鉴于前面已经完结了对于string标准库的讲解,以及自己模拟实现一个string类,学习了如何看CPlusPlus官方的文档,我们对于STL容器已经有了一部分了解,那么在学习vector和后续的list的时候,讲解速度就会稍微快一些,有一些比较简单的内容,我们就直接展示官网上的文档,大家可以自行阅读。并且我们后续的讲解还是会以官方文档的内容为主。
1. vector的简要介绍
在数学/物理领域,vector的中文意思是:"向量"。在 C++ 标准库 中,std::vector是一个动态数组容器,中文常直接称为vector容器,也可意译为动态数组。所以由此可见,vector的底层实际上就是顺序表。
我们打开一下CPlusPlus官网,观察一下vector的内容,这是官网的地址:
cplusplus.com - The C++ Resources Network

我们可以看到这里的vector是C++标准库中定义在std标准命名空间下的一个模板类,它的第一个参数:class T ,是用于指定vector容器中存储元素的类型。比如写下这个代码:std::vector<int> ,此时 T 被实例化为int类型,意味着这个vector容器用来存储int类型的数据;在 std::vector<std::string> 中,T 被实例化为 std::string 类型,容器用来存储字符串 。
它的第二个参数:class Alloc = allocator<T> ,是用于指定内存分配器的类型,负责为 vector 容器分配和释放内存 。默认使用 allocator<T> ,这是C++ 标准库提供的默认内存分配器,能够满足大多数情况下对内存管理的需求。不过在一些特殊场景,比如对内存分配有严格控制(像内存池的实现 ),或者针对特定硬件平台优化内存使用时,可以自定义内存分配器,然后通过这个参数传递给 vector 。
