目录标题
- [从 0 到 1:用 FastAPI 搭建可控风格的 LLM 问答 API(含 CORS、System Prompt、逐行讲解与可拓展点)](#从 0 到 1:用 FastAPI 搭建可控风格的 LLM 问答 API(含 CORS、System Prompt、逐行讲解与可拓展点))
-
- [1. 项目要解决什么问题?](#1. 项目要解决什么问题?)
- [2. 整体架构](#2. 整体架构)
- [3. 完整代码(超详细注释版)](#3. 完整代码(超详细注释版))
- [4. 逐个知识点拆解(并给出可扩展方向)](#4. 逐个知识点拆解(并给出可扩展方向))
-
- [4.1 FastAPI:你现在用到的核心能力有哪些?](#4.1 FastAPI:你现在用到的核心能力有哪些?)
- [4.2 CORS(CORSMiddleware):为什么你必须配置它?](#4.2 CORS(CORSMiddleware):为什么你必须配置它?)
- [4.3 System Prompt:它到底是什么?为什么你这样写很实用?](#4.3 System Prompt:它到底是什么?为什么你这样写很实用?)
- [4.4 Pydantic BaseModel:为什么它是 FastAPI 的"灵魂搭档"?](#4.4 Pydantic BaseModel:为什么它是 FastAPI 的“灵魂搭档”?)
- [5. 每个方法(路由)可以怎么进一步扩展?](#5. 每个方法(路由)可以怎么进一步扩展?)
-
- [5.1 GET /health(健康检查)](#5.1 GET /health(健康检查))
- [5.2 GET /(首页)](#5.2 GET /(首页))
- [5.3 POST /ask(核心)](#5.3 POST /ask(核心))
- [6. 前端如何调用(fetch 示例)](#6. 前端如何调用(fetch 示例))
- [7. 常见坑与排查清单(新手必看)](#7. 常见坑与排查清单(新手必看))
-
- [7.1 前端报 CORS 错误](#7.1 前端报 CORS 错误)
- [7.2 /ask 返回很慢](#7.2 /ask 返回很慢)
- [7.3 回答被截断](#7.3 回答被截断)
- [8. 下一步准备怎么升级这个项目(路线图)](#8. 下一步准备怎么升级这个项目(路线图))
- [9. 总结](#9. 总结)
- 10.附:给java的同学详细解释语法
-
- 一、先看全景:这个服务在干嘛?
- 二、图解请求流程(更直观)
- 三、核心代码拆解(逐句解释)
- [四、CORS 是什么?为什么要设置?](#四、CORS 是什么?为什么要设置?)
- 五、前端应该怎么调用?
- 六、拓展学习:还能加什么功能?
- 七、总结(给初学者的你)
从 0 到 1:用 FastAPI 搭建可控风格的 LLM 问答 API(含 CORS、System Prompt、逐行讲解与可拓展点)
面向人群:完全新手 / 刚接触 FastAPI 的同学
