一、RAG原理
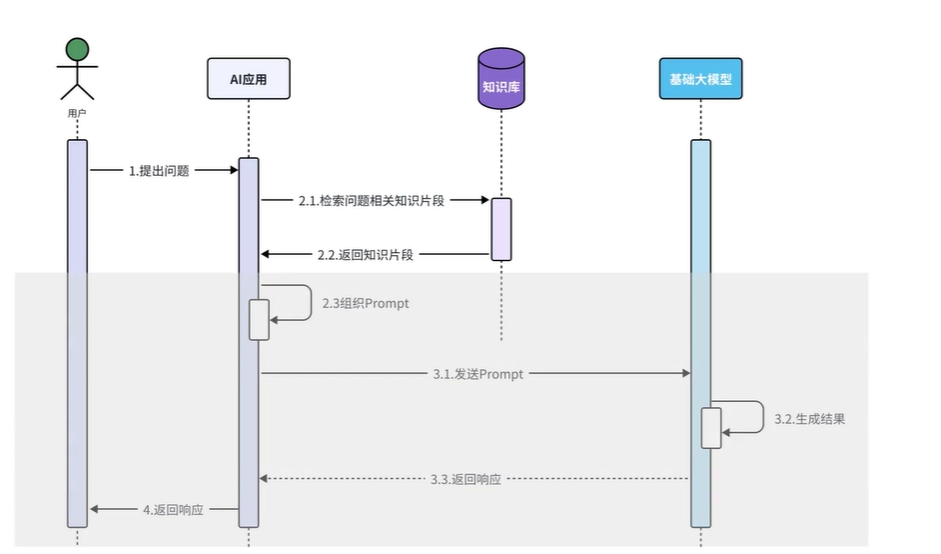
当用户把问题发送给AI应用,AI应用会先根据用户的问题从知识库中检索对应的知识片段,得到知识片段后AI应用需要结合用户的问题以及知识库中检索到的知识片段组织要发送给大模型的消息,大模型接收到消息后会同时根据用户的问题、知识库检索到的知识片段以及自身的知识储备,生成对应的结果响应给AI应用,最终再返回给用户。
向量数据库
1.余弦相似度
这个知识库一般采取的是一种特殊的数据库,叫向量数据库。目前市面上常见的向量数据库有很多,比如Milvus、Chroma、Pinecone
在第一象限中,向量之间的余弦相似度的取值范围为0~1,而且余弦相似度越大,说明向量的方向越接近,对应的两点之间的距离越小。
2.向量数据库存储数据
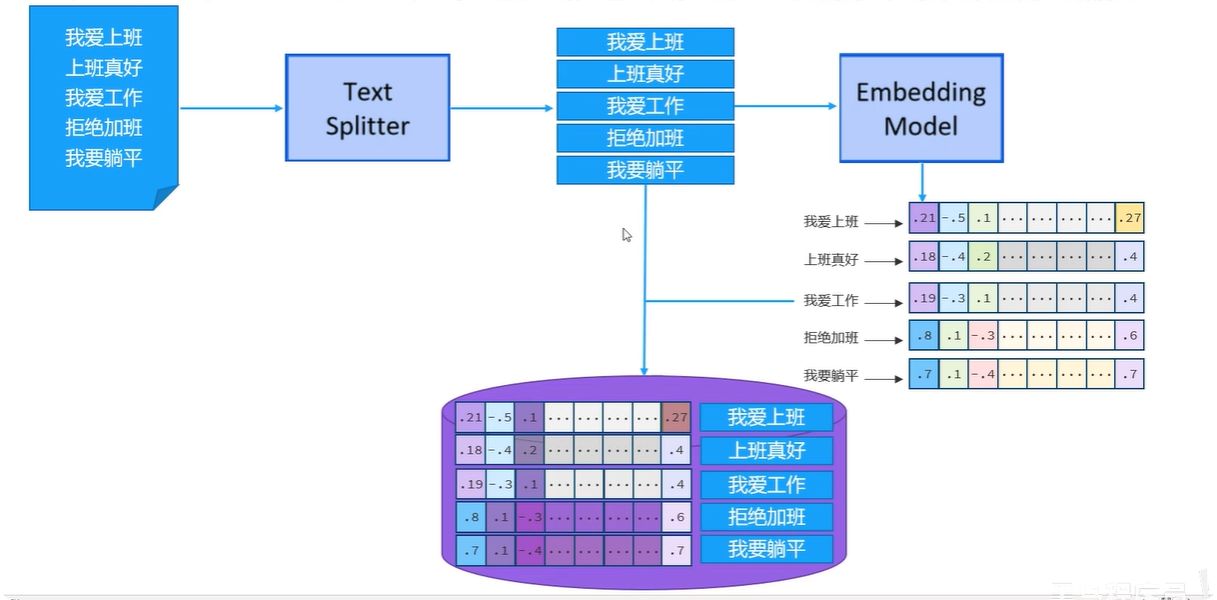
比如我有一个大的文档,里面存储了一些文本信息,接下来借助于文本分割器把大的文档切割成一个一个的文本片段,比如这里切割为我爱上班、上班真好、我爱工作、拒绝加班、我要躺平这五个小片段。紧接着使用向量模型把文本片段转化为向量,那我们之前聊过所谓的向量在坐标系中表示就是记录每一个轴的坐标,说白了就是一堆数字,最后再把每一个向量和其对应的文本片段组合成一条一条的数据存储到向量数据库中。
3.从向量数据库中检索出跟用户问题相关的文本片段
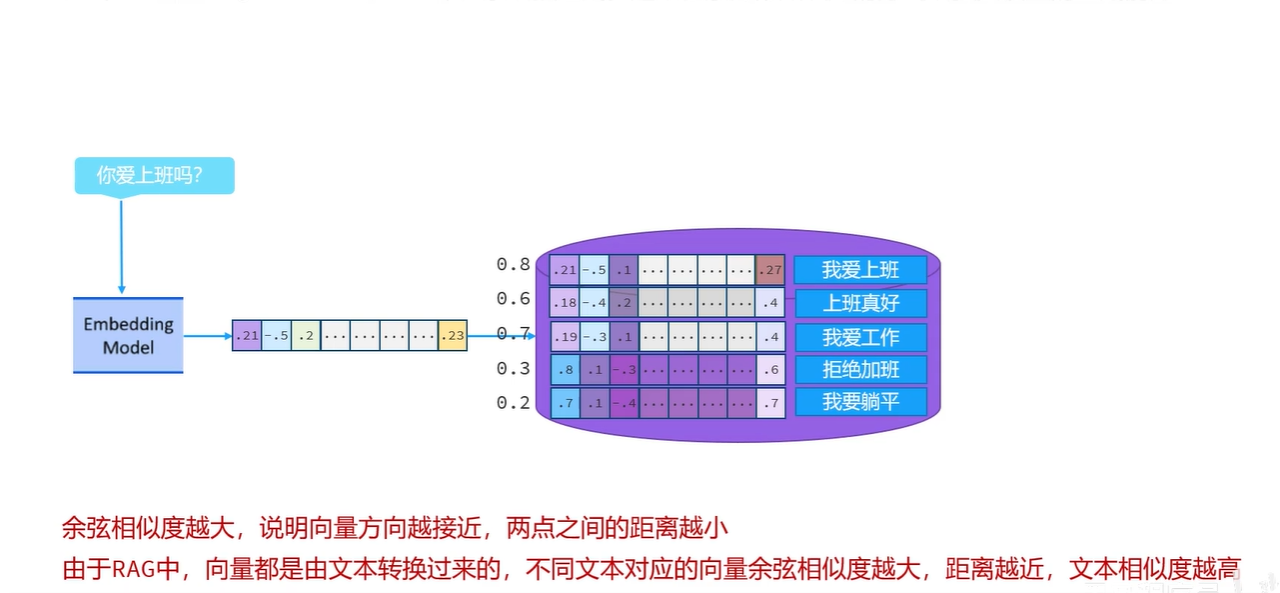
假如用户提交了一条消息,你爱上班吗?接下来需要使用向量模型将这条消息转换成向量,其实得到的就是一组坐标数据 。紧接着拿着该向量和向量数据库中的向量比对,计算余弦相似度,假设最终计算的结果分别为 0.8、0.6、0.7、0.3、0.2,之前我们讲过,两个向量的余弦相似度越大说明向量方向越接近,两点之间的距离越小。由于RAG中,向量都是由文本转换过来的,**不同文本对应的向量余弦相似度越大说明对应文本之间的距离越近,那么对应文本的相似度就越高也就是说该向量对应的文本片段跟用户问的问题相关度越高。**假设我设置一个标准:只有余弦相似度超过0.5的文本能被查出来。此时, 我爱上班、上班真好、我爱工作这三个片段就被检索出来了,最后再把用户的问题和检索出来的这三个文本片段一并发送给大模型,让大模型生成结果即可。
二、快速入门
1.存储(构建向量数据库的操作对象)
1.1引入依赖
java
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-easy-rag</artifactId>
