在 AI 语音技术飞速发展的今天,个性化语音交互已成为智能产品的核心竞争力之一。从智能客服的专属音色、有声书的个性化朗读,到虚拟数字人的语音定制,个人音色复刻 技术正逐步从实验室走向商业化落地。
阿里通义推出的 cosyvoice-v3-plus 模型凭借其低成本、高还原度、短音频适配的特性,成为中小开发者实现音色复刻的首选方案;而华为对象存储服务(OBS)则为音频文件的存储与在线访问提供了稳定、高效的支撑。本文将从技术原理、代码实现、部署测试到问题排查,完整讲解如何基于 cosyvoice-v3-plus 结合华为 OBS 实现个人音色复刻系统。
一、前言:音色复刻的时代价值与技术背景
1.1 音色复刻的应用场景
音色复刻(Voice Cloning)是指通过少量参考音频(通常 5-20 秒),快速生成与目标人物音色高度相似的合成语音。其典型应用场景包括:
- 个性化语音助手:为智能音箱、手机助手定制用户专属音色;
- 内容创作:有声书、播客、短视频的个性化配音,降低配音成本;
- 智能客服:企业定制专属客服音色,提升品牌辨识度;
- 无障碍服务:为语言障碍者复刻自然语音,改善沟通体验;
- 虚拟数字人:为虚拟主播、数字员工匹配专属音色,增强沉浸感。
1.2 cosyvoice-v3-plus:新一代语音复刻模型
cosyvoice-v3-plus 是阿里通义千问推出的新一代语音生成模型,相比传统 TTS 模型,其核心优势在于:
- 低数据量要求:仅需 5-20 秒参考音频即可完成音色复刻,无需大规模语料;
- 高还原度:支持语音语调、情感的精准复刻,接近真人发声效果;
- 多语言支持:覆盖中文、英文等主流语言,适配多场景需求;
- 开放 API 接口:提供标准化的 SDK 与 RESTful 接口,降低开发门槛;
- 高性能:合成速度快,支持实时语音生成,适配高并发场景。
1.3 华为 OBS 在音色复刻中的核心作用
cosyvoice-v3-plus 的音色复刻接口要求参考音频以公网可访问的 URL 形式传入,而非直接上传文件。华为 OBS 作为对象存储服务,在此链路中承担核心角色:
- 音频文件存储:临时存储用户上传的参考音频,避免本地文件管理的碎片化;
- 公网 URL 生成:为存储的音频文件生成临时公网访问链接,满足接口要求;
- 高可用性:华为 OBS 的分布式存储架构保证音频文件的稳定访问,避免因本地服务宕机导致的接口调用失败;
- 灵活的权限控制:支持设置 URL 过期时间,保障用户音频数据的安全性。
1.4 本文实现目标与技术栈
实现目标
基于 Spring Boot 开发一套标准化的音色复刻接口,实现两大核心功能:
- 上传参考音频,调用 cosyvoice-v3-plus 接口生成克隆音色(返回 VoiceId);
- 传入克隆 VoiceId 与文本,合成目标音色的语音文件并保存。
核心技术栈
| 技术 / 框架 | 作用 |
|---|---|
| Spring Boot 3.x | 快速构建 RESTful 接口,整合各类组件 |
| cosyvoice-v3-plus SDK | 调用阿里通义的音色复刻与语音合成接口 |
| 华为 OBS SDK | 上传音频文件并生成公网 URL |
| Redis | 缓存克隆 VoiceId,设置过期策略 |
| FFmpeg(AudioUtils) | 校验音频格式、计算音频时长 |
| Lombok | 简化 Java 代码,减少模板代码 |
二、核心技术原理拆解
2.1 cosyvoice-v3-plus 音色复刻的核心流程
cosyvoice-v3-plus 的音色复刻本质是 "参考音频特征提取→音色模型训练→VoiceId 生成→语音合成" 的链路,具体流程如下:
- 用户上传参考音频:前端上传 5-20 秒的 MP3/WAV 格式音频文件;
- 音频预处理:校验音频格式、时长,确保符合接口要求;
- OBS 上传与 URL 生成:将音频文件上传至华为 OBS,生成公网可访问的 URL;
- 调用 VoiceEnrollmentService:传入音频 URL、语言类型等参数,调用阿里通义的音色注册接口;
- 生成克隆 VoiceId:接口返回唯一的 VoiceId(音色标识),作为后续合成的核心参数;
- 语音合成:传入 VoiceId 与目标文本,调用语音合成接口生成对应音色的音频;
- 音频保存与返回:将合成的音频文件保存至本地 / OSS,返回文件路径与名称。
2.2 华为 OBS 的 URL 生成逻辑
华为 OBS 为文件生成公网 URL 的核心逻辑是 "签名 URL" 机制:
- 开发者通过 AccessKey/SecretKey 初始化 OBS 客户端;
- 将本地音频文件上传至指定 OBS Bucket;
- 调用 OBS SDK 的
generatePresignedUrl方法,设置 URL 过期时间(如 30 分钟); - 生成包含签名信息的公网 URL,该 URL 可在有效期内被 cosyvoice-v3-plus 接口访问;
- 音频文件使用完成后,可主动删除 OBS 中的文件,或依赖 Bucket 的生命周期规则自动清理。
2.3 端到端的语音复刻链路
整个系统的端到端链路可总结为:
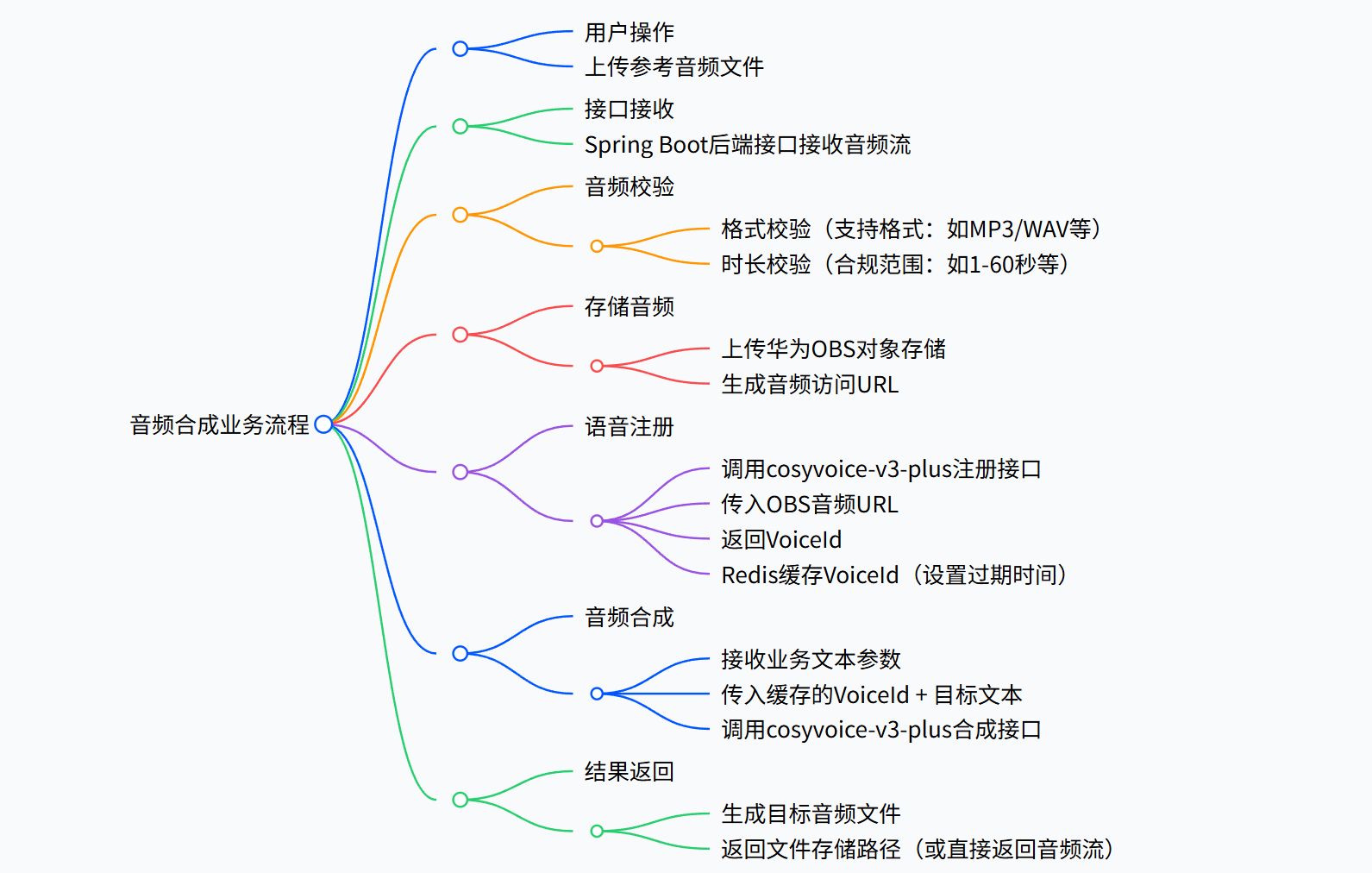
三、代码架构与核心模块解析
3.1 整体项目架构设计
项目采用经典的分层架构,严格遵循 "控制层 - 服务层 - 工具层" 的职责划分,保证代码的可维护性与扩展性:

3.2 Controller 层:接口标准化设计
Controller 层的核心职责是定义标准化的 RESTful 接口,接收前端请求并转发至 Service 层,不包含业务逻辑。
java
import gzj.spring.ai.DTO.CloneSpeechSynthesisRequestDTO;
import gzj.spring.ai.DTO.VoiceEnrollmentRequestDTO;
import gzj.spring.ai.Request.SpeechSynthesisResponse;
import gzj.spring.ai.Response.VoiceEnrollmentResponse;
import gzj.spring.ai.Service.VoiceEnrollmentService;
import jakarta.annotation.Resource;
import org.springframework.web.bind.annotation.*;