对于vector这个类里面有一下内容:
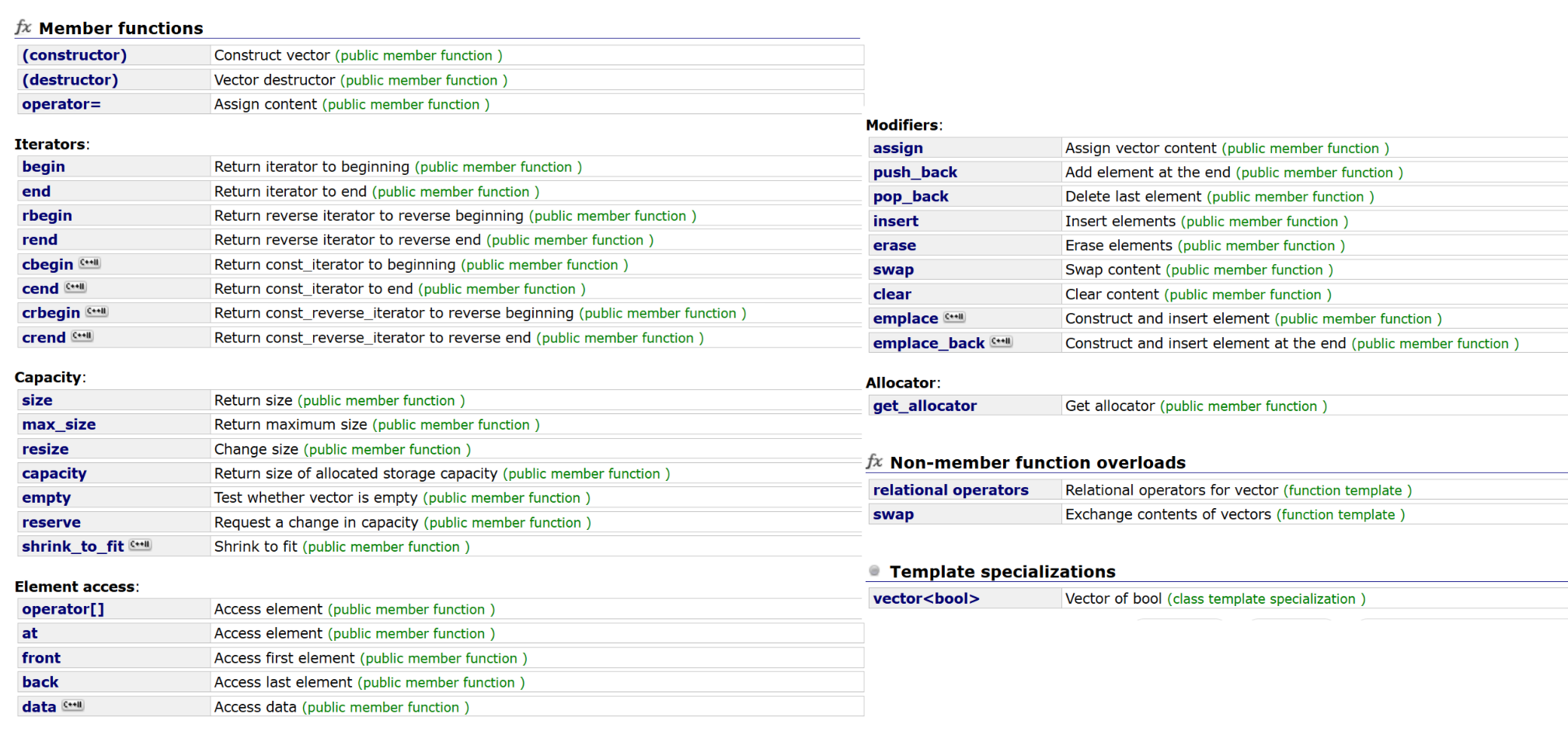
我们会发现vector和string一样,都有构造函数、迭代器、容量、元素访问操作函数、修改操作函数、内存分配操作函数和非成员函数重载。

首先大家一定要明白的一点是,当你想要定义一个vector对象,就必须要加上它的类型,因为我们说vector实际上是一个顺序表,既然是顺序表它肯定会存储内容,那么内容的类型一定要确定,否则无法调用默认构造函数。
2. vector的构造函数
 大家可以看到vector的四个构造函数里面都有一个参数:const allocator_type& alloc = allocator_type(); 它有一个缺省值是allocator_type(),这个缺省值是C++ 标准库提供的默认内存分配器,负责为 vector 容器分配和释放内存,只有在极少数的情况下我们才会为这个参数传值,因为C++标准库提供的默认内存分配器,能满足极大范围场景的使用。在这边大家就可以把它当成没看到。
大家可以看到vector的四个构造函数里面都有一个参数:const allocator_type& alloc = allocator_type(); 它有一个缺省值是allocator_type(),这个缺省值是C++ 标准库提供的默认内存分配器,负责为 vector 容器分配和释放内存,只有在极少数的情况下我们才会为这个参数传值,因为C++标准库提供的默认内存分配器,能满足极大范围场景的使用。在这边大家就可以把它当成没看到。
首先来看第一个构造函数,它是无参构造函数,就相当于默认构造函数。
