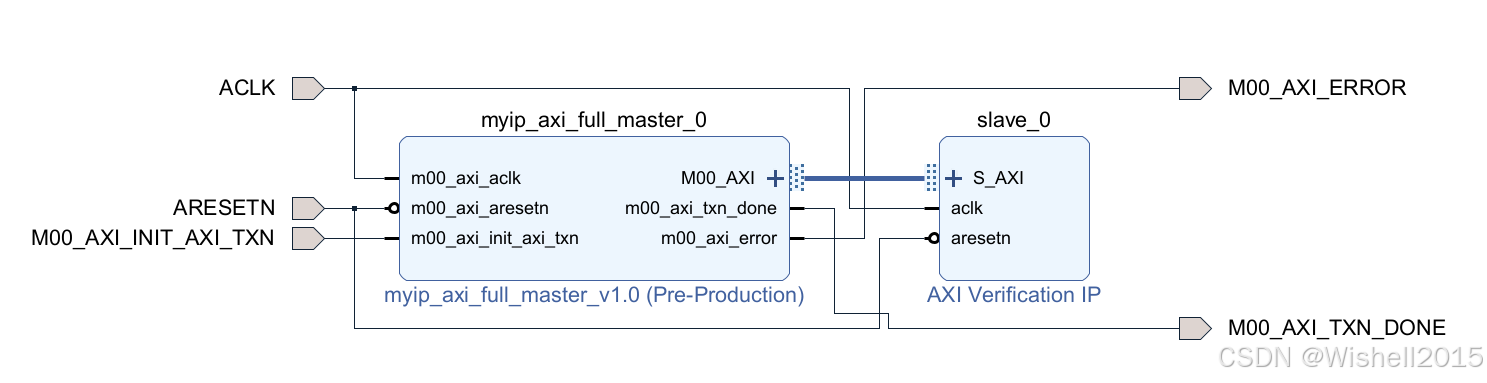
首先看框图
还是用AXI Verification进行验证,代码解释也略过,简单的看下仿真后的逻辑。
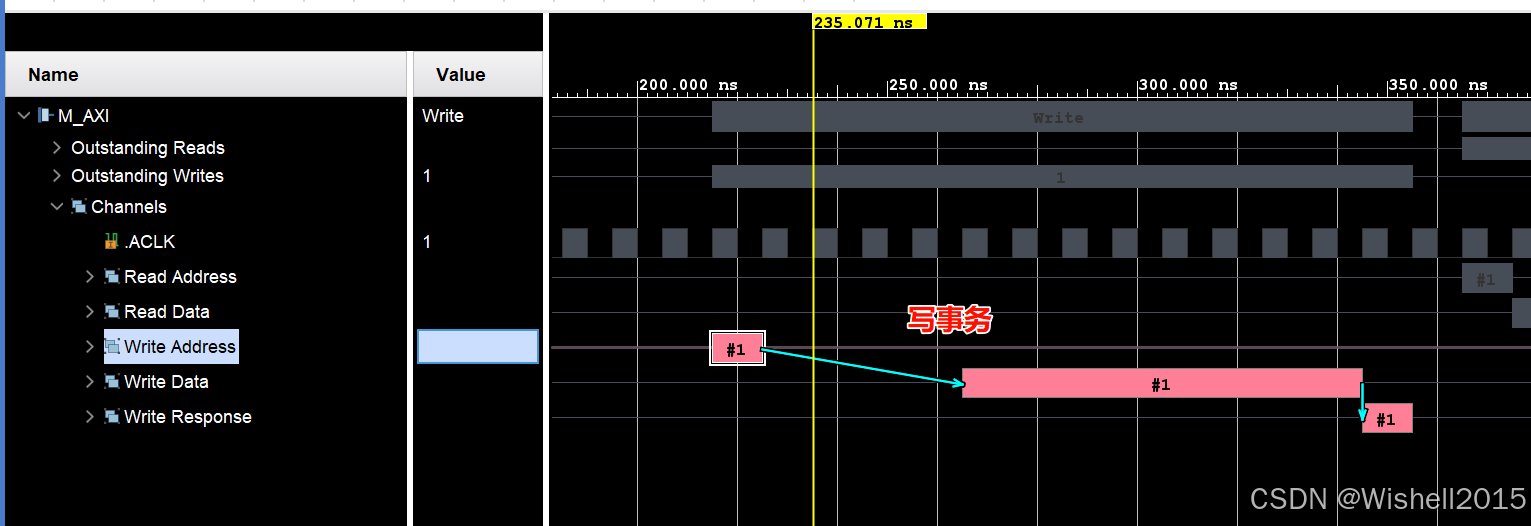
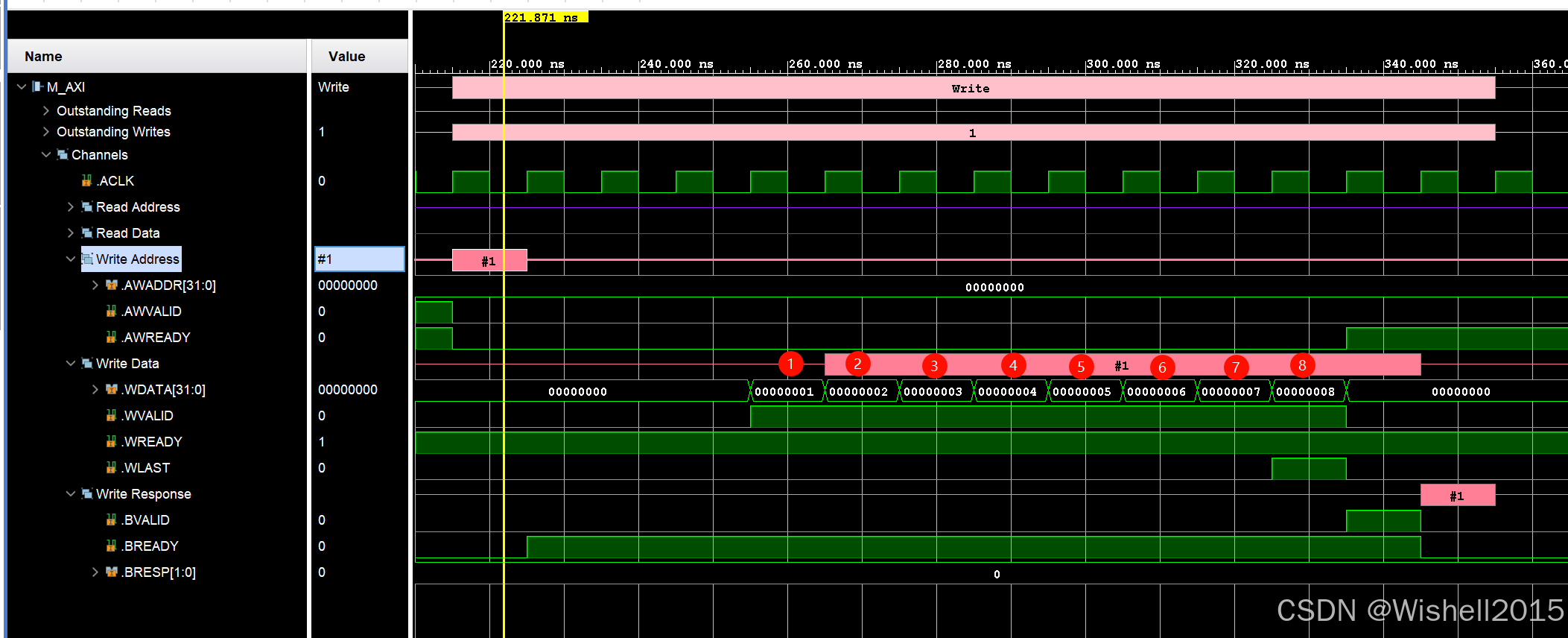
一次写事务
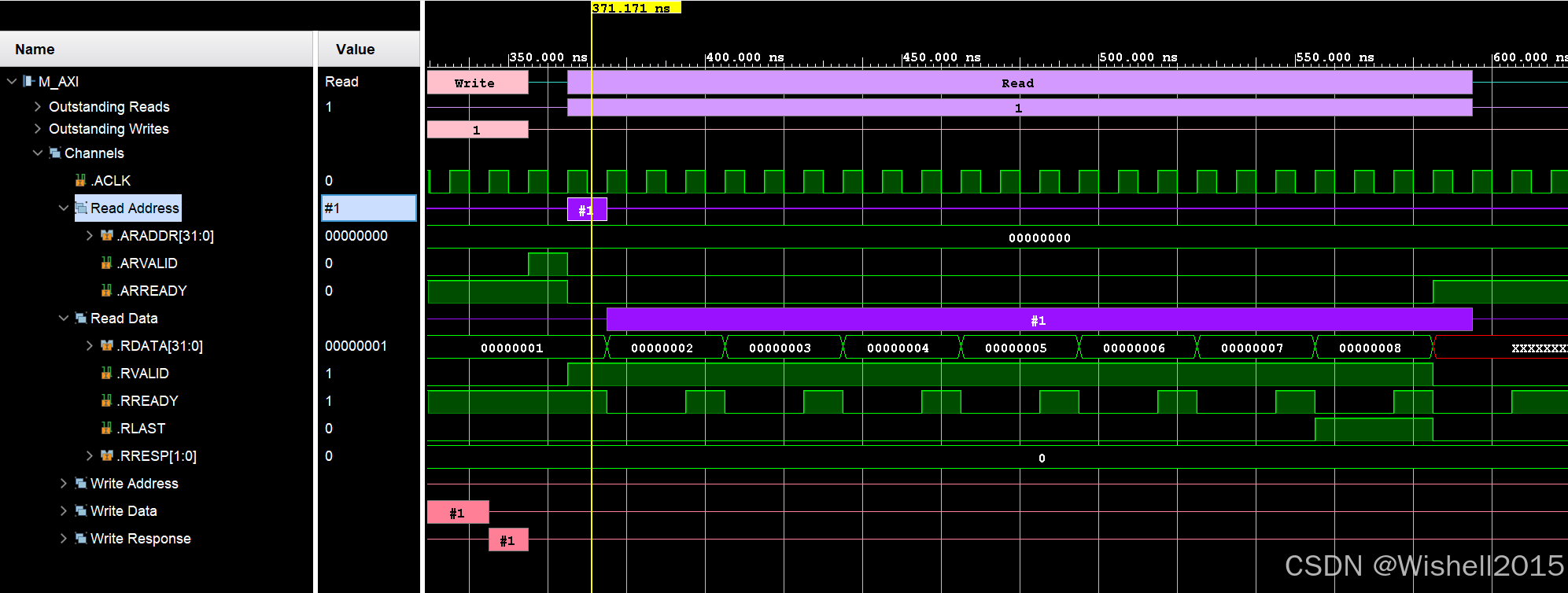
