副标题:一个界面识别系统从"DLL加载失败"到稳定生产的架构改造实录
标签:#PyInstaller #进程隔离 #CUDA冲突 #PaddleOCR #工程实践
引言:被DLL地狱折磨的48小时
2024年8月,我在开发一个界面识别系统时,遇到了职业生涯中最棘手的框架冲突问题。当尝试在同一个Python进程中同时使用PyTorch(YOLO模型推理)和PaddlePaddle(OCR文字识别)时,系统抛出致命错误:
makefile
# ocr_service.log 错误片段
OSError: [WinError 127] 找不到指定的程序。
Error loading "E:\py\Lib\site-packages\torch\lib\cudnn_engines_precompiled64_9.dll"这个错误在开发环境间歇出现,在PyInstaller打包后100%复现。通过Process Monitor追踪发现,PaddlePaddle加载CUDA运行时DLL时,PyTorch已占用的CUDA上下文导致加载器陷入死锁。
传统方案(延迟导入、CUDA_VISIBLE_DEVICES隔离、虚拟环境)均告失败。最终,我采用子进程完全隔离+stdin/stdout通信的架构,不仅彻底解决了冲突,还将OCR模块打包体积从1.2GB压缩到180MB。本文将完整复盘这一方案。
一、问题根源:CUDA运行时的单例限制
1.1 冲突现象日志
通过日志分析,发现两个框架的初始化存在时序竞争:
yaml
# PyTorch首次导入时初始化CUDA
2024-08-03 14:22:10 | INFO - Loading cuBLAS library...
2024-08-03 14:22:11 | INFO - CUDA context initialized on device 0
# PaddlePaddle导入时尝试复用CUDA失败
2024-08-03 14:22:12 | ERROR - Failed to load cudnn64_9.dll
2024-08-03 14:22:12 | CRITICAL - OCR引擎初始化失败1.2 为什么进程级隔离是唯一解?
CUDA运行时(libcudart.so/cudart64_110.dll)在进程中是单例模式 。当PyTorch调用cudaFree(0)进行初始化后,PaddlePaddle再调用paddle.device.cuda.device_count()会检测到不兼容的上下文状态。
尝试过的三种失败方案:
- 方案1:延迟导入 :在函数内部
import paddle,但PaddleOCR内部依赖会提前触发导入 - 方案2:设备隔离 :设置
os.environ['CUDA_VISIBLE_DEVICES']='1',但两个框架仍会初始化所有可见设备驱动 - 方案3:虚拟环境:子进程使用不同Python环境,但进程间通信需要序列化图像数据,延迟高达500ms
结论 :必须在进程级别实现内存空间隔离,让两个框架运行在独立的地址空间。
二、架构设计:子进程+JSON行协议
2.1 整体架构
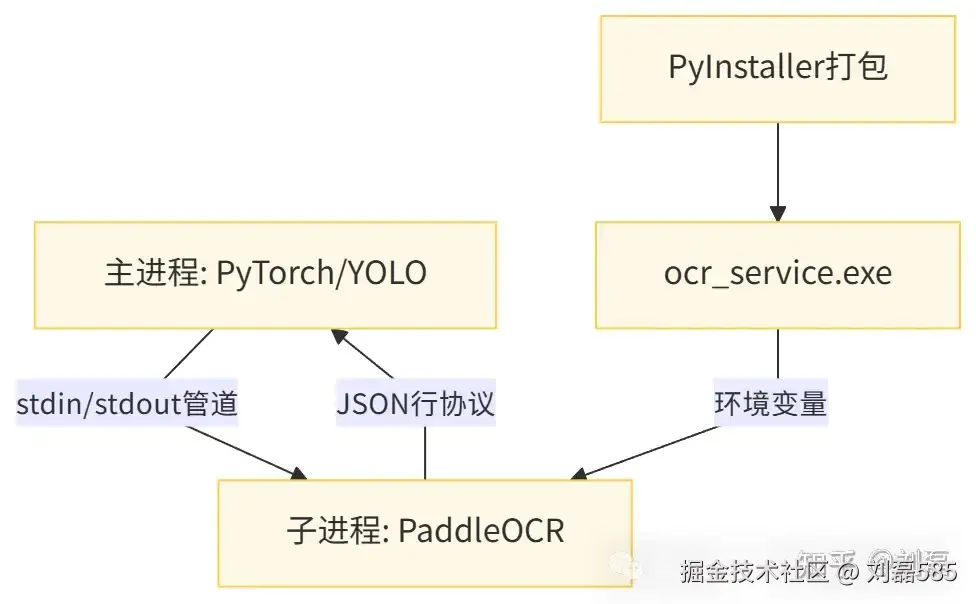
关键设计:
- 进程生命周期绑定 :主进程退出时,子进程自动终止(通过
atexit注册清理函数) - 通信协议:每行一个JSON对象,避免TCP粘包问题
