一.梳理项目
1.1 框架:
1.主要精力放到 UDP(课设要做的"数据报发送/回环/上层业务")
2.ARP模块:让电脑通过 ARP 得到你的 MAC(不然电脑发不了 IP/UDP 给你)
3.ICMP 模块(ICMP Echo请求与应答):
-
输入:GMII RX 字节流(gmii_rx_dv + gmii_rxd)
-
内部:识别"这是不是发给我的 ping"→ 把 ping 的 payload 收下来(用 FIFO 缓存)→ 准备回包
-
输出:GMII TX 字节流(gmii_tx_en + gmii_txd),回一个 Echo Reply
意义:
-
最容易验证 IP 层/以太网层你做对了(电脑 ping 一下就知道)
-
UDP 出问题时,你至少能用 ping 判断:是"底层没通"还是"UDP 逻辑没通"
4.所以你后面做 UDP,把 ICMP 当库模块直接复用,完全 OK。
1.2 最小可用协议栈(mini stack)工作过程:
接收方向(网线 → FPGA)
-
PHY(RGMII) 把数据送进 FPGA(RGMII 是 DDR 4bit + 控制)
-
gmii_to_rgmii 做两件事:
-
DDR→SDR(4bit DDR 合成 8bit GMII)
-
RX 时钟对齐(配合 PLL 相位偏移,保证采样更稳)
-
-
得到统一的 GMII RX 字节流:
gmii_rx_dv + gmii_rxd[7:0]
然后这一条 RX 字节流会被"并联"喂给多个协议模块去侦听/识别:
-
arp_rx:如果是 ARP,就解析并更新"对方 IP/MAC"
-
icmp_rx:如果是 IP 且 protocol=ICMP 且 type=Echo Request,就把 payload 吐出来
-
udp_rx:如果是 IP 且 protocol=UDP,就把 UDP payload 吐出来
说明:
1.这些模块不是同时都"接管",而是各自做判断:不是自己的包就忽略。
2.需要用到业务侧准备一个 FIFO/ROM/RAM,一是,你需要解析源IP,MAC等,二是,数据(payload)需要处理,选择什么存储器,结合各个存储模块的特点取决于项目要求,
其中原子的udp数据回环实验就用FIFO(先进先出),即把接收到的 payload 原样回发(ping 回包、udp loop 回包)。但是:接收是"边来边到",发送要"先发头再发 payload",所以需要 FIFO 暂存 payload。
发送方向(FPGA → 网线)
-
ARP/ICMP/UDP 各自都有自己的 tx 组包器,都能输出一条 GMII TX 字节流
-
eth_ctrl 做"仲裁/切换":
-
现在该谁发?ARP 还是 ICMP 还是 UDP?
-
只能选一个,把它的
gmii_tx_en/gmii_txd接到总线输出
-
-
总 GMII TX 字节流再经 gmii_to_rgmii 变回 RGMII → PHY 发到网线上
1.3 做 UDP,整体就是"加一个 udp 积木 + eth_ctrl 扩展选择"
最终 UDP 课设通常就是:
-
RX:udp_rx 把 payload 吐给你的业务模块(FIFO/缓存/处理)
-
TX:你的业务模块提供要发的 payload,udp_tx 负责封装:以太网头 + IP头 + UDP头 + payload + CRC
二.正点原子以太网UDP数据环回实验学习
2.1总览:
项目结构:RTL目录("电路逻辑原理",偏行为/结构的数字电路原理)
在 eth_udp_loop.v 里,跟 UDP 相关的链路基本是:
PHY(RGMII) ↔ gmii_to_rgmii ↔(GMII字节流)↔ udp(udp_rx + udp_tx + crc32) ↔ eth_ctrl ↔ FIFO
其中:
1.udp:udp协议实现:
-
udp/udp_rx.v :
前导码→以太网头→IP头(protocol=17)→UDP头(length)→吐 payload(rec_en/rec_data)
-
udp/udp_tx.v :