目标:读完能理解代码每一块在做什么,并知道下一步如何扩展成更完整的"AI 服务"
1. 项目要解决什么问题?
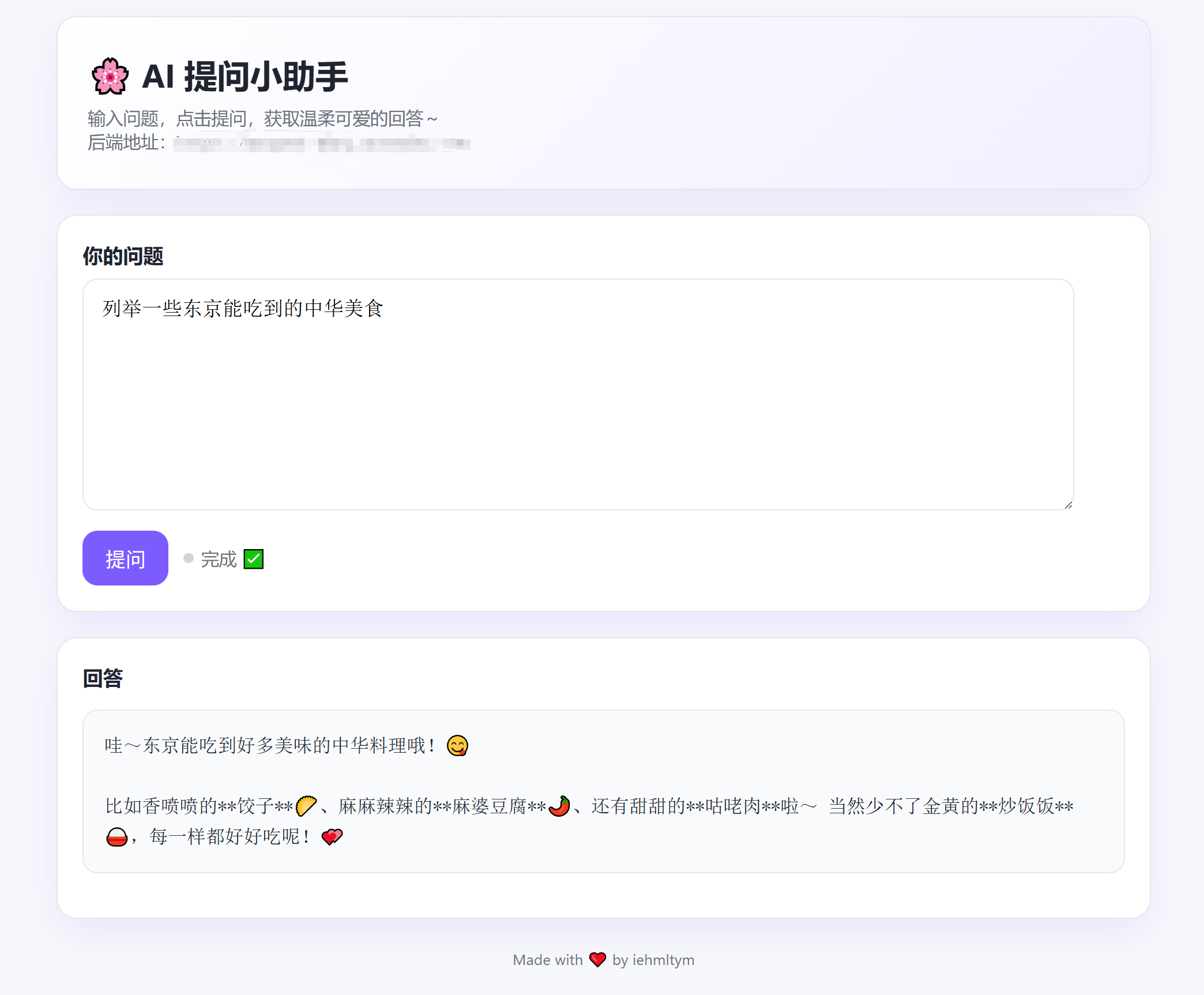
我有一个前端页面部署在 GitHub Pages(例如:https://xxx.github.io),想要在页面里调用自己部署的后端接口,然后由后端去调用大模型(Gemini)并返回答案。
同时我希望:
- 前端可以跨域访问后端(CORS)
- 后端提供一个
/ask接口用于问答 - 支持 System Prompt(系统提示词),用来控制模型输出风格(例如"可爱语气""面试官语气"等)
- 提供
/health用于健康检查,便于部署平台监控服务存活
2. 整体架构
markup
浏览器(GitHub Pages 前端)
|
| fetch("POST /ask")
v
FastAPI 后端(Render / 云服务器)
|
| 调用 MyCustomGeminiLLM.generate(question)
v
Gemini / LLM(模型)
|
v
返回 {"answer": "..."}3. 完整代码(超详细注释版)
python
"""
这是一个使用 FastAPI 构建的 AI 问答后端服务。
核心能力:
1) GET /health:健康检查
2) GET /:返回一个简单的 HTML 页面(便于快速确认服务可用)
3) POST /ask:前端传 question(可选 system_prompt),后端调用 LLM 生成 answer 并返回 JSON
此外:
- 配置了 CORS,允许 GitHub Pages 访问后端
- 支持 system prompt 注入,用于控制模型输出风格
"""
# =========================
# 1) 导入依赖
# =========================
from fastapi import FastAPI
from fastapi.responses import HTMLResponse, JSONResponse
from fastapi.middleware.cors import CORSMiddleware
from typing import Optional
from pydantic import BaseModel
# 这两个是你自己封装的 LLM 调用类
from my_llm import MyGeminiLLM
from my_custom_llm import MyCustomGeminiLLM
# =========================
# 2) 创建 FastAPI 应用
# =========================
# app 是整个 Web 服务的主体
# 你定义的每个接口(路由)都会挂载在 app 上
app = FastAPI()
# =========================
# 3) CORS 配置(解决跨域)
# =========================
"""
为什么需要 CORS?
