搜索基于深度学习的图像修复的文章主要是一些会议文章,而且像CVPR这一类的计算机视觉顶级会议偏多,其次就是ACMMM等杂志每年基本上会出一篇比较经典的论文。接下来这个部分我先将文章进行分类,主要分为仿真文献、精读文献、略读文献三种,具体收集结果见表
|------|--------------------------------------------------------------------------------|--------|----|
| 年份 | 论文名字 | 来源 | 类别 |
| 2016 | 1Context Encoders:Feature Learning by Inpainting | CVPR | 精读 |
| 2017 | 2Globally and Locally Consistent Image Completion | ACMMM | 仿真 |
| 2017 | 3Generative Face Completion | CVPR | 略读 |
| 2017 | 4High-Resolution Image Inpainting using Multi-Scale Neural Patch Synthesis | CVPR | 精读 |
| 2017 | 5Semantic Image Inpainting with Deep Generative Models | CVPR | 仿真 |
| 2017 | 6On-Demand Learning for Deep Image Restoration | ICCV | 略读 |
| 2018 | 7Generative Image Inpainting with Contextual Attention | CVPR | 精读 |
| 2018 | 8Contextual-Based Image Inpainting_ Infer, Match, and Translate | ECCV | 略读 |
| 2018 | 9Shift-Net Image Inpainting via Deep Feature Arrangement | ECCV | 仿真 |
| 2018 | 10ACMMM Semantic Image Inpainting with Progressive Generative Networks | ACMMM | 精读 |
| 2018 | 11Eye In-Painting with Exenplar Generative Adversarial Networks | CVPR | 精读 |
| 2018 | 12Image Inpainting for Irregular Holes Using partial convolutions | ECCV | 仿真 |
| 2018 | 13Deep Image Pirior | CVPR | 略读 |
| ||||
| 2018 | 14Free-Form Image Inpainting with Gated Convolution | CVPR未中 | |
| 2018 | 15Deep Structured Energy-Based Image Inpainting. | ICPR | |
|------|-----------------------------------------------------------------------------------------------------|--------|---|
| 2019 | 16CISI-net_ Explicit Latent Content Inference and Imitated Style Rendering for Image Inpainting | AAAI | |
| 2019 | 17Coherent Semantic Attention for Image Inpainting | CVPR | |
