目录标题
- [一,进阶:基于 Session 的多轮对话实现(逐行拆解)](#一,进阶:基于 Session 的多轮对话实现(逐行拆解))
-
- [1. 为什么要引入"多轮对话"?](#1. 为什么要引入“多轮对话”?)
- [2. 这次改动的核心思路](#2. 这次改动的核心思路)
- [3. 新增 import:为"会话历史"做准备](#3. 新增 import:为“会话历史”做准备)
- [4. 全局 sessions:最简单的"会话存储"](#4. 全局 sessions:最简单的“会话存储”)
-
- 这段代码在干什么?
- [⚠️ 重要说明](#⚠️ 重要说明)
- [5. 请求体升级:引入 session_id](#5. 请求体升级:引入 session_id)
-
- [为什么 session_id 放在请求体?](#为什么 session_id 放在请求体?)
- 使用约定
- [6. 规范化 session_id(非常细但很重要)](#6. 规范化 session_id(非常细但很重要))
- [7. 获取 / 初始化会话历史](#7. 获取 / 初始化会话历史)
- [8. 把历史拼成"对话 Prompt"](#8. 把历史拼成“对话 Prompt”)
-
- 拼接后的真实效果
- [为什么不用 JSON / messages?](#为什么不用 JSON / messages?)
- [9. 拼接本轮问题(关键一步)](#9. 拼接本轮问题(关键一步))
- [10. 模型调用从"question"升级为"prompt"](#10. 模型调用从“question”升级为“prompt”)
- [11. 仅在有 session_id 时才记录历史](#11. 仅在有 session_id 时才记录历史)
- [12. 当前实现的边界与风险](#12. 当前实现的边界与风险)
-
- [12.1 内存问题](#12.1 内存问题)
- [12.2 并发与部署问题](#12.2 并发与部署问题)
- [13. 下一步可以怎么升级?(路线图)](#13. 下一步可以怎么升级?(路线图))
- [14. 小结](#14. 小结)
- [二,进阶:规则优先 + Tool 调用的 Agent 雏形实现(逐行拆解)](#二,进阶:规则优先 + Tool 调用的 Agent 雏形实现(逐行拆解))
-
- [1. 为什么要加「规则 + Tools」?](#1. 为什么要加「规则 + Tools」?)
- [2. 本次升级的整体设计思想](#2. 本次升级的整体设计思想)
- [3. 新增依赖与模块拆分](#3. 新增依赖与模块拆分)
-
- [3.1 新增 import](#3.1 新增 import)
-
- [为什么引入 `re`?](#为什么引入
re?) - [为什么单独建 `tools.py`?](#为什么单独建
tools.py?)
- [为什么引入 `re`?](#为什么引入
- [4. tools.py:工具模块逐行讲解](#4. tools.py:工具模块逐行讲解)
- [5. /ask 接口升级:规则优先处理](#5. /ask 接口升级:规则优先处理)
-
- [5.1 提前取出 question(很重要的细节)](#5.1 提前取出 question(很重要的细节))
- [6. 规则 1:时间 / 日期问题](#6. 规则 1:时间 / 日期问题)
- [7. 规则 2:数学表达式识别(正则)](#7. 规则 2:数学表达式识别(正则))
-
- 这个正则能匹配什么?
- 正则拆解说明
- [7.1 提取并计算](#7.1 提取并计算)
- [为什么这里直接 return?](#为什么这里直接 return?)