import org.springframework.web.multipart.MultipartFile;
/**
* 对齐官方的语音克隆接口
*/
@RestController
@RequestMapping("/api/voice/enrollment")
public class VoiceEnrollmentController {
@Resource
private VoiceEnrollmentService voiceEnrollmentService;
/**
* 接口1:上传参考音频→创建克隆音色(官方VoiceEnrollment接口)
* POST /api/voice/enrollment/create
* Content-Type: multipart/form-data
*/
@PostMapping("/create")
public VoiceEnrollmentResponse createCloneVoice(
@RequestParam("audioFile") MultipartFile audioFile,
@RequestParam(value = "prefix", defaultValue = "myvoice") String prefix,
@RequestParam(value = "language", defaultValue = "zh") String language) {
VoiceEnrollmentRequestDTO request = new VoiceEnrollmentRequestDTO();
request.setAudioFile(audioFile);
request.setPrefix(prefix);
request.setLanguage(language);
return voiceEnrollmentService.createCloneVoice(request);
}
/**
* 接口2:使用克隆VoiceId合成语音
* POST /api/voice/enrollment/synthesize
* Content-Type: application/json
*/
@PostMapping("/synthesize")
public SpeechSynthesisResponse synthesizeWithCloneVoice(
@RequestBody CloneSpeechSynthesisRequestDTO request) {
return voiceEnrollmentService.synthesizeWithCloneVoice(request);
}
}接口设计说明
| 接口路径 | 请求方式 | Content-Type | 核心参数 | 功能描述 |
|---|---|---|---|---|
| /api/voice/enrollment/create | POST | multipart/form-data | audioFile(音频文件)、prefix(音色前缀)、language(语言) | 上传参考音频,生成克隆 VoiceId |
| /api/voice/enrollment/synthesize | POST | application/json | text(合成文本)、cloneVoiceId(克隆音色 ID) | 基于 VoiceId 合成语音 |
- 参数默认值 :prefix 默认值为
myvoice,language 默认值为zh,降低前端调用成本; - Content-Type 适配 :文件上传接口使用
multipart/form-data,JSON 参数接口使用application/json,符合 RESTful 规范; - 统一响应格式 :通过
VoiceEnrollmentResponse和SpeechSynthesisResponse封装返回结果,包含success、message、核心数据等字段,便于前端统一处理。
3.3 Service 层:核心业务逻辑实现
Service 层是整个系统的核心,包含接口定义(VoiceEnrollmentService)与实现类(VoiceEnrollmentServiceImpl),承担音频校验、OBS 上传、API 调用、Redis 缓存、音频合成等核心逻辑。
3.3.1 接口定义:VoiceEnrollmentService
java
import gzj.spring.ai.DTO.CloneSpeechSynthesisRequestDTO;
import gzj.spring.ai.DTO.VoiceEnrollmentRequestDTO;
import gzj.spring.ai.Request.SpeechSynthesisResponse;
import gzj.spring.ai.Response.VoiceEnrollmentResponse;
/**
* 对齐官方的语音克隆+合成服务接口
*/
public interface VoiceEnrollmentService {
/**
* 官方接口:上传音频(转URL)→ 创建克隆音色(VoiceEnrollmentService)
*/
VoiceEnrollmentResponse createCloneVoice(VoiceEnrollmentRequestDTO request);
/**
* 使用克隆音色ID合成语音
*/
SpeechSynthesisResponse synthesizeWithCloneVoice(CloneSpeechSynthesisRequestDTO request);
}接口设计遵循 "单一职责原则",将 "创建克隆音色" 与 "合成语音" 拆分为两个方法,便于后续扩展与维护。
3.3.2 实现类核心逻辑:VoiceEnrollmentServiceImpl
实现类是业务逻辑的核心载体,我们按功能模块拆解其核心代码:
(1)初始化配置与常量定义
java
@Slf4j
@Service
public class VoiceEnrollmentServiceImpl implements VoiceEnrollmentService {
// 通义千问API Key
@Value("${spring.ai.dashscope.api-key}")
private String apiKey;
// 克隆音频存储路径
@Value("${audio.clone-voice-path}")
private String cloneVoicePath;