浏览器有"同源策略":
- 你的前端域名(GitHub Pages)和后端域名(Render/服务器)不同
- 浏览器默认会拦截跨域请求
- 必须由后端通过 CORS 明确允许某些来源访问
这里的配置含义:
- allow_origins:明确允许的来源(白名单)
- allow_origin_regex:也可以用正则匹配来源
- allow_methods/headers:允许所有方法与请求头
- max_age:浏览器预检(OPTIONS)结果缓存时间(秒)
"""
app.add_middleware(
CORSMiddleware,
allow_origins=["https://xxx.github.io"],
allow_origin_regex=r"https://xxx\.github\.io$",
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
expose_headers=["*"],
max_age=86400,
)
# =========================
# 4) LLM 实例与默认 system prompt
# =========================
"""
llm:全局默认的 LLM 实例(当前代码里其实没有直接用到它)
- 它可以留作未来扩展:例如你想提供一个"不带 system prompt"的接口
- 或者用于"健康检查时顺便做一个轻量模型连通测试"
"""
llm = MyGeminiLLM()
"""
DEFAULT_CUTE_SYSTEM_PROMPT:默认系统提示词
- 当请求不传 system_prompt 时,就用这个
- system prompt 本质上是一段"对模型的指令/角色设定"
"""
DEFAULT_CUTE_SYSTEM_PROMPT = "请用可爱的语气回答,简洁、温柔,像小可爱一样~"
# =========================
# 5) 定义请求体结构(Pydantic)
# =========================
"""
FastAPI 会把请求 JSON 自动解析成你定义的 Pydantic 模型
好处:
- 自动校验类型
- 自动生成 Swagger 文档(/docs)
- 代码可读性强(请求体结构清晰)
"""
class QuestionRequest(BaseModel):
# question:用户输入的问题(必填)
question: str
# system_prompt:系统提示词(可选)
# Optional[str] = None 表示:可以不传
system_prompt: Optional[str] = None
# =========================
# 6) 健康检查接口
# =========================
@app.get("/health")
def health():
"""
GET /health
用途:
- 部署平台(Render等)常用来做健康检查
- 你也能用浏览器直接访问确认服务存活
返回:
{"ok": True}
"""
return {"ok": True}
# =========================
# 7) 首页接口:返回 HTML
# =========================
@app.get("/", response_class=HTMLResponse)
def index():
"""
GET /
用途:
- 给人类看的快速首页
- 不用模板文件(避免部署环境找不到 templates 目录导致报错)
- 简单展示 /health 和 /ask 的用法
注意:
- response_class=HTMLResponse 表示返回的是 HTML 字符串,而不是 JSON
"""
return """
<!doctype html>
<html lang="zh">
<head><meta charset="utf-8"><title>MyAgent API</title></head>
<body>
<h2>MyAgent API is running</h2>
<p>Health: <a href="/health">/health</a></p>
<p>Use <code>POST /ask</code> with JSON: {"question":"..."}</p>
</body>
</html>
"""
# =========================
# 8) 核心接口:问答 /ask
# =========================
@app.post("/ask")
def ask_question(req: QuestionRequest):
"""
POST /ask
输入:
- JSON 请求体会被解析成 QuestionRequest
- req.question:用户问题
- req.system_prompt(可选):系统提示词
输出:
- JSON:{"answer": "..."}
"""
# 关键逻辑:system_prompt 的"默认值处理"
# - 如果 req.system_prompt 是 None 或 "",就使用默认可爱 prompt
# - 这样前端不传时也能得到风格一致的输出
system_prompt = req.system_prompt or DEFAULT_CUTE_SYSTEM_PROMPT
"""
每次请求都创建一个 active_llm 的意义:
1) 隔离不同请求之间的上下文/配置
- 例如每个请求 system prompt 不同
2) 避免多线程/并发情况下共享状态导致混乱
3) 更容易做"按用户/按会话"扩展
"""
active_llm = MyCustomGeminiLLM(prefix=system_prompt)
"""
调用模型生成答案
- max_output_tokens=2048:控制输出长度,避免回答被截断
- 这里是同步调用;如果模型调用耗时长,未来可以改成 async 或后台队列
"""