- [8. 未命中规则 → 交给 LLM(兜底)](#8. 未命中规则 → 交给 LLM(兜底))
-
- [此时 LLM 的角色](#此时 LLM 的角色)
- [9. 当前架构的本质:Mini Agent](#9. 当前架构的本质:Mini Agent)
- [10. 与 LangChain / OpenAI Tools 的关系](#10. 与 LangChain / OpenAI Tools 的关系)
- [11. 当前实现的边界](#11. 当前实现的边界)
-
- [11.1 规则不可扩展性](#11.1 规则不可扩展性)
- [11.2 没有"模型决定是否调用工具"](#11.2 没有“模型决定是否调用工具”)
- [12. 推荐升级路线](#12. 推荐升级路线)
- [13. 总结](#13. 总结)
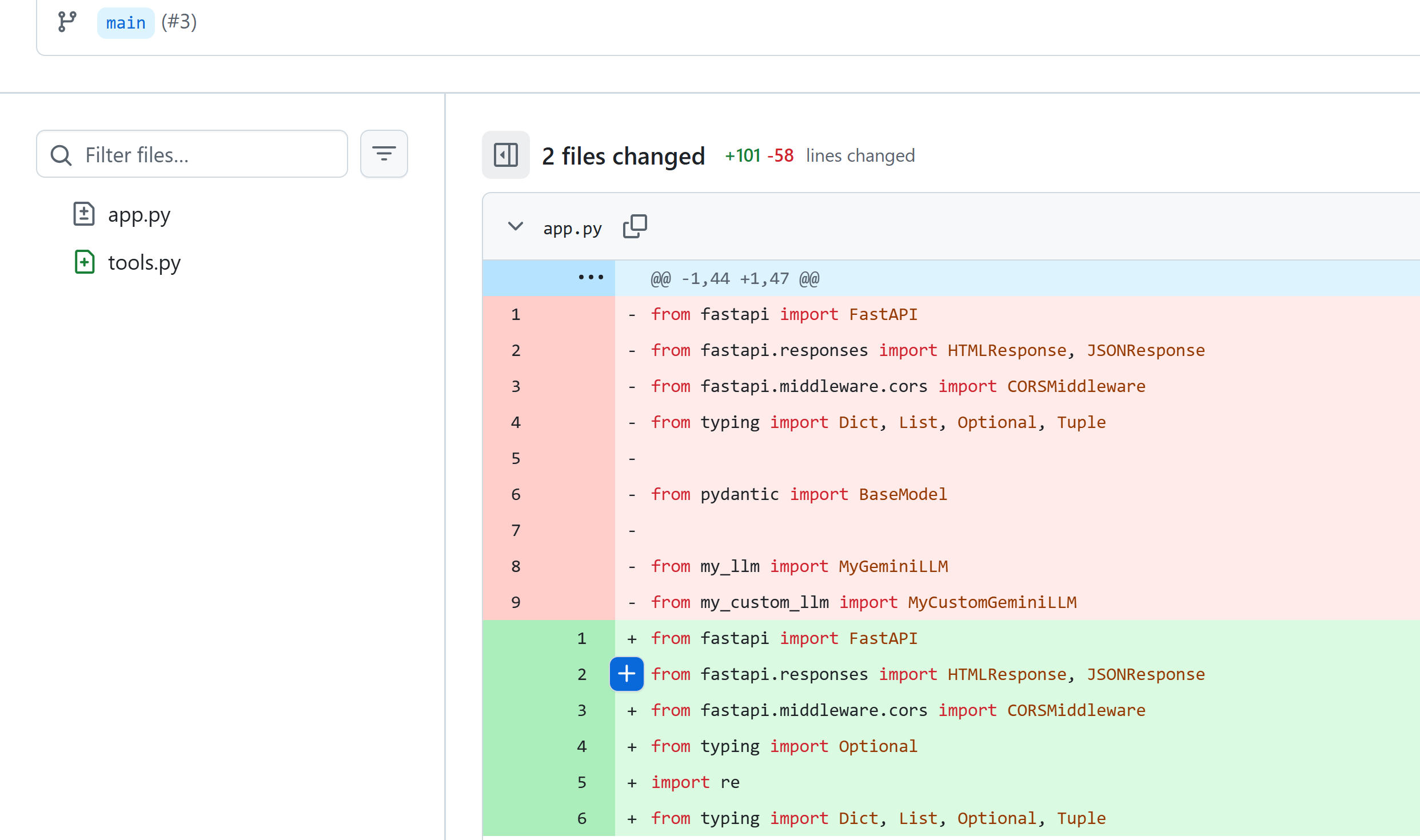
python
diff --git a/app.py b/app.py
index
--- a/app.py
+++ b/app.py
@@ -1,70 +1,91 @@
from fastapi import FastAPI
from fastapi.responses import HTMLResponse, JSONResponse
from fastapi.middleware.cors import CORSMiddleware
-from typing import Optional
+from typing import Dict, List, Optional, Tuple
from pydantic import BaseModel
from my_llm import MyGeminiLLM
from my_custom_llm import MyCustomGeminiLLM
-app = FastAPI()
+app = FastAPI()
+# 会话历史字典:key 是 session_id,value 是 [(question, answer), ...]