// 依赖注入工具类与Redis
@Resource
private OBSUtils obsUtils;
@Resource
private AudioUtils audioUtils;
@Resource
private StringRedisTemplate stringRedisTemplate;
// 参考音频时长要求(5-20秒)
private static final int MIN_AUDIO_DURATION = 5;
private static final int MAX_AUDIO_DURATION = 20;
}- 通过
@Value注入配置文件中的 API Key 与音频存储路径,避免硬编码; - 定义音频时长常量(5-20 秒),符合 cosyvoice-v3-plus 的接口要求;
- 注入 OBS 工具类、音频工具类、Redis 模板,实现功能解耦。
(2)创建克隆音色:createCloneVoice 方法
该方法是音色复刻的核心,包含 7 个关键步骤:
步骤 1:基础参数校验
java
MultipartFile audioFile = request.getAudioFile();
if (audioFile == null || audioFile.isEmpty()) {
response.setSuccess(false);
response.setMessage("参考音频文件不能为空");
return response;
}校验音频文件是否为空,是接口调用的基础前提。
步骤 2:音频格式校验
java
String[] supportedFormats = {"mp3", "wav"};
if (!audioUtils.checkAudioFormat(audioFile, supportedFormats)) {
response.setSuccess(false);
response.setMessage("仅支持mp3/wav格式的参考音频");
return response;
}通过AudioUtils校验音频格式,仅支持 MP3/WAV(cosyvoice-v3-plus 的推荐格式)。
步骤 3:本地临时文件保存与时长校验
java
// 保存临时文件
tempFile = File.createTempFile("voice_clone_", "." + getFileSuffix(audioFile.getOriginalFilename()));
try (FileOutputStream fos = new FileOutputStream(tempFile)) {
fos.write(audioFile.getBytes());
}
// 校验音频时长(5-20秒)
double duration = audioUtils.getAudioDuration(tempFile);
if (duration < MIN_AUDIO_DURATION || duration > MAX_AUDIO_DURATION) {
response.setSuccess(false);
response.setMessage("参考音频时长必须在5-20秒之间(当前:" + duration + "秒)");
return response;
}- 将上传的 MultipartFile 保存为本地临时文件,便于计算音频时长;
- 通过
AudioUtils(基于 FFmpeg)计算音频时长,确保符合接口要求; - 临时文件会在后续通过
finally块删除,避免磁盘占用。
步骤 4:华为 OBS 上传与 URL 生成
java
audioFileUrl = obsUtils.uploadToOBS(audioFile);
if (!StringUtils.hasText(audioFileUrl)) {
response.setSuccess(false);
response.setMessage("音频文件上传OSS失败,无法生成在线URL");
return response;
}调用OBSUtils将音频文件上传至华为 OBS,并生成公网可访问的 URL。此处需注意:
- OBS Bucket 需配置为 "公共读" 或生成签名 URL;
- URL 需包含完整的 HTTP/HTTPS 路径,确保 cosyvoice-v3-plus 接口可访问。
步骤 5:调用通义 VoiceEnrollmentService 创建克隆音色
java
VoiceEnrollmentService enrollmentService = new VoiceEnrollmentService(apiKey);
VoiceEnrollmentParam param = VoiceEnrollmentParam.builder()
.model(request.getCloneModelName())
.languageHints(Collections.singletonList(request.getLanguage())) // 中文zh
.build();
// 核心:创建克隆音色
Voice myVoice = enrollmentService.createVoice(
request.getTargetModel(), // cosyvoice-v3-plus
request.getPrefix(), // myvoice
audioFileUrl, // 在线音频URL
param
);- 初始化阿里通义的
VoiceEnrollmentService,传入 API Key; - 构建参数对象
VoiceEnrollmentParam,指定模型与语言; - 调用
createVoice方法,传入 cosyvoice-v3-plus 模型名、音色前缀、音频 URL,生成克隆 VoiceId。
步骤 6:结果封装与 Redis 缓存
java
// 组装响应
response.setVoiceId(myVoice.getVoiceId());
response.setRequestId(enrollmentService.getLastRequestId());
response.setAudioFileUrl(audioFileUrl);
response.setSuccess(true);
response.setMessage("音色克隆提交成功");
// 缓存音色ID(Redis,7天过期)
stringRedisTemplate.opsForValue().set(