| 2019 | 18Coordinate-based Texture Inpainting for Pose-Guided Human Image Generation | CVPR | |
| 2019 | 19Learning Pyramid-Context Encoder Network for High-Quality Image Inpainting | CVPR | |
| 2019 | 20PEPSI:Fast Image Inpainting with Parallel Decoding Network | CVPR | |
| 2019 | 19Foreground-aware Image Inpainting | CVPR | |
| 2019 | 20Pluralistic Image Completion | CVPR | |
| 2019 | 21Privacy Protectin in Street-View Panoramas using Depth and Multi-View Imagery | CVPR | |
| 2019 | 22PEPSI++:Fast and Lightweight Network for Image Inpainting | CVPR未中 | |
| 2019 | 23Generative Image Inpainting with Submanifold Alignment | IJCAI | |
| 2019 | 24MUSICAL:Multi-Scale Image Contextual Attention Learning for Inpainting | IJCAI | |
一、精读文献
1.1文献①
文献①是基于深度学习的图像修复的开山之作,首次提出采用卷积自编码器的方式进行图像修复,也是实现了从原先用传统方法对小区域缺损的修复到如今的对大区域语义区域的飞跃。
解决的问题或贡献
使用神经网络对缺损图片进行特征提取,并以缺损区域周围的完好区域作为条件,填补缺失的语义内容。由于是第一篇文章,所以其提出的解决的问题也是最基本的语义修复的任务。
网络结构的创新之处
早在2006年Hinton等人在Science上发表的一篇文章26就初步提到了自编码器的概念。文章中设计的这种图像到图像的网络结构就是在自编码器基础上演化而形成的上下文编码器,这种模型广泛应用于风格迁移、超分辨重建、图像修复这类输入、输出都是图片的任务。作者就是在卷积自编码的基础上借鉴了GAN的思想,在后面加上了一个判决器,从而判断破损区域生成的纹理、内容是否像一张真实的图片。其网络结构如下图所示。
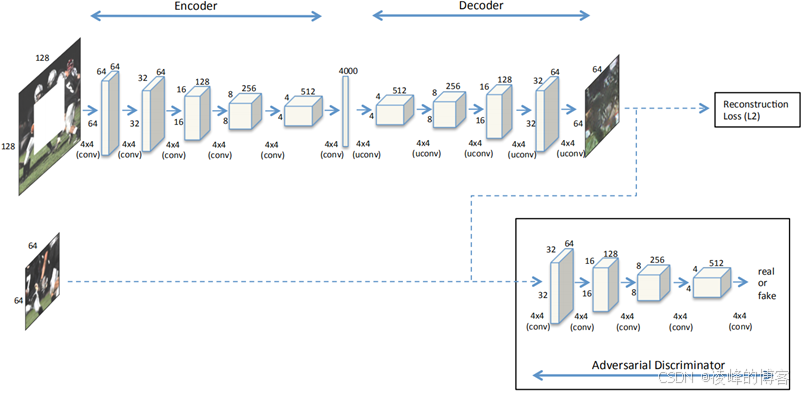
所以本文的损失函数有两个:重建损失、对抗损失。重建损失就是通过计算真实图片和修复结果缺损区域像素上的误差,对抗损失就是类似于GAN中设计的那种损失函数。两种损失的表达式如下
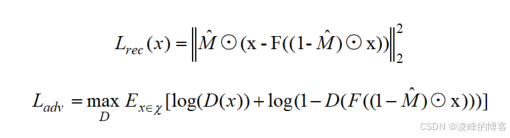
实验部分的创新之处
因为这篇文章是第一篇进行大区域语义修复的文章,所以实验部分就无所谓创新之处了,在这里介绍一下文章中用到的几种缺损类型,也即掩膜类型,后文提到的掩膜区域可以等价为缺损区域。
语义修复中比较重要的一个概念就是掩膜,掩膜是一张与输入图片大小相同的二进制图片,每个像素上只有0或1两种值,是用来形成缺损图像并在修复过程记录图片的缺损区域的。在本文中作者为图像加上了以下几种掩膜:1.中心区域掩膜;2.随机位置方块掩膜;3.随机区域掩膜。掩膜的图以及加上掩膜之后的效果图如图4-1所示,值得一提的是,这篇文章的随机区域掩膜比较有意思,是通过从其他图像上分割出的一个目标的形状,通过观察可以发现图4-1(c)中出现的掩膜的形状就是一个婴儿的形状。

存在的问题
这篇文章虽然确实比原来的传统修复方法效果好了不少,但是他的修复结果在肉眼观测下并不是很好,经过长时间学习后仍然存在如图a这样的严重模糊纹理,以及如图(b)这样的严重伪影。