第二个构造函数当中有一个参数,它有一个缺省值叫value_type()。这个value_type()是 C++ 中"值初始化"(Value Initialization)的语法形式,它会根据 value_type 的类型,生成该类型的默认值。刚刚在vector的简要介绍里面提到,如果想要定义一个vector对象,就一定要声明这个对象的类型,而这个类型就是value_type。比如我的代码中写到:vector<int> v1;此时value_type就是int,然后通过value_type()去生成int的默认初始值,根据C++的初始化规则,int的默认初始值就是0。如果类型是char,那默认初始值就是 ' \0 ' ,如果是类型是double,那默认初始值就是 0.0。所以这个构造函数的作用就是。创建构造一个有n个val的vector对象。
第三个构造函数里面的参数是迭代器,并且是begin和end迭代器。比如有两个vector对象,v1和v2,写出v2(v1.begin(),v1.end()),就表示v2存储的值是v1的从头到尾的内容。其实有点像拷贝构造函数。
而第四个就是最普通的拷贝构造函数。
接下来给大家展示一下代码:
3.vector的析构函数

4.vector的赋值运算符重载

5.vector的遍历和访问操作
因为标准库的vector类中本身并没有重载流插入运算符,所以对于我们上面的构造函数,想要把具体存储的内容打印出来,如果直接使用cout<<v1的话就会报错。因此我们这里使用for循环和访问下标的方式逐个输出元素。
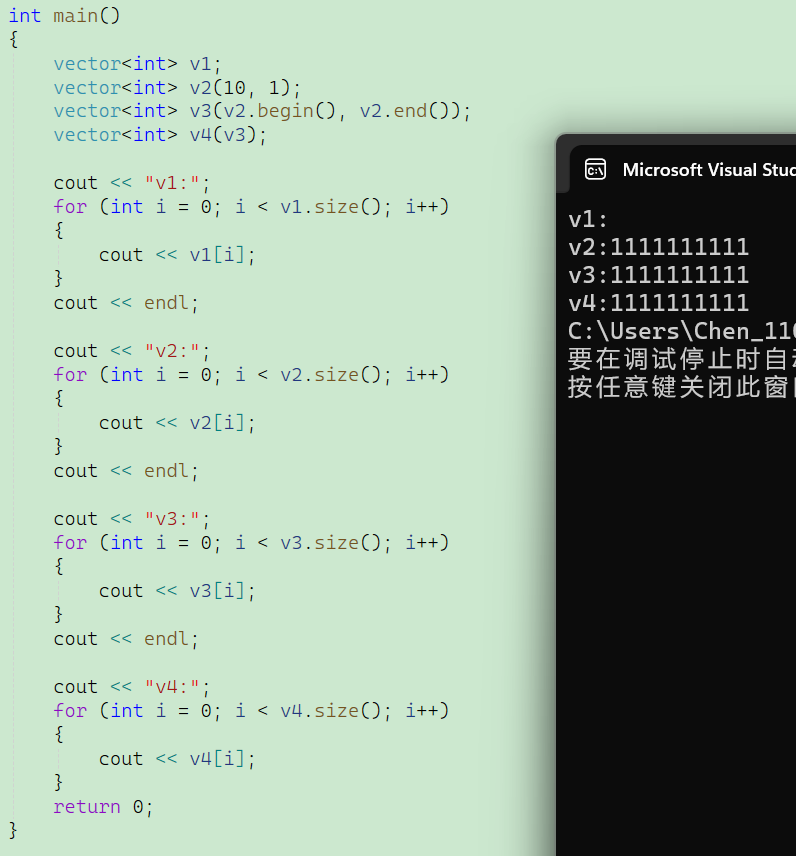
除了使用for循环,还可以使用范围for和迭代器来简化循环操作:
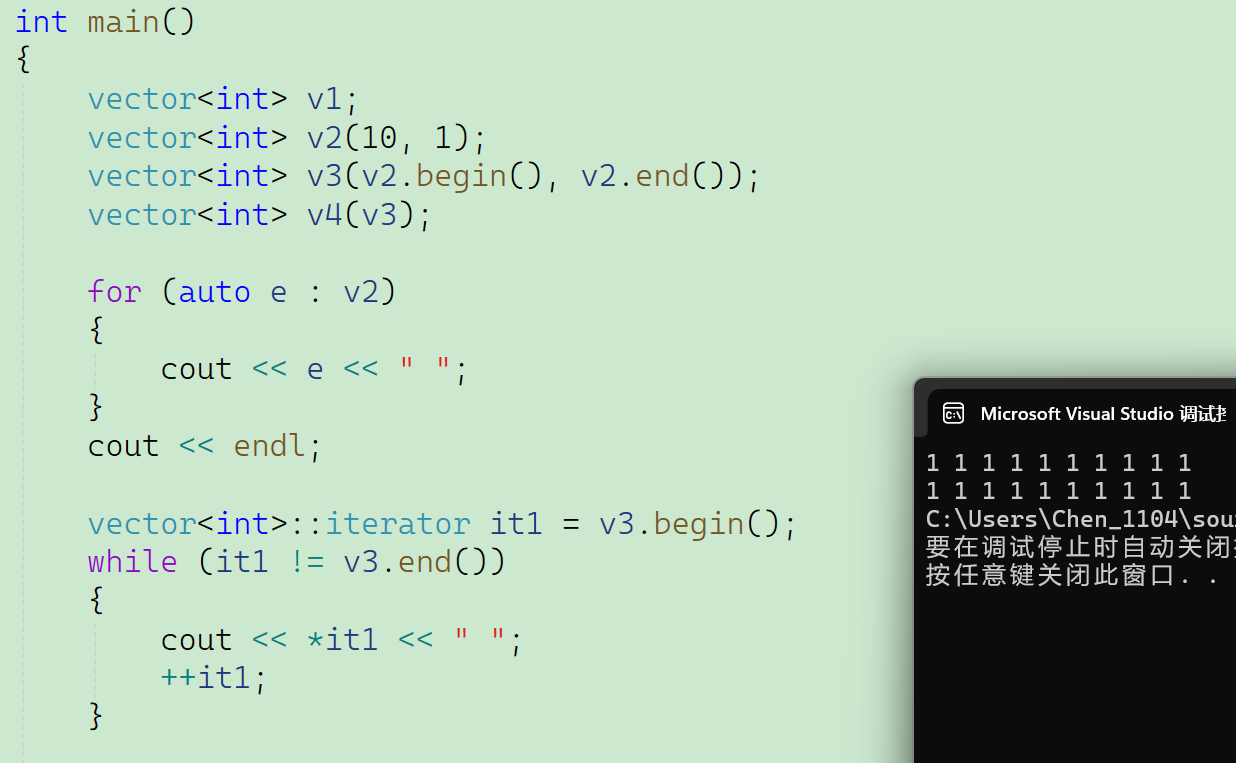
在这里我展示一个v2对象和一个v3对象的打印。在这里我们同时也使用了迭代器中的begin和end。所以大家会发现STL容器有一个特点就是:详细学习了其中一种容器之后,学习其他的容器就会非常快。vector有非常多和string相似的地方,经过了前面对string的详细学习,所以我们对vector的讲解的进度就会快很多。