"clone_voice:" + myVoice.getVoiceId(),
request.getPrefix(),
7,
TimeUnit.DAYS
);- 将 VoiceId、RequestId 等核心信息封装到响应对象;
- 将 VoiceId 缓存至 Redis,设置 7 天过期时间,避免无效 VoiceId 的使用。
步骤 7:异常处理与临时文件清理
java
} catch (ApiException e) {
// 捕获通义官方错误码
log.error("通义VoiceEnrollment API调用失败(错误码:{})", e.getCause(), e);
response.setSuccess(false);
response.setMessage("音色克隆失败:" + e.getMessage() + "(错误码:" + e.getCause() + ")");
} catch (Exception e) {
log.error("音色克隆未知异常", e);
response.setSuccess(false);
response.setMessage("音色克隆失败:" + e.getMessage());
} finally {
// 删除本地临时文件
if (tempFile != null && tempFile.exists()) {
tempFile.delete();
}
}- 捕获
ApiException(通义 API 专属异常),返回错误码与信息,便于排查; - 捕获通用异常,保证接口不崩溃;
- 在
finally块删除本地临时文件,避免磁盘泄漏。
总的实现类方法:
java
/**
* 核心:对齐官方示例的克隆逻辑(在线URL方式)
*/
@Override
public VoiceEnrollmentResponse createCloneVoice(VoiceEnrollmentRequestDTO request) {
VoiceEnrollmentResponse response = new VoiceEnrollmentResponse();
MultipartFile audioFile = request.getAudioFile();
// 1. 基础参数校验
if (audioFile == null || audioFile.isEmpty()) {
response.setSuccess(false);
response.setMessage("参考音频文件不能为空");
return response;
}
// 2. 校验音频格式和时长(复用之前的工具类)
String[] supportedFormats = {"mp3", "wav"};
if (!audioUtils.checkAudioFormat(audioFile, supportedFormats)) {
response.setSuccess(false);
response.setMessage("仅支持mp3/wav格式的参考音频");
return response;
}
// 3. 本地临时保存文件(校验时长)
File tempFile = null;
String audioFileUrl = null;
try {
// 3.1 保存临时文件
tempFile = File.createTempFile("voice_clone_", "." + getFileSuffix(audioFile.getOriginalFilename()));
try (FileOutputStream fos = new FileOutputStream(tempFile)) {
fos.write(audioFile.getBytes());
}
// 3.2 校验音频时长(5-20s)
double duration = audioUtils.getAudioDuration(tempFile);
if (duration < MIN_AUDIO_DURATION || duration > MAX_AUDIO_DURATION) {
response.setSuccess(false);
response.setMessage("参考音频时长必须在5-20秒之间(当前:" + duration + "秒)");
return response;
}
// 3.3 上传到OSS生成在线URL(官方接口必须传URL)
audioFileUrl = obsUtils.uploadToOBS(audioFile);
if (!StringUtils.hasText(audioFileUrl)) {
response.setSuccess(false);
response.setMessage("音频文件上传OSS失败,无法生成在线URL");
return response;
}
// 4. 调用官方VoiceEnrollmentService(100%对齐官方示例)
VoiceEnrollmentService enrollmentService = new VoiceEnrollmentService(apiKey);
VoiceEnrollmentParam param = VoiceEnrollmentParam.builder()
.model(request.getCloneModelName())
.languageHints(Collections.singletonList(request.getLanguage())) // 中文zh
.build();
// 核心:创建克隆音色(官方createVoice方法)
Voice myVoice = enrollmentService.createVoice(
request.getTargetModel(), // cosyvoice-v3-plus
request.getPrefix(), // myvoice
audioFileUrl, // 在线音频URL
param
);
// 5. 获取官方返回的核心参数
response.setVoiceId(myVoice.getVoiceId()); // 克隆后的音色ID
response.setRequestId(enrollmentService.getLastRequestId()); // 通义请求ID
response.setAudioFileUrl(audioFileUrl);
response.setSuccess(true);
response.setMessage("音色克隆提交成功");