虽然文献①的思想在当时很超前,但是从现在的眼光来看,首先他只考虑了像素上的误差,而没有从感知损失的角度来引导图像进行修复;其次,他将缺损区域与周围完好区域无差别的放入网络进行修复,这种方式很明显会给结果造成很大的干扰;其网络结构过于简单,只是从内容的角度进行修复,而没有在意细节纹理,这样就会造成中间的纹理有很严重的模糊现象,缺损区域与周围区域在语义上的衔接也不够紧密。
1.2文献④
文献④是一篇比较重要的文献,它首次提出采用感知损失加入网络进行训练,除了上文提到的自编码器,他还采用了其他的网络结构来为修复任务构建损失,也为后面的多层网络结构打下了基础,是这两个阶段的一个桥梁。此外,它还提出了通过上采样进行高分辨率图像修复任务。这篇文章刚开始阅读时比较难理解,直到后面阅读其他文章时,多次使用这种直接在特征图上操作的方法,反过来理解才比较容易。
解决的问题或贡献
首先文章分析了前面的的一些研究成果,说明他们因为网络限制或者因为网络训练上的困难,只能实现一些低分率的图像修复,然而面临高分辨率图像修复任务时就会出现纹理细节修复效果差等问题。所以文章做出了以下贡献:
1.利用卷积神经网络对全局内容约束和局部纹理约束进行建模,提出了一种联合优化框架。
2.进一步介绍了一种基于联合优化框架的高分辨率图像修复的多尺度神经补丁综合算法。
3.从神经网络中间层提取的特征可以用来合成真实感的图像内容和纹理,也可以用来风格迁移。
网络结构的创新
本文在网络结构上创新相比文献②是十分大的,本文构建了两个网络:内容网络、纹理网络分别对修复任务进行不同层面上的优化。内容网络与文献①、②的上下文自编码器的结构类似。主要就是后面的纹理修复网络,采用的是使用ImageNet预训练好并且固定了参数的模型,和上面的编码器网络紧密衔接,编码器的输出即为VGG16的输入。文章采用一种多尺度的方法进行高分辨率图像的修复,就是通过N个尺度不断通过损失找到最优解,然后再进行迭代的方式进行的。其表达式如下:
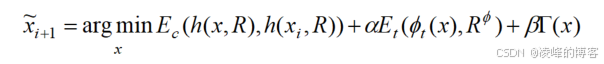
我们提取了VGG16第三层与第四层的特征图用来计算纹理损失,简而言之,让特征图的缺损区域和周围的完好区域不断接近,其表达式如下
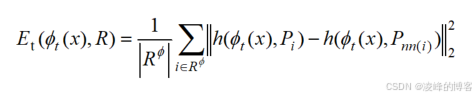
此外,文章还提出一种全变分损失来让破损区域与周围区域的语义连接性更加好。所以文中一共会有三种损失,即内容损失、纹理损失和全变分损失,这就是所谓的联合优化。文章的网络结构如图所示。
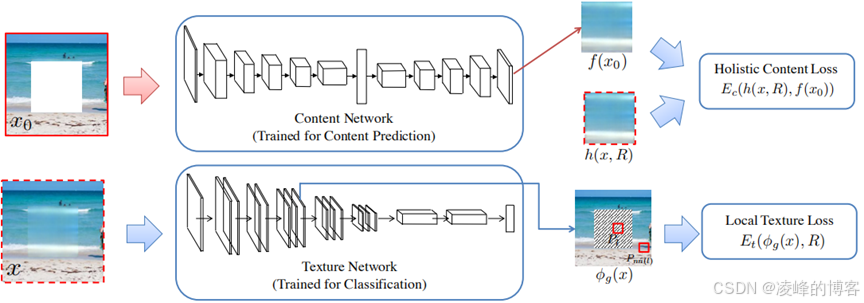
实验部分的创新
针对实验部分没有太多创新,而且受这篇文章网络特点的限制,只对矩形区域的缺损进行了修复,但是可以支持分辨率更高的图像进行修复。
存在的问题
这篇文章的问题也存在于它的创新点中,在它在纹理网络中的特征层计算缺损区域与周围正常区域的损失时,它在一张图像中只利用了这张图像的特征图的完好区域,而没有在整个数据集中去寻找其他特征图的完好区域。在一些复杂的场景中修复结果仍然存在较大的伪影,而且因为联合优化与多尺度的迭代,网络的速度很慢。
1.3文献⑦
文献⑦是首次采用粗到精网络结构来进行图像修复,即采用两个上下文卷积网络来进行图像修复的。此外,本文还提出一种上下文注意力机制,用来为缺损区域找到对其修复最有用的补丁。
解决的问题或贡献
- 提出了一种新颖的语境关注层,以便在远处的空间位置明确地参与相关的特征片。
- 介绍了几种技术,包括修复网络增强,全局和局部WGAN以及空间折扣重建损失,以提高基于当前最先进的生成修复网络的训练稳定性和速度。因此,能够在一周而不是两个月内训练网络。
- 统一的前馈生成网络在各种挑战性数据集上实现了高质量的修复效果,包括CelebA人脸数据集,CelebA-HQ人脸数据集,DTD纹理数据集,ImageNet和Place2。
网络结构的创新部分
本文首先提出了一个所谓的提升版的生成修复网络,这个网络相比于文献②修复效果就有不少的提升,随后在精细修复部分,作者又引入了上下文注意力机制,这就能够对每个对应于卷积核的感受野计算出和它最相近的完好区域块,这样就能让修复的图像和周围的语义连接更加紧密了。
实验创新