+# 用于在多轮对话中保留上下文,便于拼接成连续对话的 prompt
+sessions: Dict[str, List[Tuple[str, str]]] = {}
# 允许你的 GitHub Pages 调用(/ai 仍属于同一域名)
app.add_middleware(
CORSMiddleware,
allow_origins=["https://xxx.github.io"],
allow_origin_regex=r"https://xxx\.github\.io$",
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
expose_headers=["*"],
max_age=86400,
)
# 全局默认的 LLM 实例(不带 system prompt 的情况使用它)
llm = MyGeminiLLM()
# 默认的可爱语气 system prompt(当用户未提供时使用)
DEFAULT_CUTE_SYSTEM_PROMPT = "请用可爱的语气回答,简洁、温柔,像小可爱一样~"
class QuestionRequest(BaseModel):
# 用户输入的问题文本
question: str
# 可选的 system prompt,用来影响模型输出风格
# 如果不传或传空字符串,就会走默认的 MyGeminiLLM
system_prompt: Optional[str] = None
+ # 会话 ID:用于区分不同用户/对话的上下文
+ # 为空时表示单轮请求,不记录历史
+ session_id: Optional[str] = None
@app.get("/health")
def health():
return {"ok": True}
@app.get("/", response_class=HTMLResponse)
def index():
# 不依赖 templates 文件,避免 Render 上找不到文件导致异常
return """
<!doctype html>
<html lang="zh">
<head><meta charset="utf-8"><title>MyAgent API</title></head>
<body>
<h2>MyAgent API is running</h2>
<p>Health: <a href="/health">/health</a></p>
<p>Use <code>POST /ask</code> with JSON: {"question":"..."}</p>
</body>
</html>
"""
@app.post("/ask")
def ask_question(req: QuestionRequest):
# 如果前端传了 system_prompt,就用它;
# 否则使用默认的可爱语气 prompt。
system_prompt = req.system_prompt or DEFAULT_CUTE_SYSTEM_PROMPT
# 始终用自定义 LLM 包装器注入 system prompt,让回答保持可爱风格
active_llm = MyCustomGeminiLLM(prefix=system_prompt)
+ # 规范化 session_id(去掉首尾空白),避免同一会话被当成多个 key
+ session_id = req.session_id.strip() if req.session_id else None
+ # 获取该会话的历史;若不存在则初始化为空列表
+ # 未提供 session_id 时视为单轮对话,不读取/写入历史
+ history = sessions.setdefault(session_id, []) if session_id else []
+ # 将历史记录拼成连续对话的 prompt,格式如:
+ # 用户:... \n 助手:... \n 用户:... \n 助手:...
+ history_prompt = "".join(
+ f"用户:{question}\n助手:{response}\n" for question, response in history
+ )
+ # 拼接本次问题,提示模型继续回复助手内容
+ prompt = f"{history_prompt}用户:{req.question}\n助手:"
# 调用模型生成答案,max_output_tokens 适当提高以避免回答被截断
- answer = active_llm.generate(req.question, max_output_tokens=2048) # 避免只返回半句
+ answer = active_llm.generate(prompt, max_output_tokens=2048) # 避免只返回半句
+ if session_id:
+ # 仅当 session_id 有效时才记录历史,避免无意义的全局堆积
+ history.append((req.question, answer))
# 返回格式保持 {"answer": ...},确保前端兼容
return JSONResponse({"answer": answer})
一,进阶:基于 Session 的多轮对话实现(逐行拆解)
本文是在「单轮问答 API」基础上的一次重要升级
目标:让后端支持 多轮对话(Conversation / Chat History)
1. 为什么要引入"多轮对话"?
在最初版本中:
-
每次
POST /ask都是完全独立的 -
模型只看到当前这一个问题
-
类似这样:
Q1: FastAPI 是什么?
Q2: 它和 Flask 有什么区别?