// 6. 缓存音色ID(Redis,7天过期)
stringRedisTemplate.opsForValue().set(
"clone_voice:" + myVoice.getVoiceId(),
request.getPrefix(),
7,
TimeUnit.DAYS
);
log.info("官方克隆接口调用成功,VoiceId:{},RequestId:{}", myVoice.getVoiceId(), enrollmentService.getLastRequestId());
} catch (ApiException e) {
// 捕获通义官方错误码
log.error("通义VoiceEnrollment API调用失败(错误码:{})", e.getCause(), e);
response.setSuccess(false);
response.setMessage("音色克隆失败:" + e.getMessage() + "(错误码:" + e.getCause() + ")");
} catch (Exception e) {
log.error("音色克隆未知异常", e);
response.setSuccess(false);
response.setMessage("音色克隆失败:" + e.getMessage());
} finally {
// 删除本地临时文件
if (tempFile != null && tempFile.exists()) {
tempFile.delete();
}
}
return response;
}(3)合成语音:synthesizeWithCloneVoice 方法
该方法基于克隆 VoiceId 合成语音,核心步骤如下:
步骤 1:参数校验(含 Redis 缓存校验)
java
if (!StringUtils.hasText(request.getText())) {
response.setSuccess(false);
response.setMessage("合成文本不能为空");
return response;
}
if (!StringUtils.hasText(request.getCloneVoiceId())) {
response.setSuccess(false);
response.setMessage("克隆音色ID(cloneVoiceId)不能为空");
return response;
}
// 校验音色ID是否有效
String voiceName = stringRedisTemplate.opsForValue().get("clone_voice:" + request.getCloneVoiceId());
if (voiceName == null) {
response.setSuccess(false);
response.setMessage("克隆音色ID无效或已过期");
return response;
}- 校验合成文本与 VoiceId 是否为空;
- 通过 Redis 校验 VoiceId 是否有效(未过期),避免调用无效的 VoiceId。
步骤 2:创建音频存储目录
java
File cloneVoiceDir = new File(cloneVoicePath);
if (!cloneVoiceDir.exists() && !cloneVoiceDir.mkdirs()) {
response.setSuccess(false);
response.setMessage("克隆音频存储目录创建失败:" + cloneVoicePath);
return response;
}确保合成后的音频文件有合法的存储路径,避免文件保存失败。
步骤 3:调用通义语音合成接口
java
SpeechSynthesisParam param = SpeechSynthesisParam.builder()
.apiKey(apiKey)
.model(request.getModel() == null ? "cosyvoice-v3-plus" : request.getModel())
.voice(request.getCloneVoiceId()) // 核心:使用克隆的VoiceId
.build();
SpeechSynthesizer synthesizer = new SpeechSynthesizer(param, null);
ByteBuffer audioBuffer = synthesizer.call(request.getText());- 构建合成参数,核心是将
voice参数设置为克隆的 VoiceId; - 调用
call方法,传入合成文本,返回音频数据的 ByteBuffer。
步骤 4:音频文件保存与响应封装
java
// 保存合成音频文件
String fileName = "clone_" + request.getCloneVoiceId() + "_" + System.currentTimeMillis() + ".mp3";
File audioFile = new File(cloneVoiceDir, fileName);
try (FileOutputStream fos = new FileOutputStream(audioFile)) {
fos.write(audioBuffer.array());
}
// 组装响应
response.setSuccess(true);
response.setMessage("克隆音色语音合成成功");
response.setFileName(fileName);
response.setFilePath(audioFile.getAbsolutePath());- 生成唯一的文件名(VoiceId + 时间戳),避免文件覆盖;
- 将 ByteBuffer 中的音频数据写入文件,保存至指定目录;
- 封装文件名与路径,返回给前端。
总的实现类代码:
java
/**
* 使用克隆得到的VoiceId合成语音(逻辑不变,仅voice参数传克隆的VoiceId)
*/
@Override
public SpeechSynthesisResponse synthesizeWithCloneVoice(CloneSpeechSynthesisRequestDTO request) {
SpeechSynthesisResponse response = new SpeechSynthesisResponse();