在实验上没有太多创新,特别是受注意力机制的限制,不能实现对随机缺损的修复。
存在问题
这个在展示的修复结果中已经比较好了,但是可以发现他处理的图片都是分辨率比较低的,作者也提到将会在接下来的文章中将其改进为可以进行高分率图像修复。
1.4文献⑩
这篇文章将课程学习的方式引入了图形修复中,主要就是针对大区域缺损的修复任务,他采用四层卷积自编码器,并将每一层有机的进行连接,实现由外之内逐层的修复。
解决的问题与贡献
- 提出了一种渐进的语义图像修复框架,一种端到端神经网络,与课程学习策略相关联,可以显著减少缺失图像区域边界的非自然转换。
- 与以往基于GAN的图像修复算法不同,PGN的判别器是对生成样本的整个区域进行判别,以保持结构和纹理的一致性。
- 在PGN中引入LSTM体系结构来串所有的子任务来控制PGN中的信息流。它能够避免信息干扰,提高图像的画质。
网络结构的创新
首先是加大了卷积编码器的阶数,达到了四阶。然后文中引入了长短期记忆网络,可以将前一阶段学习到的内容可以通过LSTM传递到下一阶。
存在的问题
存在的问题很明显就是只能对一整块完整的区域进行修复。
1.5文献11
文献11和文献⑤联系是十分紧密的,也是以GAN为基本框架的,他解决的问题也是针对于⑤在文末提出的修复结果中虽然生成的人脸比较真实,但是和原图相对来说差别比较大。有时候人脸修复的时候,如果和原先的人差别很大,那在实际应用中一定价值不大。所以文中提出了自己的解决方法。
解决的问题或贡献
将Exemplar GANs引入了图像修复,它可以利用样本信息产生高质量、个性化的绘画结果。使用了样本信息,以区域的参考图像的形式进行修复,或者使用描述该对象的感知编码。
网络结构的创新
这篇文章最重要的一点就是将感知损失引入了基于GAN的图像修复,设计了两个编码器,专门用来计算图片的感知编码,从而计算感知损失。其次就是使用图像对的方式,通过编码器也实现了待修复人物的个性化特征的提取,从而在修复的时候能够保持图像的个性化特征,其网络结构如图所示:
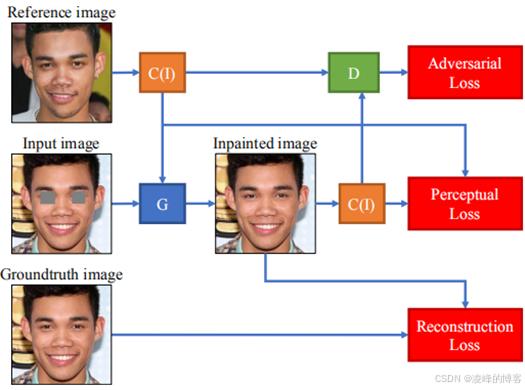
实验的创新之处
这个网络专门收集了一份特殊的人脸数据集,里面有17000人的100000张照片,其中不同人的每个人至少三张在不同时间以不同姿势拍摄的照片,这样就能够通过其中任意一张完好图片修复其他两张图片了。在实验中作者们详细对比了五官(特别是眼睛)的修复结果。
二、仿真文献
2.1文献②
文献②的是我仿真的第一篇文章,其实当时本来打算仿真文献①的,恰好在这之前读到了这篇文章,发现这篇文章只是在文献①的基础上在对抗损失部分进行了改进,但是结果却提升了不少。其改进的部分就是添加了一个全局对抗损失,除了在判断生成的缺损区域的真实与否,还能判断其在语义的连接性上是否比较好。
解决的问题或贡献
1.实现了可以完成任意缺失区域的高性能网络模型;
2.实现了用于图像完成的全局和局部一致的对抗训练方法;
3.将文章方法应用于特定的数据集以完成更具挑战性的图像的结果。
网络结构的创新
就像前面提到的,这篇文章最大的创新点就在于增加了一个对抗损失,即全局对抗损失,除了在判断生成的缺损区域的真实与否,还能判断其在语义的连接性上是否比较好。其次就是将卷积编码器和解码器之间的全连接层替换成了空洞卷积,这样增大的图像的感受野,可以更具破损像素周围更大区域来进行特征的学习。具体的示意图如图所示:
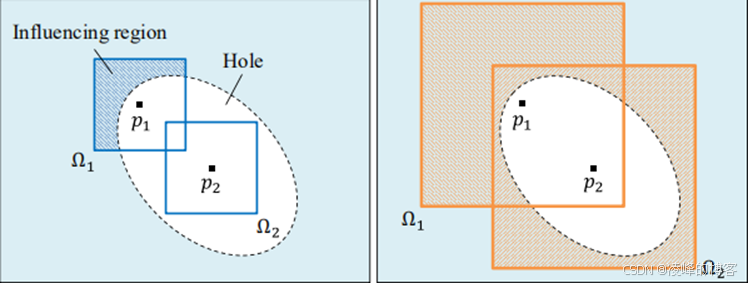
最后,文章还提到了一种避免伪影的方法,就是把数据集中所有像素的平均值拿来先填充空洞,这是一种价格高昂的预处理过程,但是最后的结果看来效果确实不错。
实验创新之处
文献②相比于文献①的实验的多样性确实有提升,文献①中提到了一个重要的数据集就是巴黎街景数据集,但是作者没有对外公开,文献②采用的是Place2数据集和人脸数据集,这两个都是图像修复最常用的数据集,在掩膜方面基本上还是那三种,但是随后的随机区域掩膜就是采用那种随手画出来的掩膜。最终各种修复结果如下,看上去真的很不错,特别是针对人脸修复的时候。可能是图片分辨率的问题,我后面看到的好多文章修复结果看上去甚至不如这个。文章还采用一种新的主观观测指标,即自然度(naturalness)进行修复性能的评价。