模型并不知道 Q2 是在追问 Q1。
👉 为了解决这个问题,我们需要 "对话上下文(Conversation Context)"。
2. 这次改动的核心思路
一句话总结:
用 session_id 作为"会话标识",在后端保存历史问答,并在每次请求时把历史拼进 prompt
具体流程:
前端
├─ session_id = "abc123"
├─ question = "FastAPI 是什么?"
└─ POST /ask
↓
后端
├─ sessions["abc123"] = []
├─ prompt = "用户:FastAPI 是什么?\n助手:"
└─ 返回 answer
↓
后端保存
└─ sessions["abc123"].append((question, answer))下一轮:
用户:FastAPI 是什么?
助手:...
用户:它和 Flask 有什么区别?
助手:3. 新增 import:为"会话历史"做准备
python
from typing import Dict, List, Optional, Tuple为什么要这些类型?
| 类型 | 用途 |
|---|---|
| Dict | sessions 是一个字典 |
| List | 每个 session 保存多轮历史 |
| Tuple | 每一轮是 (question, answer) |
| Optional | session_id 可以不传 |
4. 全局 sessions:最简单的"会话存储"
python
# 会话历史字典:key 是 session_id,value 是 [(question, answer), ...]
# 用于在多轮对话中保留上下文,便于拼接成连续对话的 prompt
sessions: Dict[str, List[Tuple[str, str]]] = {}这段代码在干什么?
sessions是一个 内存中的会话池- key:
session_id(前端生成并传入) - value:一个列表,按顺序保存问答历史
示例结构:
python
{
"abc123": [
("FastAPI 是什么?", "FastAPI 是一个......"),
("它和 Flask 有什么区别?", "主要区别在于......")
]
}⚠️ 重要说明
这是一个 教学级实现:
- ❌ 服务重启后会丢失
- ❌ 多进程 / 多实例不共享
- ❌ 不适合生产环境
👉 后续可以替换为:
- Redis
- 数据库
- 向量数据库(更高级)
5. 请求体升级:引入 session_id
python
class QuestionRequest(BaseModel):
question: str
system_prompt: Optional[str] = None
session_id: Optional[str] = None为什么 session_id 放在请求体?
- 每个请求都明确属于哪个会话
- 后端保持"无状态接口 + 有状态存储"的平衡
- 前端完全可控(适合 Web / App / 小程序)
使用约定
session_id = null
👉 单轮对话,不记录历史session_id = "xxx"
👉 多轮对话,参与上下文拼接
6. 规范化 session_id(非常细但很重要)
python
session_id = req.session_id.strip() if req.session_id else None这一行解决了什么问题?
避免下面这种情况:
text
"abc123"
" abc123"
"abc123 "如果不处理,会被当成 三个不同的会话 key。
👉 这是后端健壮性设计的典型细节。
7. 获取 / 初始化会话历史
python
history = sessions.setdefault(session_id, []) if session_id else []逐层拆解:
-
session_id is None- 👉 单轮对话
- 👉 使用空历史,不写入 sessions
-
setdefault(session_id, [])- 如果不存在,就创建一个空列表
- 如果已存在,直接返回原有历史
这是一个非常 Pythonic 的写法。
8. 把历史拼成"对话 Prompt"
python
history_prompt = "".join(
f"用户:{question}\n助手:{response}\n" for question, response in history
)拼接后的真实效果
text
用户:FastAPI 是什么?
助手:FastAPI 是一个现代的 Web 框架......
用户:它和 Flask 有什么区别?
助手:主要区别包括......为什么不用 JSON / messages?
- 你当前的
MyCustomGeminiLLM.generate()接受的是 纯文本 - 这是最通用、最容易理解的方式
- 对新手非常友好
👉 后续可以升级为:
- OpenAI / Gemini 原生
messages=[{role, content}]结构
9. 拼接本轮问题(关键一步)
python
prompt = f"{history_prompt}用户:{req.question}\n助手:"这一行的意义
-
把"历史 + 当前问题"合并
-
明确告诉模型:
现在该 助手 继续说话了
这是对话式 Prompt Engineering 的核心技巧之一。
10. 模型调用从"question"升级为"prompt"
diff
- answer = active_llm.generate(req.question, max_output_tokens=2048)
+ answer = active_llm.generate(prompt, max_output_tokens=2048)本质变化
- ❌ 以前:模型只看到"一个问题"
- ✅ 现在:模型看到"完整对话历史"
👉 这一步,正式让你的 API 变成"Chat API"。
11. 仅在有 session_id 时才记录历史
python
if session_id:
history.append((req.question, answer))为什么要加这个判断?