// 1. 参数校验
if (!StringUtils.hasText(request.getText())) {
response.setSuccess(false);
response.setMessage("合成文本不能为空");
return response;
}
if (!StringUtils.hasText(request.getCloneVoiceId())) {
response.setSuccess(false);
response.setMessage("克隆音色ID(cloneVoiceId)不能为空");
return response;
}
// 校验音色ID是否有效
String voiceName = stringRedisTemplate.opsForValue().get("clone_voice:" + request.getCloneVoiceId());
if (voiceName == null) {
response.setSuccess(false);
response.setMessage("克隆音色ID无效或已过期");
return response;
}
// 2. 创建合成音频目录
File cloneVoiceDir = new File(cloneVoicePath);
if (!cloneVoiceDir.exists() && !cloneVoiceDir.mkdirs()) {
response.setSuccess(false);
response.setMessage("克隆音频存储目录创建失败:" + cloneVoicePath);
return response;
}
// 3. 调用合成SDK(voice参数传克隆的VoiceId)
SpeechSynthesisParam param = SpeechSynthesisParam.builder()
.apiKey(apiKey)
.model(request.getModel() == null ? "cosyvoice-v3-plus" : request.getModel())
.voice(request.getCloneVoiceId()) // 核心:使用克隆的VoiceId
.build();
SpeechSynthesizer synthesizer = new SpeechSynthesizer(param, null);
ByteBuffer audioBuffer = null;
try {
log.info("使用克隆VoiceId合成语音,文本:{},VoiceId:{}", request.getText(), request.getCloneVoiceId());
audioBuffer = synthesizer.call(request.getText());
} catch (ApiException e) {
log.error("合成失败(错误码:{})", e.getCause(), e);
response.setSuccess(false);
response.setMessage("语音合成失败:" + e.getMessage() + "(错误码:" + e.getCause() + ")");
return response;
} catch (Exception e) {
log.error("合成未知异常", e);
response.setSuccess(false);
response.setMessage("语音合成失败:" + e.getMessage());
return response;
} finally {
// 释放资源
if (synthesizer != null && synthesizer.getDuplexApi() != null) {
try {
synthesizer.getDuplexApi().close(1000, "资源释放");
} catch (Exception e) {
log.warn("资源释放失败", e);
}
}
}
// 4. 校验音频缓冲区
if (audioBuffer == null || audioBuffer.remaining() == 0) {
response.setSuccess(false);
response.setMessage("未获取到有效音频数据");
return response;
}
// 5. 保存合成音频文件
String fileName = "clone_" + request.getCloneVoiceId() + "_" + System.currentTimeMillis() + ".mp3";
File audioFile = new File(cloneVoiceDir, fileName);
try (FileOutputStream fos = new FileOutputStream(audioFile)) {
fos.write(audioBuffer.array());
if (!audioFile.exists() || audioFile.length() == 0) {
response.setSuccess(false);
response.setMessage("音频文件生成失败:文件为空");
return response;
}
} catch (IOException e) {
log.error("保存克隆音频失败", e);
response.setSuccess(false);
response.setMessage("音频文件保存失败:" + e.getMessage());
return response;
}
// 6. 组装响应
response.setSuccess(true);
response.setMessage("克隆音色语音合成成功");
response.setFileName(fileName);
response.setFilePath(audioFile.getAbsolutePath());
return response;
}3.4 参数与返回值封装
为保证参数传递的规范性,项目通过 DTO(数据传输对象)封装请求参数,通过 Response 封装返回结果:
请求Reques DTO 示例(VoiceEnrollmentRequestDTO)
java
import io.swagger.annotations.ApiModelProperty;
import lombok.Data;