存在的问题
这篇文章存在的很严重的一个问题就是训练时间过长,文中采用四片K80GPU跑了两个月才跑出来的结果。所以在后面的仿真过程中我只是为了学习这种网络结构进行仿真的。其次,在对于大区域掩膜的时候修复效果就不是很好,最后对于那些出现在边界上的缺损,由于只能从另外三个甚至更少的方向学习周围正常的内容,所以修复效果也不是很好。

文献②修复结果
仿真中出现的问题
由于这些17年文章年代比较久远,作者给出的源码有的是基于torch的,而现在这种框架已经逐渐过时了。最后参考的是一个基于keras的文献①程序,自己修改了网络结构,主要就是针对文中提出的改变对抗损失重新进行了一部分编程,当然中间出现了很多程序上的bug,最后得以把代码跑通。我是用的是celeba数据集,只采用了一种掩膜就是保持掩膜区域大小占整张图片面积的1/10-1/5生成随机位置的矩形掩膜,最后我把epoch设定为100,图片也只用了50000张图片,最后生成出来的图像效果只在平滑区域修复效果比较好,五官细节就不能实现完整的修复了,这主要还是训练时间过短的问题。具体结果图如下:

我们可以看到当遮挡区域在五官等纹理十分明显的位置时就会出现明显的伪影,在一些平滑区域像额头等区域时修复效果尚可。由于没有进行完整的训练(用实验室1080Ti显卡训练了26个小时左右),所以对其进行评价并没太大意义。但是此次仿真让我对于这种编码器的结构有了比较清晰的认识,可以比较熟练地对这种结构进行修改。
2.2 文献⑤
以上这种方法都存在一个问题:在对不同破损条件下的图像修复任务之间的转变不够灵活。即当修复任务的破损区域的形状或者大小发生改变时,就需要重新针对新的修复任务进行训练,这在实际应用中常常是不被允许的。文献⑤中,作者提出了一种语义图像修复的新方法。在文章中作者认为图像修复就是一个有条件限制的图像生成问题,他训练了一个有一定深度的生成对抗网络,致力于寻找一个最接近潜在空间的图像的受损图像的编码。然后利用该编码来使用生成器重建图像。定义"最近"的方法是采用加权上下文损失来接近输入图像的破损区域,以及先验损失来惩罚不真实的图像。与CE等上述方法相比,该方法的主要优点之一是它不需要训练掩码,在推理过程中可以应用于任意结构的缺失区域。
解决的问题或贡献
提出了一种语义图像修复的新方法。把语义修复当做一个受限的图像生成问题。与文献①等方法相比,该方法的主要优点之一是它不需要训练掩码,在推理过程中可以应用于任意结构的缺失区域,在具有挑战性的语义修复任务中,该方法可以获得比现有技术更逼真的图像。
网络结构的创新
为了填补图片上的缺失区域,这篇文章采用的方法就是先采用未破损图片训练生成器G和判决器D。经过一定量的训练之后,G就能采用符合高斯分布Pz的随机点z模仿输入样本分布Pdata来生成一些和输入样本相似的图片。我们假设生成器G已经学习到了所有符合Pdata的图像的特征,并产生了对应的编码流形z,可以通过生成器G直接产生图片。那么现在有一张分布并不服从Pdata的图像,那么他的特征并不在我们所学习到的编码流形z当中。所以我们接下来的目的是让网络在一定的约束条件下,学习到和破损图像最接近的编码流形Z^,下图中我们对整个网络框架进行了描述,并采用了t-SNE27对后面这个学习过程进行了可视化操作,我们可以看到,生成的图像随着迭代次数的增加,越来越接近输入的破损图像。最终我们得到Z^之后,直接通过生成器G就能产生图片的缺失区域了。
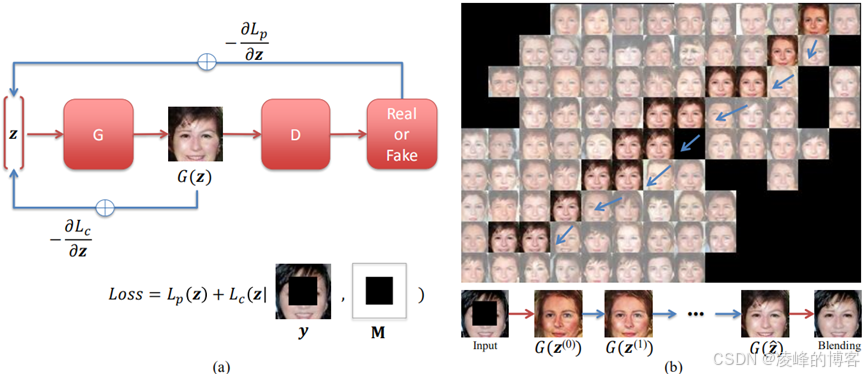
实验创新之处
