
总结:简而言之:InfiniteTalk 是一款无限时长的有声视频生成模型,支持音频驱动的视频对视频和图像到视频生成
🚨 传统配音的"尴尬癌":嘴在动,脸僵住,肢体像被焊死
你是否见过这样的"诡异"视频:配音激情澎湃喊着"我中了700万",画面里的人却面无表情,只有嘴部机械开合?这就是困扰行业多年的"口型僵局"------传统技术如MuseTalk、LatentSync,只能修复嘴部区域,导致"情感割裂":
• ✅ 口型同步达标
• ❌ 面部表情僵硬(笑不出来的"假笑")
• ❌ 肢体动作脱节(激动时手都不抬)
更糟的是,新兴AI生成模型也掉链子:
• I2V模型(图像转视频):长视频生成到后期,人物脸歪、背景变色(累积误差)
• FL2V模型(首末帧引导):片段过渡像"卡壳",挥手动作突然"瞬移"(缺乏动量传递)

💡 美团InfiniteTalk:用"稀疏帧魔法"重构视频配音逻辑
美团视觉智能部研发的InfiniteTalk彻底颠覆规则!它把配音从"嘴部修复"升级为"全身电影级生成",核心突破在于:
1️⃣ 稀疏关键帧:给AI导演"分镜脚本"

不再逐帧修复,而是精选关键帧(如情绪高潮的手势、转头)作为锚点,让AI像导演一样,根据音频情感自由生成中间画面。
2️⃣ 流式生成+上下文帧:解决"断片"难题

•分段生成:超长视频拆成小片段(chunks)逐段处理
• 接力机制:用上一段结尾帧当"起跑器",确保动作连贯(如挥手自然衔接)
3️⃣ 软条件控制:平衡"自由"与"真实"
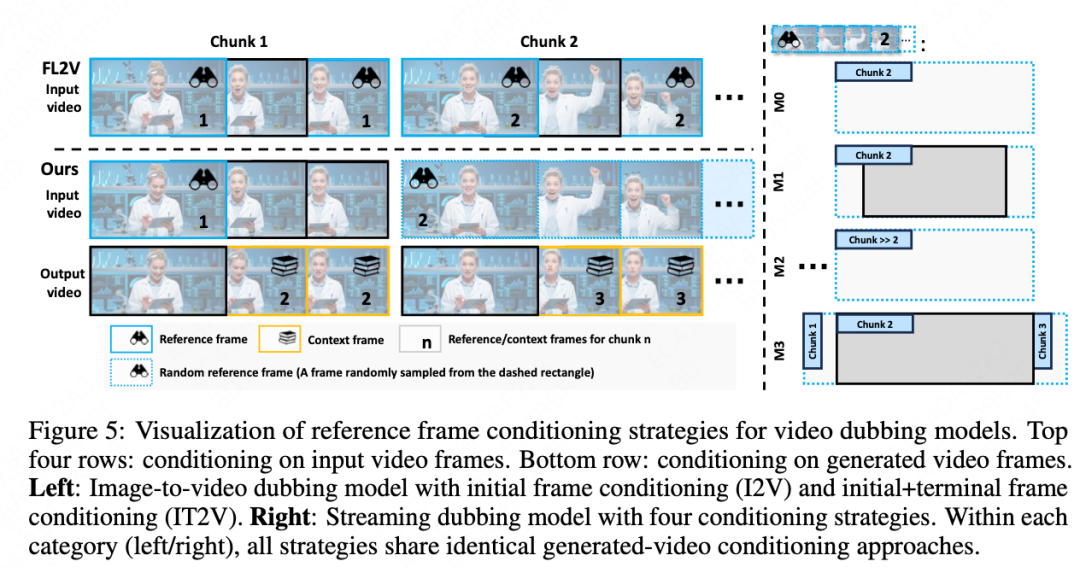
• 太严格参考原视频→动作僵硬(M1策略失败案例)
• 太放飞自我→人物变样(M2策略失败案例)
• M3最优解:动态调整控制强度,既保留源视频风格,又让AI自由发挥情感动作
✨ 效果炸裂:从"念稿子"到"飙演技"的跨越
看对比就懂多震撼!👇

核心指标碾压对手(HDTF数据集):
• Sync-C(情感同步):9.18(超MultiTalk 9.02)
• Sync-D(动作连贯):6.84(越低越好,领先FantacyTalking 10.80)
🔧 技术揭秘:两大黑科技模块
1. 音频-视觉双交叉注意力
• 音频特征(wav2vec提取)与视频帧深度绑定,确保"声音皱眉时,画面真皱眉"
2. 动态参考帧定位
• 智能选择邻近帧作为参考,避免"对着10秒前的动作硬套当前情绪"
🚀 美团的野心:不止配音,要重构虚拟人产业
这项技术已开源(论文+代码+权重),背后是美团视觉智能部的"全栈布局":
• 虚拟人基建:从基础生成模型到多模交互(直播、营销)
• 本地生活场景落地:商家低成本AI直播、智能客服虚拟人
• 技术护城河:人脸识别、商品图像分析等已成为公司基础设施
🎬 未来已来:这些场景即将被颠覆
• 短视频创作:一键给网红换配音,表情动作自动匹配
• 影视译制:国外大片配音不再"违和",演员表情随中文台词变化
• 虚拟主播:24小时直播带货,语气激动时自动挥手、前倾。
🌏本地部署方法以及相关报告
• 项目主页 :https://meigen-ai.github.io/InfiniteTalk/
• 开源代码 :https://github.com/MeiGen-AI/InfiniteTalk
• 技术报告 :https://arxiv.org/abs/2508.14033
🎞视频讲解:
http://【【教个知己-添亮】视频已打包,欢迎围观!】 https://www.bilibili.com/video/BV1r6v8BgE26/?share_source=copy_web