前文"Run如何撮合需求、能力与流程"中,调用client.beta.threads.runs.create后,任务提交给了OpenAI云服务器端。本文讨论OpenAI云服务器端的处理流程:任务入队、等待调度、状态逐步转换,到最终完成并写入结果并返回给客户端。
这个过程的核心是异步非阻塞的任务生命周期管理 :你调用runs.create只是"提交任务",而非"等待任务完成",云服务器会将任务加入队列,按优先级调度处理,处理完成后把结果写入Thread,你需要通过轮询/监听状态来获取最终结果。下面结合前文"鲜花价格计算器"案例,补充这个完整流程:
一、Run任务的完整生命周期(云服务视角)
整个过程可分为6个核心阶段,每个阶段对应Run的特定状态,且状态会实时更新到OpenAI的服务器中:
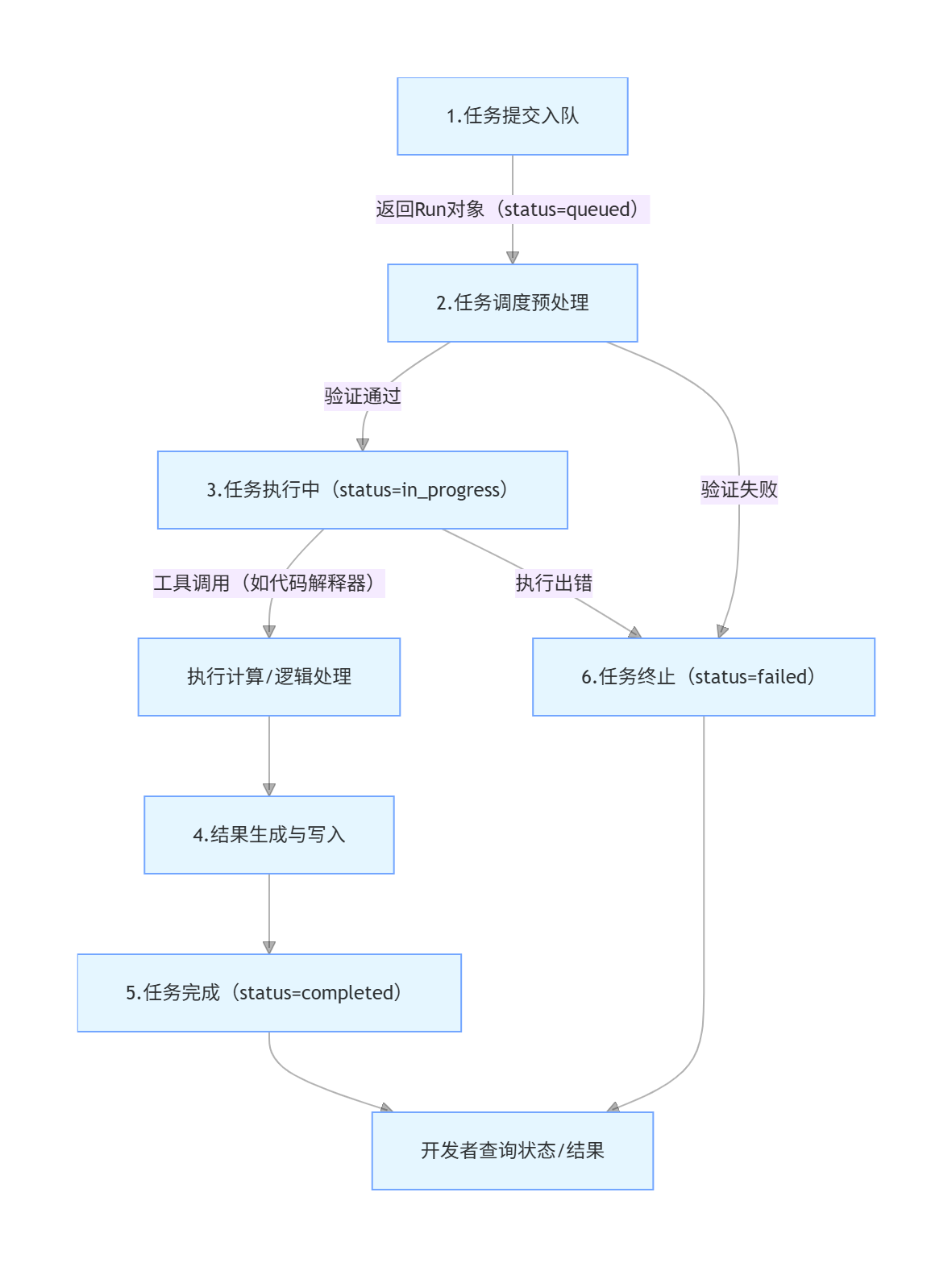
阶段1:任务提交与入队(客户端→云服务)
- 客户端动作 :调用
client.beta.threads.runs.create(thread_id=..., assistant_id=...),传入"工作环境(Thread)"和"助手能力(Assistant)"的关联ID; - 云服务动作 :
- 立即生成一个唯一的
run_id(任务标识); - 验证入参的合法性(如
thread_id/assistant_id是否存在),若参数非法直接返回status=failed; - 若参数合法,将任务加入全局任务队列(按优先级排序,付费用户/低负载时段调度更快);
- 立即返回Run对象给客户端(非阻塞),此时
status=queued(排队中),客户端无需等待,可继续执行其他逻辑。
- 立即生成一个唯一的
示例返回(初始Run对象):
python
Run(id='run_xxxx', status='queued', created_at=17198xxxxxx, ...)阶段2:任务调度与预处理(云服务内部)
- 云服务动作 :
- 从任务队列中取出你的Run任务(按"优先级+提交时间"排序,比如GPT-4任务优先级高于GPT-3.5);
- 预处理:加载Assistant的配置(模型、工具、指令)、读取Thread中的用户消息(需求)、检查工具权限(如代码解释器是否可用);
- 若预处理失败(如Assistant绑定的模型已下线、Thread无用户消息),直接将Run状态改为
failed,并记录失败原因; - 若预处理成功,将Run状态改为
in_progress(执行中)。
阶段3:任务执行(核心阶段,云服务→大模型+工具)
这是任务的核心处理环节,云服务会驱动"助手"在"线程环境"中处理用户需求,分两种场景(以你的鲜花计算器为例):
场景1:纯文本回复(无工具调用)
云服务将"用户需求+助手指令"打包发送给指定的大模型(如gpt-4-turbo),大模型直接生成文本回复。
场景2:工具调用(如代码解释器,你的案例)
- 云服务将用户需求发送给大模型,大模型判断"需要调用代码解释器计算价格";
- 云服务触发代码解释器工具,执行计算逻辑(
3*5 + 2*8 = 31); - 工具返回计算结果给大模型,大模型结合结果生成带计算过程的自然语言回复;
- 整个执行过程中,Run状态始终为
in_progress,云服务会实时记录执行日志(如工具调用耗时、模型推理耗时)。
阶段4:结果生成与写入(云服务→Thread)
- 云服务动作 :
- 大模型生成最终回复后,云服务将这条回复以
role=assistant的消息写入对应的Thread(绑定thread_id); - 记录回复的创建时间、内容、关联的Run ID;
- 完成结果写入后,准备更新Run状态。
- 大模型生成最终回复后,云服务将这条回复以
阶段5:任务完成/终止(状态最终固化)
- 正常完成 :若所有步骤无异常,Run状态被更新为