组帧头/IP头/UDP头→从 FIFO 读 payload → 不够 46 字节则补齐 → CRC
2.eth_ctrl:仲裁/切换(ARP/ICMP/UDP 谁在发,就把谁的 gmii_tx_en/gmii_txd 接到总线上;同时也把 RX 的 rec_* 选一路写 FIFO)
3.async_fifo_2048x8b:缓存 payload(收到的 UDP 数据先存起来,回发时再读出来)
4.gmii_to_rgmii:RGMII(4bit DDR) ⇄ GMII(8bit SDR) 的物理层"字节化/对齐"
其中:需要掌握并在你项目复用的"库接口",主要就是 udp 模块的"用户接口"那一组信号。
2.2 UDP 模块对外端口
分 3 类:GMII口、用户口、目的地址口
A. GMII 接口(底层字节流口:接 PHY/接 gmii_to_rgmii)
这些你一般照抄工程接法就行:
-
gmii_rx_clk:接收时钟(每个 clk 来一个字节节拍) -
gmii_rx_dv:接收有效(=1 时gmii_rxd[7:0]是有效字节) -
gmii_rxd[7:0]:接收字节数据 -
gmii_tx_clk:发送时钟(发送 FSM 跑在这个时钟域) -
gmii_tx_en:发送有效(=1 时gmii_txd[7:0]输出到 PHY) -
gmii_txd[7:0]:发送字节数据
B. 用户接口(重点:你上层逻辑怎么喂数据、怎么收数据)------这就是你要当"库接口"的部分
1)接收方向
-
rec_en:接收数据有效脉冲rec_en=1的那些拍:rec_data才是 UDP payload 的字节
-
rec_data[7:0]:接收到的 UDP payload 字节流 -
rec_byte_num[15:0]:本次收到的 payload 总字节数 -
rec_pkt_done:整包 payload 收完了(包结束指示)
总结: udp_rx 把"UDP 数据部分"抽出来,像 UART 一样吐给你:rec_en + rec_data;包结束后给你 rec_pkt_done,同时 rec_byte_num 告诉你长度。
2)发送方向
-
tx_start_en:开始发送的"启动脉冲"(通常给 1 个 clk 的脉冲)- udp_tx 在看到它后,会"锁存本次 tx_byte_num",然后开始组包发送
-
tx_byte_num[15:0]:本次要发送的 payload 字节数 -
tx_req:udp_tx 向你"要数据"的请求(读数据请求)- udp_tx 每需要一个 payload 字节,就会拉高
tx_req
- udp_tx 每需要一个 payload 字节,就会拉高
-
tx_data[7:0]:你提供给 udp_tx 的 payload 字节 -
tx_done:本次 UDP 包发送完成指示
关键握手:udp_tx 是"主动方",它通过
tx_req来拉取你的数据;你要保证tx_req来了以后,你能把下一字节放到tx_data(这个工程用 FIFO + 延迟对齐来做的)。
C 接口时序分析:(给出TX过程为例)

当复位解除(rst_n=1)并且上层逻辑通过 tx_start_en 发出一次"启动发包"的请求后,它会从空闲态切换到忙碌态,开始把一帧完整的 UDP/IP/以太网帧内容按顺序逐字节推出去。上层逻辑负责告诉它"发给谁、发多少、数据从哪里来",真正的"组头、按协议格式排字节、最后补 CRC"都是 udp_tx 内部一次性完成的。
波形中最关键的启动动作就是 tx_start_en 的那个短高脉冲。它通常只需要维持一个时钟周期(也可以更久,但规范做法是一拍脉冲),作用类似于"按下发送按钮"。在 tx_start_en 发生的附近,tx_byte_num、des_mac[47:0]、des_ip[31:0] 必须已经稳定,因为 udp_tx 会在这个时刻把这些参数锁存下来:其中 tx_byte_num 代表你希望发送的 UDP payload(数据区)字节数,udp_tx 会利用它计算 UDP 头部里的长度字段(UDP length = 8 + payload_len),同时也会计算 IP 头部的 total length(IP total = 20 + UDP length),并用这个长度来决定后续"数据区到底要发多少个字节"。
而 des_mac 与 des_ip 则直接参与以太网头/IP头的目的地址字段填写,决定这包最终"发给哪台设备"。因此从接口设计角度看,tx_start_en 是一次事务的起点,tx_byte_num/des_mac/des_ip 是本次事务的配置参数,在发包开始后应保持不变直到发包结束,至少要保证在锁存时刻稳定。
当 tx_start_en 触发后,你会看到 gmii_tx_en 很快被拉高,并在整个发包窗口内保持为 1。gmii_tx_en 的含义非常朴素:它就是"当前这一个时钟拍,GMII 发送数据字节有效"。只要 gmii_tx_en=1,外部 PHY 就会把同一拍 gmii_txd[7:0] 上的字节当成要发送到网线上的真实数据;反过来,只要 gmii_tx_en=0,那一拍 gmii_txd 即使变化也不会被当成有效帧内容。
换句话说,gmii_tx_en 把连续的若干个时钟拍"圈起来",圈住的这段就是一帧从起始到结束的完整发送窗口。图中 gmii_txd[7:0] 在这段窗口内依次标注了 8'h55、8'hd5、eth_head、ip_head+udp_head、data、CRC校验,这恰好对应了以太网帧的典型发送顺序:先发前导码(Preamble,通常 7 个字节的 0x55),再发帧开始定界符 SFD(1 个字节 0xD5),接着发以太网头(目的 MAC、源 MAC、类型字段),再发 IP 头与 UDP 头,之后才是你真正关心的数据区 payload,最后以 4 字节的 CRC32 作为帧校验序列(FCS)收尾。也就是说,udp_tx 并不是"只负责 UDP",它在这个工程里承担了"把 UDP 包封装成 IP 包、再封装成以太网帧,并最终以 GMII 字节流形式发出去"的全部发送任务,这就是为什么它会输出完整的 preamble/SFD/CRC,而不仅仅是 UDP payload。
在发送流程中,tx_req 与 tx_data 这一对信号体现了 udp_tx 和"数据提供者"(你自己的业务模块、FIFO、RAM 或其他缓存)之间的握手关系,也是这张图里最像"库接口"的部分。因为 udp_tx 可以自己生成所有头部字段和 CRC,但它不可能凭空生成 payload,所以它采用"拉取式"的接口:当状态机推进到 data 区时,它开始拉高 tx_req,含义是"我进入 payload 段了,我每个时钟拍都需要一个新的数据字节,请你给我"。此时 tx_data 必须与 tx_req 配合,在 tx_req=1 的每个有效拍上提供一个正确的 payload 字节,udp_tx 会把这一拍的 tx_data 采样下来,并把它作为 data 区的下一个字节输出到 gmii_txd[7:0]。从波形上看,tx_req 的高电平持续了整段 data 区;与此同时,tx_data 在 data 区段不断变化,表示数据源正在连续输出字节流。更进一步地说,tx_req 的持续拍数与 tx_byte_num 直接对应:如果 tx_byte_num=N,那么 udp_tx 会请求 N 个字节数据,最终 data 区就发 N 个字节;数据提供者只要保证在这 N 个请求拍里依次给出 N 个字节即可。这个握手逻辑的好处是明显的:上层不用和 udp_tx 对齐"什么时候发头、什么时候发数据",只需要在 tx_req 来的时候供数即可,工程结构就会非常清晰。
图中的 crc_en、crc_clr、crc_data[31:0]、crc_next[7:0] 则反映了 crc32_d8 积木与 udp_tx 的配合方式。可以把 CRC 模块理解为一个"并行的随包计数器":在真正开始计算一帧 CRC 之前,udp_tx 会通过 crc_clr 给 CRC 模块一个清零/初始化动作;随后在 crc_en=1 的时间段内,udp_tx 每输出一个有效字节(严格来说是从以太网帧头开始到 payload 结束的那段需要计入 FCS 的字节范围),都会把该字节同时送入 CRC 模块,让 CRC 模块更新内部 CRC 寄存器。等到数据区结束后,CRC 模块内部累积得到最终的 CRC32 值,udp_tx 再把它拆成 4 个字节作为"CRC校验"段输出到 gmii_txd 的最后四拍。你会看到在接近尾部的位置,crc_en 会被拉低,表示"CRC 累积结束",接着出现 CRC 输出阶段,然后整个发送窗口结束。也就是说,CRC 的存在并不改变你提供 tx_data 的方式,它只是 udp_tx 在发包期间同步做的一件"伴随计算",最后将计算结果追加到帧尾。
最后,当 udp_tx 把整个帧(包括 CRC32)发送完毕后,你会看到 tx_done 出现一个短脉冲。tx_done 的意义与 tx_start_en 恰好对称:tx_start_en 表示"开始一次发送事务",tx_done 表示"这次发送事务已完成"。一旦 tx_done 到来,上层逻辑就可以认为这一包 UDP 已经被完整推送到了 GMII 输出并进入 PHY 发送链路;此时可以选择立即准备下一包(比如周期发送),或者等待新的触发条件。与此同时,gmii_tx_en 会被拉低回到 0,模块回到空闲状态,等待下一次 tx_start_en。
总结:把整张波形浓缩成一句"工程上最重要的时序原则",就是:启动时锁存参数(tx_start_en + tx_byte_num + des_ip/des_mac),随后 udp_tx 自己发头并在 data 区通过 tx_req 拉取 tx_data,直到请求满 tx_byte_num 个字节,然后补 CRC 并用 tx_done 收尾。你只要牢牢记住这条原则,后面无论你是用 FIFO 回放、用 ROM 固定字符串、还是用计数器/采样数据作为 payload,只要能在 tx_req 的节拍下稳定输出 tx_data,并在触发时刻给对正确的长度与目的地址,你的"主动发送 UDP"就一定能跑通。
状态图梳理:(正点原子手册图)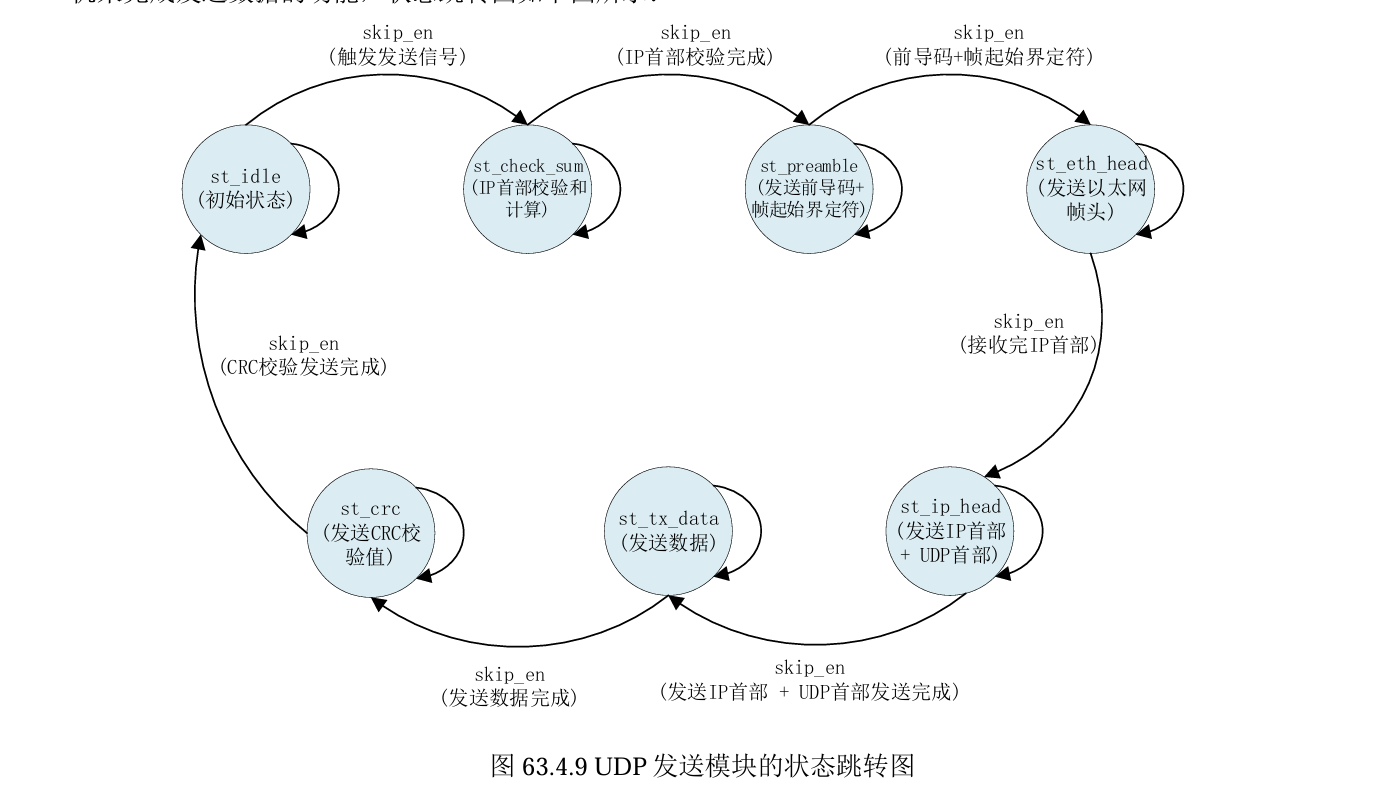
D. 目的地址输入(发包要填头:发给谁)
-
des_mac[47:0]:目的 MAC -
des_ip[31:0]:目的 IP
在这个工程里,它们不是你手填的,而是 从 ARP 模块学出来的(ARP 学到"电脑 IP 对应的电脑 MAC"后,提供给 UDP/ICMP 用)。
2.3 整个 UDP loopback 工作过程
说明:UDP 回环的"触发逻辑":tx_start_en / tx_byte_num
在 eth_udp_loop.v 里做了最简单的回环:
-
tx_start_en = rec_pkt_done;→ 收到一包 UDP 结束,就立刻启动发一包
-
tx_byte_num = rec_byte_num;→ 发回去的 payload 长度 = 收到的 payload 长度
所以你看懂了这两句,就知道这是 "UDP loopback"。
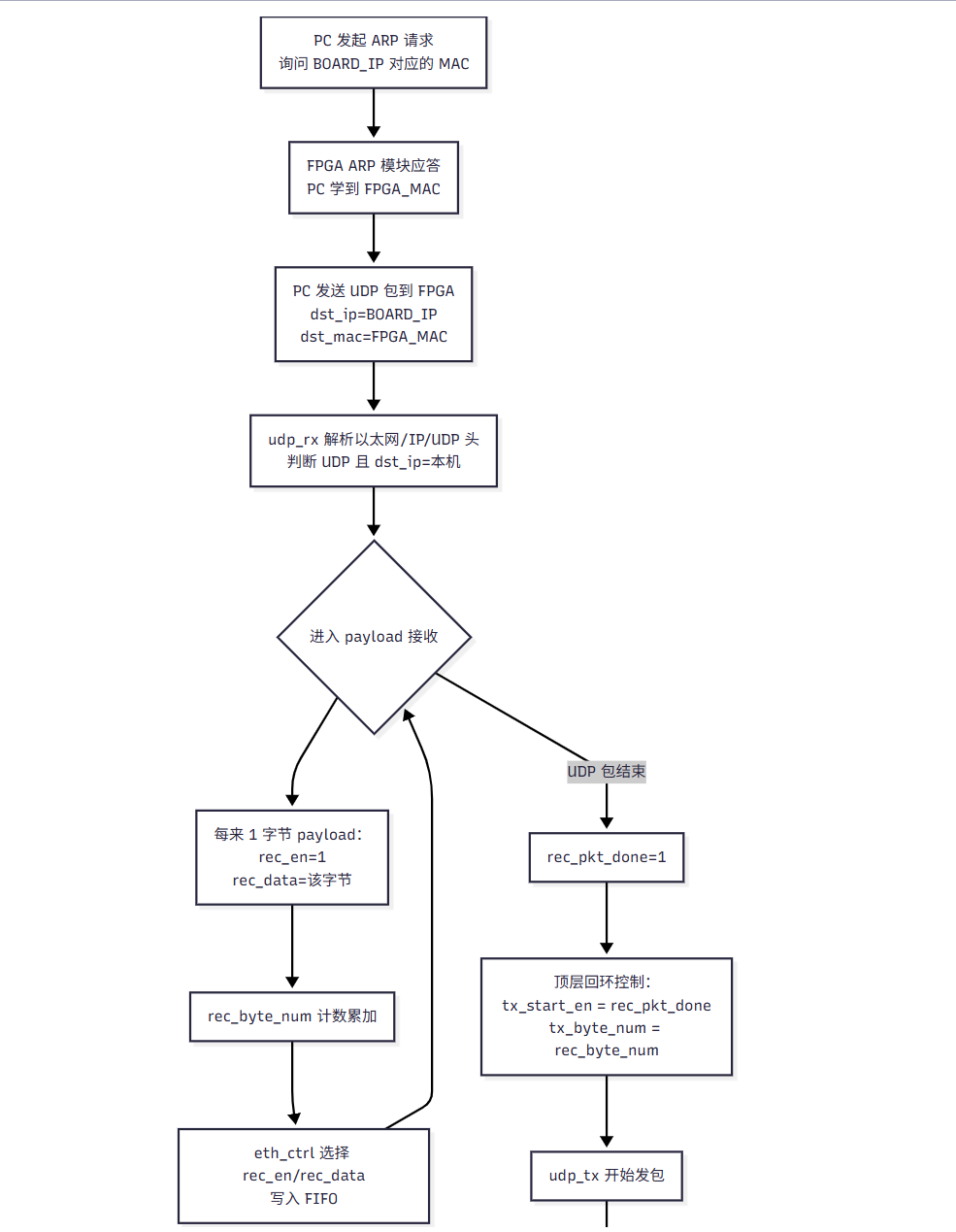
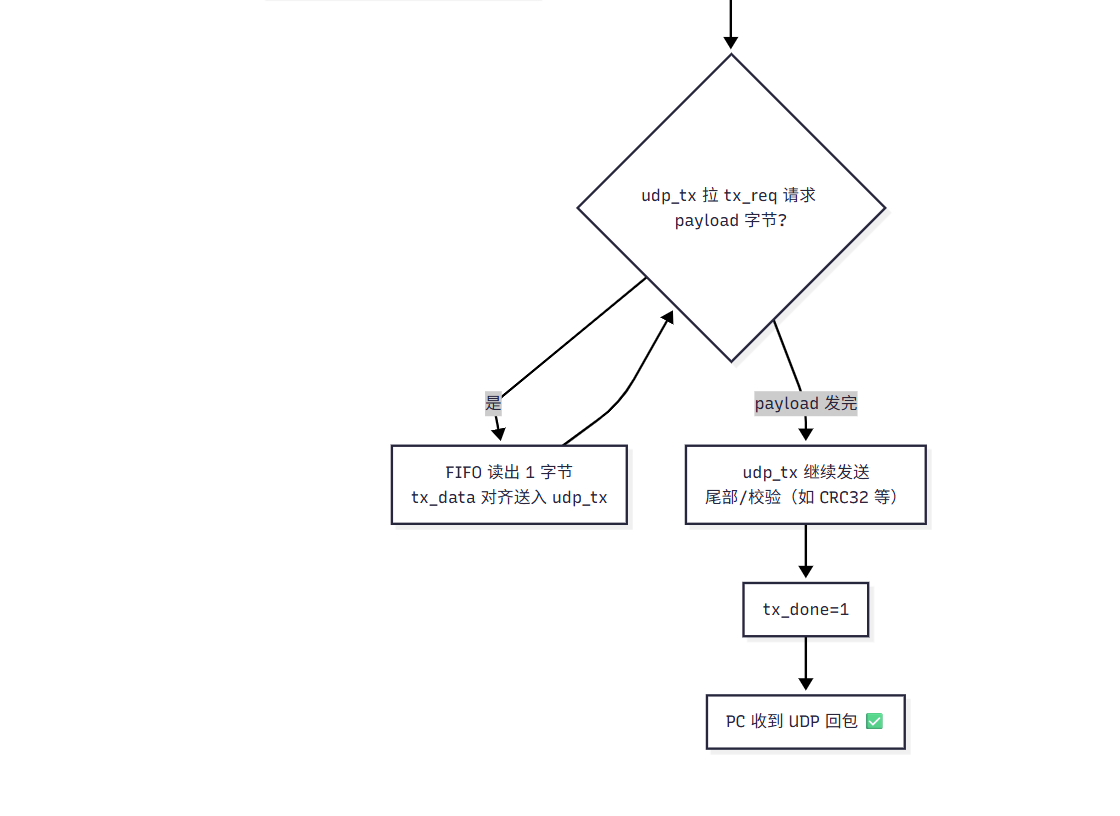
2.4 UDP 发送电路实现思路
前面思路跟 UDP loopback一样,
-
电脑先通过 ARP 让 FPGA 学到电脑的 MAC(这样 FPGA 才知道"回包要发给谁")
-
电脑发 UDP 包到 FPGA(目标 IP=BOARD_IP,目标 MAC=FPGA MAC)
(因为板子发送总是要触发的,什么时候发,可以是接收到上位机指令,这个指令只是不是串口,而是UDP包)
-
然后把 UDP 当库用时,你业务模块只需要管:
发:
给一次 tx_start_en(启动)
给好 tx_byte_num(要发多少字节)
在 tx_req 的节拍下把字节送到 tx_data
看 tx_done(结束)
收(FPGA):
-
监听
rec_en/rec_data把 payload 存起来 -
rec_pkt_done到了处理一包
其它 gmii_*、crc32、组头这些都属于库内部实现,你不用重复造轮子。
4.那么关注: UDP loopback项目payload 怎么"从 udp_rx 送到 udp_tx",
正点原子的 eth_udp_loop 示例采用的是最直观、最适合新手理解的方式:回环(loopback) 。其数据通路是"先收再发"------上位机通过网络调试助手发送一段字符串,FPGA 的 udp_rx 在解析并确认该帧为发给本机的 UDP 后,将 payload 以 rec_en/rec_data 的形式逐字节吐出;顶层再把这些字节写入 FIFO 缓存;随后在回环逻辑触发后,udp_tx 通过 tx_req 向 FIFO 拉取数据,FIFO 输出字节接到 tx_data,最终实现"原样返回"。因此,你在上位机端看到的现象就是:发送什么字符串,FPGA 就返回什么字符串------这用来验证链路、协议解析、组包与发送流程都正确,非常有效。
进一步推广到"真正的发送电路"时,核心思想其实不变:udp_tx 并不关心 payload 来自哪里,它只通过 tx_req/tx_data 这组接口按需取数。
5.模式:
-
业务侧准备一个数据源:可以是 ROM(固定字符串/固定报文) 、RAM(可写可读、可变内容) ,也可以是 FIFO(缓存/队列);
-
当
udp_tx拉高tx_req请求数据时,业务侧执行一次读取; -
在随后一个时钟周期,把读出的字节送到
tx_data(必要时做 1 拍对齐); -
如此循环直到输出满
tx_byte_num个字节,udp_tx 完成整包发送并给出tx_done。
5.说明
(1)
细节:FIFO 的 q 往往会有 1 拍延迟 ,所以这个工程在 eth_ctrl.v 里做了一个对齐(把 udp_tx_req 延迟一拍后再喂给 udp_tx 的 udp_tx_data),你只要记住结论:
即:在这个库里,tx_req 更像"提前一拍的读请求",数据 tx_data 会在随后对齐的时钟拍变有效。
(2)
从用途上看,FIFO 更常用于"缓存与解耦":例如接收侧临时存包、跨时钟域搬运数据、生产者与消费者速率不一致时的缓冲等;而如果你的目标是"主动发送固定/可配置的报文内容",更典型的数据源往往是 ROM/RAM:ROM 适合快速验证(例如直接发 "HELLO UDP"),RAM 则便于扩展(例如按地址读取不同字符串、按寄存器配置选择发送内容、或者周期性更新采样数据后再发送)。正点原子的 loopback 只是用 FIFO 实现了"最简单闭环逻辑",把数据源从"内部存储"换成"接收缓存",从而用最少的控制逻辑就达成了演示目标。
三.单端口 RAM IP核使用学习
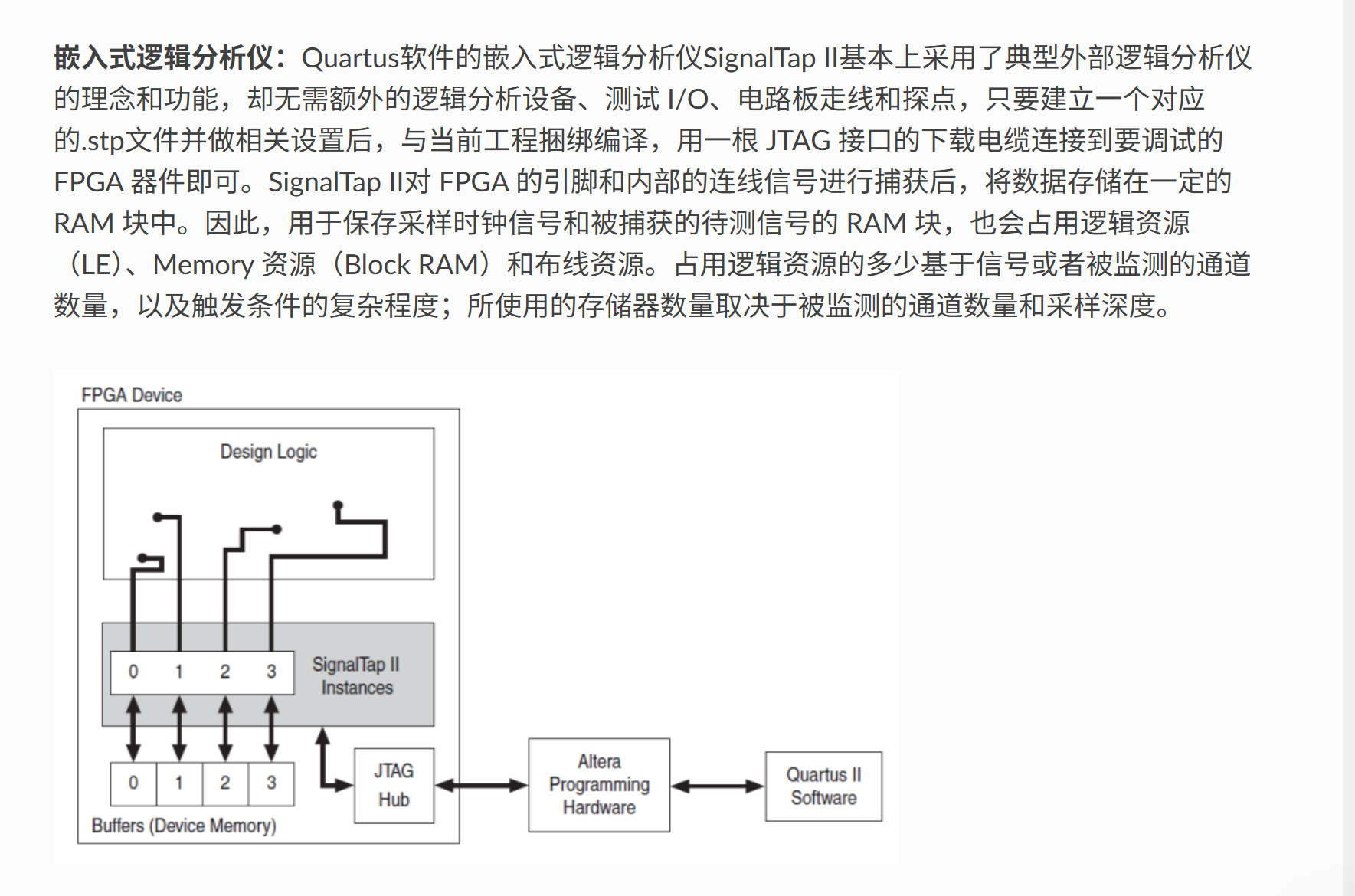
这里先来复现原子提供的源码,以学习:使用Signal Tap Logic Analyzer
实验任务:
本节实验任务是使用Altera RAMIP核生成一个单端口的RAM,然后对RAM进行读写操作,并通过SignalTap软件进行在线调试。
3.1 用户端口和读写时序
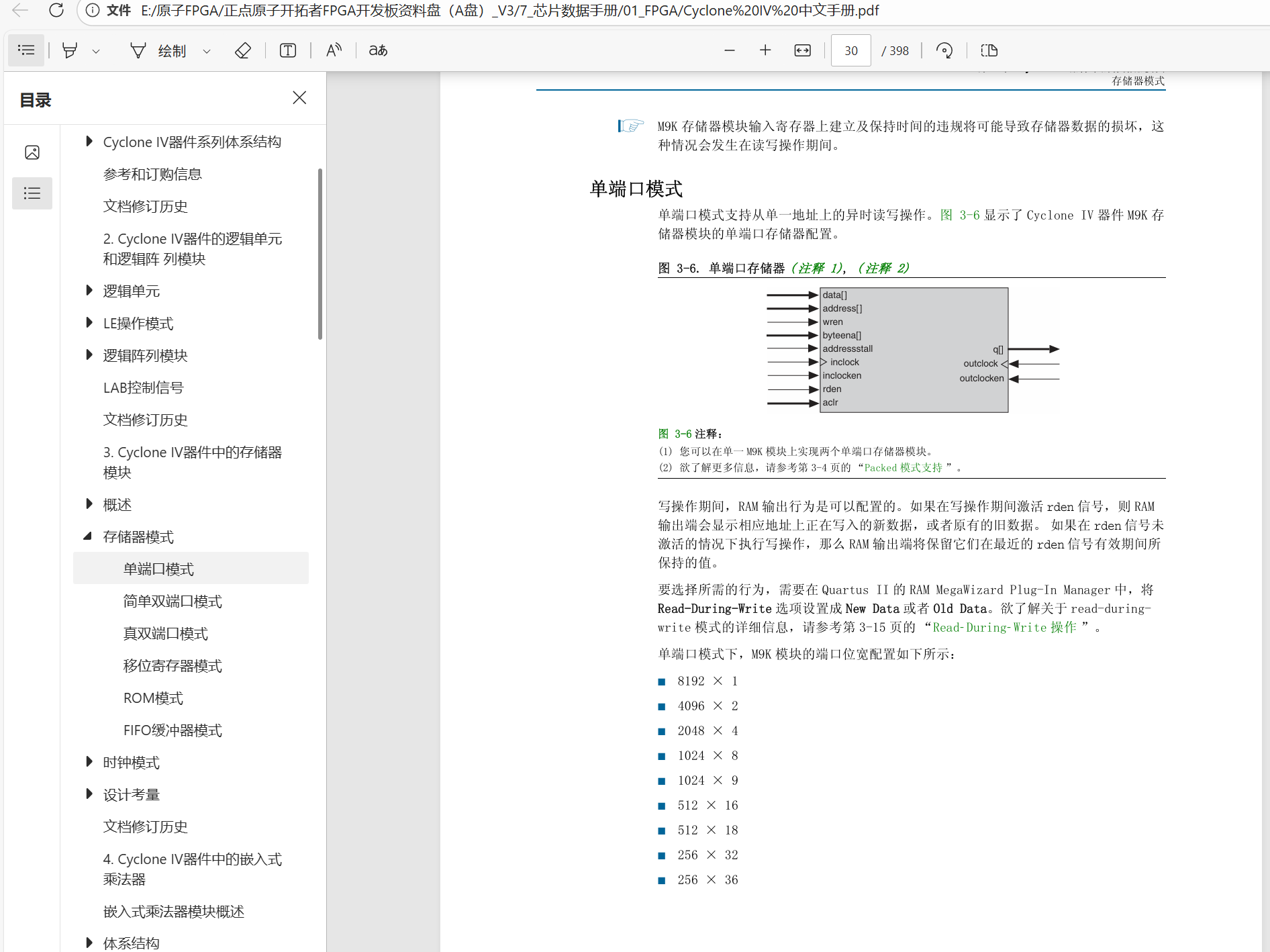
说明:上面手册上很全,但是只用到如下几个端口,
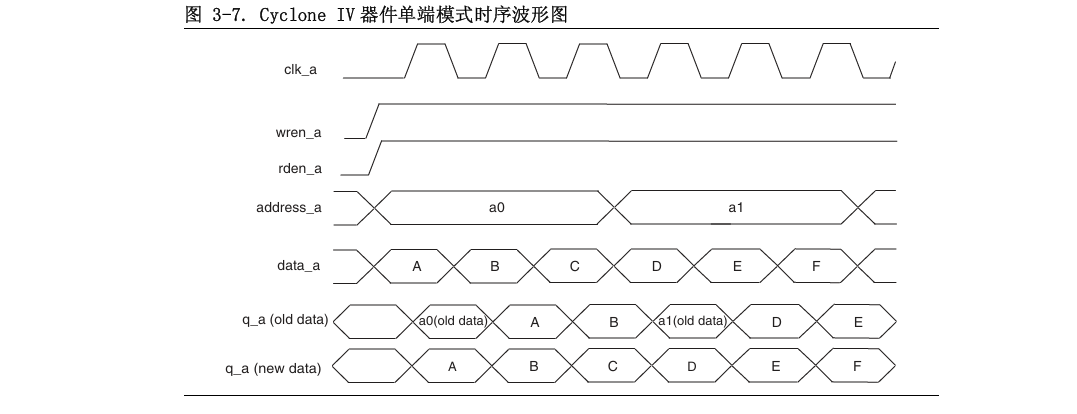
注意读时序图相位,
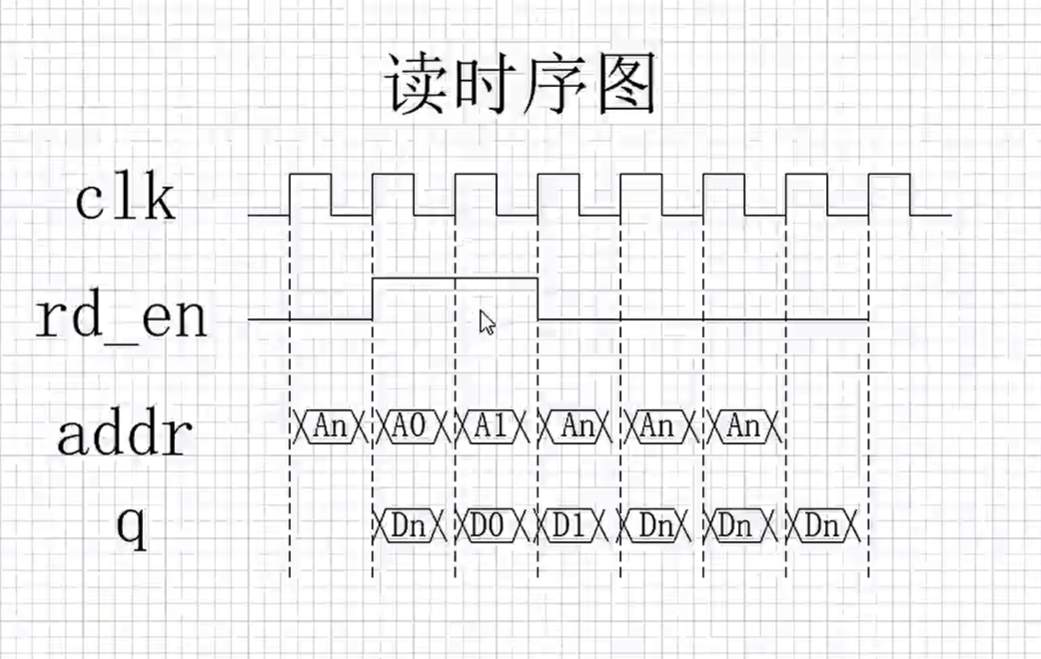
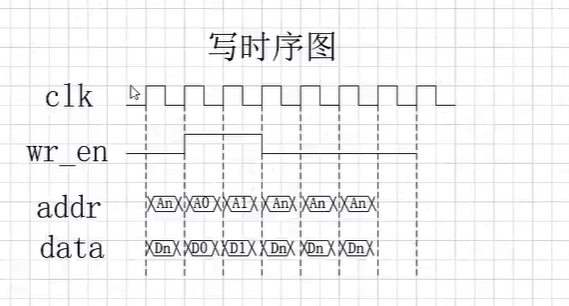
图来自:
【正点原子】FPGA系列教学视频 【基于开拓者V2和新起点V2】
本来想快速配置ram IP核去找视频操作的,然后发现FPGA系列视频有好几期,包括开发指南后面的项目,还有可能源码更新了吧,去看了一下第二期没有ICMP也可能没录制这部分。
3.2 RAM读写模块
目标:手册截图
cnt循环:cnt=0-31对应写0-31到addr(0-31),cnt=32-63读addr(0-31),rd_data晚1clk(对addr对应数字)

手册上代码太长了超过一页了,这里贴上正点原子给的源码,方便理解逻辑,好判断后面SignalTap软件进行在线调试的波形
//****************************************Copyright (c)***********************************//
//技术支持:www.openedv.com
//淘宝店铺:http://openedv.taobao.com
//关注微信公众平台微信号:"正点原子",免费获取FPGA & STM32资料。
//版权所有,盗版必究。
//Copyright(C) 正点原子 2018-2028
//All rights reserved
//----------------------------------------------------------------------------------------
// File name: ram_rw
// Last modified Date: 2018/3/18 8:41:06
// Last Version: V1.0
// Descriptions:
//----------------------------------------------------------------------------------------
// Created by: 正点原子
// Created date: 2018/3/18 8:41:06
// Version: V1.0
// Descriptions: The original version
//
//----------------------------------------------------------------------------------------
//****************************************************************************************//
module ram_rw(
input clk , //时钟信号
input rst_n , //复位信号,低电平有效
output ram_wr_en , //ram写使能
output ram_rd_en , //ram读使能
output reg [4:0] ram_addr , //ram读写地址
output reg [7:0] ram_wr_data, //ram写数据
input [7:0] ram_rd_data //ram读数据
);
//reg define
reg [5:0] rw_cnt ; //读写控制计数器
//*****************************************************
//** main code
//*****************************************************
//rw_cnt计数范围在0~31,ram_wr_en为高电平;32~63时,ram_wr_en为低电平
assign ram_wr_en = ((rw_cnt >= 6'd0) && (rw_cnt <= 6'd31) && rst_n) ? 1'b1 : 1'b0;
//rw_cnt计数范围在32~63,ram_rd_en为高电平;0~31时,ram_rd_en为低电平
assign ram_rd_en = ((rw_cnt >= 6'd32) && (rw_cnt <= 6'd63)) ? 1'b1 : 1'b0;
//读写控制计数器,计数器范围0~63
always @(posedge clk or negedge rst_n) begin
if(rst_n == 1'b0)
rw_cnt <= 6'd0;
else if(rw_cnt == 6'd63)
rw_cnt <= 6'd0;
else
rw_cnt <= rw_cnt + 6'd1;
end
//读写控制器计数范围:0~31 产生ram写使能信号和写数据信号
always @(posedge clk or negedge rst_n) begin
if(rst_n == 1'b0)
ram_wr_data <= 8'd0;
else if(rw_cnt >= 6'd0 && rw_cnt <= 6'd31)
ram_wr_data <= ram_wr_data + 8'd1;
else
ram_wr_data <= 8'd0;
end
//读写地址信号 范围:0~31
always @(posedge clk or negedge rst_n) begin
if(rst_n == 1'b0)
ram_addr <= 5'd0;
else if(ram_addr == 5'd31)
ram_addr <= 5'd0;
else
ram_addr <= ram_addr + 1'b1;
end
endmodule3.3 Signal Tap Logic Analyzer
3.3.1 介绍
浏览器搜一下大概了解,参考链接:https://doc.embedfire.com/fpga/altera/ep4ce10_pro/zh/latest/code/signaltap.html

数电课设里用过逻辑分析仪:

3.3.2 验证
这里主要为了学习Signal Tap Logic Analyzer 调试,下面快速建立环境:
因为原子工程里存在Signal Tap Logic Analyzer 配置信息,下面重新创建,按照之前流程:
B1. 新建 Quartus 工程&B2添加正点原子的源码
第20个例程
B3. 加入 IP 核
其实还是没自己建,copy原子ipcore文件夹添加文件

B4. 管脚/IO 约束
跟之前有点不一样,这个例程doc文件夹没有tcl文件,复制qsf文件配置引脚,
说明:QSF 本质就是工程的"设置脚本",复制过来就能用;
但要注意两件事:路径/工程名要对得上,所以工程结构最好按照原子的建,以及 SignalTap 那一大段不要带,因为本次操作目的就是调一遍SignalTap 使用。
 必要最小 QSF:把你工程的
必要最小 QSF:把你工程的 ip_1port_ram.qsf 打开,直接替换为下面这个精简版:
set_global_assignment -name FAMILY "Cyclone IV E"
set_global_assignment -name DEVICE EP4CE10F17C8
set_global_assignment -name TOP_LEVEL_ENTITY ip_1port_ram
set_global_assignment -name PROJECT_OUTPUT_DIRECTORY output_files
set_global_assignment -name VERILOG_FILE ../rtl/ram_rw.v
set_global_assignment -name VERILOG_FILE ../rtl/ip_1port_ram.v
set_global_assignment -name QIP_FILE ipcore/ram_1port.qip
# pins
set_location_assignment PIN_M2 -to sys_clk
set_location_assignment PIN_M1 -to sys_rst_n
set_instance_assignment -name IO_STANDARD "3.3-V LVCMOS" -to sys_clk
set_instance_assignment -name IO_STANDARD "3.3-V LVCMOS" -to sys_rst_nB5. Signal Tap Logic Analyzer
分析综合并设置Signal Tap
B5.1、打开 SignalTap,选时钟信号
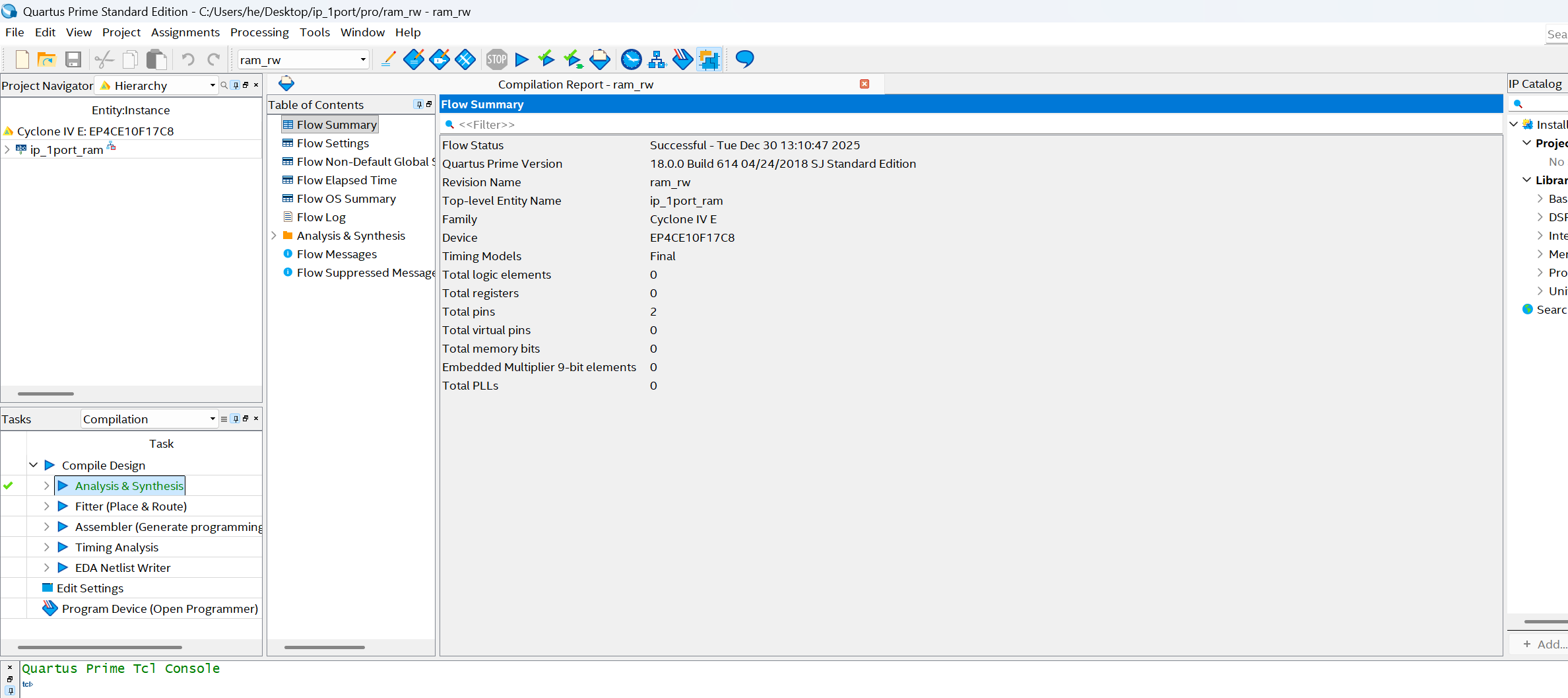

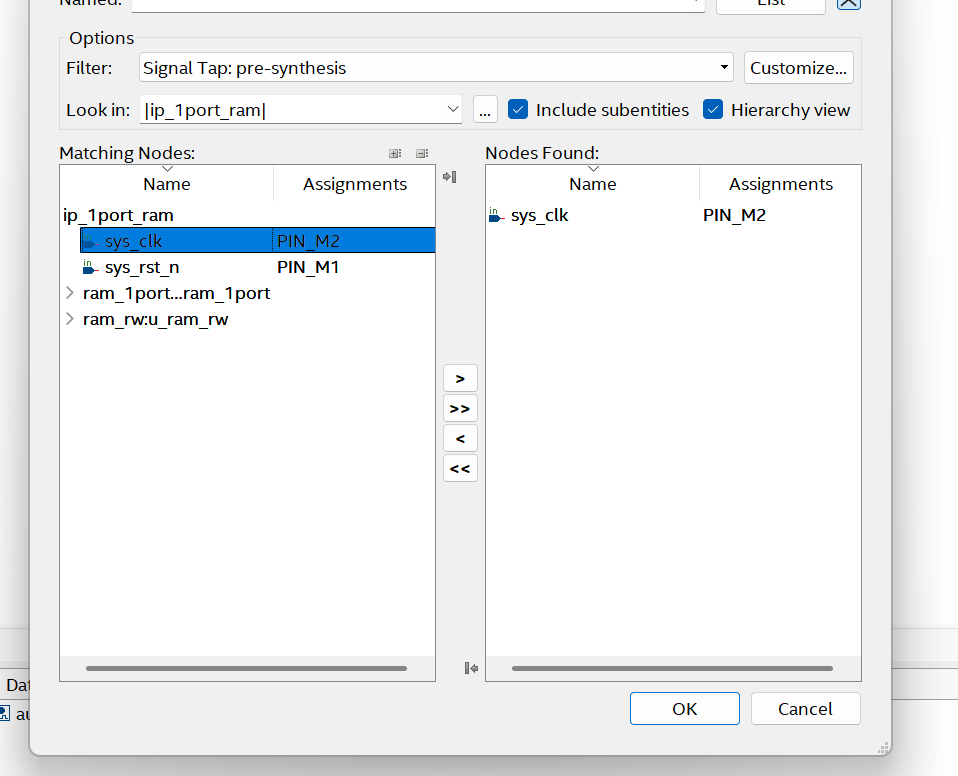
先选Filter,再list
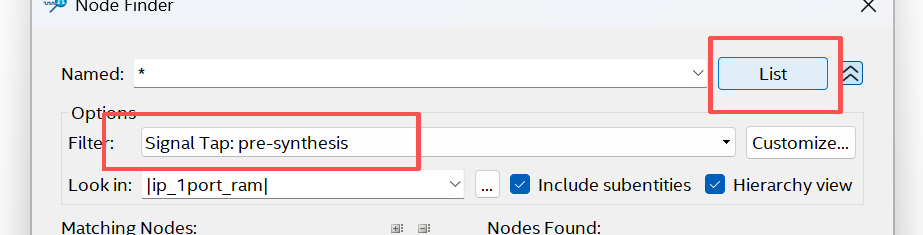
双击sys-clk,ok
说明1:SignalTap 是靠时钟驱动的采样电路。它每个时钟沿(通常是上升沿)采一拍,把内部信号状态存进 FPGA 内部的 RAM。
B5.2、选择要观察(采样)的信号,设置采样深度(Sample depth)
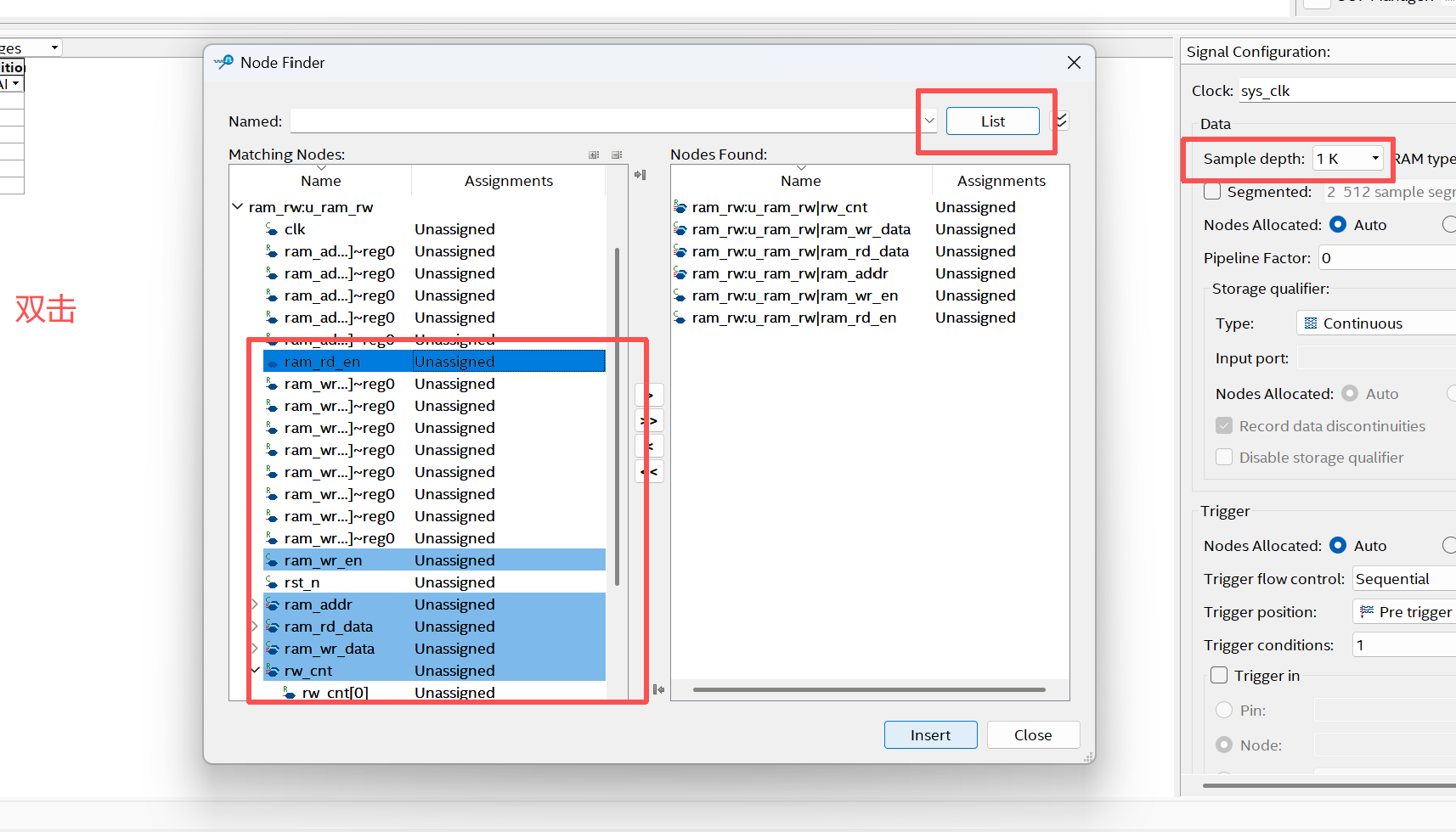
双击中间空白区->node Finder窗口->点list->添加如下信号->insert,
ctrl+s保存文件到工程,yes
说明2:(1)把这些信号接入 SignalTap 的采样通道(Data)。这些信号会被硬件逻辑连进一个采样阵列中,编译后 FPGA 内部就会生成对应的抓取通路。
(2)设置采样深度:
操作:
右边面板中 "Sample depth" 选 1K / 2K / 4K 等。
意思:
采样深度 = 一次最多能抓多少拍波形。
每一拍是一个时钟周期的快照。
深度越大:
-
波形显示时间越长;
-
但占用 FPGA 内部 RAM 资源更多。
比如:
-
1K= 抓 1024 拍 -
4K= 抓 4096 拍
B5.3、设置触发条件(Trigger)
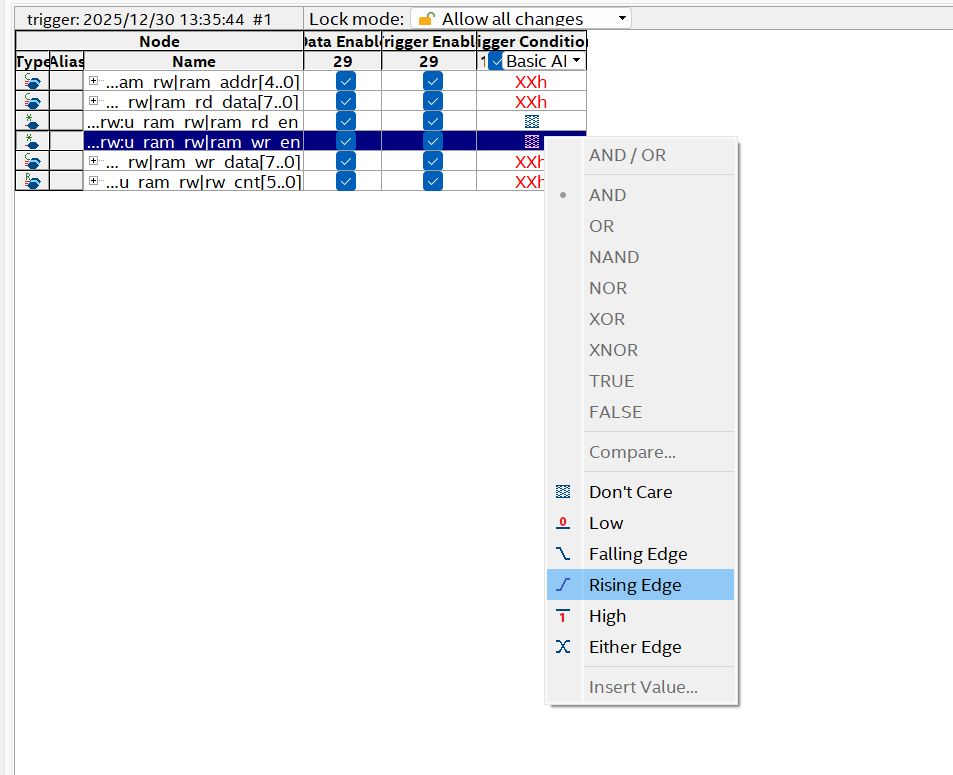
说明3:
操作:
在触发列右键 → "Rising Edge"、"High"、"Don't care"等。
意思:
SignalTap 可以设定"满足某条件才开始抓"。
举例:
| 条件 | 意义 |
|---|---|
| Rising Edge | 当该信号从 0→1 时触发抓波形 |
| High | 当该信号为高电平时触发 |
| Don't Care | 不管它是什么状态 |
| Either Edge | 上升或下降沿都触发 |
这样你就能只在特定事件发生时开始采样(比如写使能上升沿)。
B5.4、保存 .stp 文件到工程中
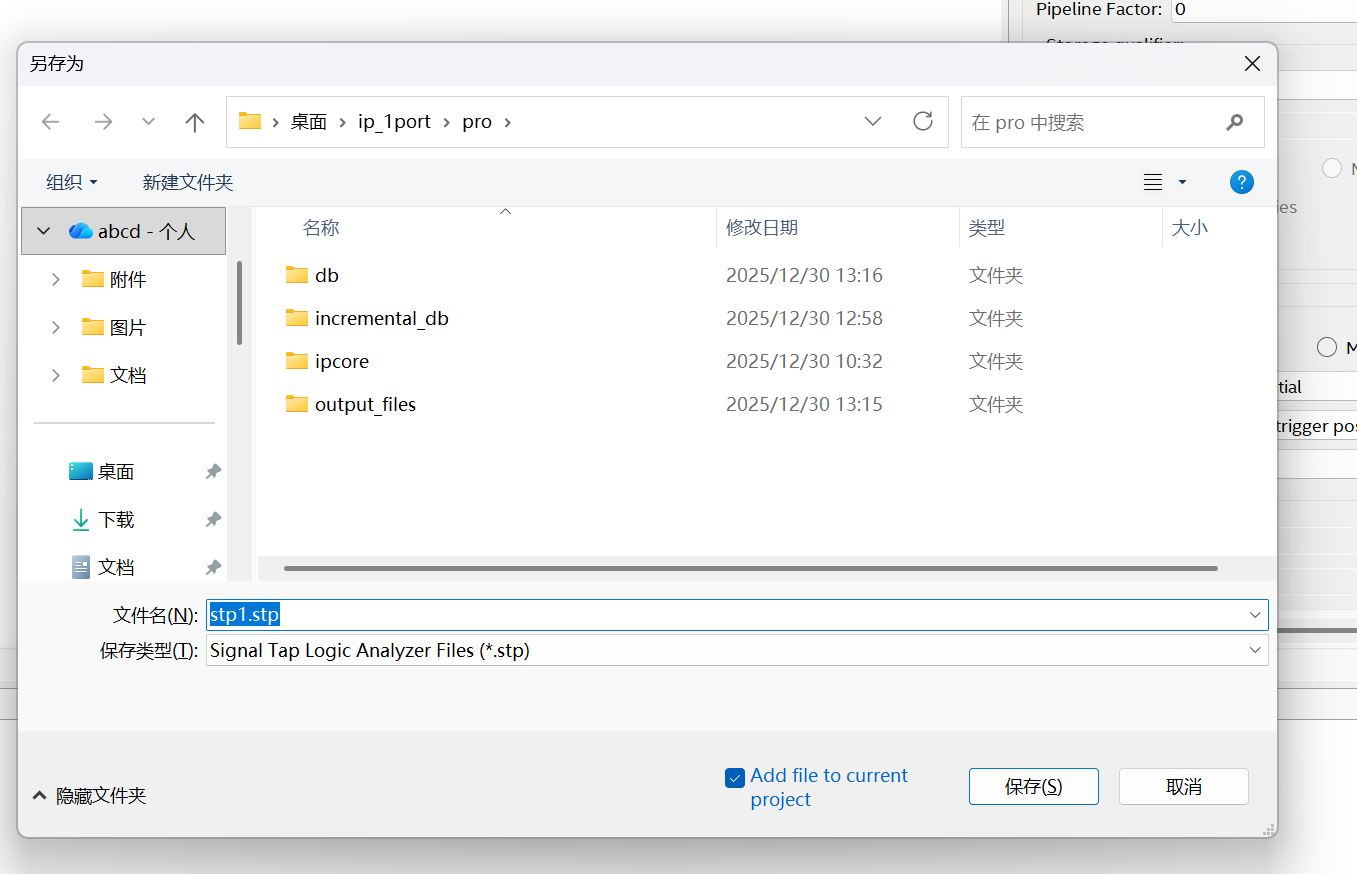
操作:
Ctrl+S → 弹出保存框 → 命名 stp1.stp
Quartus 提示:
"是否启用这个 SignalTap 文件?" → 选 Yes
意思:
stp1.stp 是 SignalTap 的配置文件(类似工程脚本)。
保存后 Quartus 会自动在 QSF 里加入几行:
set_global_assignment -name ENABLE_SIGNALTAP ON set_global_assignment -name SIGNALTAP_FILE stp1.stp
也就是说:
工程从此带上了"SignalTap 抓波形模块"。
B5.5全编译并下载
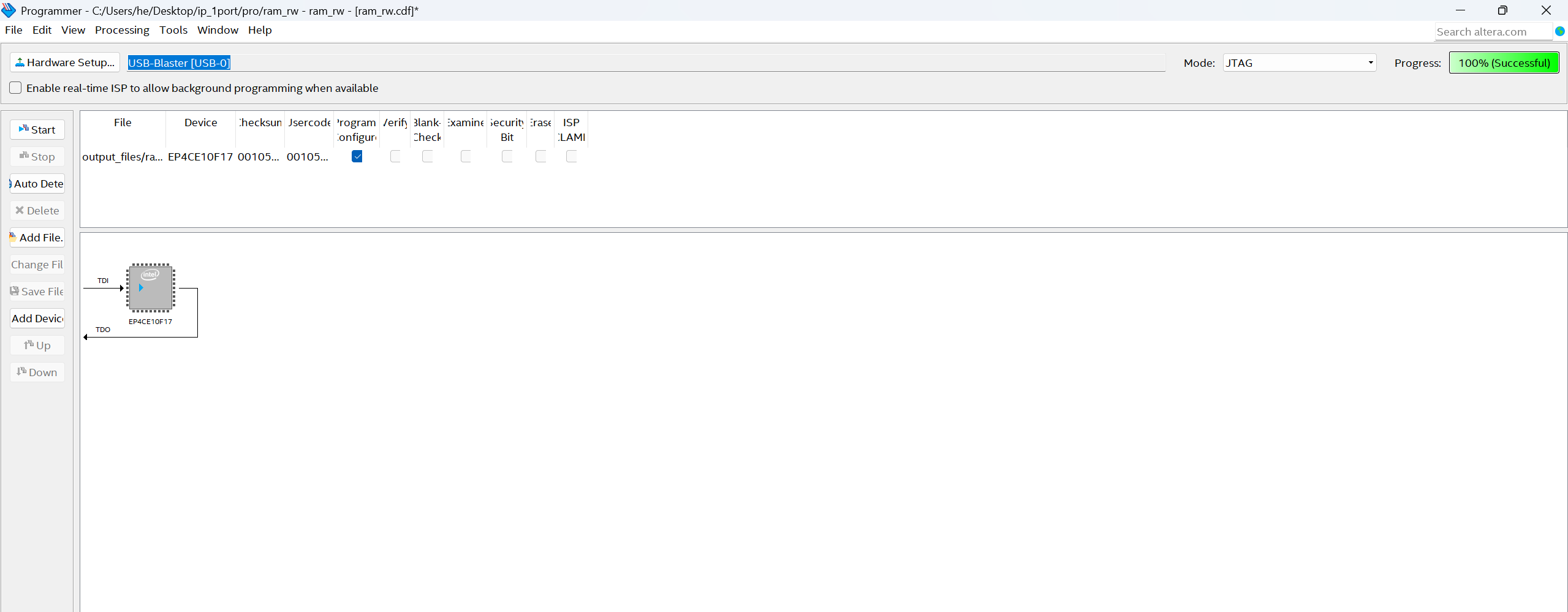
(1)编译器会:
-
把你选的信号连到一个采样逻辑网络;
-
分配 FPGA 内部 RAM 用来存数据;
-
加上 JTAG 控制通道(用于你电脑读取波形)。
所以这一步编译后生成的 .sof 比原来的大一点。
(2)把带 SignalTap 调试逻辑的 FPGA 程序下载到板上。
FPGA 现在除了执行你的 RAM 逻辑,还多了个"内部逻辑分析仪
B5.6看波形
你看到的波形不是仿真,而是板上真实信号的时序快照。
这是 SignalTap 的核心作用:
"让 FPGA 自己当示波器,用 JTAG 把内部信号采出来。"

点几下波形就放大了,设置无符号十进制
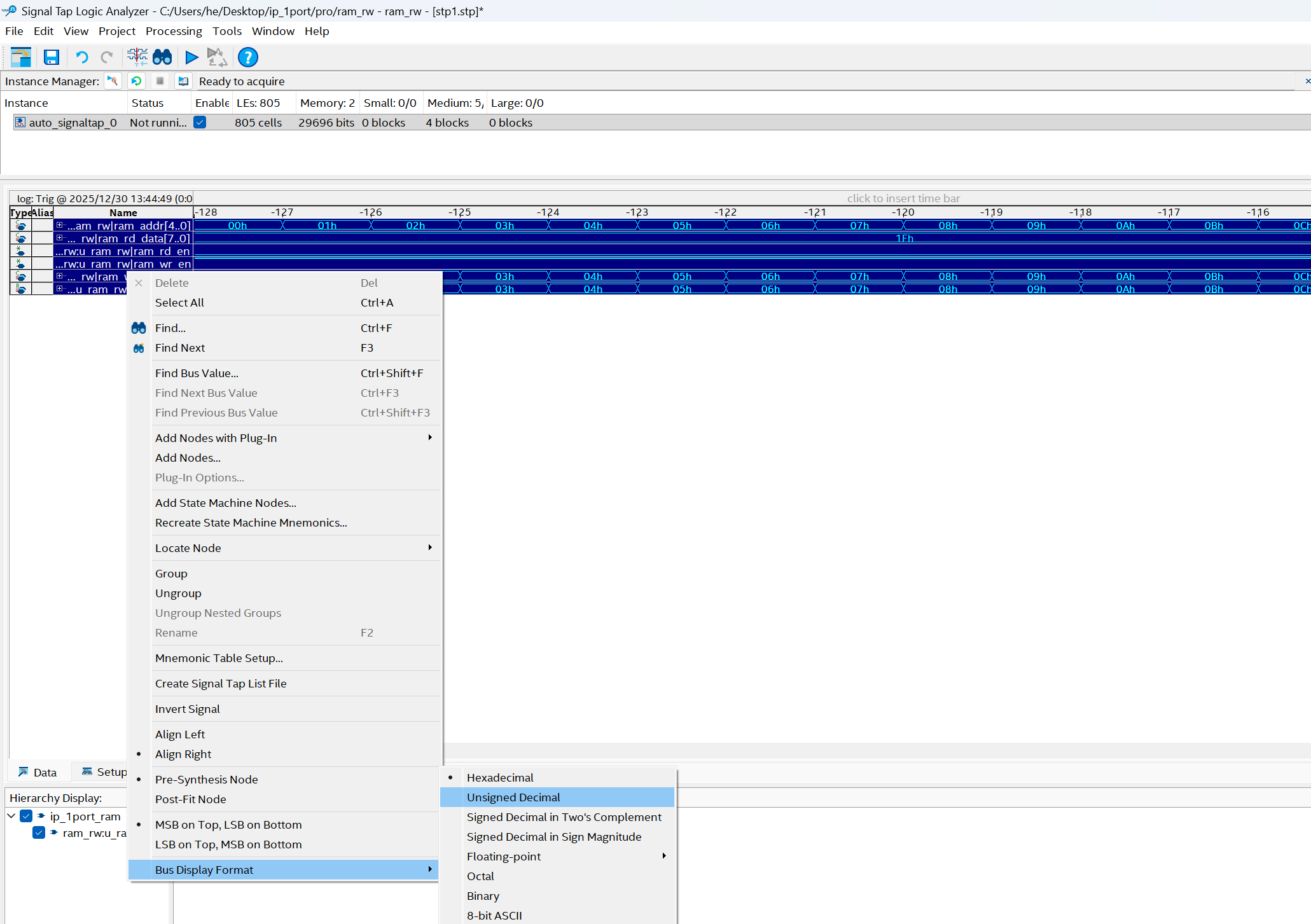
分析波形
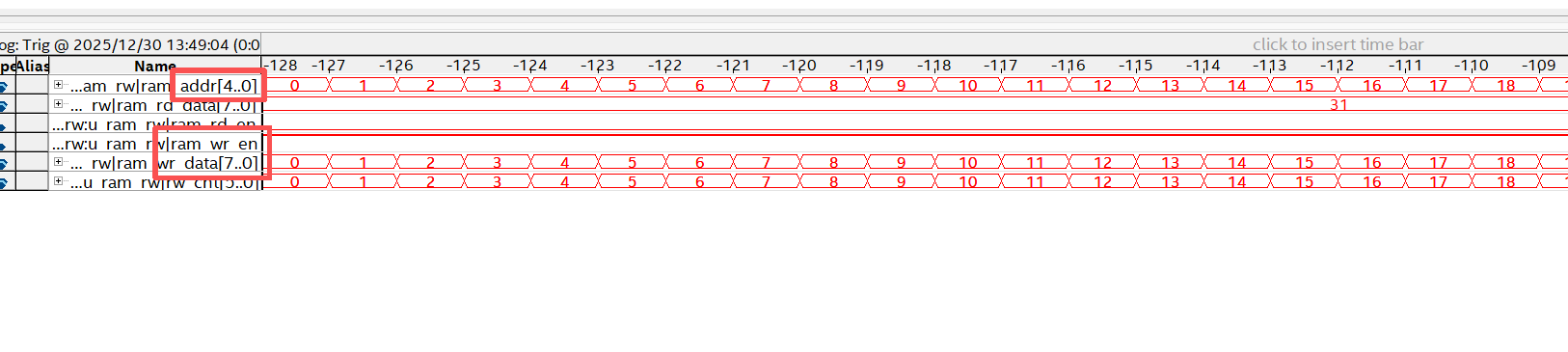

前半周关注写操作,wr_en=1,cnt=0-31,addr=0-31,wr_data=0-31,
另外,rd_data保持最后读addr的rd_data=31(相位cnt=63+1=0,晚1clk),虽然有32但是wr_en=0
后半周关注读操作,rd_en=1,cnt=32-63,addr=0-31,rd_data=0-31,
其中rd_data=0-31,相对rd_en=1,addr=0-31晚1clk