Protocol Buffers:结构化数据交换的基石------深度技术解析
1. 整体介绍
1.1 项目概况
- 项目地址 : github.com/protocolbuf...
- 项目数据 : 截至分析时,该项目在 GitHub 上拥有超过 63,000 个 Star 和超过 15,000 个 Fork,这表明其在开发者社区中具有广泛的影响力和采纳度。它是现代微服务通信、数据存储等领域的基础设施之一。
- 许可证: 基于 BSD 3-Clause 开源许可证。
1.2 主要功能与核心价值
Protocol Buffers 的核心是一个 接口定义语言(IDL) 及一套 代码生成工具和运行时库。其工作流程可概括为:
rust
编写 .proto 文件 (IDL) -> protoc 编译 -> 生成目标语言的数据访问类 -> 在应用中使用生成的类进行序列化/反序列化其产生的序列化数据为紧凑的二进制格式。
核心价值在于:
- 结构清晰,契约先行 :通过
.proto文件明确定义数据结构,作为服务间、模块间通信的强类型契约。 - 高效的编解码性能:二进制编码体积小,解析速度快,显著优于同期的 XML 和 JSON(在 CPU 和带宽消耗上)。
- 强大的向后兼容性:通过独特的字段编号和规则设计,支持在不破坏旧客户端/服务端的情况下演进数据格式。
- 真正的跨语言 :同一份
.proto文件可以为 C++、Java、Go、Python 等十多种主流语言生成类型安全、接口一致的客户端代码,消除了手动编解码和类型映射的错误。
1.3 面临问题与解决之道
-
面临问题:
- 异构系统数据交换:在微服务或分布式系统中,不同服务使用不同语言/平台,需要一种统一、高效的数据交换格式。
- API/数据契约管理:需要一种机器可读、可验证的方式来定义和版本化服务接口和数据结构。
- 序列化性能瓶颈:XML/JSON 等文本格式的解析开销和传输体积在性能敏感场景成为瓶颈。
- 协议演进复杂性:添加或修改字段时,需要确保新旧版本的客户端和服务端能够协同工作,手动处理极易出错。
-
传统解决方式:
- 使用 XML 或 JSON:可读性好,但冗余度高,缺乏强制性的模式(Schema),解析性能较差,跨语言类型映射需要额外约定和开发。
- 使用 自定义二进制格式:高效但开发成本高,难以维护和跨语言,可读性差。
-
Protocol Buffers 的解决方案:
- 引入 IDL :提供
.proto文件作为单一事实来源,明确定义数据结构。 - 提供编译器 (protoc):将 IDL 编译为各种语言的"桩代码"(Stub),自动化了类型安全的编解码逻辑。
- 设计高效二进制编码 (Wire Format):采用如 Varints、ZigZag 等编码技术,减少数据体积。
- 设计兼容性规则:基于字段编号(而非名称)和字段规则(optional/repeated)实现向前/向后兼容。
- 引入 IDL :提供
1.4 商业价值估算逻辑
Protocol Buffers 的商业价值难以直接用货币量化,但可从 成本节省 和 效益提升 两个维度评估:
- 开发成本节省 :
- 替代方案开发成本:假设一个中型公司为 5 种语言开发并维护一套具备同等兼容性、性能的自定义二进制序列化框架,需要至少 10 人年。
- 采用 Protobuf 成本 :学习成本 + 集成成本,远低于 1 人年。直接节省了超过 9 人年的初始开发成本,且无需承担后续巨大的维护、升级和跨团队协调成本。
- 运维与协作效益 :
- 降低沟通成本 :
.proto文件成为团队间、服务间明确无误的契约文档。 - 提升系统性能:更小的网络负载和更快的解析速度,直接降低了服务器资源成本和用户延迟。
- 减少运行时错误:编译时类型检查避免了大量由于手动序列化或动态类型错误导致的线上故障。
- 加速新功能上线:协议可以安全、快速地演进,支持敏捷开发。
- 降低沟通成本 :
综合估算 :对于任何涉及多语言通信或对性能有要求的技术组织,引入 Protocol Buffers 带来的长期总体拥有成本(TCO)降低和系统稳定性、开发效率的提升,其价值远超其近乎为零的直接采用成本。
2. 详细功能拆解
| 功能视角 | 产品视角 | 技术视角 |
|---|---|---|
| 协议定义 | 提供 .proto 语法,支持定义消息、枚举、服务。字段可指定类型、编号、规则。 |
实现了一个语法解析器(通常使用 Flex/Bison 或 ANTLR),将文本 IDL 转化为抽象语法树(AST)。 |
| 代码生成 | 用户执行 protoc --cpp_out=. example.proto,即可得到 example.pb.cc 和 example.pb.h。 |
protoc 编译器 是核心。它是一个 C++ 程序,内置或通过插件支持多种语言的 生成器(CodeGenerator) 。编译器前端解析 .proto 为 FileDescriptorProto(AST 的序列化形式),后端调用对应生成器产出代码。 |
| 运行时序列化 | 开发者调用 message.SerializeToString(&output) 或 message.ParseFromString(input)。 |
每种语言运行时库都实现了 Wire Format 编码/解码器。核心是将内存中的结构化对象按照字段编号和类型,编码为线性的字节流,反之亦然。涉及内存管理、反射等机制。 |
| 兼容性保障 | 新增 optional 字段,旧代码可以忽略;删除字段,需保留其编号为 reserved。 |
编码时,每个字段由 (field_number, wire_type, value) 三元组构成。解码器遇到未知字段编号(新字段)会将其存入消息的"未知字段集"或直接跳过;遇到缺失字段(已删除字段)则使用默认值。字段编号是兼容性的关键。 |
3. 技术难点挖掘
- 向后兼容性机制的设计:如何在二进制层面设计一种编码格式,使得解析器能够安全地忽略未知字段或为缺失字段提供合理默认值,同时保证编码的高效性。这是 protobuf 成功的核心。
- 跨语言一致性保证 :确保为不同语言生成的代码,其序列化/反序列化结果完全一致,行为(如默认值、枚举处理、
oneof语义)完全相同。这需要对每种目标语言的特性有深入理解,并在生成器中做适配。 - 高性能编解码实现:尤其在 C++、Java 等语言中,需要精细优化内存访问、避免不必要的拷贝、利用 SIMD 指令等。例如,对整数的 Varint 编码、对字符串长度的快速判断等。
- 构建系统与生态集成 :支持
Bazel、CMake、Maven、Gradle、Go Modules等多样化的构建和依赖管理系统,提供预编译二进制、源码集成等多种分发和使用方式,降低了用户的接入门槛。 - 插件系统与扩展性:如何设计编译器架构,使其能够支持第三方插件(如 gRPC 插件、自定义生成器),这是一个设计上的挑战。
4. 详细设计图
4.1 核心架构图
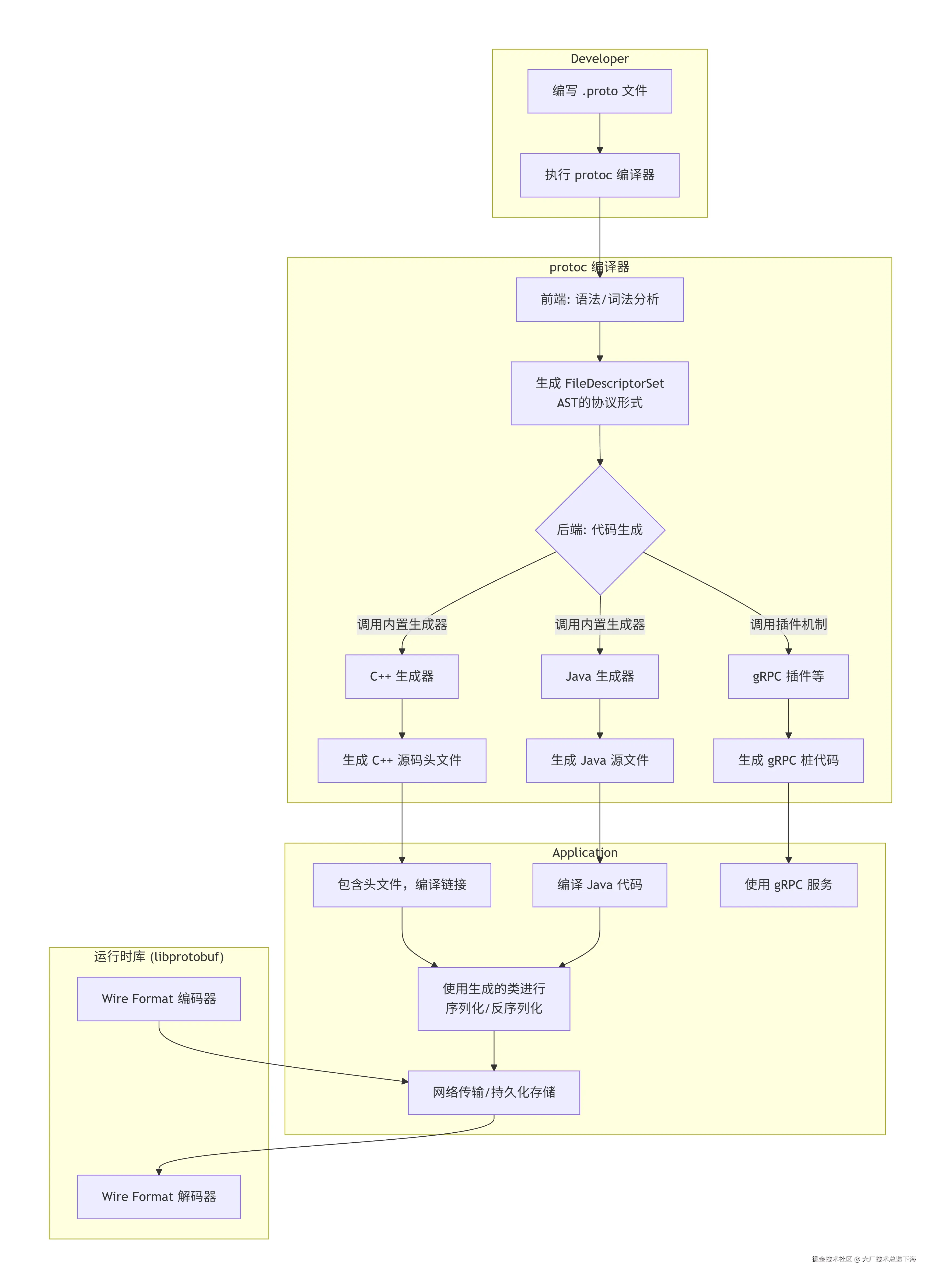
4.2 核心链路序列图(protoc 编译流程)
sequenceDiagram
participant User as 用户
participant Protoc as protoc 主程序
participant Parser as 语法解析器
participant Importer as 文件导入器
participant Generator as 代码生成器 (如 CppGenerator)
participant FS as 文件系统
User->>Protoc: protoc --cpp_out=. my.proto
Protoc->>Parser: 解析命令行参数
Protoc->>Importer: 导入并解析 my.proto
Importer->>Parser: 词法/语法分析
Parser->>Importer: 返回 FileDescriptor
Importer->>Protoc: 返回完整的 FileDescriptorSet
Protoc->>Generator: 调用 Generate(FileDescriptor, ...)
Generator->>Generator: 根据 AST 生成 C++ 代码字符串
Generator->>FS: 写入 my.pb.cc, my.pb.h
FS-->>Protoc: 完成
Protoc-->>User: 退出(成功/错误)
4.3 核心类图(编译器 CLI 部分简化)
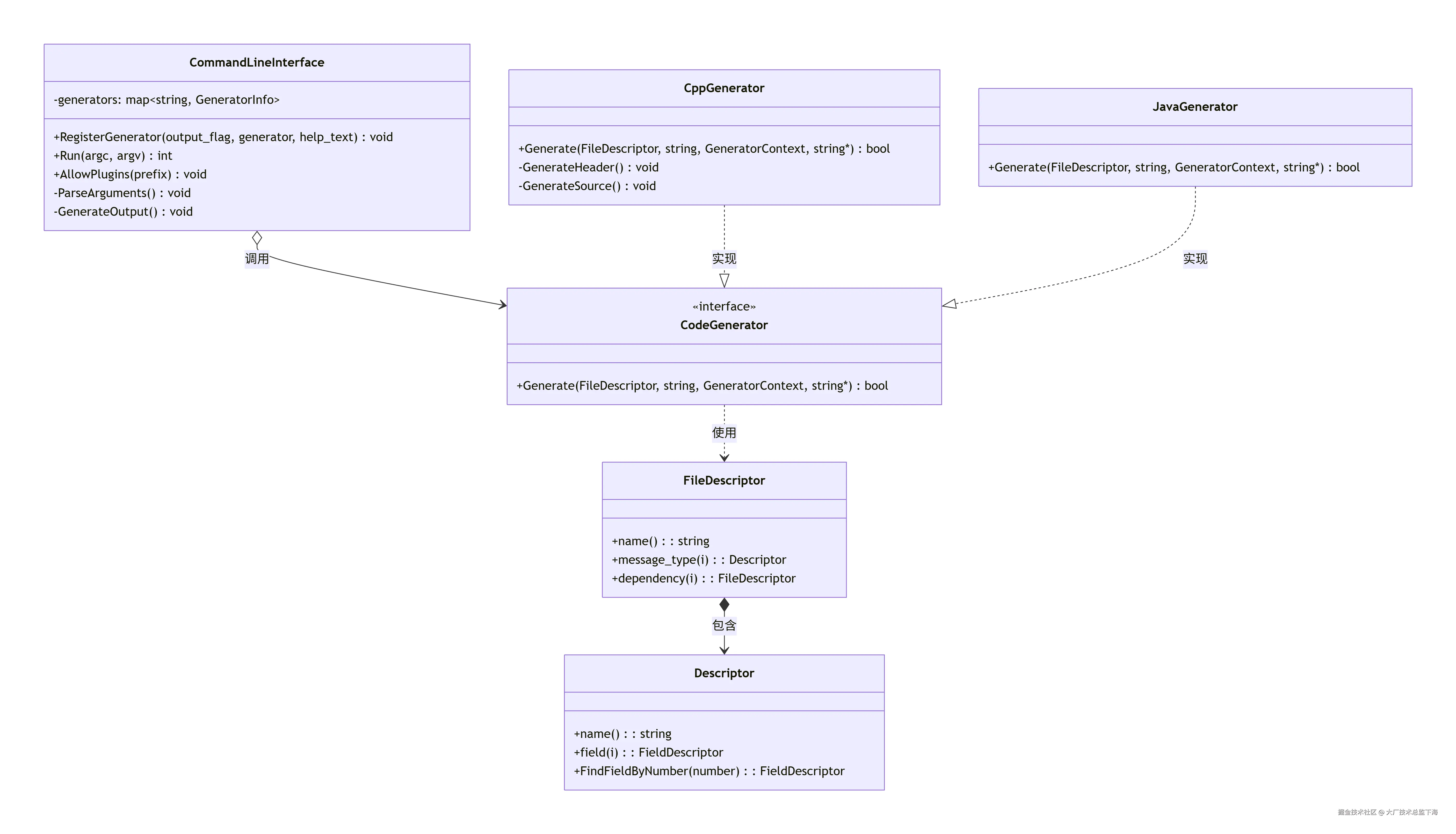
4.4 核心函数拆解图(ProtobufMain)
scss
ProtobufMain(int argc, char* argv[])
├── 初始化日志系统 (absl::InitializeLog)
├── 创建命令行接口对象 (CommandLineInterface cli)
├── 注册各语言代码生成器
│ ├── cli.RegisterGenerator("--cpp_out", &cpp_generator, ...)
│ ├── cli.RegisterGenerator("--java_out", &java_generator, ...)
│ ├── cli.RegisterGenerator("--kotlin_out", &kt_generator, ...)
│ └── ... (Python, C#, Go, Rust 等)
├── (Windows 特有) 宽字符命令行参数转换
│ ├── CommandLineToArgvW
│ └── WideCharToMultiByte(CP_UTF8)
└── 执行命令行解析与代码生成 (cli.Run(argc, argv))
├── 解析 .proto 文件,构建 FileDescriptor 树
├── 根据 --*_out 参数定位对应的生成器
├── 调用生成器的 Generate() 方法
└── 将生成的代码写入指定目录5. 核心函数解析
以下分析 src/google/protobuf/compiler/main.cc 中的核心函数 ProtobufMain。该函数是 protoc 编译器的真正入口点。
cpp
// 核心函数:protoc 编译器的主逻辑入口
int ProtobufMain(int argc, char* argv[]) {
// 1. 初始化开源运行时标志(如果定义了相关宏)
#ifdef GOOGLE_PROTOBUF_RUNTIME_INCLUDE_BASE
google::protobuf::internal::SetIsOss(true);
#endif
// 2. 初始化 Abseil 日志库,用于编译器内部的日志输出
absl::InitializeLog();
// 3. 创建命令行接口 (CLI) 对象,它是编译器工作流的协调器
CommandLineInterface cli;
// 允许加载以 "protoc-" 为前缀的插件
cli.AllowPlugins("protoc-");
// 4. 注册所有内置的代码生成器 (CodeGenerator)
// 这是编译器支持多语言的核心:将语言关键字与具体的生成器对象绑定
// 4.1 注册 C++ 生成器
cpp::CppGenerator cpp_generator;
// 参数: "--cpp_out" 指定输出标志, "--cpp_opt" 指定选项标志, &cpp_generator 是生成器实例, 最后是帮助文本
cli.RegisterGenerator("--cpp_out", "--cpp_opt", &cpp_generator,
"Generate C++ header and source.");
// ... (为开源版本设置特定参数)
// 4.2 注册 Java 生成器
java::JavaGenerator java_generator;
cli.RegisterGenerator("--java_out", "--java_opt", &java_generator,
"Generate Java source file.");
// 4.3 注册 Kotlin 生成器
kotlin::KotlinGenerator kt_generator;
cli.RegisterGenerator("--kotlin_out", "--kotlin_opt", &kt_generator,
"Generate Kotlin file.");
// 4.4 注册 Python 生成器
python::Generator py_generator;
cli.RegisterGenerator("--python_out", "--python_opt", &py_generator,
"Generate Python source file.");
// 4.5 注册 Python 类型存根 (.pyi) 生成器
python::PyiGenerator pyi_generator;
// Pyi 生成器通常没有额外选项,故只用一个参数
cli.RegisterGenerator("--pyi_out", &pyi_generator,
"Generate python pyi stub.");
// 4.6 注册其他语言生成器 (PHP, Ruby, C#, Objective-C, Rust)
// 模式与上述类似,此处为简洁省略...
// php::Generator, ruby::Generator, csharp::Generator,
// objectivec::ObjectiveCGenerator, rust::RustGenerator
// 5. 处理可能的内部白名单机制(用于控制某些实验性或内部特性)
#ifdef DISABLE_PROTOC_CONFIG
auto cleanup = internal::DisableAllowlistInternalOnly();
#endif // DISABLE_PROTOC_CONFIG
// 6. 将控制权移交给 CLI 对象,执行实际的编译工作流:
// - 解析命令行参数
// - 读取并解析 .proto 文件,构建语法描述符 (FileDescriptor)
// - 根据用户指定的 `--*_out` 参数,找到对应的生成器
// - 调用生成器的 Generate() 方法,并传入 FileDescriptor
// - 生成器负责将 AST 转换为目标语言代码并写入文件
// - 返回执行状态 (0 成功,非 0 错误)
return cli.Run(argc, argv);
}代码解析要点:
- 模块化设计 :
CommandLineInterface是中枢,负责流程调度。各语言生成器是独立的插件模块,通过RegisterGenerator注册,符合开闭原则。 - 支持插件化 :
AllowPlugins函数表明架构支持外部插件,这是 gRPC 等工具能够无缝集成的基础。 - 平台适配 :文件末尾的
main函数针对 Windows 平台进行了特殊的 UTF-16 到 UTF-8 命令行参数转换,体现了跨平台支持的细节处理。 - 清晰的职责分离 :
ProtobufMain仅负责初始化和注册,具体的编译逻辑封装在cli.Run()中。生成器只负责代码生成,不关心文件解析。
与同类技术对比:
- 对比 Apache Thrift:两者都提供 IDL 和跨语言代码生成。Thrift 内置了 RPC 框架定义,更"全栈";而 Protobuf 更专注于序列化本身,通过插件(如 gRPC)实现 RPC,更为"专注"和"灵活"。Protobuf 的二进制编码通常被认为更紧凑。
- 对比 JSON/XML:Protobuf 需要预编译步骤和强类型 Schema,在灵活性和开发便捷性上不及 JSON,但在性能、类型安全和契约管理上具有明显优势。适用于内部服务通信、配置文件、数据持久化等场景。
- 对比 FlatBuffers/Cap'n Proto:后两者是"零拷贝"序列化方案的典型,访问序列化数据时无需完全解析,在特定场景(如大型数据结构频繁访问部分字段)性能更高。但 Protobuf 的生态更成熟,API 更简单,向后兼容性方案经过大规模验证,通用性更强。
总结 :Protocol Buffers 通过其精巧的 IDL 设计、高效的 Wire Format、稳健的兼容性规则以及模块化、插件化的编译器架构,成功解决了跨语言、高性能、可演进的数据交换这一核心工程问题。它不仅是一个工具库,更是一种被广泛接受的设计模式和工程实践标准。深入理解其设计原理,对于构建健壮的分布式系统至关重要。