模型介绍
混元翻译模型1.5版本包含1.8B翻译模型HY-MT1.5-1.8B和7B翻译模型HY-MT1.5-7B。两模型均聚焦支持33种语言互译,并包含5种民族语和方言变体。其中HY-MT1.5-7B为WMT25夺冠模型的升级版本,优化了注释翻译和混合语种场景,新增支持术语干预、上下文翻译、格式翻译等功能。HY-MT1.5-1.8B参数量不足HY-MT1.5-7B的三分之一,但翻译效果媲美7B模型,兼顾速度与质量。1.8B模型量化后可在端侧部署,支持实时翻译场景,具备广泛适用性。
核心特点与优势
- HY-MT1.5-1.8B达到同规模模型业界领先效果,超越多数商用翻译API。
- HY-MT1.5-1.8B支持端侧部署及实时翻译场景,适用性广泛。
- HY-MT1.5-7B相较9月开源版本,优化了注释翻译和混合语种场景。
- 两模型均支持术语干预、上下文翻译、格式翻译。
相关动态
- 2025.12.30,我们在Hugging Face开源了HY-MT1.5-1.8B 和HY-MT1.5-7B。
- 2025.9.1,我们在Hugging Face开源了混元-MT-7B 、混元-MT-Chimera-7B 。
性能表现
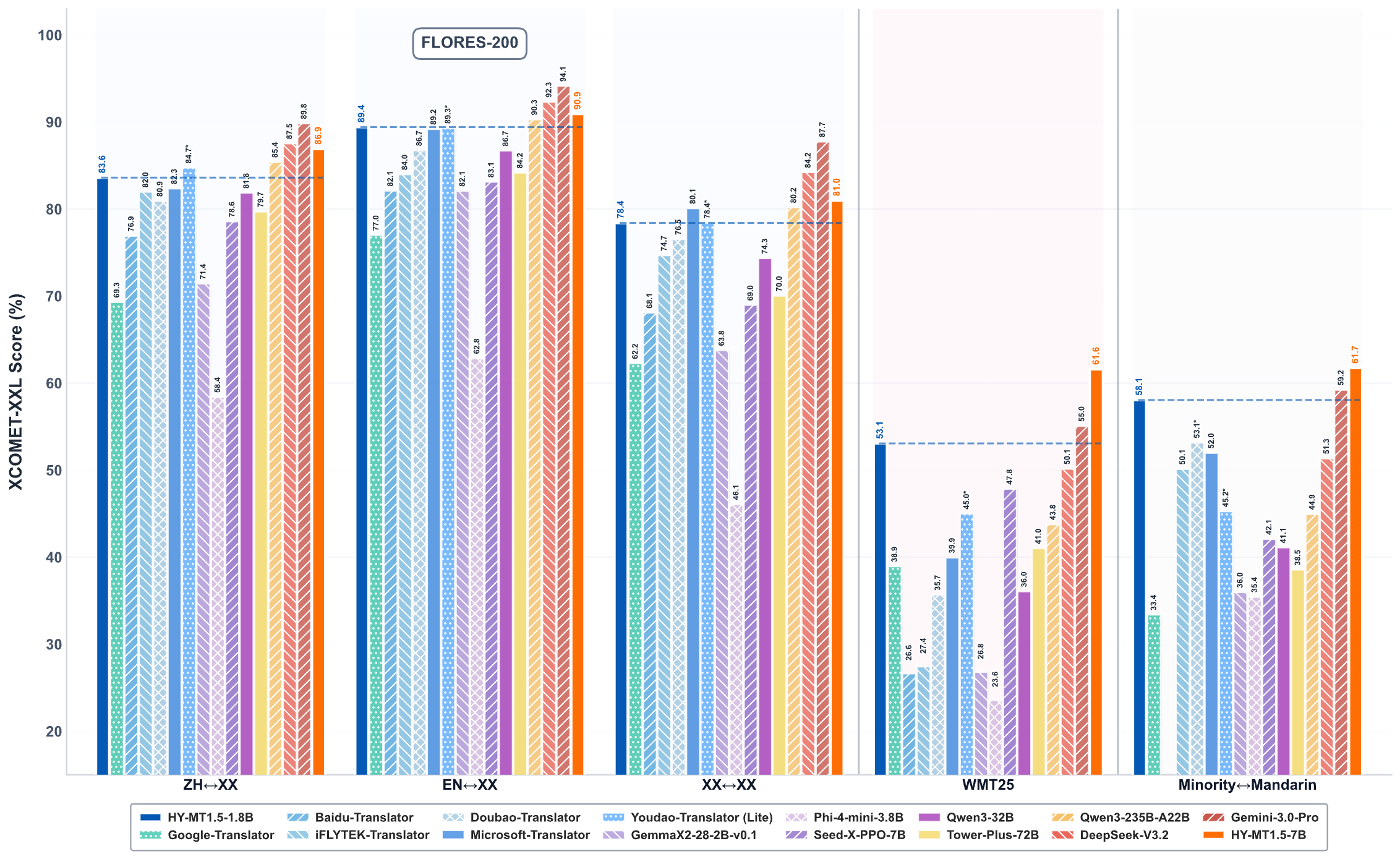
您可以参考我们的技术报告以获取更多实验结果和分析。
模型链接
| 模型名称 | 描述 | 下载地址 |
|---|---|---|
| HY-MT1.5-1.8B | 混元1.8B翻译模型 | 🤗 模型 |
| HY-MT1.5-1.8B-FP8 | 混元1.8B翻译模型,fp8量化版 | 🤗 模型 |
| HY-MT1.5-7B | 混元7B翻译模型 | 🤗 模型 |
| HY-MT1.5-7B-FP8 | 混元7B翻译模型,fp8量化版 | 🤗 模型 |
提示词
ZH<=>XX 翻译的提示模板.
