目标识别精度指标与IoU及置信度关系辨析
一、目标识别
1.1目标识别简介
目标识别,也称为目标检测,是计算机视觉领域中的一个分支,通常与图像分类、语义分割和实例分割并列。目标识别需要输出图片中包含的目标类别,以及目标所在的边界框,同时还可以输出目标类别的置信度。

1.2目标识别两大流派
目标识别领域可分为以下两大流派:以R-CNN为代表的two-stage流派,以YOLO为首的one-stage流派。
一阶段和两阶段流派对比如下:
| ------ | 识别过程 | 性能 |
|---|---|---|
| 两阶段 | 先提取可能包含目标的区域,再对每个区域进行识别,最后给出结果 | 通常精度高,速度慢 |
| 一阶段 | 定位和分类耦合在一起,同步完成 | 通常精度低,速度快 |
二、识别阈值参数与精度指标
识别阈值参数主要为置信度阈值与IoU阈值。
目标识别精度的指标主要有:precision(精确率)、recall(召回率)、F1-score(F1分数)、mAP。
下面分别进行概念介绍和计算方式。
2.1识别阈值参数
2.1.1置信度阈值
目标识别输出的预测框会有一个置信度,置信度的高低代表模型对预测结果有多大的把握。置信度阈值就是人为设置的一个筛选参数,只输出置信度高的预测框。
显然置信度阈值的设定会影响模型精度,某种意义上该参数就是在设置模型预测的谨慎程度。置信度阈值越高,模型越保守,不会将没有把握的目标识别出来,因此必然会漏掉一些并不明显的目标。
2.1.2IoU阈值
IoU定义为预测框与真实框之间的重合度,IoU越大说明预测框越接近于真实框,预测效果越好,计算公式如下:
I o U = P r e ∩ T r u e P r e ∪ T r u e IoU = \frac{Pre∩True}{Pre∪True} IoU=Pre∪TruePre∩True
IoU阈值就是设定一个判定界限,高于该阈值的预测框才能够说是正确识别,而低于该阈值则判定为错误识别。
2.2Precision(精确率)
precision指某一类目标识别正确的数量占该类总识别数量的比率,它的计算公式如下:
p r e c i s i o n = T P T P + F P precision = \frac{TP}{TP+FP} precision=TP+FPTP
TP指识别正确的目标数,FP指识别错误的目标数,即将其他目标错误识别为此目标的数量。
通常说的误检率就等于1-precision。
2.3Recall(召回率)
recall指某一类目标识别正确的数量占该类总数量的比率,它的计算公式如下:
r e c a l l = T P T P + F N recall = \frac{TP}{TP+FN} recall=TP+FNTP
TP指识别正确的目标数,FN指未能识别出来的目标数,即将此目标识别为了其他目标的数量。
通常说的漏检率就等于1-recall。
2.4F1-score(F1分数)
precision与recall通常情况下相互矛盾,当提高置信度阈值时,会提高precision降低recall,置信度阈值降低则相反。
因此单一的P或R不能够全面地衡量模型精度,就有了综合两者的指标F1-score,它被定义为精确率和召回率的调和平均数,计算公式如下:
F 1 = 2 ∗ P ∗ R P + R F1 = \frac{2*P*R}{P+R} F1=P+R2∗P∗R
从计算公式可以看出,当precision与recall同时较大时F1才会比较大,如果precision与recall失衡,一个明显高于另一个的情况下F1会比较小。这说明F1分数的值能够较好地综合衡量模型的识别精度。
2.5mAP
2.5.1AP
2.5.1.1概念与计算方法
如上一小节所说,单一的precision与recall无法准确地表示模型识别精度,因而提出了F1-score用于综合两者。同样地,AP也是综合precision与recall的一种指标。
AP(Average Precision),中文为平均精确率,AP值是PR曲线的面积,即以Recall为横坐标对Precision进行累加求和,也就是积分运算。
PR曲线即为置信度阈值从0到1对应的P、R值绘制的曲线,如下图所示:
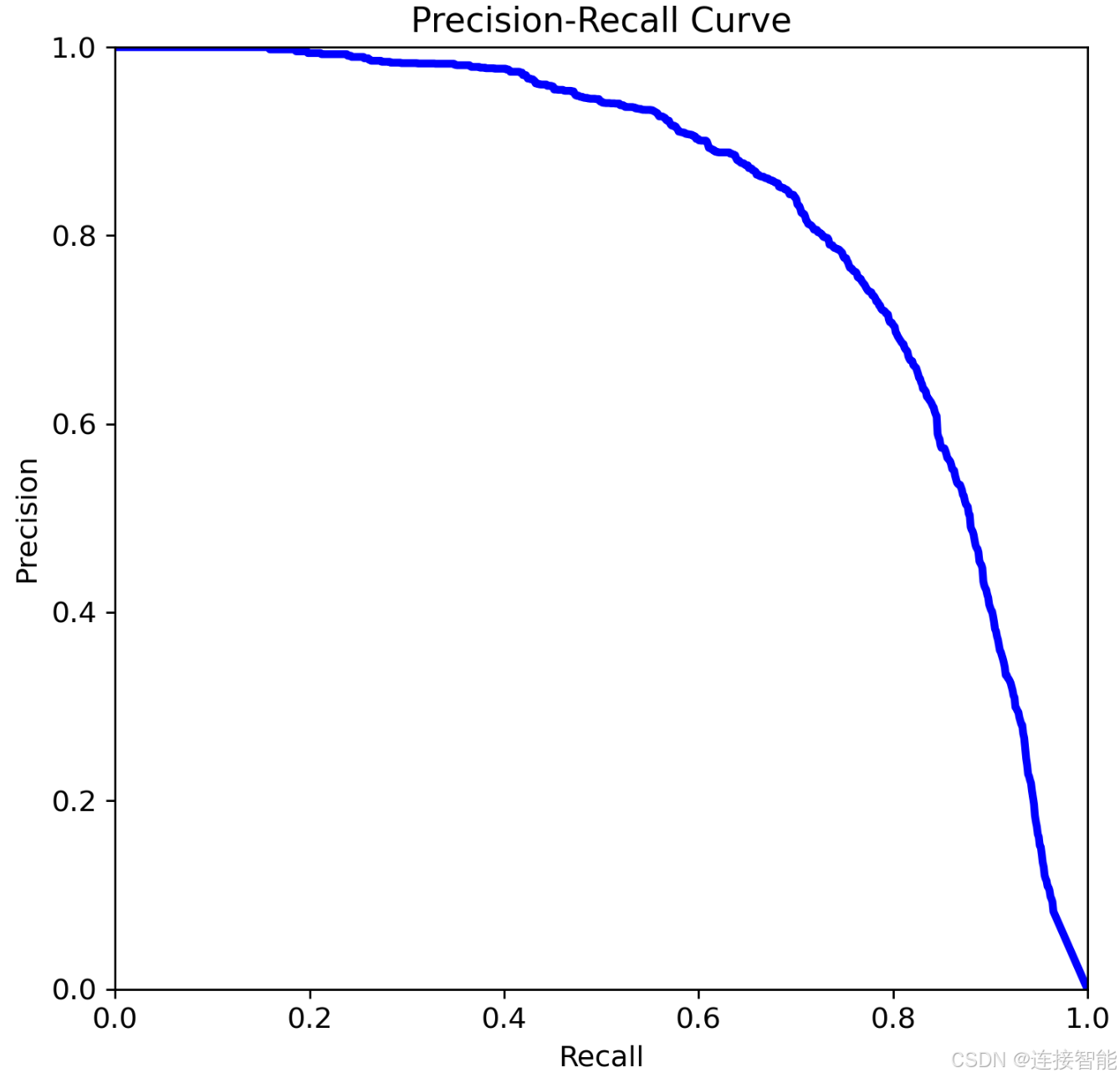
上图是一个典型的PR曲线图,曲线形状与上一小节所说precision与recall之间的矛盾关系一致,当recall近似于0时,说明此时置信度阈值非常大,所以precision很高接近于1,随着recall增加precision会逐渐降低,最后recall接近于1而precision近似于0。