6.vector的插入操作
首先来看一下vector里面不同于string类里面的插入:emplace_back。

其实对于emplace_back来说它就有点像push_back都是在对象末尾插入内容,但有所不同的是,emplace_back在某些场景下效率会更高一些。
emplace_back直接在 vector 的末尾内存空间(预留 / 新分配的空间)中就地构造对象 。它不需要接收已构造的对象,而是接收对象构造所需的参数列表 ,然后在 vector 的目标位置直接调用对象的构造函数。 即:跳过了临时对象的创建步骤,直接在目标内存地址完成对象构造。
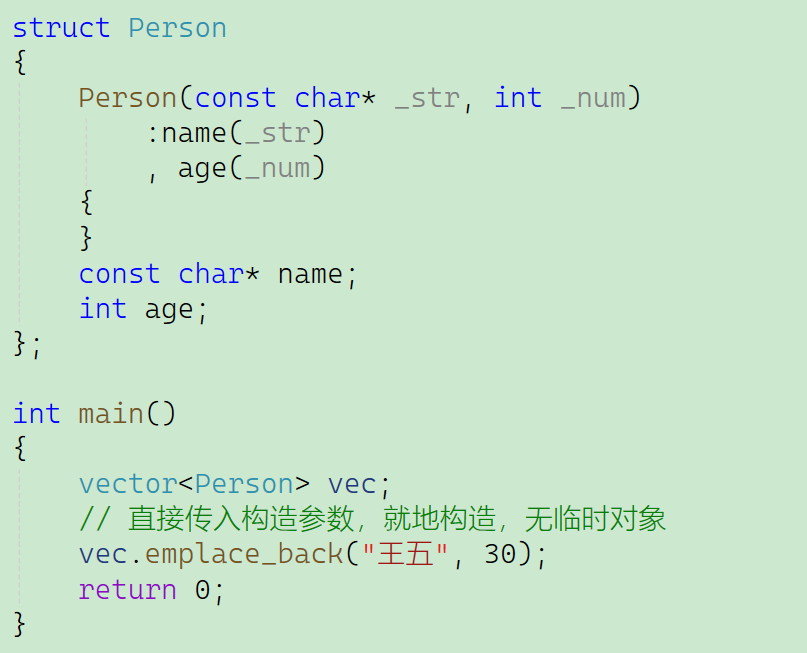
假设我们有一个自定义类Person,只有带参构造函数Person(string name,int age)
使用push_back添加对象时,必须先创建一个临时对象,再将其拷贝 / 移动到 vector 中,临时对象随后会被销毁:

使用emplace_back时,直接传入构造参数,在 vector 末尾就地构造Person对象,全程无临时对象产生:
效率更高的第二点是:对于push_back:无论传入左值还是右值,都需要额外调用一次「拷贝构造函数」或「移动构造函数」,将对象从原内存(或临时内存)复制 / 移动到 vector 的内存中。
对于emplace_back:直接在 vector 的目标内存中构造对象,无需额外的拷贝或移动操作,仅调用一次对象的普通构造函数即可完成添加操作,减少了一次构造调用的开销。