将以下文本翻译为{target_language},注意只需要输出翻译后的结果,不要额外解释:
{source_text}适用于XX<=>XX翻译的提示模板(不包括中文<=>XX)
Translate the following segment into {target_language}, without additional explanation.
{source_text}术语干预的提示模板。
参考下面的翻译:
{source_term} 翻译成 {target_term}
将以下文本翻译为{target_language},注意只需要输出翻译后的结果,不要额外解释:
{source_text}上下文翻译的提示模板
{context}
参考上面的信息,把下面的文本翻译成{target_language},注意不需要翻译上文,也不要额外解释:
{source_text}格式化翻译的提示模板
将以下<source></source>之间的文本翻译为中文,注意只需要输出翻译后的结果,不要额外解释,原文中的<sn></sn>标签表示标签内文本包含格式信息,需要在译文中相应的位置尽量保留该标签。输出格式为:<target>str</target>
<source>{src_text_with_format}</source>与 transformers 一起使用
首先,请安装 transformers,推荐版本 v4.56.0
SHELL
pip install transformers==4.56.0!!! 如需使用transformers加载fp8模型,您需要将config.json中的"ignored_layers"字段名称改为"ignore",并将compressed-tensors升级至compressed-tensors-0.11.0版本。
以下代码片段展示了如何使用transformers库加载并应用该模型。
我们以tencent/HY-MT1.5-1.8B模型为例
python
from transformers import AutoModelForCausalLM, AutoTokenizer
import os
model_name_or_path = "tencent/HY-MT1.5-1.8B"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, device_map="auto") # You may want to use bfloat16 and/or move to GPU here
messages = [
{"role": "user", "content": "Translate the following segment into Chinese, without additional explanation.\n\nIt's on the house."},
]
tokenized_chat = tokenizer.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=False,
return_tensors="pt"
)
outputs = model.generate(tokenized_chat.to(model.device), max_new_tokens=2048)
output_text = tokenizer.decode(outputs[0])我们推荐使用以下参数集进行推理。请注意,我们的模型没有默认的system_prompt。
json
{
"top_k": 20,
"top_p": 0.6,
"repetition_penalty": 1.05,
"temperature": 0.7
}支持的语言:
| 语言 | 缩写 | 中文名称 |
|---|---|---|
| Chinese | zh | 中文 |
| English | en | 英语 |
| French | fr | 法语 |
| Portuguese | pt | 葡萄牙语 |
| Spanish | es | 西班牙语 |
| Japanese | ja | 日语 |
| Turkish | tr | 土耳其语 |
| Russian | ru | 俄语 |
| Arabic | ar | 阿拉伯语 |
| Korean | ko | 韩语 |
| Thai | th | 泰语 |
| Italian | it | 意大利语 |
| German | de | 德语 |
| Vietnamese | vi | 越南语 |
| Malay | ms | 马来语 |
| Indonesian | id | 印尼语 |
| Filipino | tl | 菲律宾语 |
| Hindi | hi | 印地语 |
| Traditional Chinese | zh-Hant | 繁体中文 |
| Polish | pl | 波兰语 |
| Czech | cs | 捷克语 |
| Dutch | nl | 荷兰语 |
| Khmer | km | 高棉语 |
| Burmese | my | 缅甸语 |
| Persian | fa | 波斯语 |
| Gujarati | gu | 古吉拉特语 |
| Urdu | ur | 乌尔都语 |
| Telugu | te | 泰卢固语 |
| Marathi | mr | 马拉地语 |
| Hebrew | he | 希伯来语 |
| Bengali | bn | 孟加拉语 |
| Tamil | ta | 泰米尔语 |
| Ukrainian | uk | 乌克兰语 |
| Tibetan | bo | 藏语 |
| Kazakh | kk | 哈萨克语 |
| Mongolian | mn | 蒙古语 |
| Uyghur | ug | 维吾尔语 |
| Cantonese | yue | 粤语 |