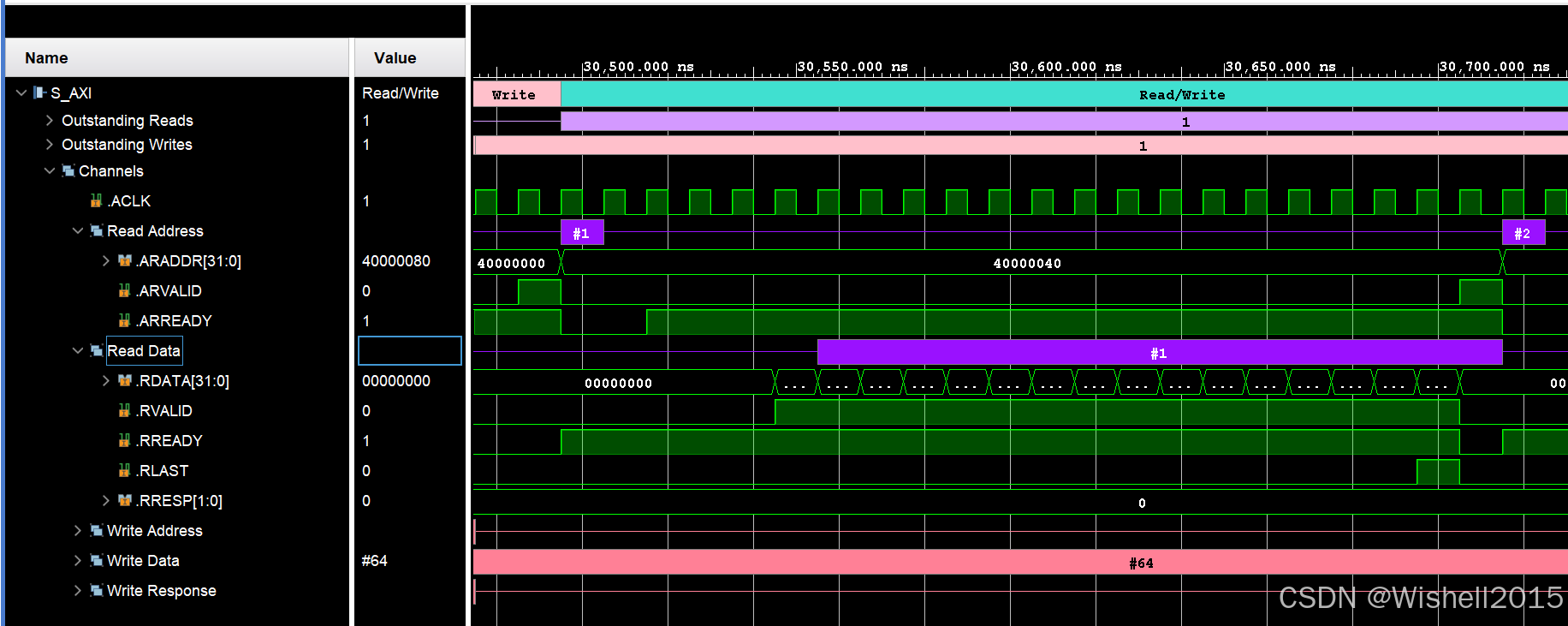
一次读事务
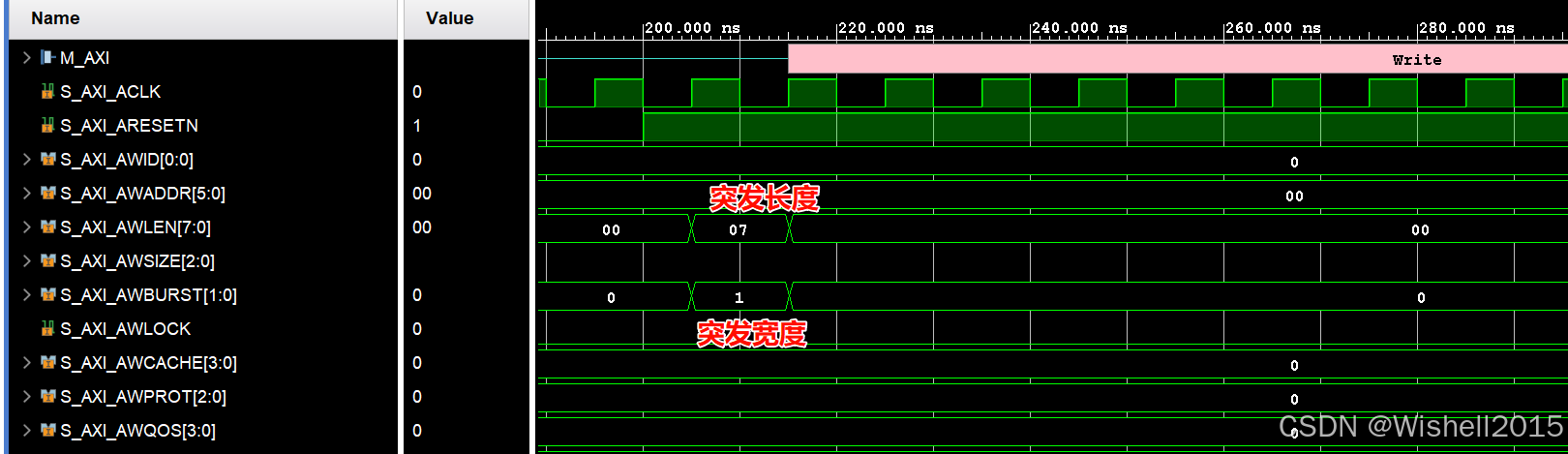
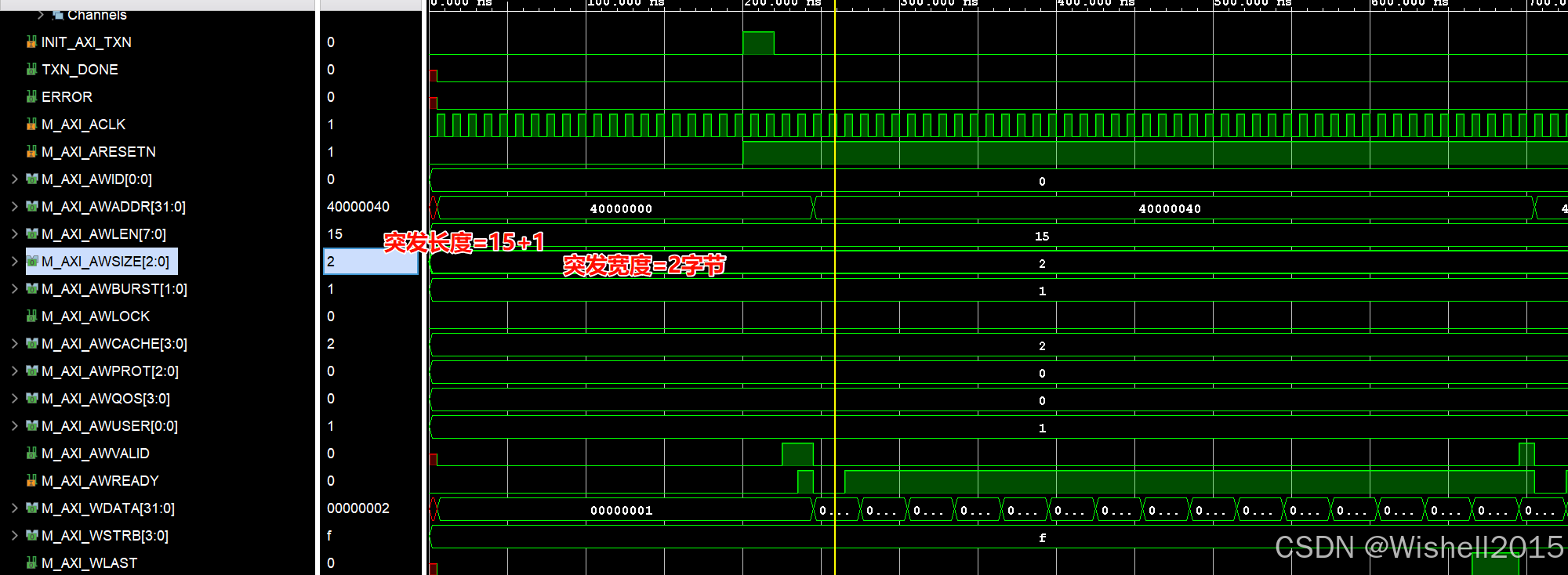
去slave中查看,可以看到突发长度与突发宽度,再深刻的理解一下:
- 传输次数 (Beats) =
AWLEN+ 1 - 每次传输宽度 (Bytes/Beat) = 2AWSIZE2^{\text{AWSIZE}}2AWSIZE
