1.安装
js
tar -xf apache-hive-3.1.3-bin.tar.gz -C /opt/software2.配置修改日志存放路径
js
mv hive-log4j2.properties.template hive-log4j2.properties
修改配置如下
property.hive.log.dir=/opt/module/hive/logs3.Hive的JVM堆内存设置
js
新版本的Hive启动的时候,默认申请的JVM堆内存大小为256M,JVM堆内存申请的太小,导致后期开启本地模式,执行复杂的SQL时经常会报错:java.lang.OutOfMemoryError: Java heap space,因此最好提前调整一下HADOOP_HEAPSIZE这个参数。
1.修改$HIVE_HOME/conf下的hive-env.sh.template为hive-env.sh
mv hive-env.sh.template hive-env.sh
2.将hive-env.sh其中的参数 export HADOOP_HEAPSIZE修改为2048,重启Hive。
修改前
# The heap size of the jvm stared by hive shell script can be controlled via:
# export HADOOP_HEAPSIZE=1024
修改后
# The heap size of the jvm stared by hive shell script can be controlled via:
export HADOOP_HEAPSIZE=20484.关闭Hadoop虚拟内存检查
js
在yarn-site.xml中关闭虚拟内存检查(虚拟内存校验,如果已经关闭了,就不需要配了)。
1.修改前记得先停Hadoop
cd /opt/module/hadoop-3.1.3/etc/hadoop
2.添加如下配置
vim yarn-site.xml
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
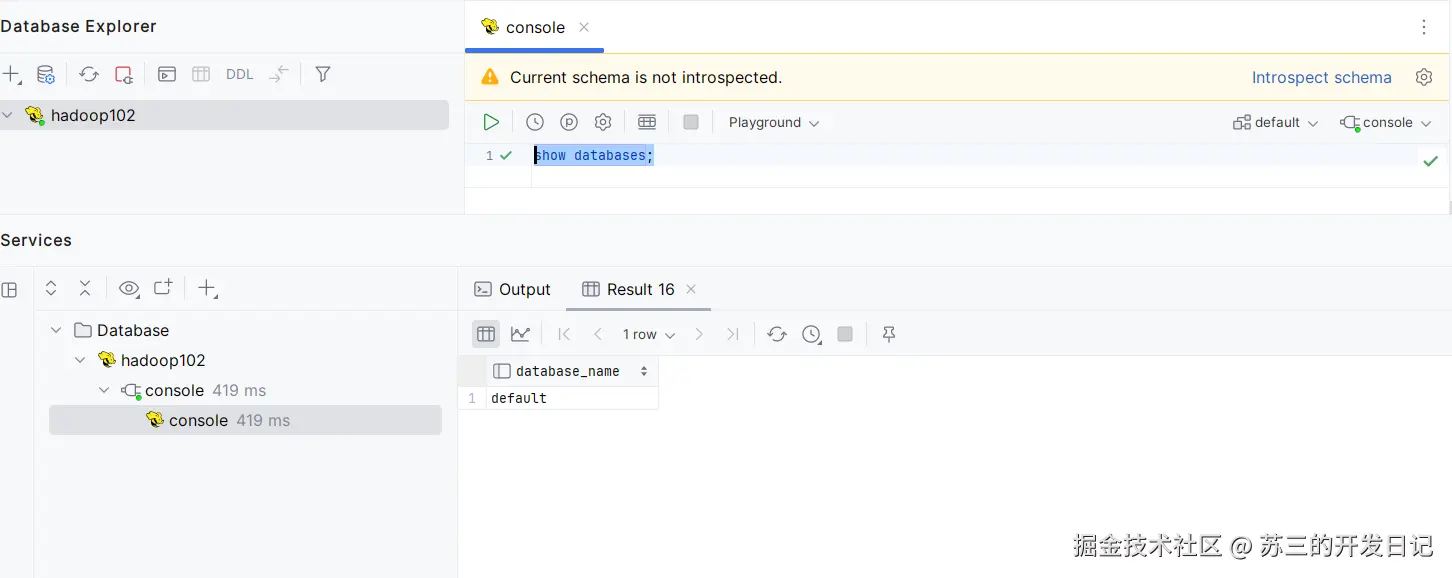
3.修改完后记得分发yarn-site.xml,并重启yarn。5.设置hive可以使用DataGrip工具进行连接
设置hive可以通过datagrip进行连接,需要修改hive-site.xml,hadoop目录下的core-site.xml内容,为了方便hive的管理,使用hiveservices.sh进行管理。
hive目录conf地址下的hive-site.xml
js
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- jdbc连接的URL -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop102:3306/metastore?useSSL=false</value>
</property>
<!-- jdbc连接的Driver-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- jdbc连接的username-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- jdbc连接的password -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>cpc!23#@</value>
</property>
<!-- Hive默认在HDFS的工作目录 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<!-- 指定hiveserver2连接的host -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop102</value>
</property>
<!-- 指定hiveserver2连接的端口号 -->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop102:9083</value>
</property>
<!-- 指定hiveserver2连接的host -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop102</value>
</property>
<!-- 指定hiveserver2连接的端口号 -->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<!--显示字段名称-->
<property>
<name>hive.cli.print.header</name>
<value>true</value>
<description>Whether to print the names of the columns in query output.</description>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
<description>Whether to include the current database in the Hive prompt.</description>
</property>
</configuration>hadoop的core-site.xml
js
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定 NameNode 的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:8020</value>