<version>1.0.1-beta6</version>
</dependency>1.2加载知识数据文档
A. 将资料中准备的《西北大学.pdf》拷贝到当前工程的 resources/content 目录下
B. LangChain4j提供的ClassPathDocumentLoader 可以让我们快速的将指定目录下的文档加载进内存中,并且每一个文档,都会对应的生成一个Document对象来记录文档的内容。这一部分工作需要在CommonConfig.java中完成。
java
@Bean
public EmbeddingStore store(){
//1.加载文档进内存
List<Document> documents = ClassPathDocumentLoader.loadDocuments("content");
return null;
}1.3构建向量数据库操作对象EmbeddingStore
java
@Bean
public EmbeddingStore store(){
//1.加载文档进内存
List<Document> documents = ClassPathDocumentLoader.loadDocuments("content");
//2.构建向量数据库操作对象 操作的是内存版本的向量数据库
InMemoryEmbeddingStore store = new InMemoryEmbeddingStore();
return store;
}1.4切割文档、向量化并存储到向量数据库
java
@Bean
public EmbeddingStore store(){
//1.加载文档进内存
List<Document> documents = ClassPathDocumentLoader.loadDocuments("content");
//2.构建向量数据库操作对象 操作的是内存版本的向量数据库,存储在JVM内存
InMemoryEmbeddingStore store = new InMemoryEmbeddingStore();
//3.构建一个EmbeddingStoreIngestor对象,完成文本数据切割,向量化, 存储
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
.embeddingStore(store)
.build();
ingestor.ingest(documents);
return store;
}2.检索
2.1构建ContentRetriever对象