情况 1:AWLEN = 7, AWSIZE = 1
这是一个 "细长型" 的传输。
-
传输次数 (Beats): 7+1=87 + 1 = \mathbf{8}7+1=8 次。
Master 会在写数据通道上进行 8 次握手(
WVALID &WREADY)。 -
单次宽度 (Width): 21=22^1 = \mathbf{2}21=2 字节 (即 16-bit)。
这意味着你的数据总线只需要 16 根线(或者你只用了其中的 16 根)。
-
总数据量 (Total Data):
8 (beats)×2 (bytes)=16 Bytes 8 \text{ (beats)} \times 2 \text{ (bytes)} = \mathbf{16 \text{ Bytes}} 8 (beats)×2 (bytes)=16 Bytes
-
地址变化 (INCR模式):
每传一次,地址增加 2。
例如:
0x00 ->0x02 ->0x04 ... ->0x0E。
这就好比用一辆小三轮车(只能装 2 字节),往返跑了 8 趟。
情况 2:AWLEN = 1, AWSIZE = 7
这是一个 "短宽型" (或者说是巨型)的传输。
-
传输次数 (Beats): 1+1=21 + 1 = \mathbf{2}1+1=2 次。
Master 只需要在数据通道上进行 2 次握手。
-
单次宽度 (Width): 27=1282^7 = \mathbf{128}27=128 字节 (即 1024-bit)。