answer = active_llm.generate(req.question, max_output_tokens=2048)
# 返回 JSON,字段名固定为 answer,确保前端兼容
return JSONResponse({"answer": answer})app.py简洁版本
python
from fastapi import FastAPI
from fastapi.responses import HTMLResponse, JSONResponse
from fastapi.middleware.cors import CORSMiddleware
from typing import Optional
from pydantic import BaseModel
from my_llm import MyGeminiLLM
from my_custom_llm import MyCustomGeminiLLM
app = FastAPI()
# 允许你的 GitHub Pages 调用(/ai 仍属于同一域名)
app.add_middleware(
CORSMiddleware,
allow_origins=["https://xxx.github.io"],
allow_origin_regex=r"https://xxx\.github\.io$",
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
expose_headers=["*"],
max_age=86400,
)
# 全局默认的 LLM 实例(不带 system prompt 的情况使用它)
llm = MyGeminiLLM()
# 默认的可爱语气 system prompt(当用户未提供时使用)
DEFAULT_CUTE_SYSTEM_PROMPT = "请用可爱的语气回答,简洁、温柔,像小可爱一样~"
class QuestionRequest(BaseModel):
# 用户输入的问题文本
question: str
# 可选的 system prompt,用来影响模型输出风格
# 如果不传或传空字符串,就会走默认的 MyGeminiLLM
system_prompt: Optional[str] = None
@app.get("/health")
def health():
return {"ok": True}
@app.get("/", response_class=HTMLResponse)
def index():
# 不依赖 templates 文件,避免 Render 上找不到文件导致异常
return """
<!doctype html>
<html lang="zh">
<head><meta charset="utf-8"><title>MyAgent API</title></head>
<body>
<h2>MyAgent API is running</h2>
<p>Health: <a href="/health">/health</a></p>
<p>Use <code>POST /ask</code> with JSON: {"question":"..."}</p>
</body>
</html>
"""
@app.post("/ask")
def ask_question(req: QuestionRequest):
# 如果前端传了 system_prompt,就用它;
# 否则使用默认的可爱语气 prompt。
system_prompt = req.system_prompt or DEFAULT_CUTE_SYSTEM_PROMPT
# 始终用自定义 LLM 包装器注入 system prompt,让回答保持可爱风格
active_llm = MyCustomGeminiLLM(prefix=system_prompt)
# 调用模型生成答案,max_output_tokens 适当提高以避免回答被截断
answer = active_llm.generate(req.question, max_output_tokens=2048) # 避免只返回半句
# 返回格式保持 {"answer": ...},确保前端兼容
return JSONResponse({"answer": answer})diff
python
diff --git a/app.py b/app.py
index 355ee043b18674a632dc12d9d09d9a8e58460efd..d307e43cd6db04f731ea00263ffebac21bb20616 100644
--- a/app.py
+++ b/app.py
@@ -1,52 +1,70 @@
-from fastapi import FastAPI
-from fastapi.responses import HTMLResponse, JSONResponse
-from fastapi.middleware.cors import CORSMiddleware
-from pydantic import BaseModel
+from fastapi import FastAPI # FastAPI:用来快速创建 Web API 服务的框架
+from fastapi.responses import HTMLResponse, JSONResponse # HTMLResponse/JSONResponse:返回 HTML 或 JSON 的响应对象
+from fastapi.middleware.cors import CORSMiddleware # CORS 中间件:解决跨域请求限制
+from typing import Optional # Optional[T]:表示该字段可以是 T 或 None
+
+from pydantic import BaseModel # BaseModel:用来声明/校验请求数据结构的基类
+
+from my_llm import MyGeminiLLM # 默认的 LLM 封装(不带自定义 system prompt)