总结一下就是:对于内置类型(如int、char),两者性能差异几乎可以忽略(因为内置类型无复杂构造 / 析构逻辑)。在绝大多数场景下,优先使用emplace_back,既能提升性能,又能增强兼容性;仅在需要明确传入已构造对象,且无需就地构造时,可使用push_back。

我们来看一下vector中的insert。 string里面的insert函数的作用是:在指定位置插入字符,然后其余的内容向后自动移动。vector里的insert也是一样,但是vector的insert设计的就简洁了很多,并且我们来看这里面的参数,都有一个iterator position,表示迭代器的位置,而string里的insert用的还是字符串的下标。我们来做一下代码演示: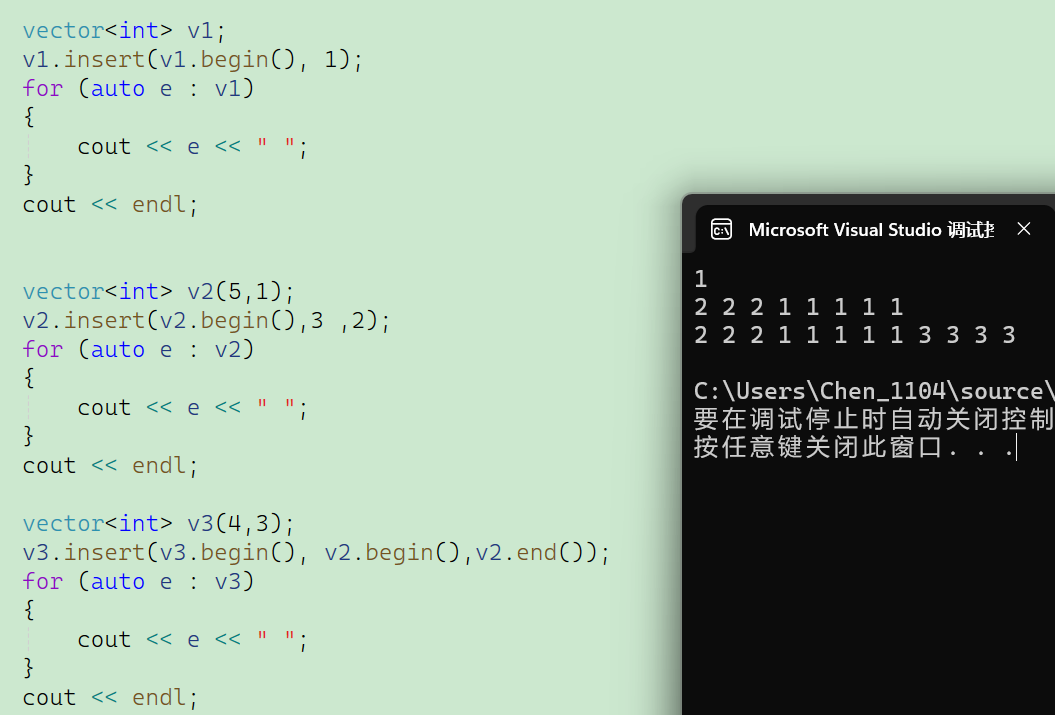
对于v1来说,是直接在头部插入一个数字1。
对于v2来说,是在v2的头部插入3个2。
对于v3来说是在v3的头部插入v2的从头到尾。
但是按照目前参数的逻辑,只能在头部或者尾部插入。那如果我想要在其他位置插入值的话该怎么办呢?因为我们使用的是迭代器,对于迭代器来说它是一个像指针一样的东西,既然是像指针的话,我们就可以用加减指向的位置来进行操作:
对于v3这个vector对象来说,它原本自身存储的内容是4个3,现在我调用insert函数,在v3头部往后两个位置的地方,插入v2的从头到尾。这就实现了任意位置插入的操作。
那如果我现在不想要根据下标位置来插入,我想要根据vector对象里存储的内容的位置来插入。比如说有一个vector对象存储的是1 2 3 4 5,我想要在3后面插入一个6,那这个时候我应该是要先找到数字3,然后再进行插入操作,但问题是该怎么找到数字3呢?
7.算法库中的find函数
在string类当中有一个函数叫find,可是我们观察一下,在vector类中竟然没有find函数。其实这是因为vector如果想要使用find函数,使用的其实是标准算法库中的find函数:
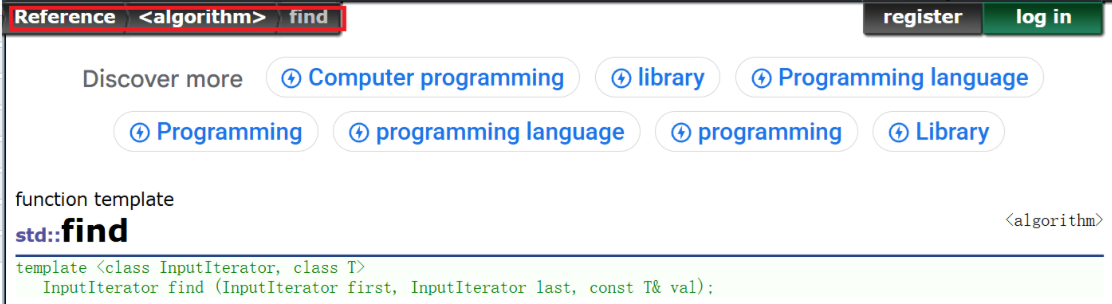
算法库里面的find函数其实是一个模板,所以不管是vector类还是list类都可以用这个find函数来进行查找内容的操作。那为什么string类需要自己创建一个find函数,而不用算法库里的find函数呢?这是因为对于string类的查找比较复杂,它需要从指定位置开始查找等等。

那我们来看一下算法库中find函数的样例,因为find函数如果没有找到指定内容,就返回要查找的这个数组里面的最后一个内容,如果找到了,就返回找到的这个数字的迭代器。
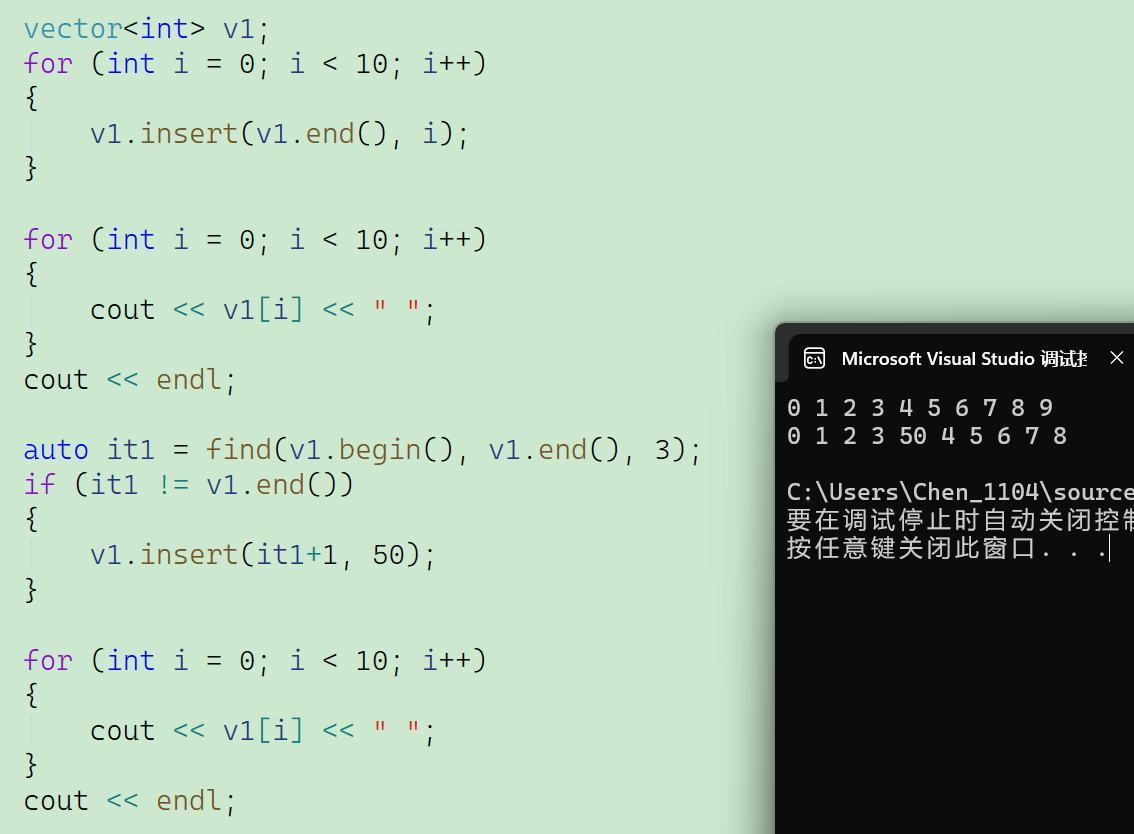
首先我先创建了一个vector对象v1,然后往v1里面依次插入0到9共10个数字。接着调用find函数并用it1这个变量来接受find的返回值。然后再调用insert函数在下标为3的数字后面插入一个50。
8.vector中的删除操作

大家可以看到erase的参数也是迭代器的位置,并且还有一个迭代器区间。那么这样的话我们就可以实现指定位置的删除和指定区间的删除。
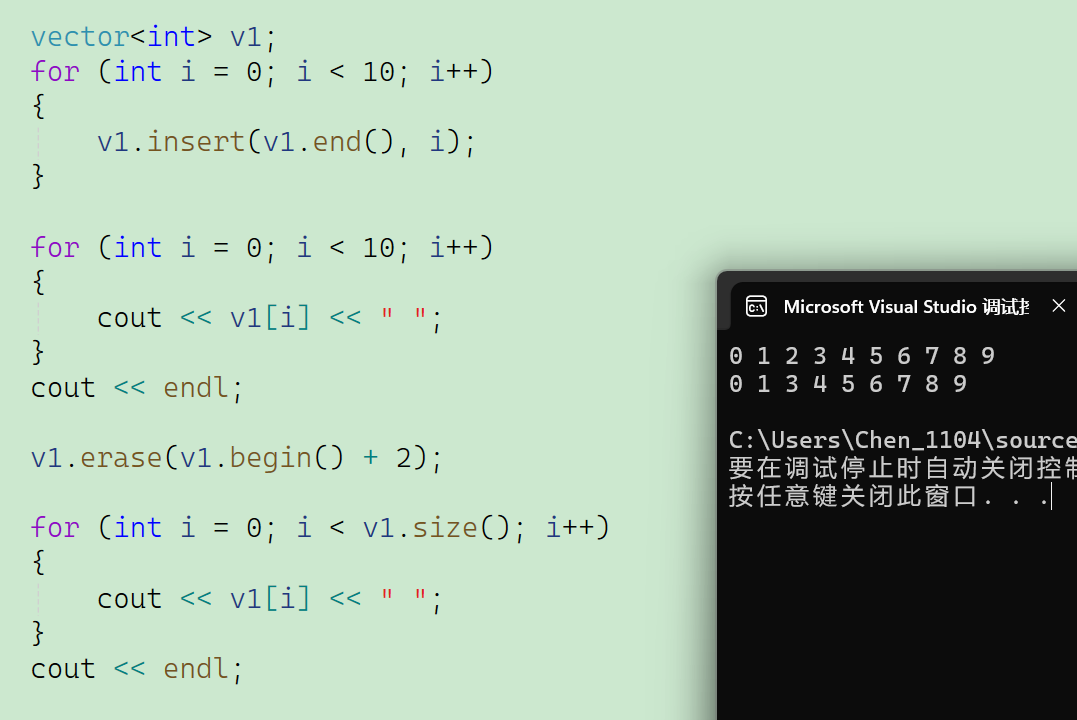
比如这里我是想要把v1首元素往后两个位置的数字,也就是数字2给删除。那么调用erase函数,让迭代器begin往后加2。要注意的是不管是vector还是string的insert和erase函数,因为都涉及到元素的移动,所以会降低效率,要谨慎使用。
9.vector的关系运算符重载

和string一样,vector也支持关系运算符重载,并且vector的比较大小是根据vector储存内容依次去比较,而不是直接比较vector的长度大小。和string的比较大小逻辑类似。
10. vector和string的区别