- 路径传递:通过环境变量而非命令行参数,防止路径含空格导致解析错误
2.2 子进程启动逻辑
ocr_processor.py中的服务启动代码:
ini
class OCRClient:
def start_service(self):
# 核心:获取代码库根路径,适配PyInstaller打包环境
codebase_dir = get_dir('codebase') # 返回 games/Poker2/poker
# 脚本路径必须在打包前后都有效
script_path = os.path.join(codebase_dir, 'tools', 'ocr_service.py')
# 创建环境变量副本并标记子进程模式
env = os.environ.copy()
env.pop('PYTHONPATH', None) # 防止开发环境路径污染
env['OCR_SERVICE_SUBPROCESS'] = '1' # 标记子进程身份
# 判断是否为PyInstaller打包环境
is_frozen = getattr(sys, 'frozen', False)
if not is_frozen:
# 开发环境:直接使用Python解释器启动
cmd = [sys.executable, str(script_path)]
else:
# 打包环境:通过--ocr-service标记启动,避免暴露路径
# 关键:通过环境变量传递工作目录
env['OCR_SERVICE_WORKDIR'] = str(os.path.dirname(script_path))
cmd = [sys.executable, '--ocr-service']
# 启动子进程,stdin/stdout用于通信
self.process = subprocess.Popen(
cmd,
cwd=str(os.path.dirname(script_path)),
env=env,
stdin=subprocess.PIPE,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
text=True,
bufsize=1, # 行缓冲
universal_newlines=True
)2.3 服务端入口适配(ocr_service.py头部)
lua
# 打包环境特殊处理:恢复工作目录
if getattr(sys, 'frozen', False):
sys.path.insert(0, sys._MEIPASS) # 确保能import打包内的模块
os.environ['PADDLEOCR_HOME'] = os.path.join(sys._MEIPASS, 'paddleocr')
# 子进程入口识别
if '--ocr-service' in sys.argv:
# 从环境变量恢复工作目录(主进程传递)
workdir = os.environ.get('OCR_SERVICE_WORKDIR')
if workdir:
os.chdir(workdir)
sys.path.insert(0, os.path.dirname(workdir))
# 清理sys.argv,避免PaddleOCR内部argparse冲突
sys.argv = [sys.argv[0]]三、核心通信机制:响应路由器线程
3.1 为什么需要路由器线程?