import org.springframework.web.multipart.MultipartFile;
/**
* 语音克隆请求DTO(对齐官方参数)
* @author DELL
*/
@Data
public class VoiceEnrollmentRequestDTO {
/**
* 参考音频文件(本地上传)
*/
@ApiModelProperty(value = "参考音频文件")
private MultipartFile audioFile;
/**
* 自定义音色前缀(对应官方prefix)
*/
@ApiModelProperty(value = "自定义音色前缀")
private String prefix = "myvoice";
/**
* 目标模型(固定cosyvoice-v3-plus)
*/
@ApiModelProperty(value = "目标模型")
private String targetModel = "cosyvoice-v3-plus";
/**
* 克隆模型名称(固定voice-enrollment)
*/
@ApiModelProperty(value = "克隆模型名称")
private String cloneModelName = "voice-enrollment";
/**
* 语言(默认中文zh)
*/
@ApiModelProperty(value = "语言")
private String language = "zh";
}响应 Response 示例(VoiceEnrollmentResponse)
java
import io.swagger.annotations.ApiModelProperty;
import lombok.Data;
/**
* @author DELL
*/
@Data
public class VoiceEnrollmentResponse {
/**
* 克隆后的音色ID(合成时需要传入)
*/
@ApiModelProperty("克隆后的音色ID")
private String voiceId;
/**
* 通义请求ID(排查问题用)
*/
@ApiModelProperty("通义请求ID")
private String requestId;
/**
* 音频在线URL
*/
@ApiModelProperty("音频在线URL")
private String audioFileUrl;
/**
* 是否成功
*/
@ApiModelProperty("是否成功")
private Boolean success;
/**
* 提示信息
*/
@ApiModelProperty("提示信息")
private String message;
}通过 Lombok 的@Data注解简化 getter/setter 方法,减少模板代码。
3.5 工具类设计
(1)OBSUtils:华为 OBS 操作工具
核心方法uploadToOBS实现文件上传与 URL 生成:
java
package gzj.spring.ai.util;
import com.obs.services.ObsClient;
import com.obs.services.exception.ObsException;
import com.obs.services.model.HttpMethodEnum;
import com.obs.services.model.TemporarySignatureRequest;
import com.obs.services.model.TemporarySignatureResponse;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Component;
import org.springframework.web.multipart.MultipartFile;
import java.io.InputStream;
import java.util.UUID;
/**
* 华为OBS工具类:上传文件+生成预签名URL(核心修复:仅返回带签名的URL)
*/
@Slf4j
@Component
public class OBSUtils {
@Value("${huawei.obs.endpoint}")
private String endpoint;
@Value("${huawei.obs.access-key-id}")
private String accessKeyId;
@Value("${huawei.obs.secret-access-key}")
private String secretAccessKey;
@Value("${huawei.obs.bucket-name}")
private String bucketName;
/**
* 核心修复:上传文件+生成预签名URL(私有文件可访问)
*/
public String uploadToOBS(MultipartFile file) throws Exception {
if (file.isEmpty()) {
throw new IllegalArgumentException("音频文件不能为空");
}
// 1. 生成唯一OBS文件名
String suffix = file.getOriginalFilename().substring(file.getOriginalFilename().lastIndexOf("."));
String obsFileName = "voice-clone/" + UUID.randomUUID() + suffix;
ObsClient obsClient = null;
try {
// 2. 初始化OBS客户端(私有上传)
obsClient = new ObsClient(accessKeyId, secretAccessKey, endpoint);
// 3. 上传文件到OBS(默认私有ACL,无需公开)
try (InputStream is = file.getInputStream()) {
obsClient.putObject(bucketName, obsFileName, is);
log.info("OBS文件上传成功:{}", obsFileName);
}
// 4. 生成预签名URL(关键:带签名,通义可访问)
TemporarySignatureRequest req = new TemporarySignatureRequest();