注意! 这是一个非常恐怖的宽度。通常只有高性能计算(HPC)、GPU 内部或者 HBM(高带宽内存)接口才会有 1024 位宽的数据总线。普通 CPU 总线通常只是 32位 (SIZE=2) 或 64位 (SIZE=3)。
-
总数据量 (Total Data):
2 (beats)×128 (bytes)=256 Bytes 2 \text{ (beats)} \times 128 \text{ (bytes)} = \mathbf{256 \text{ Bytes}} 2 (beats)×128 (bytes)=256 Bytes
-
地址变化 (INCR模式):
每传一次,地址增加 128。
例如:
0x00 ->0x80。
这就好比开着一辆巨型重卡(能装 128 字节),跑了 2 趟。
Master
框图如下:
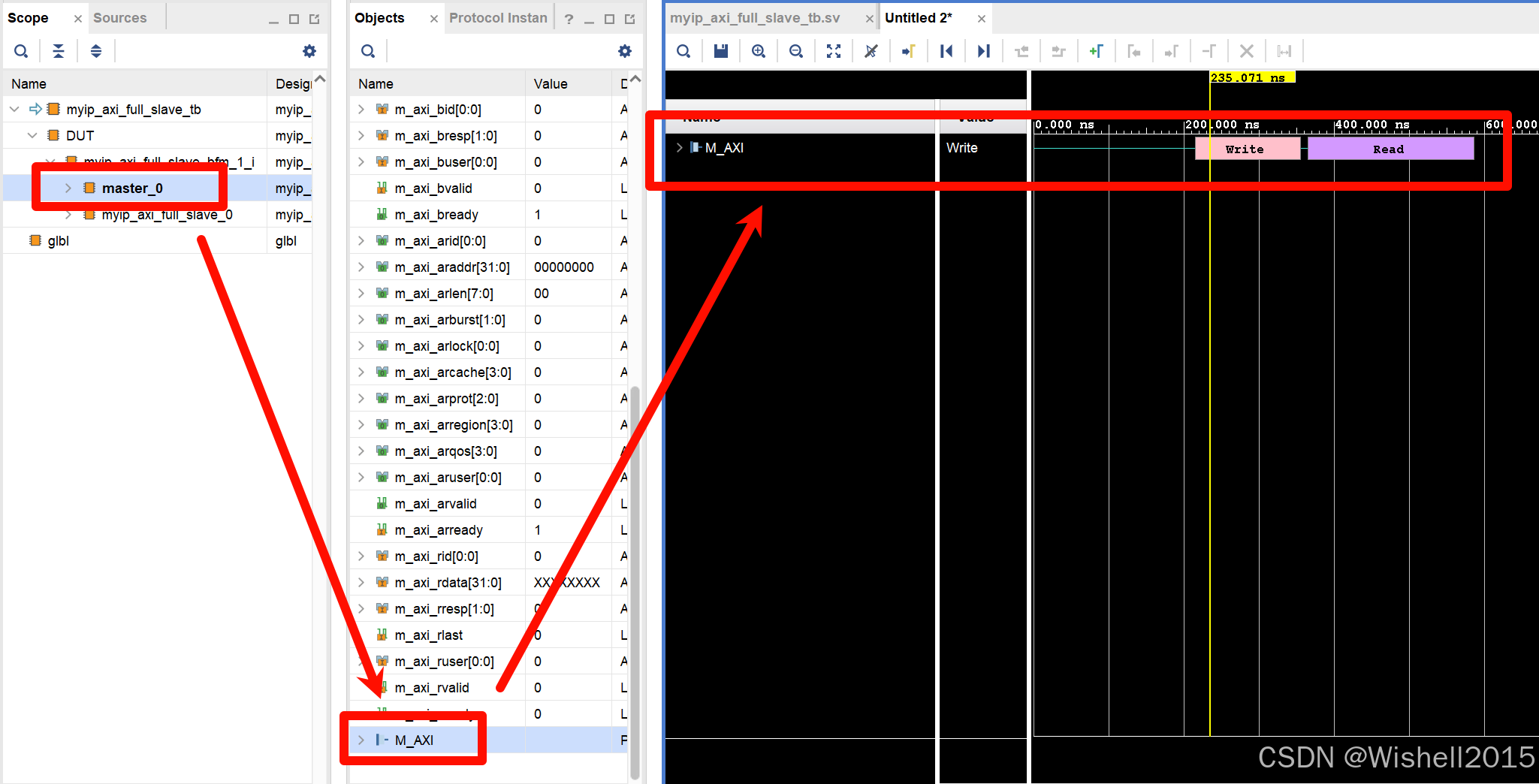
发现拿AXI Verification去看对应的读写操作会比直接看ip核更直观一点。
写了一次的事务:
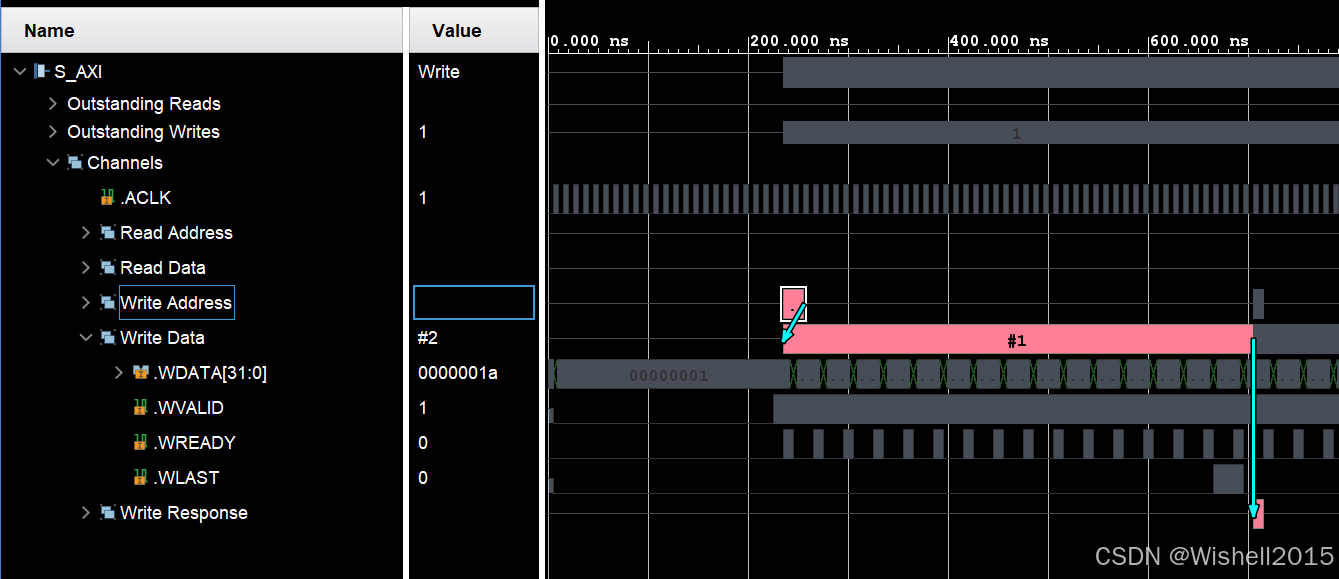