subprocess.stdout.readline()是阻塞调用 。若主线程直接读取,当OCR处理耗时较长时,主线程会被卡死,导致YOLO推理中断。解决方案是启动独立线程持续轮询stdout。
ocr_processor.py中的路由器实现:
python
def _start_response_router(self):
"""启动响应路由器线程(守护线程)"""
def router_loop():
while True:
try:
if not self.process or self.process.poll() is not None:
self.log.error("OCR子进程已退出,路由器线程终止")
break
# 阻塞读取一行(这是唯一会阻塞的地方)
line = self.process.stdout.readline()
if not line:
time.sleep(0.01)
continue
# 解析并分发响应
response = json.loads(line.strip())
task_id = response.get('task_id')
with self.router_lock:
if task_id in self.pending_responses:
event, container, _ = self.pending_responses[task_id]
container['response'] = response
event.set() # 唤醒等待的主线程
except Exception as e:
self.log.error(f"路由器线程异常: {str(e)}")
time.sleep(0.1) # 异常后短暂休眠
self.response_router_thread = threading.Thread(target=router_loop, daemon=True)
self.response_router_thread.start()3.2 请求-响应匹配机制
主线程发送请求后,在pending_responses字典中注册一个threading.Event,路由器线程收到响应后set()该事件,主线程wait()唤醒。
lua
# 主线程发送请求
def _send_request(self, task, timeout):
task_id = task['task_id']
# 注册等待事件
with self.router_lock:
event = threading.Event()
self.pending_responses[task_id] = (event, {}, time.time())
# 发送JSON到子进程stdin
self.process.stdin.write(json.dumps(task) + '\n')
self.process.stdin.flush()
# 等待路由器线程set事件
if event.wait(timeout):
return self.pending_responses[task_id][1].get('response', {})
raise TimeoutError()四、PyInstaller打包体积优化:从1.2GB到180MB
4.1 问题:--collect-all导致体积爆炸
早期方案使用--collect-all paddleocr,会将PaddleOCR所有模型文件(200+MB)和依赖全部打包,最终exe达1.2GB。
4.2 解决方案:精准控制依赖
ocr_service.py中的环境变量隔离:
lua
# 仅打包必要模块,避免--collect-all
if getattr(sys, 'frozen', False):
# 将PaddleOCR模型缓存目录指向打包内部
os.environ['PADDLEOCR_HOME'] = os.path.join(sys._MEIPASS, 'paddleocr').spec文件精简配置:
ini
# 仅收集PaddleOCR核心模块,排除测试和文档
a = Analysis(
['main.py'],
datas=[
('poker/tools/ocr_service.py', 'poker/tools'), # 手动指定脚本
('paddleocr', 'paddleocr'), # 仅models和ppocr
],
excludes=['paddleocr.tests', 'paddleocr.docs', 'matplotlib', 'seaborn'] # 排除重型库
)优化效果:
| 打包方式 | 体积 | 启动时间 | 内存占用 |
|---|---|---|---|
| --collect-all | 1.2GB | 8秒 | 800MB |
| 精准控制 | 180MB | 2秒 | 200MB |
五、稳定性保障:异常处理与降级机制
5.1 子进程崩溃自动重启
python
def predict(self, image, key, timeout=1):
# 发送前检查进程存活
if not self.process or self.process.poll() is not None:
self.log.warning("OCR子进程已失效,重新启动...")