本文的实验过程中采用的掩膜就比较多了,一共使用了四类掩膜,如下图(a)(b)所示的方块掩膜,这一类掩膜在以往基于深度学习的图像修复方法中使用最为频繁的一种。主要作用是检查网络对图片语义的学习情况和修复的细节,观察方块中修复的像素与周边像素的连贯性,以及方块中修复的细节情况。第二类是随机模式掩膜,这种掩膜是采用形态学操作来形成的,采用一个椭圆结构元素,然后不断在图片上随机选择像素并用结构元素对其进行膨胀操作,直到大小达到指定面积为止。最后我们采用闭操作对图片上的单个像素缺损进行去除,从而达到生成的缺损区域为一个整体,如图(c)所示。这一类掩膜更符合日常图像修复的需要,因为日常面临的图像修复任务面对的都是不规则的缺损。第三类掩膜是随机点掩膜,即在图片上随机选择像素,达到预先设置的面积,然后对这些区域加上掩膜如图(d)所示。这类掩膜主要是为了凸显本文算法的优势,说明面临大面积随机点缺失时,修复效果依然不错。第四类是边缘掩膜,在图像上水平或者垂直方向的边缘添加面积小于图像一半面积的掩膜,如图(e)。这类掩膜主要是针对人脸数据集,可以观察对特定五官的修复效果,以及观察修复结果的五官是否对称。

作者在文章中也指出现在的语义修复任务已经不同于原先针对小区域的修复任务,所以PSNR这些对于最后修复结果的评价并不十分客观,作者还举出例子证明了为什么在图像整体效果看上去比文献①好的情况下,PSNR反而会更低。
存在的问题
由于过于依赖DCGAN,只能在一些单一的数据集上才能收敛,如果切换到了复杂场景、语义的图片,修复效果就不是那么令人满意。
仿真遇到的问题
仿真过程中遇到的比较大的问题就是掩膜的设计,特别是随机模式掩膜,最后的实现是通过形态学中的膨胀操作实现的,这次仿真让我学会了很多掩膜的设计方法,为后面几篇文章的仿真打下了基础,最后仿真出来的结果也是相比上次针对文献②的仿真要好很多。如图所示。

4.2.3文献⑨
文献⑨是将一种我们比较熟悉的结构引入了自编码器,那就是U-net中的跳跃连接,此外他在一层上使用了他独创的shift操作和shift-net。
解决的问题或贡献
首先作者提出了目前修复网络的问题:在大多数现有的方法(例如,上下文编码器)中,通过将周围的卷积特征通过完全连接的层传播来预测丢失的部分,其意图产生语义貌似可信但模糊的结果。
- 引入了U-net跳跃连接,开发了一种新的shift网络体系结构,以有效地将基于CNN和基于示例的图像修复结合起来。
- 引入指导损失、重建损失和对抗损失来训练我们的Shift-net,即使部署shift操作,所有的网络参数也可以实现端到端的方式学习。
- 与前面的文章相比,Shift-net达到了目前最好的结果,并且在生成精细详细的纹理和视觉上合理的结果方面表现良好。
网络结构的创新
在基于范例的修补中,通常假定缺失的部分是已知区域内像素/补丁的空间重排。在未知区域的每个像素或者补丁y都有对应的迁移向量uy,我们可以通过使用I_(v+u_v)来修复I_v,就是这样的思想。但与之不同的又有以下几点:
- 虽然基于示例的修复是在像素/补丁上进行操作的,但shift操作是在通过了训练数据中端对端学习的深度编码器特征区域进行操作的。
- 在基于范例的修复中,通过求解一个优化问题或按特定的顺序得到移位向量。而shift操作中所有的shift向量都可以并行计算。
- 对于基于示例的修复,修补处理命令和全局图像相干性都不足以保存复杂的结构和语义。相比之下,shift更容易捕获全局语义。
- shift操作不是将已知区域的像素进行移位然后直接得到结果,而是需要和编解码器的特征层结合起来作为L-l+1层的输入。而且我们的Shift-Net可以端对端学习。
仿真过程遇到的问题
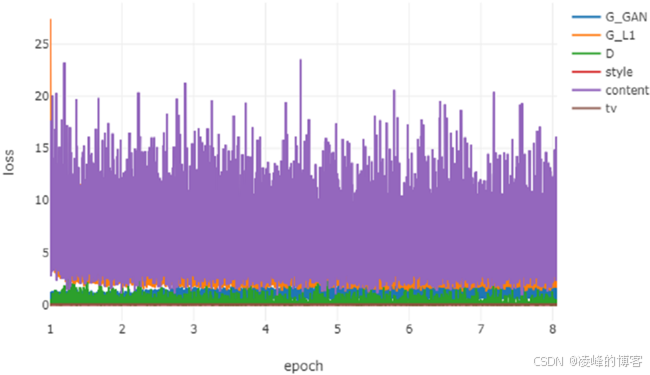
这个网络结构是用pytorch进行搭建的,在训练过程中还使用visdom这个视觉化工具,这个过程中主要难点就是理解文中的shift操作,看文章一直都不是很理解这个操作是怎么实现的,看了代码之后才慢慢理解shift向量是怎么回事。这个代码运行时间还是挺长的,跑了大概一个星期左右,是目前运行时间最长的代码。最后这是跑了十个批次的修复的代码,可以发现脸部的大致轮廓修复的还是不错的,但是像牙齿这样比较细节的区域修复结果就不是很能让人满意,而且通过visdom的数据表现出的是,其收敛速度很快,就是在前几次迭代的时候就已经达到了比较好的结果,但是达不到论文的效果。可以通过观察visdom读数我们也能看出损失在前几个批次中就减小到了一个比较小的数值,在后面的训练过程中就一直稳定在一个数值上下波动。这应该还是网络存在一定问题,但后面由于电脑的问题一直都没有查清,希望能在之后把这个结构的原理弄的更透彻之后再来解决这个问题。