LangChain4j提供的向量数据库检索对象叫做EmbeddingStoreContentRetriever,构建的时候我们可以设置三个内容。第一个 得调用embeddingStore方法告诉它从哪里检索,其实就是我们刚才构建的这个InmemoryEmbeddingStore给他即可;第二个 我们可以设置一下最小余弦相似度的值,之前我们讲过检索的时候会把用户的问题向量化,然后与向量数据库中已经存在的向量计算余弦相似度,值越大,相似度越高,这里通过minScore方法设置一个最低的相似度分数,可以确保检索出来的内容跟用户问题的相关度比较高;第三个可以设置一个最大检索出来的片段数量值,因为将来如果检索出来的片段太多,一并发送给大模型,token的消耗是比较大的,而且分数低的片段你发送给大模型还会影响生成的结果,这里通过maxResults方法设置最大的片段数量后,它会保留分数最高的前几个片段使用。这些操作也是在CommonConfig.java中完成
java
@Bean
public ContentRetriever contentRetriever(EmbeddingStore store){
return EmbeddingStoreContentRetriever.builder()
.embeddingStore(store)//设置向量数据库操作对象
.minScore(0.5)//设置最小分数
.maxResults(3)//设置最大片段数量
.build();
}2.2配置ContentRetriever对象
在AiService注解中借助于contentRetriver这个属性完成配置即可。
java
@AiService(
wiringMode = AiServiceWiringMode.EXPLICIT,//手动装配
chatModel = "openAiChatModel",//指定模型
streamingChatModel = "openAiStreamingChatModel",
//chatMemory = "chatMemory",//配置会话记忆对象
chatMemoryProvider = "chatMemoryProvider",//配置会话记忆提供者对象
contentRetriever = "contentRetriever"//配置向量数据库检索对象
)
//@AiService
public interface ConsultantService {
//用于聊天的方法
//public String chat(String message);
//@SystemMessage("你是东哥的助手小月月,人美心善又多金!")