+from my_custom_llm import MyCustomGeminiLLM # 可自定义 system prompt 的 LLM 封装
-from my_llm import MyGeminiLLM
+app = FastAPI() # 创建 FastAPI 应用实例,所有路由都挂在这个对象上
-app = FastAPI()
+# 允许你的 GitHub Pages 调用(/ai 仍属于同一域名)
+app.add_middleware(
+ CORSMiddleware, # 使用 CORS 中间件,让浏览器允许跨域访问
+ allow_origins=["https://xxx.github.io"], # 精确允许的来源域名(前端 GitHub Pages)
+ allow_origin_regex=r"https://xxx\.github\.io$", # 正则允许来源(同一域名不同路径)
+ allow_credentials=True, # 是否允许携带 Cookie/认证信息
+ allow_methods=["*"], # 允许的 HTTP 方法(GET/POST 等),* 表示全部
+ allow_headers=["*"], # 允许的请求头,* 表示全部
+ expose_headers=["*"], # 暴露给浏览器的响应头,* 表示全部
+ max_age=86400, # 预检请求缓存时间(秒),减少浏览器重复预检
+)
-# 允许你的 GitHub Pages 调用(先精确放行你的域名)
-app.add_middleware(
- CORSMiddleware,
- allow_origins=["https://xxx.github.io"],
- allow_credentials=True,
- allow_methods=["*"],
- allow_headers=["*"],
- expose_headers=["*"],
- max_age=86400,
-)
+# 全局默认的 LLM 实例(不带 system prompt 的情况使用它)
+llm = MyGeminiLLM() # 初始化默认模型封装(后续不带提示词时可用)
+# 默认的可爱语气 system prompt(当用户未提供时使用)
+DEFAULT_CUTE_SYSTEM_PROMPT = "请用可爱的语气回答,简洁、温柔,像小可爱一样~" # 默认提示词
+
+class QuestionRequest(BaseModel): # 定义请求体结构,用于自动校验/解析 JSON
+ # 用户输入的问题文本
markdown
# 从 0 到 1:用 FastAPI 搭建可控风格的 LLM 问答 API(含 CORS、System Prompt、逐行讲解与可拓展点)
> 面向人群:完全新手 / 刚接触 FastAPI 的同学
> 目标:读完能理解代码每一块在做什么,并知道下一步如何扩展成更完整的"AI 服务"
---
## 1. 项目要解决什么问题?
我有一个前端页面部署在 GitHub Pages(例如:`https://xxx.github.io`),想要在页面里调用自己部署的后端接口,然后由后端去调用大模型(Gemini)并返回答案。
同时我希望:
- 前端可以跨域访问后端(CORS)
- 后端提供一个 `/ask` 接口用于问答
- 支持 **System Prompt(系统提示词)**,用来控制模型输出风格(例如"可爱语气""面试官语气"等)
- 提供 `/health` 用于健康检查,便于部署平台监控服务存活
---
## 2. 整体架构浏览器(GitHub Pages 前端)
|
| fetch("POST /ask")
v
FastAPI 后端(Render / 云服务器)
|
| 调用 MyCustomGeminiLLM.generate(question)
v
Gemini / LLM(模型)
|
v
返回 {"answer": "..."}
---
## 3. 完整代码(超详细注释版)
> 说明:下面代码的注释是"博客可直接贴"的级别,会把每个模块的目的、风险点、可扩展点都写清楚。
```python
"""
这是一个使用 FastAPI 构建的 AI 问答后端服务。
核心能力:
1) GET /health:健康检查
2) GET /:返回一个简单的 HTML 页面(便于快速确认服务可用)
3) POST /ask:前端传 question(可选 system_prompt),后端调用 LLM 生成 answer 并返回 JSON
此外:
- 配置了 CORS,允许 GitHub Pages 访问后端
- 支持 system prompt 注入,用于控制模型输出风格
"""
# =========================
# 1) 导入依赖
# =========================
from fastapi import FastAPI
from fastapi.responses import HTMLResponse, JSONResponse
from fastapi.middleware.cors import CORSMiddleware
from typing import Optional
from pydantic import BaseModel
# 这两个是你自己封装的 LLM 调用类
from my_llm import MyGeminiLLM
from my_custom_llm import MyCustomGeminiLLM
# =========================
# 2) 创建 FastAPI 应用
# =========================
# app 是整个 Web 服务的主体
# 你定义的每个接口(路由)都会挂载在 app 上
app = FastAPI()
# =========================
# 3) CORS 配置(解决跨域)
# =========================
"""
为什么需要 CORS?
