近年来,随着深度学习的发展,基于神经网络的语言模型取得了显著进展。以GPT 为代表的大规模神经网络语言模型,或简称大语言模型(LLM),展现出了强大的语言理解与生成能力。这些模型的核心任务是通过上下文信息预测下一个词,从而生成自然流畅的句子。
大语言模型之所以强大,主要得益于它们具备超强的上下文建模能力。传统的 N 元文法模型通常只能考虑前几个词(一般不超过 5 个)的上下文信息,而基于神经网络的模型可以处理极长的上下文信息。例如,第一代 GPT-1 模型可以处理 512 个标记(Token)的上下文,而最新的 GPT-4 模型可以处理长达 12.8 万个标记的上下文。标记是文本表示的最小单位,一个英文单词平均包含 1.2-1.5 个 Token。
这种强大的上下文处理能力归功于一种名为 Transformer 的网络结构。Transformer 的核心是自注意力机制,它允许模型在生成下一个词时回顾并整合所有前面已经生成的单词,从而使生成内容连贯、一致。如图 31.4所示,当模型预测第 9 个单词"it"时,它可以通过回顾所有前面的单词来生成下一个词。
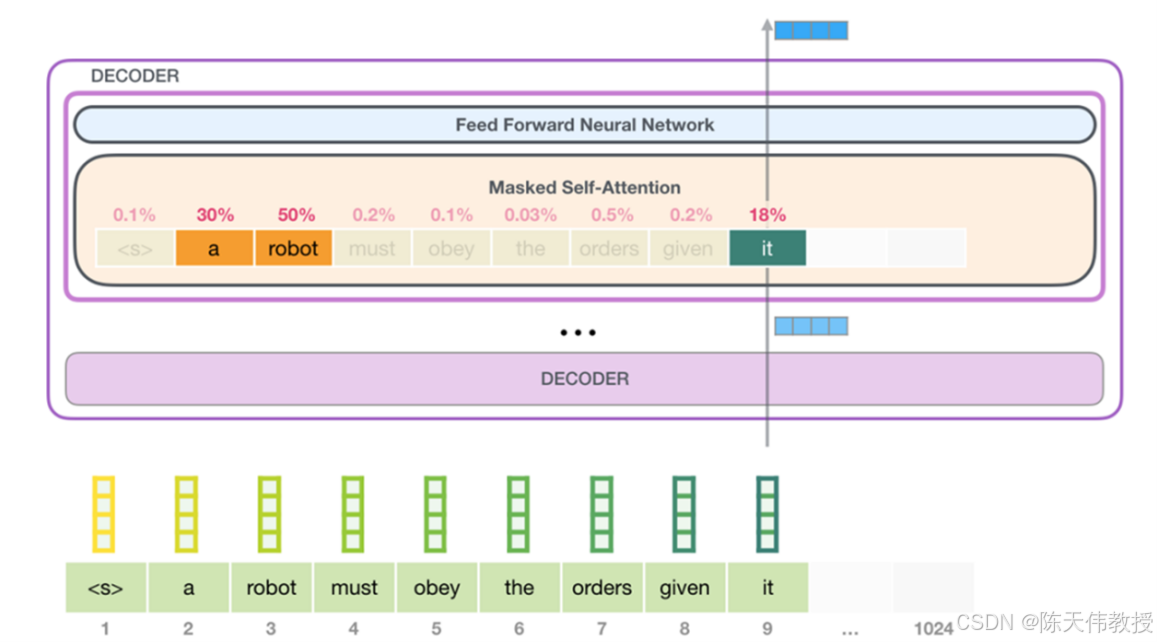
大语言模型的单词预测示意图。图片来源:Jay Alammar's blog