2.4文献12
文献12是目前正在仿真的一篇文献,这篇文章提出了一种全新的卷积方式,用来处理任意缺损图片,随着卷积的进行,可以发现掩膜不断减小,缺损区域被慢慢填补,这种卷积非常适合图像修复,NVIDIA的展示视频中,左侧任意画上缺损区域,右侧都能实行比较完美的修复。
解决的问题与贡献
- 使用部分卷积与自动掩码更新步骤,以实现目前效果最好的图像修复。
- 虽然以前的工作未能在具有典型卷积的U-net中用跳跃链接获得良好的修复效果,但我们证明用部分卷积和掩码更新代替卷积层可以达到目前效果最好的修复效果。
- 第一个证明训练图像修复模型对不规则形状的孔的有效性。
- 提出了一个大型的不规则掩模数据集,将发布给公众,以促进今后在培训和评估修复模型方面的进展。
网络结构的创新
本文的网络结构依然是采用U-net的网络结构。但是将所有的卷积层全部替换成了部分卷积,就是只利用完好的区域来进行卷积,我们可以回忆一下原先的修复方法,以前都是将一整张待修复的图片喂入网络中,然后通过各种损失与机制来引导整个网络产生更好的参数,从而产生更好的修复结果。注意这个过程中破损区域也是随着图片的卷积一起进行卷积运算的,但就是这些破损区域中有着与周围区域不同的语义内容,如果参与进行计算的话会导致最终生成的图像中出现"噪声"。所以作者们提出了一种新的卷积运算,即:只用完好的区域进行计算卷积运算,具体操作就是随着图像喂入网络的还有一张二进制掩膜,大小和图像一致,上面破损区域值为0,完好区域的值为1,每次进行卷积的时候,网络都会使用掩膜将感受野中的完好区域挑出来进行运算,最后再根据有效区域的大小除以一个适当的缩放因子。在每一层卷积计算结束之后,对二进制掩膜进行更新,这样缺损区域就会越来越小,从而达到了图像修复的效果。
实验的创新
这篇文章的实验创新主要是在主观指标方面,作者将图片放在网上进行了一项测试,就是把用其他方法修复的图片、本文方法修复的图片以及原图放在一块,让人们区分哪个是原图。测试也分两种,一种是有时间限制的,一种是没有时间限制的。有时间限制要求被测试者在4秒钟选出自己认为质量最好的图片,这就检验了图片给人的第一主观印象是否真实。没有时间限制的就会给被测试者充分的时间直到选出自己认为质量最好的图片为止,这就要求修复的纹理细节要足够真实。最后作者还画出了以下的图像来反映实验结果,十分直观。
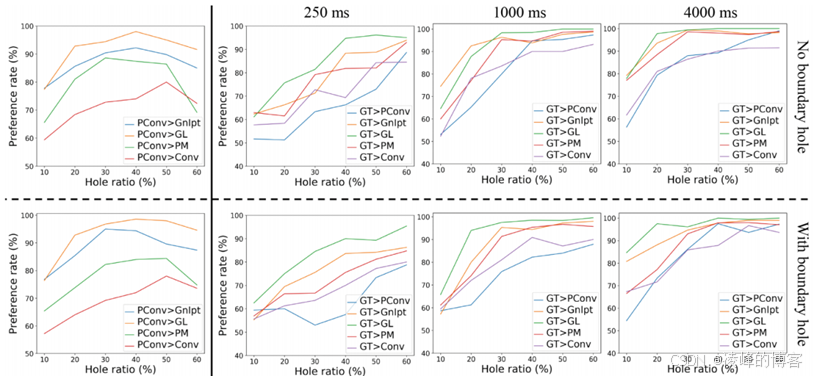
存在的问题
在进行一些稀疏结构的修复时,效果不是太好,比如:比较密集的铁栏杆。和其他方法一样,这种修复方法会在修复面积最大的缺损部位时有一定困难。
仿真过程中遇到的问题
这篇文章的作者没有给出文中提到的随机掩膜的数据集,所以我只能自己使用OpenCV来实现对掩膜的生成。比较难理解的地方就是部分卷积的实现过程以及掩膜的更新过程,按照文章提到的掩膜的更新也是通过卷积来进行实现的。所以我做实验对掩膜进行更新,效果如图

可以看到掩膜确实是随着部分卷积的进行不断缩小。随后我进行单张图片的训练,训练批次设定为100,由于电脑显存的限制,batch_size只能设定为1,最后训练出来的结果如下图所示(分别选取的是epoch为1、5、10时的结果)。通过观察可以发现图像一开始是比较模糊的,随着修复的进行越来越清晰。一开始完全是模糊的主要是因为整张图像完全是由网络生成的,也就是网络生成的不仅仅是缺损区域。这样看来整体思路应该是没有错的,目前正在采用人脸数据集来对整个网络进行训练。

三、参考文献
1 M. V. Afonso, J. M. Bioucas-Dias, and M. A. Figueiredo. An augmented lagrangian approach to the constrained optimization formulation of imaging inverse problems. IEEE TIP, 2011.