@SystemMessage(fromResource = "system.txt")
//@UserMessage("你是东哥的助手小月月,人美心善又多金!{{it}}")
//@UserMessage("你是东哥的助手小月月,人美心善又多金!{{msg}}")
public Flux<String> chat(/*@V("msg")*/@MemoryId String memoryId, @UserMessage String message);
}三、核心API
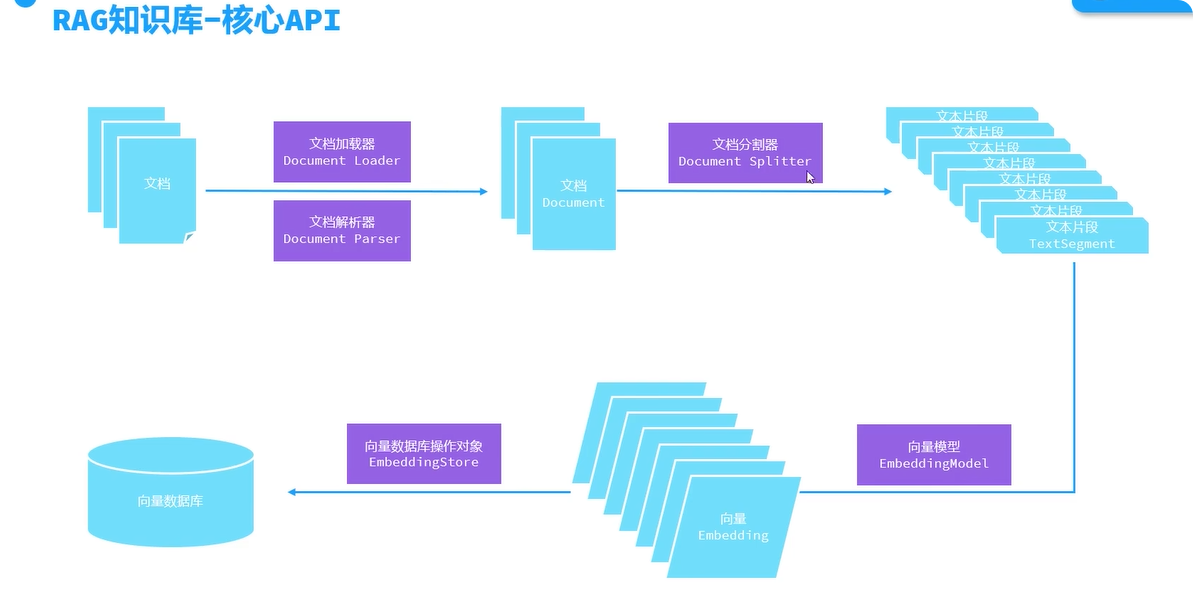
在整个流程中,主要用到了文档加载器、文档解析器、文档分割器、向量模型以及向量数据库操作对象 这五类API,等会儿咱们挨个讲解。其中有关文档分割器、向量模型、还有向量数据库操作对象的具体方法的调用都被封装到了EmbeddingStoreIngestor 中了,对于咱们来说无需过多关注,我们主要关注的是使用哪种文档分割器、哪种向量模型、哪种向量数据库操作对象即可,将来用哪种把哪种交给EmbeddingStoreIngestor就可以了。
1.文档加载器
- FileSystemDocumentLoader, 根据本地磁盘绝对路径加载
- ClassPathDocumentLoader,相对于类路径加载,就是相对于resources
- UrlDocumentLoader,根据url路径加载
2.文档解析器
- TextDocumentParser,解析纯文本格式的文件
- ApachePdfBoxDocumentParser,解析pdf格式文件
- ApachePoiDocumentParser,解析微软的office文件,例如DOC、PPT、XLS
- ApacheTikaDocumentParser(默认),几乎可以解析所有格式的文件
切换默认解析器:
2.1准备pdf格式的数据
2.2引入解析器依赖
java
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-document-parser-apache-pdfbox</artifactId>
<version>1.0.1-beta6</version>
</dependency>2.3加载文档时指定解析器
java
@Bean
public EmbeddingStore store(){
//1.加载文档进内存
//List<Document> documents = ClassPathDocumentLoader.loadDocuments("content");
//加载文档的时候指定解析器
List<Document> documents = ClassPathDocumentLoader.loadDocuments("content",new ApachePdfBoxDocumentParser());
//2.构建向量数据库操作对象 操作的是内存版本的向量数据库
InMemoryEmbeddingStore store = new InMemoryEmbeddingStore();
//3.构建一个EmbeddingStoreIngestor对象,完成文本数据切割,向量化, 存储
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
.embeddingStore(store)
.build();
ingestor.ingest(documents);
return store;
}3.文档分割器
文本分割器会把一个大的文档,切割成一个一个的小片段,每个文本片段会有最大限制,默认是300
- DocuemntByParagraphSplitter,按照段落分割文本
- DocumentByLineSplitter,按照行分割文本
- DocumentBySentenceSplitter,按照句子分割文本
- DocumentByWordSplitter,按照词分割文本
- DocumentByCharacterSplitter,按照固定数量的字符分割文本
- DocumentByRegexSplitter,按照正则表达式分割文本
- DocumentSplitters.recursive(...)(默认 ),递归分割器,优先段落分割,再按照行分割,再按照句子分割,再按照词分割,当按段落分割文本片段盛不下一个完整的段落的时候就会尝试使用行分割,依次类推
切换默认的文本分割器
3.1构建文本分割器对象
java
DocumentSplitter documentSplitter = DocumentSplitters.recursive(
每个片段最大容纳的字符,
两个片段之间重叠字符的个数(把上一个片段末尾放在下一个片段开头,保持连贯)
);3.2配置文本分割器对象
java
@Bean
public EmbeddingStore store(){
//1.加载文档进内存
//List<Document> documents = ClassPathDocumentLoader.loadDocuments("content");
//加载文档的时候指定解析器