completed,云服务会记录完成时间、消耗的Token数等元数据; - 异常终止 :若执行过程中出错(如模型超时、工具调用失败、权限不足),Run状态被更新为
failed,并在last_error字段中记录错误原因(如"message": "Code interpreter execution timed out"); - 手动终止 :若你调用
client.beta.threads.runs.cancel(),Run状态会变为cancelled。
阶段6:开发者获取结果(客户端←云服务)
- 你通过轮询
client.beta.threads.runs.retrieve(thread_id, run_id)获取最终状态:- 若状态为
completed,调用client.beta.threads.messages.list(thread_id)从Thread中读取助手回复; - 若状态为
failed,从run.last_error中排查问题。
- 若状态为
二、实战验证:状态转换的代码监控(客户端视角)
结合前文的代码,补充完善后续的处理(这段正是对上述流程的"客户端视角监控"):
python
# 提交任务(阶段1:入队,status=queued)
run = client.beta.threads.runs.create(thread_id=thread.id, assistant_id=assistant.id)
# 轮询监控状态转换(阶段2→3→5)
while run.status not in ["completed", "failed", "cancelled"]:
time.sleep(2) # 避免频繁查询
run = client.beta.threads.runs.retrieve(thread_id=thread.id, run_id=run.id)
print(f"当前状态:{run.status}") # 会依次打印 queued → in_progress → completed
# 阶段6:获取结果
if run.status == "completed":
messages = client.beta.threads.messages.list(thread_id=thread.id)
print("任务完成,结果:", messages.data[0].content[0].text.value)
elif run.status == "failed":
print("任务失败,原因:", run.last_error.message)记住:
runs.create的本质是异步提交任务:云服务不立即处理,而是入队等待调度,客户端快速拿到Run ID和初始状态;- 任务生命周期核心是状态转换 :
queued(排队)→in_progress(执行中)→completed/failed(最终状态); - 结果最终写入Thread:Run仅负责驱动执行,结果持久化在Thread中,需从Thread读取最终回复;
- 客户端需通过轮询状态获取结果,这是异步任务的标准处理方式,适配云服务的分布式调度逻辑。
补充:异步流程的特点
- 非阻塞设计 :调用
runs.create后立即返回,不会阻塞客户端线程(比如你的Python程序不会卡在这一步等结果),适合处理耗时任务(如复杂计算、多轮工具调用); - 状态驱动 :Run的全生命周期通过
status字段体现,开发者只需关注状态变化,无需关心云服务内部的调度、执行细节; - 结果持久化:最终结果写入Thread而非Run本身,即使Run执行完成,Thread中的消息也会长期保存(除非手动删除),可随时查询;
- 重试友好 :若Run状态为
failed,你可复用原Thread和Assistant,重新创建Run(只需改参数),无需重建整个环境。