2 J. Shen and T. F. Chan. Mathematical models for local nontexture inpaintings. SIAM Journal on Applied Mathematics, 2002.
3 K. He and J. Sun. Statistics of patch offsets for image completion. In ECCV. 2012.
4 J.-B. Huang, S. B. Kang, N. Ahuja, and J. Kopf. Image completion using planar structure guidance. ACM TOG, 2014.
5 Y. Hu, D. Zhang, J. Ye, X. Li, and X. He. Fast and accurate matrix completion via truncated nuclear norm regularization. IEEE PAMI, 2013.
6 C. Barnes, E. Shechtman, A. Finkelstein, and D. Goldman. PatchMatch: a randomized correspondence algorithm for structural image editing ACM TOG, 2009.
7 J. Hays and A. A. Efros. Scene completion using millions of photographs. ACM TOG, 2007.
8 O. Whyte, J. Sivic, and A. Zisserman. Get out of my picture! internet-based inpainting In BMVC, 2009.
9 Lecun Y,Bottou L,Bengio Y,et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE,1998,86( 11) : 2278-2324. [DOI: 10. 1109 /5. 726791]
10 Gatys L A,Ecker A S,Bethge M. Texture synthesis using convolutional neural networks[C]/ / Proceedings of the 28th International Conference on Neural Information Processing Systems.Montreal,Canada: ACM,2015: 262-270.
11 Convolutional Neural Networks."2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 2414--2423.
12 Goodfellow, Ian, et al. "Generative Adversarial Nets."Advances in Neural Information Processing Systems 27, 2014, pp. 2672--2680.
13 Pathak, Deepak, et al. "Context Encoders: Feature Learning by Inpainting."2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 2536--2544.
14 Iizuka S , Simo-Serra E , Ishikawa H . Globally and locally consistent image completionJ. ACM Transactions on Graphics, 2017, 36(4):1-14.
15 Li, Yijun, et al. "Generative Face Completion." 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 5892--5900.
16 Johnson, Justin, et al. "Perceptual Losses for Real-Time Style Transfer and Super-Resolution."European Conference on Computer Vision (ECCV), 2016, pp. 694--711.
17 Yang, Chao, et al. "High-Resolution Image Inpainting Using Multi-Scale Neural Patch Synthesis." 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 4076--4084.
18 Yu, Jiahui, et al. "Generative Image Inpainting with Contextual Attention." 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018, pp. 5505--5514.
19 Song, Yuhang, et al. "Contextual-Based Image Inpainting: Infer, Match, and Translate." Proceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 3--18.
20 Zhang, Haoran, et al. "Semantic Image Inpainting with Progressive Generative Networks."Proceedings of the 26th ACM International Conference on Multimedia, 2018, pp. 1939--1947.
21 Yeh, Raymond A., et al. "Semantic Image Inpainting with Deep Generative Models."2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 6882--6890.
22 Dolhansky, Brian, and Cristian Canton Ferrer. "Eye In-Painting with Exemplar Generative Adversarial Networks." 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018, pp. 7902--7911.
23 Liu, Guilin, et al. "Image Inpainting for Irregular Holes Using Partial Convolutions." Proceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 89--105.
24 Ronneberger, Olaf, et al. "U-Net: Convolutional Networks for Biomedical Image Segmentation." International Conference on Medical Image Computing and Computer-Assisted Intervention, 2015, pp. 234--241.
25 Lempitsky, Victor, et al. "Deep Image Prior."2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018, pp. 9446--9454.
26 G. E. Hinton and R. R. Salakhutdinov. Reducing the dimensionality of data with neural networks. Science, 2006.
27 L. v. d. Maaten and G. Hinton. Visualizing data using t-SNE. Journal of Machine Learning Research, 2008.