List<Document> documents = ClassPathDocumentLoader.loadDocuments("content",new ApachePdfBoxDocumentParser());
//2.构建向量数据库操作对象 操作的是内存版本的向量数据库
InMemoryEmbeddingStore store = new InMemoryEmbeddingStore();
//构建文档分割器对象
DocumentSplitter ds = DocumentSplitters.recursive(500,100);
//3.构建一个EmbeddingStoreIngestor对象,完成文本数据切割,向量化, 存储
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
.embeddingStore(store)
.documentSplitter(ds)
.build();
ingestor.ingest(documents);
return store;
}4.向量模型
向量模型的作用是把分割后的文本片段向量化或者把用户消息向量化。
LangChain4j中提供了EmbeddingModel接口 用于定义有关向量模型的方法,例如有embed、embedall等等方法用于把文本片段向量化。LangChain4j提供了一个内存版本的向量模型实现方案,而咱们快速入门中使用的就是这个向量模型,只是咱们当时并没有指定这个向量模型,因为它被封装到EmbeddingStoreIngestor中了,所以我们并没有看到。
4.1配置向量模型
在总配置文件加入embedding-model的配置
java
langchain4j:
open-ai:
embedding-model:
base-url: https://dashscope.aliyuncs.com/compatible-mode/v1
api-key: ${API-KEY}
model-name: text-embedding-v3
log-requests: true
log-responses: true
//这是根据text-embedding-v3这个模型的自身限制决定的,一次最多发10个片段
max-segments-per-batch4.2设置向量模型
把这个EmbeddingModel对象交给EmbeddingStoreIngestor和EmbeddingStoreContentRetriever即可,一个是存储的时候使用,一个是检索的时候使用。
java
@Autowired
private EmbeddingModel embeddingModel;
@Bean
public EmbeddingStore store(){
//1.加载文档进内存
//List<Document> documents = ClassPathDocumentLoader.loadDocuments("content");
//加载文档的时候指定解析器
List<Document> documents = ClassPathDocumentLoader.loadDocuments("content",new ApachePdfBoxDocumentParser());
//2.构建向量数据库操作对象 操作的是内存版本的向量数据库
InMemoryEmbeddingStore store = new InMemoryEmbeddingStore();
//构建文档分割器对象
DocumentSplitter ds = DocumentSplitters.recursive(500,100);
//3.构建一个EmbeddingStoreIngestor对象,完成文本数据切割,向量化, 存储
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
.embeddingStore(store)
.documentSplitter(ds)
.embeddingModel(embeddingModel)
.build();
ingestor.ingest(documents);
return store;
}
@Bean
public ContentRetriever contentRetriever(EmbeddingStore store){
return EmbeddingStoreContentRetriever.builder()
.embeddingStore(store)
.minScore(0.5)
.maxResults(3)
.embeddingModel(embeddingModel)
.build();
}5.操作向量数据库
EmbeddingStore是用来操作向量数据库的API,将来不管是存储还是检索都需要借助于它来完成。LangChain4j提供的EmbeddingStore接口中提供了两组方法,分别是add用于存储数据,search用于检索数据。