req.setBucketName(bucketName);
req.setObjectKey(obsFileName);
req.setMethod(HttpMethodEnum.GET);
TemporarySignatureResponse response = obsClient.createTemporarySignature(req);
// 5. 返回带签名的URL(包含accessKey签名,无需公开可读)
String presignedUrl = response.getSignedUrl();
log.info("生成OBS预签名URL:{}", presignedUrl);
return presignedUrl;
} catch (ObsException e) {
log.error("OBS操作失败:{}", e.getErrorMessage(), e);
throw new Exception("OBS上传/预签名URL生成失败:" + e.getErrorMessage());
} finally {
if (obsClient != null) obsClient.close();
}
}
}(2)AudioUtils:音频校验工具
基于 FFmpeg 实现音频格式与时长校验:
java
import org.jaudiotagger.audio.AudioFile;
import org.jaudiotagger.audio.AudioFileIO;
import org.jaudiotagger.audio.AudioHeader;
import org.springframework.stereotype.Component;
import org.springframework.web.multipart.MultipartFile;
import java.io.File;
/**
* 音频工具类:校验时长、格式
* @author DELL
*/
@Component
public class AudioUtils {
/**
* 获取音频文件时长(秒)
*/
public double getAudioDuration(File audioFile) throws Exception {
AudioFile file = AudioFileIO.read(audioFile);
AudioHeader header = file.getAudioHeader();
return header.getTrackLength();
}
/**
* 校验音频格式(mp3/wav)
*/
public boolean checkAudioFormat(MultipartFile file, String[] supportedFormats) {
String originalFilename = file.getOriginalFilename();
if (originalFilename == null) return false;
String suffix = originalFilename.substring(originalFilename.lastIndexOf(".") + 1).toLowerCase();
for (String format : supportedFormats) {
if (format.equals(suffix)) return true;
}
return false;
}
}四、实战部署与接口测试
4.1 环境准备
4.1.1 基础环境
- JDK 17+(Spring Boot 3.x 要求);
- Maven 3.8+;
- Redis 6.0+;
- FFmpeg(AudioUtils 依赖,需配置环境变量);
- 华为云账号(开通 OBS 服务);
- 阿里通义千问账号(获取 API Key,开通 cosyvoice-v3-plus 权限)。
4.1.2 华为 OBS 配置
- 登录华为云控制台,创建 OBS Bucket(建议选择 "公有读、私有写" 权限);
- 获取 AccessKey/SecretKey(IAM 用户);
- 记录 Bucket 的 Endpoint(地域节点,如
obs.cn-north-4.myhuaweicloud.com)。
4.1.3 通义千问 API Key 获取
- 登录通义千问控制台(https://dashscope.console.aliyun.com/);
- 进入 "API-KEY 管理",创建并复制 API Key;
- 确保账号已开通 cosyvoice-v3-plus 的调用权限。
4.2 配置文件编写(application.yml)
java
spring:
# Redis配置
redis:
host: 127.0.0.1
port: 6379
password:
database: 0
# 通义千问配置
ai:
dashscope:
api-key: 你的通义API Key
# 音频配置
audio:
clone-voice-path: /data/clone-voice # 合成音频存储路径
# 华为OBS配置
obs:
endpoint: 你的OBS Endpoint
access-key: 你的OBS AccessKey
secret-key: 你的OBS SecretKey
bucket-name: 你的OBS Bucket名称4.3 依赖引入(pom.xml)
java
<dependency>
<groupId>com.huaweicloud</groupId>
<artifactId>esdk-obs-java-bundle</artifactId>
<version>3.25.10</version>
</dependency>4.4 接口测试(Postman)
1. 音色克隆(OBS)
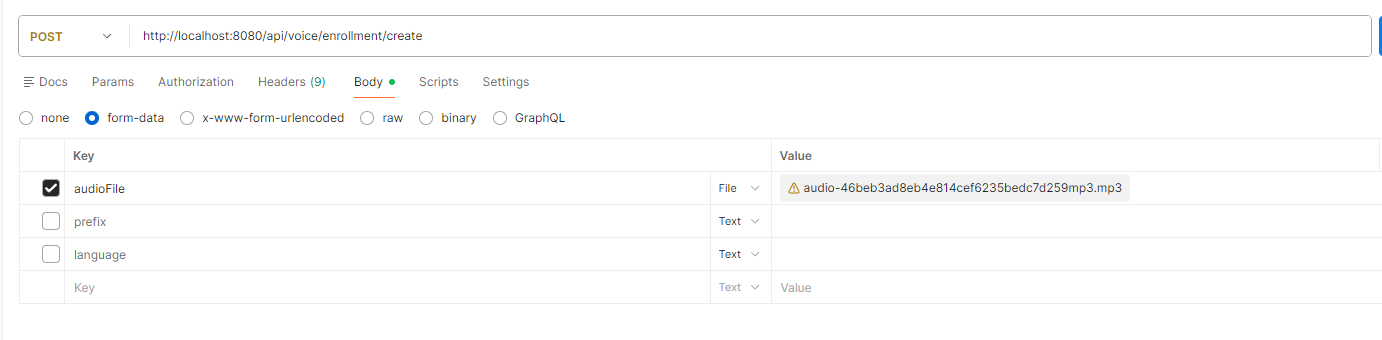
响应

2. 音色克隆完之后,复制克隆好的id进行复刻
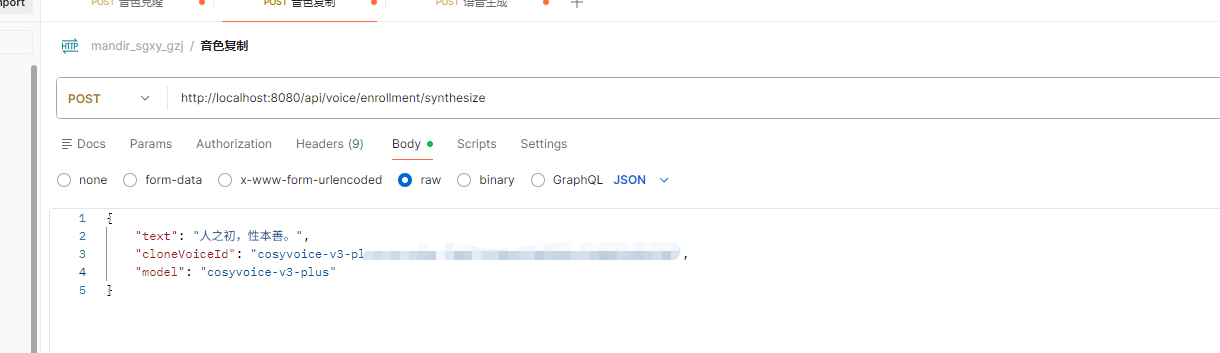
响应

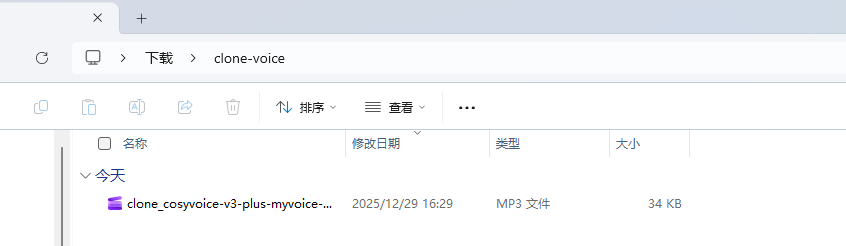
生成的文件:
END
如果觉得这份修改实用、总结清晰,别忘了动动小手点个赞👍,再关注一下呀~ 后续还会分享更多 AI 接口封装、代码优化的干货技巧,一起解锁更多好用的功能,少踩坑多提效!🥰 你的支持就是我更新的最大动力,咱们下次分享再见呀~🌟