- 单轮请求不应该污染全局状态
- 避免 sessions 无限增长
- 给调用方明确的行为边界
这是一个非常成熟的接口设计习惯。
12. 当前实现的边界与风险
12.1 内存问题
- 会话越来越多
- 历史越来越长
- Prompt 会无限膨胀
👉 后续方案:
- 限制历史轮数(例如只保留最近 N 轮)
- 定期清理 sessions
- 用 Redis + TTL
12.2 并发与部署问题
-
多 worker / 多实例下:
- sessions 不共享
-
适合:
- 单实例学习项目
-
不适合:
- 高并发生产环境
13. 下一步可以怎么升级?(路线图)
- ✅ 单轮问答
- ✅ session 多轮对话(本文)
- 🔜 限制历史长度 + 自动摘要
- 🔜 Redis / 数据库存储 session
- 🔜 messages 结构(对齐 OpenAI API)
- 🔜 用户鉴权 + session 绑定
- 🔜 流式输出(Streaming)
14. 小结
通过引入 session_id 与后端会话历史管理,我们用 极少的代码,把一个"问答 API"升级成了一个真正的"对话型 AI 接口"。
这套实现 也是后续高级架构(Redis / 多轮 / Agent)的基础
diff
python
这是 另一个新任务 diff --git a/app.py b/app.py
index 609aafa7c245b602aa9eec4f60362ca5f2ab75e8..c9171356fa8ada9d8708aa45c2e43e0b28a7bd1c 100644
--- a/app.py
+++ b/app.py
@@ -1,34 +1,36 @@
from fastapi import FastAPI
from fastapi.responses import HTMLResponse, JSONResponse
from fastapi.middleware.cors import CORSMiddleware
from typing import Optional
+import re
from pydantic import BaseModel
from my_llm import MyGeminiLLM
from my_custom_llm import MyCustomGeminiLLM
+from tools import add, get_time
app = FastAPI()
# 允许你的 GitHub Pages 调用(/ai 仍属于同一域名)
app.add_middleware(
CORSMiddleware,
allow_origins=["https://xxx.github.io"],
allow_origin_regex=r"https://xxx\.github\.io$",
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
expose_headers=["*"],
max_age=86400,
)
# 全局默认的 LLM 实例(不带 system prompt 的情况使用它)
llm = MyGeminiLLM()
# 默认的可爱语气 system prompt(当用户未提供时使用)
DEFAULT_CUTE_SYSTEM_PROMPT = "请用可爱的语气回答,简洁、温柔,像小可爱一样~"
class QuestionRequest(BaseModel):
# 用户输入的问题文本
question: str
# 可选的 system prompt,用来影响模型输出风格
# 如果不传或传空字符串,就会走默认的 MyGeminiLLM
@@ -36,35 +38,51 @@ class QuestionRequest(BaseModel):
@app.get("/health")
def health():
return {"ok": True}
@app.get("/", response_class=HTMLResponse)
def index():
# 不依赖 templates 文件,避免 Render 上找不到文件导致异常
return """
<!doctype html>
<html lang="zh">
<head><meta charset="utf-8"><title>MyAgent API</title></head>
<body>
<h2>MyAgent API is running</h2>
<p>Health: <a href="/health">/health</a></p>
<p>Use <code>POST /ask</code> with JSON: {"question":"..."}</p>
</body>
</html>
"""
@app.post("/ask")
def ask_question(req: QuestionRequest):
+ # 取出用户输入的问题文本,便于后续处理
+ question = req.question
+ # 规则 1:如果问题中出现"现在几点"或"今天日期",直接返回当前时间
+ if "现在几点" in question or "今天日期" in question:
+ return JSONResponse({"answer": get_time()})
+
+ # 规则 2:如果问题符合 "a+b=?" 形式,解析出 a、b 并计算
+ # 说明:下面这个正则允许空格和小数,比如 " 1 + 2 = ? "
+ math_match = re.fullmatch(r"\s*(\d+(?:\.\d+)?)\s*\+\s*(\d+(?:\.\d+)?)\s*=\s*\?\s*", question)