浏览器有"同源策略":
- 你的前端域名(GitHub Pages)和后端域名(Render/服务器)不同
- 浏览器默认会拦截跨域请求
- 必须由后端通过 CORS 明确允许某些来源访问
这里的配置含义:
- allow_origins:明确允许的来源(白名单)
- allow_origin_regex:也可以用正则匹配来源
- allow_methods/headers:允许所有方法与请求头
- max_age:浏览器预检(OPTIONS)结果缓存时间(秒)
"""
app.add_middleware(
CORSMiddleware,
allow_origins=["https://xxx.github.io"],
allow_origin_regex=r"https://xxx\.github\.io$",
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
expose_headers=["*"],
max_age=86400,
)
# =========================
# 4) LLM 实例与默认 system prompt
# =========================
"""
llm:全局默认的 LLM 实例(当前代码里其实没有直接用到它)
- 它可以留作未来扩展:例如你想提供一个"不带 system prompt"的接口
- 或者用于"健康检查时顺便做一个轻量模型连通测试"
"""
llm = MyGeminiLLM()
"""
DEFAULT_CUTE_SYSTEM_PROMPT:默认系统提示词
- 当请求不传 system_prompt 时,就用这个
- system prompt 本质上是一段"对模型的指令/角色设定"
"""
DEFAULT_CUTE_SYSTEM_PROMPT = "请用可爱的语气回答,简洁、温柔,像小可爱一样~"
# =========================
# 5) 定义请求体结构(Pydantic)
# =========================
"""
FastAPI 会把请求 JSON 自动解析成你定义的 Pydantic 模型
好处:
- 自动校验类型
- 自动生成 Swagger 文档(/docs)
- 代码可读性强(请求体结构清晰)
"""
class QuestionRequest(BaseModel):
# question:用户输入的问题(必填)
question: str
# system_prompt:系统提示词(可选)
# Optional[str] = None 表示:可以不传
system_prompt: Optional[str] = None
# =========================
# 6) 健康检查接口
# =========================
@app.get("/health")
def health():
"""
GET /health
用途:
- 部署平台(Render等)常用来做健康检查
- 你也能用浏览器直接访问确认服务存活
返回:
{"ok": True}
"""
return {"ok": True}
# =========================
# 7) 首页接口:返回 HTML
# =========================
@app.get("/", response_class=HTMLResponse)
def index():
"""
GET /
用途:
- 给人类看的快速首页
- 不用模板文件(避免部署环境找不到 templates 目录导致报错)
- 简单展示 /health 和 /ask 的用法
注意:
- response_class=HTMLResponse 表示返回的是 HTML 字符串,而不是 JSON
"""
return """
<!doctype html>
<html lang="zh">
<head><meta charset="utf-8"><title>MyAgent API</title></head>
<body>
<h2>MyAgent API is running</h2>
<p>Health: <a href="/health">/health</a></p>
<p>Use <code>POST /ask</code> with JSON: {"question":"..."}</p>
</body>
</html>
"""
# =========================
# 8) 核心接口:问答 /ask
# =========================
@app.post("/ask")
def ask_question(req: QuestionRequest):
"""
POST /ask
输入:
- JSON 请求体会被解析成 QuestionRequest
- req.question:用户问题
- req.system_prompt(可选):系统提示词
输出:
- JSON:{"answer": "..."}
"""
# 关键逻辑:system_prompt 的"默认值处理"
# - 如果 req.system_prompt 是 None 或 "",就使用默认可爱 prompt
# - 这样前端不传时也能得到风格一致的输出
system_prompt = req.system_prompt or DEFAULT_CUTE_SYSTEM_PROMPT
"""
每次请求都创建一个 active_llm 的意义:
1) 隔离不同请求之间的上下文/配置
- 例如每个请求 system prompt 不同
2) 避免多线程/并发情况下共享状态导致混乱
3) 更容易做"按用户/按会话"扩展
"""
active_llm = MyCustomGeminiLLM(prefix=system_prompt)
"""
调用模型生成答案
- max_output_tokens=2048:控制输出长度,避免回答被截断
- 这里是同步调用;如果模型调用耗时长,未来可以改成 async 或后台队列
"""
answer = active_llm.generate(req.question, max_output_tokens=2048)
# 返回 JSON,字段名固定为 answer,确保前端兼容
return JSONResponse({"answer": answer})4. 逐个知识点拆解(并给出可扩展方向)
4.1 FastAPI:你现在用到的核心能力有哪些?
你已经用到了
-
FastAPI():创建应用 -
装饰器路由:
@app.get("/health")@app.get("/")@app.post("/ask")
-
response_class=HTMLResponse:返回 HTML -
JSONResponse:返回 JSON -
请求体模型
BaseModel:自动解析与校验
可扩展方向
- 自动文档
-
FastAPI 会自动提供:
/docs(Swagger UI)/redoc(ReDoc)
-
这对于调试接口非常有用
- 状态码与错误处理
-
目前
/ask里如果模型调用失败,可能直接抛异常导致 500 -
可以用:
from fastapi import HTTPException- 自己捕获异常并返回更友好的错误信息
- 异步(async)
- 如果模型调用 I/O 很重(网络请求),可以把接口改成
async def - 但要注意:如果
generate()是阻塞函数,需要配合线程池或异步 SDK
4.2 CORS(CORSMiddleware):为什么你必须配置它?
浏览器同源策略(非常关键)
如果不配置 CORS,你前端会遇到类似错误:
- "has been blocked by CORS policy"
- 预检请求(OPTIONS)失败
你当前的配置解释
allow_origins=["https://xxx.github.io"]
只允许这个来源访问(白名单思路)allow_origin_regex=...