大家来看这两行代码,我们说string的底层是一个数组,vector的底层也是一个数组。并且对于string来说,它同时也是字符串。那么当我把vector的参数类型设置成char类型,那么从底层的角度来看,这两个容器存储的好像是同样的东西。
它们的差异点在于,虽然vector存储的也是字符数组,但是vector只存储用户显示存入的char类型元素,并不会在这个数组末尾自动加上 ' \0 ' 标识。如果没有 ' \0 ' 标识的话,vector就不能兼容C语言。
并且在成员函数的设计上,string和vector也不太一样,比如string有一个成员函数叫append,它可以在原字符串后直接+=另一个字符串,但是对于vector来说只有一个push_back,每次只能插入一个元素。并且对于vector来说,它是一个类模板,也就意味着它可以存储任何类型的数据,包括string类型等等,比如写成:vector<string> v1;也是没有问题的。
所以总的来说只能是vector的参数类型设置成char类型可以储存字符,变成一个字符数组,但是完全不能替代string。
11.vector的嵌套
对于vector的嵌套,我想用一道算法题目来带大家深入了解:118. 杨辉三角 - 力扣(LeetCode)
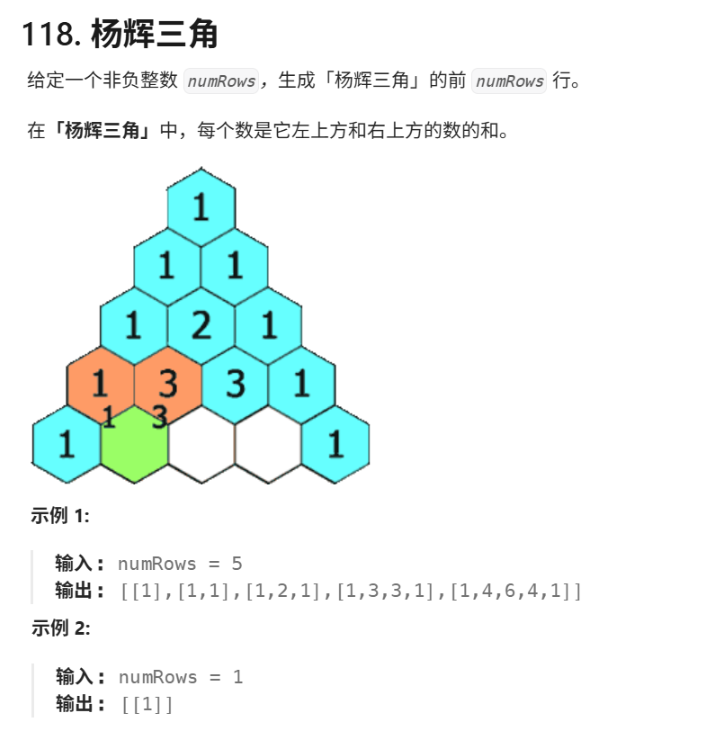
这是一道杨辉三角的算法题目,它要求我们把杨辉三角每一行的内容都打印出来。在这道算法题目里面我们需要用到二维数组,而这个二维数组我们就可以用vector的嵌套来实现。所以vector<vector<int>>实际上就是一个二维动态数组。
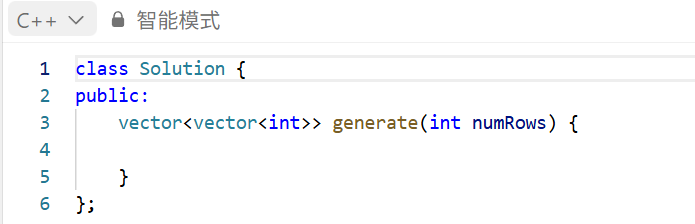
这是力扣平台上提供的初始代码。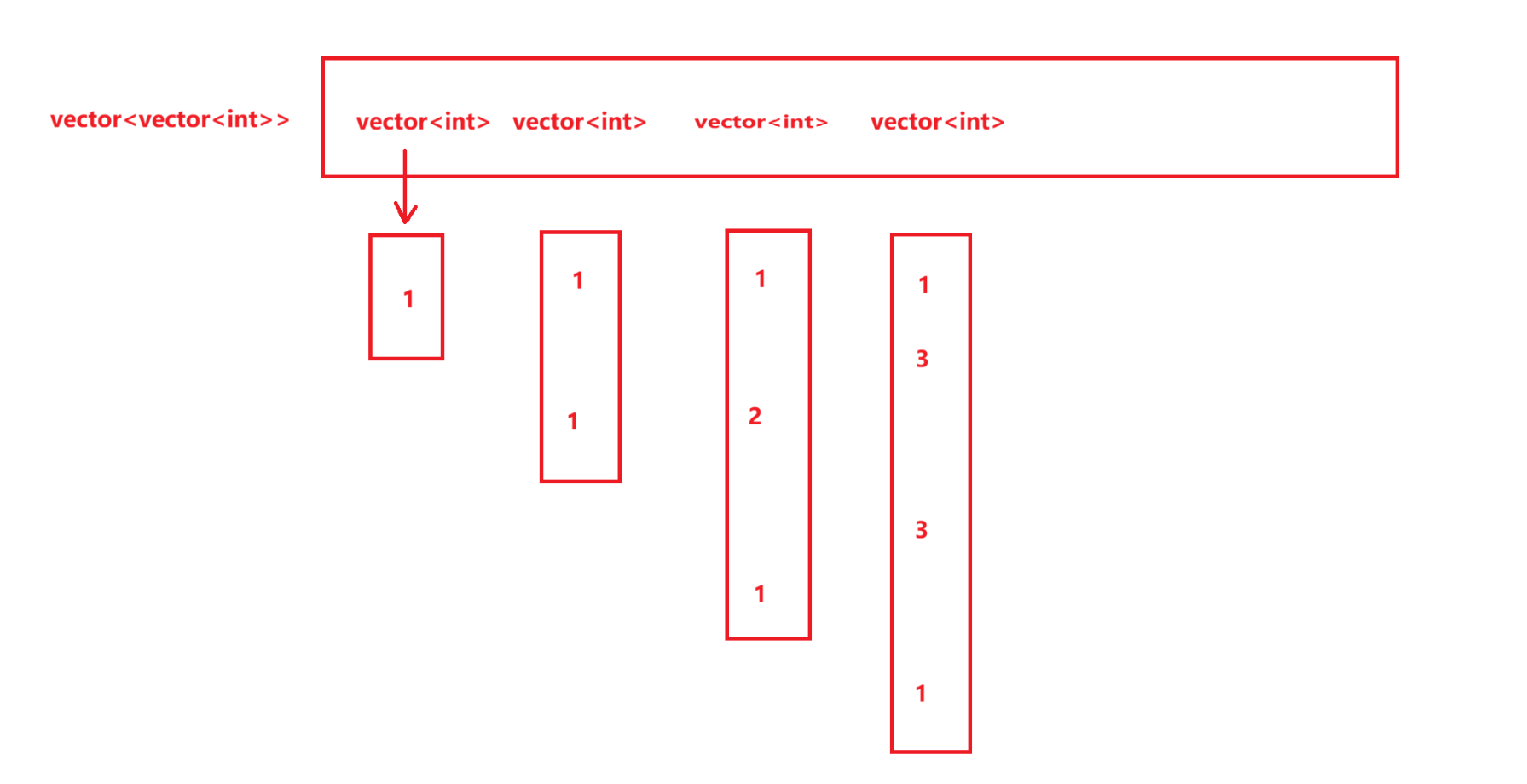