LangChain4j还提供了一个实现方案InMemoryEmbeddingStore ,也就是咱们之前一直使用的方案,但是这它操作的是内存向量数据库,如果我们使用内存向量数据库,一旦服务器重启数据就丢失了,又得重新加载文档、重新向量化,这样每次启动都会比较耗时,还有就是每次启动都会使用百炼平台提供的向量模型完成向量化,它是收费的,每次都这么干那是跟钱过不去,没必要对吧。
所以咱们得考虑把向量化后的数据存储到外部的向量数据库中。之前给大家介绍过常见的向量数据库有Milvus、Chroma、Pinecone、RediSearch以及pgvector, 用哪一种都行,LangChain4j对这些向量数据库都做了支持。咱们本次课程中采用redisearch存储向量数据。
5.1准备向量数据库RediSearch
这一块我们依然使用docker来部署redisearch ,由于redisearch是redis扩展的一个功能,所以我们得把之前部署的redis先卸载掉,然后部署一个扩展了redissearch的redis即可。这里我们需要执行三条命令:
java
docker stop redis # 停止原有的redis镜像
docker rm redis #删除原有的redis镜像
docker run --name redis-vector -d -p 6379:6379 redislabs/redisearch #安装扩展redisearch功能的redis5.2引入依赖
java
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-redis-spring-boot-starter</artifactId>
<version>1.0.1-beta6</version>
</dependency>5.3配置向量数据库连接信息
java
langchain4j:
community:
redis:
host: localhost
port: 63795.4注入RedisEmbeddingStore对象使用
java
@Autowired
private RedisEmbeddingStore redisEmbeddingStore;
@Bean
public EmbeddingStore store(){//embeddingStore的对象, 这个对象的名字不能重复,所以这里使用store
//1.加载文档进内存
//List<Document> documents = ClassPathDocumentLoader.loadDocuments("content");
List<Document> documents = ClassPathDocumentLoader.loadDocuments("content",new ApachePdfBoxDocumentParser());
//List<Document> documents = FileSystemDocumentLoader.loadDocuments("C:\\Users\\Administrator\\ideaProjects\\consultant\\src\\main\\resources\\content");
//2.构建向量数据库操作对象 操作的是内存版本的向量数据库
//InMemoryEmbeddingStore store = new InMemoryEmbeddingStore();
//构建文档分割器对象
DocumentSplitter ds = DocumentSplitters.recursive(500,100);
//3.构建一个EmbeddingStoreIngestor对象,完成文本数据切割,向量化, 存储
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
//.embeddingStore(store)
.embeddingStore(redisEmbeddingStore)
.documentSplitter(ds)
.embeddingModel(embeddingModel)
.build();
ingestor.ingest(documents);
return redisEmbeddingStore;
}
@Bean
public ContentRetriever contentRetriever(/*EmbeddingStore store*/){
return EmbeddingStoreContentRetriever.builder()
.embeddingStore(redisEmbeddingStore)
.minScore(0.5)
.maxResults(3)
.embeddingModel(embeddingModel)
.build();
}四、收尾工作
1.将所有的pdf文档放入resources
2.避免每次启动程序都做向量化的操作
由于咱们准备向量数据库的操作是在CommonConfig配置类中完成的,在该类中我们提供了一个store方法,方法上添加了一个@Bean注解,所以每次启动程序,该方法都会执行一遍 ,文档就会重新加载,重新向量化,不合适。所以当我们把所有文档拷贝到content目录中,启动测试一遍后,redis中就已经存好了所有的数据,接下来把store方法上的@Bean注解注释掉,可以避免每次启动都做向量化的操作。