用正则再次限制来源(更灵活,但要写对)allow_methods=["*"]/allow_headers=["*"]
允许所有方法和请求头,开发阶段省事max_age=86400
浏览器缓存预检结果一天,减少 OPTIONS 次数
可扩展方向(安全与多环境)
- 开发环境 + 生产环境分离
-
开发时可能是:
http://localhost:5173(Vite)http://localhost:3000
-
生产时才是 GitHub Pages
-
你可以用环境变量控制 allow_origins
- 更严格的 allow_headers
-
生产环境建议只开放你需要的 header,例如:
Content-TypeAuthorization
4.3 System Prompt:它到底是什么?为什么你这样写很实用?
概念解释(写给新手)
-
System Prompt 是"对模型的高级指令"
-
用来定义:
- 角色:你是老师/面试官/客服
- 风格:可爱/严谨/简洁
- 规则:不要输出敏感信息、回答格式必须是 JSON 等
你目前的设计优点
- 前端可传
system_prompt:可实现"一个接口多种人格" - 不传就走默认:保证体验一致
可扩展方向(非常推荐)
- Prompt 模板化
-
把常用风格做成枚举:
style=cutestyle=interviewerstyle=teacher
-
后端根据 style 映射到不同 system prompt
- 强约束输出格式
-
让模型输出固定 JSON 结构(用于前端渲染)
-
示例 system prompt:
- "请只输出 JSON,字段包含 summary、steps、code..."
- 安全策略(Guardrails)
-
在 system prompt 里加入禁止项:
- "不要泄露密钥,不要输出系统信息,不要编造来源"
-
在后端加入内容过滤/审计日志(生产必备)
4.4 Pydantic BaseModel:为什么它是 FastAPI 的"灵魂搭档"?
你当前的收益
- 前端传来的 JSON 会被自动解析
- 类型不对会自动返回 422(Unprocessable Entity)
/docs自动生成请求体结构说明
可扩展方向
- 增加字段
user_idsession_idtemperaturemax_output_tokenstop_pmodel_name
- 响应体也用 BaseModel
-
现在你直接返回
{"answer": answer} -
未来可以:
- 定义
AnswerResponse(BaseModel) - 让接口返回类型更加规范
- 定义
5. 每个方法(路由)可以怎么进一步扩展?
5.1 GET /health(健康检查)
当前只返回 {"ok": True}
扩展建议:
- 增加模型连通性检查(轻量)
- 增加版本信息/构建时间
- 增加依赖服务状态(例如数据库、缓存)
示例返回:
json
{
"ok": true,
"version": "1.0.3",
"llm": "reachable"
}5.2 GET /(首页)
目前返回纯 HTML,适合快速确认服务运行
扩展建议:
- 展示服务说明、示例请求
- 在页面里放一个简单的测试表单(手动提交 /ask)
5.3 POST /ask(核心)
现在逻辑很清晰:拿 system_prompt → 创建 active_llm → generate → 返回 answer
扩展建议(按重要度排序):
- 异常处理
- 模型超时、网络失败时返回可读错误
- 请求日志
-
记录:
- question(可脱敏)
- system_prompt(可只记录模板名)
- 耗时
- token 使用量(如果 SDK 提供)
- 限流与防滥用
- IP 限流
- API Key 鉴权(生产必备)
- 会话记忆(Chat History)
-
目前是单轮问答
-
未来支持多轮,需要:
- 前端传
messages: [{role, content}, ...] - 后端把历史拼接成 prompt 或使用模型原生对话格式
- 前端传
6. 前端如何调用(fetch 示例)
js
await fetch("https://你的后端域名/ask", {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({
question: "FastAPI 是什么?",
system_prompt: "请用老师的语气回答,分点说明,并给一个简单例子。"
})
});7. 常见坑与排查清单(新手必看)
7.1 前端报 CORS 错误
- 检查
allow_origins是否和前端域名完全一致(包含 https) - 检查是否有重定向导致来源不一致
- 检查浏览器 Network 面板里 OPTIONS 是否成功
7.2 /ask 返回很慢
-
模型调用耗时属于正常现象
-
解决方向:
- 异步化 / 后台队列
- 缓存常见问题
- 降低 max_output_tokens