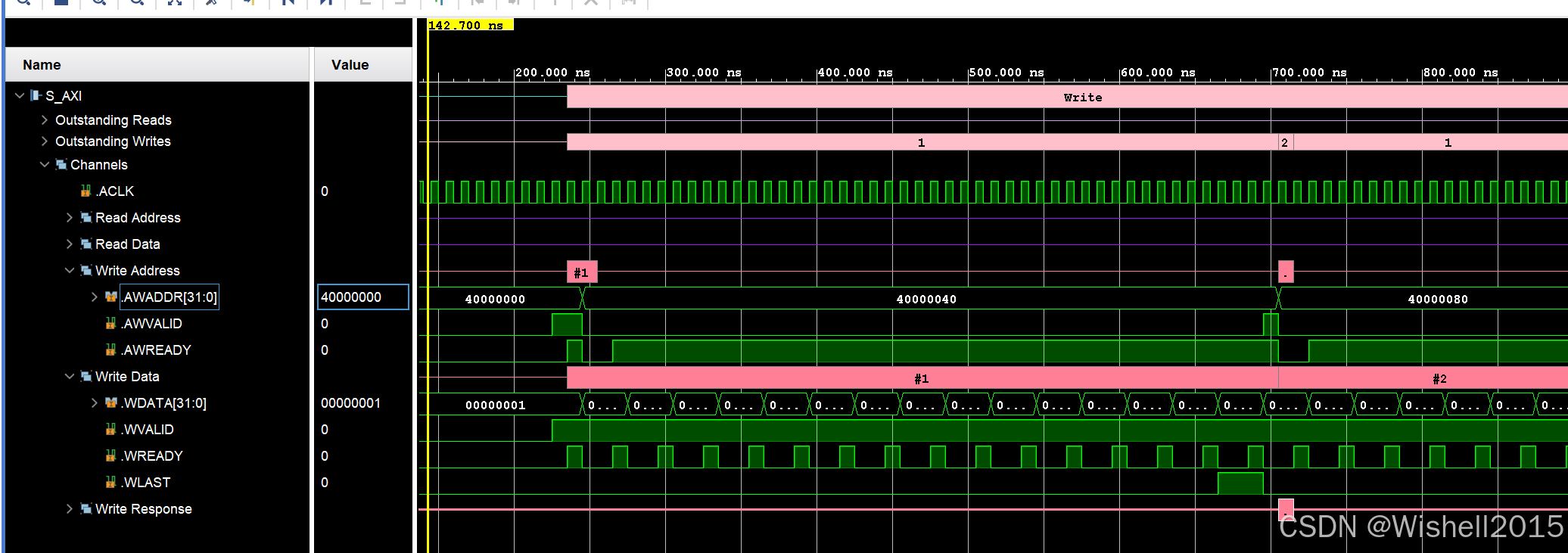
一次事务内,握手了16次,一次2字节,可以看到第二次事务,地址从40000040开始。
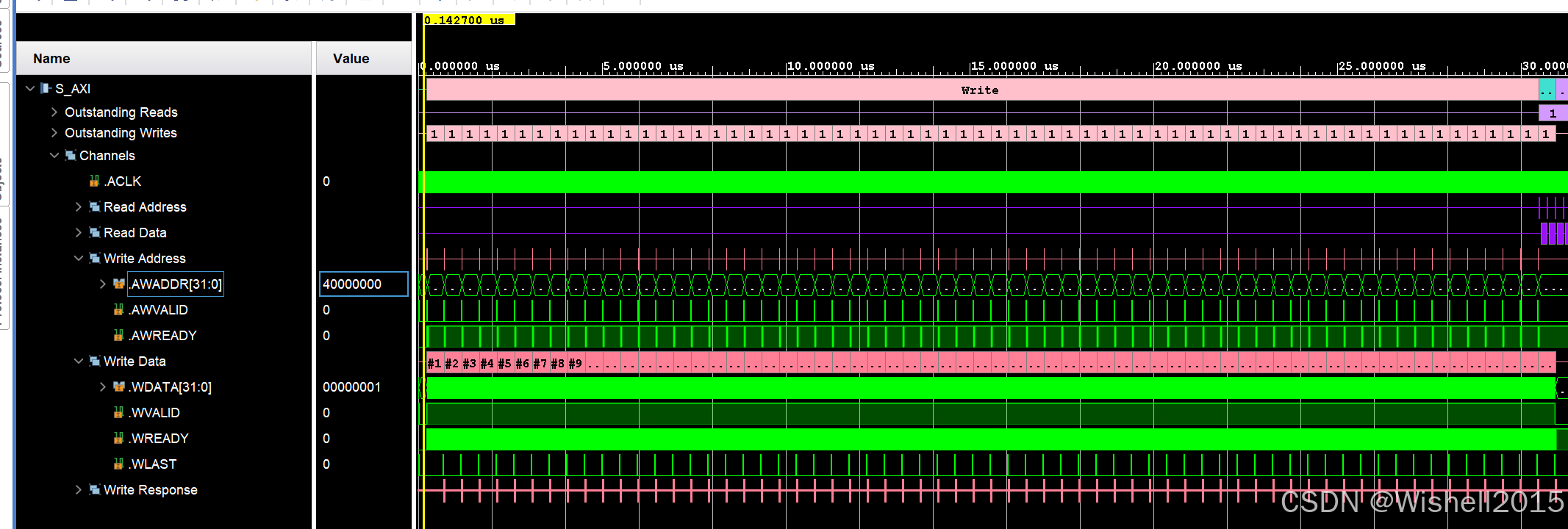
一共写了64次:
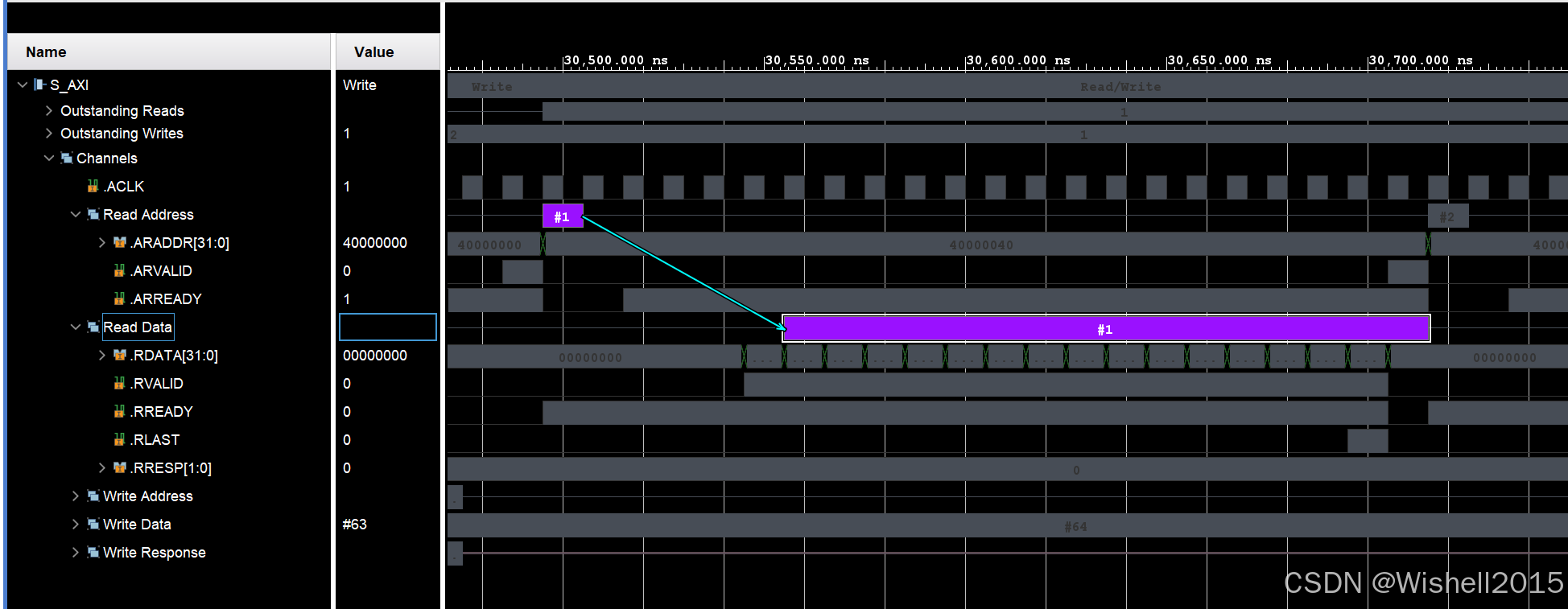
读也一样,可以看到一次事务只有两个步骤。
打开主的仿真,主要看下突发是否对应: