我整理好的1000+面试题,请看
大模型面试题总结-CSDN博客
或者
https://gitee.com/lilitom/ai_interview_questions/blob/master/README.md
最好将URL复制到浏览器中打开,不然可能无法直接打开
📄 LiveTalk: Real-Time Multimodal Interactive Video Diffusion via Improved On-Policy Distillation
1. 作者与机构 🔬
作者: Ethan Chern、Zhulin Hu、Bohao Tang、Jiadi Su、Steffi Chern、Zhijie Deng、Pengfei Liu (arXiv1)
机构: 作者来自多个研究机构,包括 SII、SJTU、GAIR(具体机构信息可参考论文原文)(闲记算法2)
📌 背景补充: 团队成员在 视频生成、扩散模型、互动系统与多模态学习 等领域有多项相关研究,在构建用于实时交互的视频生成系统方面具有较强经验积累。
2. 研究背景 📚
随着 AI 技术的发展,实时生成视频响应 是构建智能交互系统(如虚拟数字人、对话型 AI 伴侣)的重要基础任务。然而目前:
-
扩散模型(Diffusion Models) 在视频生成中表现出优异的视觉质量,但其迭代式去噪与双向注意力机制 要求在生成每一帧之前访问整个视频序列,从而导致推理延迟高达 60--120 秒,不适合实时场景。(AIModels3)
-
现有为了提速的蒸馏方法(如 Self Forcing)已能将生成过程变为自回归并减少步骤,但它们主要针对文本到视频 (T2V) 情况设计,多模态条件下生成仍表现不稳定,出现闪烁、黑帧和质量下降等伪影。(AIModels3)
因此,在更复杂的 多模态条件(文本、图像、音频) 下进行实时视频扩散生成仍存在明显挑战。(AIModels3)
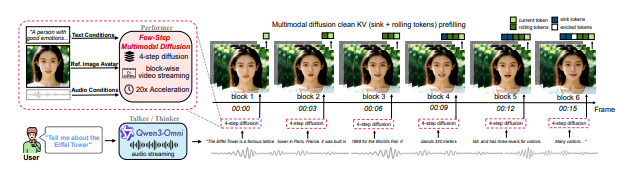
3. 研究动机
🎯 核心问题: 毫秒级或接近实时的视频生成对于人机交互至关重要,但目前的视频扩散系统由于架构和训练机制限制,还无法满足这种实时性需求。
📌 具体挑战:
-
如何在 多模态条件(text + image + audio) 下稳定地微调扩散模型,从而实现高速推理?
-
现有的 on-policy distillation 方法在单一条件下表现良好,但当条件信号多源且互相竞争时容易失败。
📍 研究价值: 设计一种 改进的 on-policy 蒸馏(distillation)配方 ,使得视频生成模型能够保持与高质量双向扩散基线相当的视觉质量,并实现 20× 更低推理成本与延迟,从而真正支持实时 AI 交互系统。(Hugging Face4)
4. 方法概述 ⚙
本文提出了一套改进的 on-policy distillation 机制和条件数据处理策略,使视频扩散模型能在保持高质量的同时,支持真实时间多模态交互。
📌 4.1 问题定位:为何 Self Forcing 失败
Self Forcing 是现有用于蒸馏扩散模型为自回归结构的方法,但当同时引入多个条件信号(如音频嘴型、身份图像、文本语义)时,这些信号之间可能冲突,最终导致:
-
视频闪烁、黑帧伪影;
-
身份不一致;
-
质量下降。(AIModels3)
🛠 4.2 核心改进点
论文提出了 三条改进策略 来提升蒸馏训练的稳定性与效率:
✅ 1. 条件输入的质量筛选
-
对 音频、图像、文本 条件输入进行预处理与筛选。
-
音频需清晰且容易与视觉嘴型对齐;
-
图像需光照均匀且身份一致;
-
文本需与录制内容语义保持高度一致。 思路:清晰、噪声低的条件输入提供更稳定的训练信号。(AIModels3)
🧠 2. 改进的初始化与优化调度
-
在蒸馏训练过程中,并非从随机噪声开始学习,而是在一定程度上让学生模型先"暖身"以匹配教师模型的输出。
-
具体来说,让学生模型从与教师模型接近的输出起点开始蒸馏,有助于避免在早期训练中陷入错误模式。
-
同时采用更激进的调度策略,让训练后期更快逼近期望的少步采样能力。(AIModels3)
🔁 3. 增强 on-policy 优化策略
-
通过调整训练策略与蒸馏优化机制,使得模型在多模态条件下获得更一致、更稳定的学习信号。
-
论文指出这些调整在视觉质量和稳定性方面都带来显著改进。(AIModels3)
📎 4.3 构建 LiveTalk 系统
论文不仅提出蒸馏改进方法,还基于此构建了完整的实时多模态交互系统 LiveTalk:
-
将蒸馏后的视频生成模型与 音频语言模型(如 Qwen3-Omni) 集成;
-
通过 Anchor-Heavy Identity Sinks 等技术维持长序列对话中的身份一致性;
-
实现多模态输入(语音、图像、文本)条件下的实时视频生成响应。(AIModels3)
5. 实验结果 📊
🔍 实验设置
评估任务集中于 多模态条件的 Avatar 视频生成,使用多个 benchmark:
-
HDTF
-
AVSpeech
-
CelebV-HQ 这些数据集包含语音、面部图像和文本语义等多模态信息,适合评估系统在真实多源条件下的性能。(Hugging Face4)
📈 关键实验结果
✅ 显著加速
-
蒸馏模型在推理阶段相比双向全步扩散基线性能 降低约 20× 的计算成本与延迟。
-
响应延迟从 60--120 秒 被压缩至 实时接近水平。(Hugging Face4)
✅ 保持高视觉质量
- 在视觉质量评估指标上(如身份一致性、音视频同步、内容质量等),蒸馏模型与大规模、全步 bidirectional 模型表现基本一致。(Hugging Face4)
✅ 系统级 benchmark 优势
-
LiveTalk 在多个回合交互基准测试中优于现有 SOTA 模型(如 Sora2、Veo3),表现为:
-
更高的视频连贯性;
-
更自然的多轮生成质量;
-
极低的响应延迟。(Hugging Face4)
-
6. 未来展望 🔮
📍 研究局限性与潜在方向:
-
高质量条件输入筛选机制依赖数据质量,在噪声较高场景可能受限;
-
蒸馏策略虽显著提升实时性能,但对于更大场景(如全身动作实时生成)或更加复杂条件(多人物、多语言)仍有探索空间;
-
将方法推广至更丰富的实时互动环境(AR/VR、跨设备协作等)是未来可能方向。
📌 开源代码与资源
📂 论文链接(arXiv): https://arxiv.org/abs/2512.23576 (arXiv1)
📌 **注意:**截至目前未检测到官方开源代码库,如有发布可后续补充链接。
1.https://arxiv.org/abs/2512.23576 2.https://lonepatient.top/2025/12/30/arxiv_papers_2025-12-30.html 3.https://www.aimodels.fyi/papers/arxiv/livetalk-real-time-multimodal-interactive-video-diffusion?utm_source=chatgpt.com "LiveTalk: Real-Time Multimodal Interactive Video Diffusion via Improved On-Policy Distillation | AI Research Paper Details" 4.https://huggingface.co/papers/2512.23576