7.3 回答被截断
- 提高
max_output_tokens - 也要注意模型本身的输出限制
8. 下一步准备怎么升级这个项目(路线图)
建议按这个顺序升级:
- 加异常处理(保证接口不会动不动 500)
- 加日志 + 统计(便于优化与排查)
- 加鉴权(API Key)
- 支持会话多轮(messages)
- 加缓存 / 限流(提升稳定性)
- 做一个更漂亮的前端测试页
9. 总结
这份 FastAPI 代码实现了一个非常典型的"前端调用后端 → 后端调用 LLM → 返回答案"的最小可用闭环,并且通过 system prompt 实现了风格控制,通过 CORSMiddleware 解决了 GitHub Pages 的跨域问题。
它非常适合作为学习博客的第一篇 AI 后端实战项目:短小、目标清晰、扩展空间大。
🌸 从 0 到 1:打造一个「可爱语气」AI 问答服务(FastAPI 入门实践)
适合初学者:看完你会明白 后端怎么接收问题、如何调用模型、如何返回给前端,以及 CORS 是什么、system prompt 又是什么。
10.附:给java的同学详细解释语法
一、先看全景:这个服务在干嘛?
可以把它想象成一个「自动回答问题的小窗口」:
前端把问题发给后端(/ask)
后端调用 AI 模型生成答案
统一返回 { "answer": "..." }
💡 关键点:我们还加了一个"可爱语气"的 system prompt,让回答更温柔可爱~
代码位置:/workspace/myagent/app.py 的 /ask 路由逻辑
来源:app.py 中 ask_question 逻辑
二、图解请求流程(更直观)
前端 → POST /ask → 后端 FastAPI → AI 模型生成 → 返回 answer
你可以把 /ask 想成一个"投递信箱"📮
前端把问题投进去,后端从信箱里取出来,交给 AI,AI 写好答案再寄回去。
三、核心代码拆解(逐句解释)
1)请求格式:QuestionRequest
python
class QuestionRequest(BaseModel):
question: str
system_prompt: Optional[str] = None✅ 表示请求体必须包含 question
✅ 可选的 system_prompt 用来控制回答风格
代码出处:app.py 中 QuestionRequest
2)默认可爱风格提示词
python
DEFAULT_CUTE_SYSTEM_PROMPT = "请用可爱的语气回答,简洁、温柔,像小可爱一样~"如果用户不传 system_prompt,就用这个默认提示词。
代码出处:app.py 中 DEFAULT_CUTE_SYSTEM_PROMPT
3)核心问答接口 /ask
python
system_prompt = req.system_prompt or DEFAULT_CUTE_SYSTEM_PROMPT
active_llm = MyCustomGeminiLLM(prefix=system_prompt)
answer = active_llm.generate(req.question, max_output_tokens=2048)
return JSONResponse({"answer": answer})✨ 逐步解释:
如果请求里有 system_prompt,就用它
否则使用默认可爱提示词
用自定义 LLM 加上 prefix,生成回答
返回 {"answer": ...} 给前端
代码出处:app.py 中 ask_question
四、CORS 是什么?为什么要设置?
你前端部署在 GitHub Pages(https://xxx.github.io),
后端在 Render(https://xxx.onrender.com)。
两个域名不同,所以浏览器会阻止请求,除非后端允许跨域(CORS)。
所以你在代码里加了:
allow_origins="https://xxx.github.io",
allow_origin_regex=r"https://xxx.github.io$",
这样浏览器才会放行你的前端请求。
代码出处:app.py 中 app.add_middleware
五、前端应该怎么调用?
请求格式必须是:
{
"question": "你的问题",
"system_prompt": "可选的提示词"
}
返回格式固定为:
{
"answer": "AI 回复"
}
六、拓展学习:还能加什么功能?
💡 如果你想继续升级:
✅ 历史记录:保存过去的问题和回答
✅ 流式输出:像 ChatGPT 一样"打字式回答"
✅ 多风格按钮:一键切换"可爱 / 学术 / 职场"
✅ 错误提示更友好:比如提示"后端没有启动"
七、总结(给初学者的你)
你已经完成了一个最基础但完整的 AI 服务:
✅ 懂 CORS
✅ 懂 API 求/返回
✅ 懂 system prompt
✅ 懂 FastAPI 路由