+ if math_match:
+ # 正则分组 1 和 2 分别是 a、b 的文本形式
+ left = float(math_match.group(1))
+ right = float(math_match.group(2))
+ # 计算完成后直接返回,避免走 LLM
+ return JSONResponse({"answer": str(add(left, right))})
+
# 如果前端传了 system_prompt,就用它;
# 否则使用默认的可爱语气 prompt。
system_prompt = req.system_prompt or DEFAULT_CUTE_SYSTEM_PROMPT
# 始终用自定义 LLM 包装器注入 system prompt,让回答保持可爱风格
active_llm = MyCustomGeminiLLM(prefix=system_prompt)
# 调用模型生成答案,max_output_tokens 适当提高以避免回答被截断
- answer = active_llm.generate(req.question, max_output_tokens=2048) # 避免只返回半句
+ answer = active_llm.generate(question, max_output_tokens=2048) # 避免只返回半句
# 返回格式保持 {"answer": ...},确保前端兼容
return JSONResponse({"answer": answer})
新文件 tools.py diff --git a/tools.py b/tools.py
new file mode 100644
index 0000000000000000000000000000000000000000..8005f222a02563a982dd9fdf6c7f616b2c472576
--- /dev/null
+++ b/tools.py
@@ -0,0 +1,24 @@
+from __future__ import annotations
+
+from datetime import datetime
+
+
+def get_time() -> str:
+ """获取当前时间字符串。
+
+ 返回格式:YYYY-MM-DD HH:MM:SS
+ 示例:2025-01-31 09:30:00
+ """
+ # datetime.now() 会获取系统当前的本地时间(不是 UTC)
+ now = datetime.now()
+ # strftime 用指定格式把时间对象转成字符串,便于直接返回给前端
+ return now.strftime("%Y-%m-%d %H:%M:%S")
+
+
+def add(a: float, b: float) -> float:
+ """执行加法并返回结果。
+
+ 这里接收 float,既可以处理整数,也可以处理小数。
+ """
+ # Python 的 + 会进行数值相加
+ return a + b从"纯 LLM 问答" → "规则优先 + LLM 兜底"的 Agent 雏形
二,进阶:规则优先 + Tool 调用的 Agent 雏形实现(逐行拆解)
本文目标:
在已有 FastAPI + LLM 问答接口的基础上,引入 规则判断(Rule-based)与工具函数(Tools) ,
让系统具备 "能不用 LLM 就不用 LLM" 的基础 Agent 能力。
1. 为什么要加「规则 + Tools」?
在最初版本中:
- 所有问题 无条件丢给 LLM
- 即使是下面这种问题:
text
现在几点?
1 + 2 = ?也会:
- 消耗 token
- 增加响应时间
- 引入不确定性(模型可能胡说)
👉 现实系统里,LLM 不应该是第一选择,而是"兜底选择"。
2. 本次升级的整体设计思想
一句话总结:
先用确定性规则解决能确定的问题,其余问题再交给 LLM
执行顺序:
用户问题
↓
规则判断(if / regex)
├─ 命中 → 调用工具函数 → 直接返回
└─ 未命中 → 交给 LLM这正是很多 Agent 框架(LangChain / OpenAI Tools)的原始思想。
3. 新增依赖与模块拆分
3.1 新增 import
python
import re
from tools import add, get_time为什么引入 re?
- 用正则精确判断 "是否是数学表达式"
- 避免模糊匹配导致误判
为什么单独建 tools.py?
- 职责清晰(Single Responsibility)
- 方便未来扩展更多工具
- 为后续 "Tool Calling / Function Calling" 打基础
4. tools.py:工具模块逐行讲解
python
from __future__ import annotations这行是干什么的?
- 让类型注解支持 前向引用
- 属于现代 Python 的最佳实践
- 对当前代码影响不大,但写法专业
4.1 获取当前时间:get_time
python
def get_time() -> str:设计要点
- 返回
str而不是datetime - 前端可以直接展示,无需再处理
python
now = datetime.now()- 获取本地系统时间
- 非 UTC(符合直觉)
python
return now.strftime("%Y-%m-%d %H:%M:%S")示例返回:
text
2025-01-31 09:30:00👉 确定性、零成本、零 token
4.2 数学工具:add
python
def add(a: float, b: float) -> float:为什么用 float?