</property>
<!-- 指定 hadoop 数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<!-- 配置 HDFS 网页登录使用的静态用户为 atguigu -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>atguigu</value>
</property>
<!--配置所有节点的atguigu用户都可作为代理用户-->
<property>
<name>hadoop.proxyuser.atguigu.hosts</name>
<value>*</value>
</property>
<!--配置atguigu用户能够代理的用户组为任意组-->
<property>
<name>hadoop.proxyuser.atguigu.groups</name>
<value>*</value>
</property>
<!--配置atguigu用户能够代理的用户为任意用户-->
<property>
<name>hadoop.proxyuser.atguigu.users</name>
<value>*</value>
</property>
</configuration>存放到hive的bin地址下的hiveservices.sh,注意修改配置执行权限 chmod +x hiveservices.sh
js
#!/bin/bash
HIVE_LOG_DIR=$HIVE_HOME/logs
if [ ! -d $HIVE_LOG_DIR ]
then
mkdir -p $HIVE_LOG_DIR
fi
#检查进程是否运行正常,参数1为进程名,参数2为进程端口
function check_process()
{
pid=$(ps -ef 2>/dev/null | grep -v grep | grep -i $1 | awk '{print $2}')
ppid=$(netstat -nltp 2>/dev/null | grep $2 | awk '{print $7}' | cut -d '/' -f 1)
echo $pid
[[ "$pid" =~ "$ppid" ]] && [ "$ppid" ] && return 0 || return 1
}
function hive_start()
{
metapid=$(check_process HiveMetastore 9083)
cmd="nohup hive --service metastore >$HIVE_LOG_DIR/metastore.log 2>&1 &"
[ -z "$metapid" ] && eval $cmd || echo "Metastroe服务已启动"
server2pid=$(check_process HiveServer2 10000)
cmd="nohup hive --service hiveserver2 >$HIVE_LOG_DIR/hiveServer2.log 2>&1 &"
[ -z "$server2pid" ] && eval $cmd || echo "HiveServer2服务已启动"
}
function hive_stop()
{
metapid=$(check_process HiveMetastore 9083)
[ "$metapid" ] && kill $metapid || echo "Metastore服务未启动"
server2pid=$(check_process HiveServer2 10000)
[ "$server2pid" ] && kill $server2pid || echo "HiveServer2服务未启动"
}
case $1 in
"start")
hive_start
;;
"stop")
hive_stop
;;
"restart")
hive_stop
sleep 2
hive_start
;;
"status")
check_process HiveMetastore 9083 >/dev/null && echo "Metastore服务运行正常" || echo "Metastore服务运行异常"
check_process HiveServer2 10000 >/dev/null && echo "HiveServer2服务运行正常" || echo "HiveServer2服务运行异常"
;;
*)
echo Invalid Args!
echo 'Usage: '$(basename $0)' start|stop|restart|status'
;;
esac6.使用mysql进行配置metastore
原因在于Hive默认使用的元数据库为derby 。derby数据库的特点是同一时间只允许一个客户端访问。如果多个Hive客户端同时访问,就会报错。 由于在企业开发中,都是多人协作开发,需要多客户端同时访问Hive,怎么解决呢?我们可以将Hive的元数据改为用MySQL存储,MySQL支持多客户端同时访问。
js
使用工具navicat创建数据库 metastore或者服务器内登录mysql 执行create database metastore;
[username@hadoop102 hive]$ bin/schematool -dbType mysql -initSchema -verbose7.hive下载地址
js
https://archive.apache.org/dist/hive/8.使用Datagrip进行验证是否可以登录