这就是我们大概的思路:首先创建一个二维数组。每个数组里面存储的又是一个一维数组。而这个一维数组里面存储的就是杨辉三角每一行的内容。那么首先我们就要先开辟出来二维数组的大小,然后再开辟每个一维数组中的大小,先把空间设定好。
 这里的思路是先创建一个二维数组vv,然后开辟numRows个大小类型都为 int 类型的数组,这里其实第二个参数,即 vector<int>() 也可以不写,因为resize的第二个参数还有缺省值,会自动调用默认构造函数然后确认类型。再调用循环将二维数组里面的每个内容都设置为1。其中第 i 个数组就设置 i+1 个 1 。
这里的思路是先创建一个二维数组vv,然后开辟numRows个大小类型都为 int 类型的数组,这里其实第二个参数,即 vector<int>() 也可以不写,因为resize的第二个参数还有缺省值,会自动调用默认构造函数然后确认类型。再调用循环将二维数组里面的每个内容都设置为1。其中第 i 个数组就设置 i+1 个 1 。
并且我们来观察一下杨辉三角,对于每一行来说,第一位和最后一位的数字都是1,所以我们只需要对中间位置的内容进行操作。并且比如说下标为 1 的数字,其实是由上一行下标为 1 和 0 的数字相加而成的。那么假设,有一个下标为n的数字,那它就是由上一行的下标为 n 和 n-1 的数字相加而成的。
那么最后的代码就是这样:

要注意在第二个循环里面 i 的初始值是2,因为要从第三行开始才会有杨辉三角的特征。并且我们要保证第一行第 1 个和最后一个的数字都是 1 ,所以要从首位的下一位开始,到末位的前一位结束。即:size_ j = 1 ; j < vv i . size( ) - 1 ;
对于vector的使用就暂时讲到这里,本文到此结束,感谢各位读者的阅读。如果有讲得不好或错误的地方欢迎大家指正和批评。