-
同时支持:
1 + 21.5 + 2.3
python
return a + b👉 完全确定性,比 LLM 可靠 100 倍
5. /ask 接口升级:规则优先处理
5.1 提前取出 question(很重要的细节)
python
question = req.question好处:
- 避免后面多次
req.question - 逻辑更清晰
- 方便未来做预处理(normalize / trim / lower)
6. 规则 1:时间 / 日期问题
python
if "现在几点" in question or "今天日期" in question:
return JSONResponse({"answer": get_time()})设计思想
- 使用 最简单、最稳定的字符串判断
- 不走 LLM,直接返回
为什么不用正则?
- 中文语义简单
- 可读性更高
- 规则足够明确
👉 这是 Agent 中的 "Rule Shortcut"
7. 规则 2:数学表达式识别(正则)
python
math_match = re.fullmatch(
r"\s*(\d+(?:\.\d+)?)\s*\+\s*(\d+(?:\.\d+)?)\s*=\s*\?\s*",
question
)这个正则能匹配什么?
以下全部合法:
text
1+2=?
1 + 2 = ?
3.5 + 4.2 = ?正则拆解说明
| 部分 | 含义 |
|---|---|
| \d+ | 整数 |
| (?:.\d+)? | 可选小数 |
| \s* | 任意空格 |
| fullmatch | 必须整行完全匹配 |
👉 避免误伤普通自然语言问题。
7.1 提取并计算
python
left = float(math_match.group(1))
right = float(math_match.group(2))- 正则分组 1、2 对应左右操作数
- 统一转成 float
python
return JSONResponse({"answer": str(add(left, right))})为什么这里直接 return?
- 一旦规则命中
- 立刻短路
- 不再进入 LLM 逻辑
这是 规则优先架构的核心特征。
8. 未命中规则 → 交给 LLM(兜底)
python
system_prompt = req.system_prompt or DEFAULT_CUTE_SYSTEM_PROMPT
active_llm = MyCustomGeminiLLM(prefix=system_prompt)
answer = active_llm.generate(question, max_output_tokens=2048)此时 LLM 的角色
-
不再是"万能解答者"
-
而是:
"规则无法处理时的智能兜底"
这正是现代 Agent 的定位。
9. 当前架构的本质:Mini Agent
你现在的系统,已经具备 Agent 的三个核心要素:
| Agent 要素 | 当前是否具备 |
|---|---|
| 观察输入 | ✅ question |
| 决策(规则) | ✅ if / regex |
| 行动(Tools) | ✅ add / get_time |
| 兜底智能 | ✅ LLM |
👉 这不是"玩具代码",而是 Agent 的原型结构
10. 与 LangChain / OpenAI Tools 的关系
你现在写的,其实是:
"手写版 Tool Calling"
对比:
| 你现在 | 高级框架 |
|---|---|
| if / regex | LLM 自动选择 tool |
| Python 函数 | Tool Schema |
| 人写规则 | 模型决策 |
理解这一层后,再学框架会非常轻松。
11. 当前实现的边界
11.1 规则不可扩展性
- if / regex 多了会很乱
👉 后续可改为:
- 规则表
- Chain of Responsibility
- Plugin 架构
11.2 没有"模型决定是否调用工具"
- 目前是人写规则
- 不是 LLM 自主判断
👉 下一阶段:
- 把 tools 描述交给 LLM
- 让模型返回
tool_name + args
12. 推荐升级路线
- ✅ LLM 问答
- ✅ Session 多轮对话
- ✅ Rule + Tools(本文)
- 🔜 Tool Schema + LLM 选择工具
- 🔜 多工具组合(计算 + 时间 + 搜索)
- 🔜 真正的 Agent Loop(Plan → Act → Observe)
13. 总结
通过这次改动,我们完成了从:
"所有问题都问 LLM"
→ "规则优先,LLM 兜底"
这一步,是从"AI Demo"走向"AI 系统"的分水岭。