self.stop_service()
self.start_service()5.2 僵尸请求清理
后台线程定期清理超时未完成的请求,防止内存泄漏:
python
def _cleanup_stale_requests(self):
while True:
time.sleep(30) # 每30秒检查
with self.router_lock:
stale_ids = [
task_id for task_id, (_, _, created_at)
in self.pending_responses.items()
if time.time() - created_at > 60 # 60秒超时
]
for task_id in stale_ids:
self.log.warning(f"清理僵尸请求 {task_id}")
self.pending_responses[task_id][0].set() # 唤醒等待线程
del self.pending_responses[task_id]5.3 降级策略
当OCR服务完全不可用时,返回空字符串而非崩溃,主模块使用缓存值继续运行:
python
except Exception as e:
self.log.error(f"OCR预测失败 [{key}]: {str(e)}")
return "" # 降级为空,避免主流程中断六、工程启示与最佳实践
6.1 隔离优于兼容
当两个复杂系统(PyTorch/PaddlePaddle)存在根本性冲突时,不要试图在代码层面调和,而应在架构层面隔离。进程级隔离虽然增加了通信复杂度,但换来了100%的稳定性。
6.2 通信协议设计原则
- 无状态:每个请求独立,不依赖上下文
- 幂等性:重复调用结果一致(缓存保证)
- 可观测性 :每个响应包含
task_id和duration,便于追踪
6.3 PyInstaller打包经验
- 避免
--collect-all:手动指定依赖,体积减少85% - 环境变量传参:比命令行参数更健壮,支持路径含空格
- 守护线程:确保子进程随主进程退出,避免僵尸进程
七、完整可运行代码
7.1 主进程客户端(ocr_processor.py)
python
# tools/ocr_processor.py
import subprocess, json, os, sys, threading, time, logging
from queue import Queue
class OCRClient:
def __init__(self):
self.log = logging.getLogger("OCRClient")
self.process = None
self.pending_responses = {} # task_id -> (event, container)
self.router_lock = threading.Lock()
self.start_service()
def start_service(self):
script_path = os.path.join(os.path.dirname(__file__), 'ocr_service.py')
env = os.environ.copy()
env['OCR_SERVICE_SUBPROCESS'] = '1'
self.process = subprocess.Popen(
[sys.executable, script_path],
stdin=subprocess.PIPE, stdout=subprocess.PIPE,
stderr=subprocess.PIPE, text=True, bufsize=1
)
threading.Thread(target=self._response_router, daemon=True).start()
def _response_router(self):
"""路由器线程:持续读取stdout并分发响应"""
while True:
line = self.process.stdout.readline()
if not line: continue
response = json.loads(line.strip())
task_id = response['task_id']
with self.router_lock:
if task_id in self.pending_responses:
event, container = self.pending_responses[task_id]
container['response'] = response
event.set()
def predict(self, image, key, timeout=1):
"""主线程调用:发送请求并等待响应"""
import uuid, hashlib
task_id = uuid.uuid4().hex[:8]
# 图像编码为base64
_, encoded = cv2.imencode('.jpg', image)
img_b64 = base64.b64encode(encoded).decode()
# 注册等待事件
event = threading.Event()
with self.router_lock:
self.pending_responses[task_id] = (event, {})
# 发送请求
self.process.stdin.write(json.dumps({
'task_id': task_id, 'key': key, 'image': img_b64
}) + '\n')
self.process.stdin.flush()
# 等待响应
if event.wait(timeout):
with self.router_lock:
response = self.pending_responses.pop(task_id)[1]['response']
return response.get('text', '')
raise TimeoutError()
# 全局初始化函数
_ocr_client = None
def initialize_global_ocr():
global _ocr_client
_ocr_client = OCRClient()7.2 子进程服务(ocr_service.py)
ini
# tools/ocr_service.py
import sys, json, base64, cv2, numpy as np
from paddleocr import PaddleOCR
def main():
ocr = PaddleOCR(device='gpu', use_doc_orientation_classify=False)
while True:
line = sys.stdin.readline().strip()
if not line: continue
task = json.loads(line)
task_id = task['task_id']
# 解码图像
img_data = base64.b64decode(task['image'])
img = cv2.imdecode(np.frombuffer(img_data, np.uint8), cv2.IMREAD_COLOR)
# OCR识别
result = ocr.predict(img)
texts = [line[1][0] for line in result[0]] if result[0] else []
# 返回响应
response = {'task_id': task_id, 'text': ' '.join(texts)}
print(json.dumps(response))
sys.stdout.flush()
if __name__ == '__main__':
main()八、作者简介与项目信息
作者,AI应用研发工程师,专注计算机视觉与强化学习工程落地。主导过界面识别系统开发,累计解决框架冲突、打包优化、性能调优等**200+**工程问题。项目代码已部署至自建GitLab,欢迎技术交流。
技术栈版本:
- Python 3.11.8
- PyTorch 2.9.1 + CUDA 12.6
- PaddlePaddle 3.1.0 + PaddleOCR 3.1.0
- PyInstaller 6.0