AP值就是该曲线与XY轴围成的面积。
2.5.1.2python计算代码
YOLOv11与YOLOv26的开源代码中就包含了AP的计算代码,代码如下:
python
def compute_ap(recall: list[float], precision: list[float]) -> tuple[float, np.ndarray, np.ndarray]:
"""Compute the average precision (AP) given the recall and precision curves.
Args:
recall (list): The recall curve.
precision (list): The precision curve.
Returns:
ap (float): Average precision.
mpre (np.ndarray): Precision envelope curve.
mrec (np.ndarray): Modified recall curve with sentinel values added at the beginning and end.
"""
# Append sentinel values to beginning and end
mrec = np.concatenate(([0.0], recall, [1.0]))
mpre = np.concatenate(([1.0], precision, [0.0]))
# Compute the precision envelope
mpre = np.flip(np.maximum.accumulate(np.flip(mpre)))
# Integrate area under curve
method = "interp" # methods: 'continuous', 'interp'
if method == "interp":
x = np.linspace(0, 1, 101) # 101-point interp (COCO)
func = np.trapezoid if checks.check_version(np.__version__, ">=2.0") else np.trapz # np.trapz deprecated
ap = func(np.interp(x, mrec, mpre), x) # integrate
else: # 'continuous'
i = np.where(mrec[1:] != mrec[:-1])[0] # points where x-axis (recall) changes
ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1]) # area under curve
return ap, mpre, mrec上述代码关键步骤如下:
- 因为实际的P、R不一定能够包含0和1,而为了构造一个完整区间,使用np.concatenate函数添加0.0和1.0;
- 原始PR曲线通常是锯齿状的,即会有部分recall增加而precision也变大的与理论不符的特殊点,因此使用np.flip(np.maximum.accumulate(np.flip(mpre))),得到一条单调不增的PR曲线;
- 上面得到的是一组离散PR点,所以要进行插值近似得到曲线,代码中设定插值101个PR点,然后使用np.trapezoid函数进行数值积分运算,得到最终ap值。
2.5.2mAP
mAP(mean Average Precision)为平均AP值,就是对所有类的AP取平均值。例如有80个类,那么对每个类按照上一小节的方式计算对应的AP值,然后80个AP取均值。
2.5.3mAP@0.5与IoU阈值
如前文所述,IoU阈值影响预测框的判断正确与否,因此设定不同的IoU阈值会有不同的mAP值。
mAP@0.5,就代表IoU阈值为0.5时得到的mAP值,也可表示为mAP50,二者含义相同。
同样地,mAP@0.75,或者mAP75,就代表IoU阈值为0.75时得到的mAP值。显然同一个模型下mAP@0.75会小于mAP@0.5。
mAP50-95,代表IoU阈值从0.5到0.95范围内以0.05为分度值共10个IoU阈值下的mAP的平均值。
如果mAP后没有任何后缀,那么一般代表mAP50-95。