Transformer实战(34)------多语言和跨语言Transformer模型
0. 前言
我们已经学习了多种 Transformer 架构,从仅编码器模型到仅解码器模型,从高效 Transformer 到长上下文 Transformer,还学习了基于孪生网络 (Siamese network) 的语义文本表示方法,但这些模型都局限于单语言任务。这些模型仅能理解单一语言,无法对文本进行跨语言的通用理解。事实上,其中一些模型已经有了多语言变体,例如:多语言双向 Transformer 编码器 (multilingual bidirectional encoder representations from transformer, mBERT)、多语言文本到文本迁移 Transformer (multilingual text-to-text transfer transformer, mT5) 和多语言双向自回归 Transformer (multilingual bidirectional and auto-regressive transformer, mBART)等。另一方面,一些模型是专门为多语言任务设计的,并通过跨语言目标进行训练,如跨语言语言模型 (cross-lingual language model, XLM)。
本节将介绍语言间的知识共享概念,并分析字节对编码 (byte-pair encoding, BPE) 在分词部分的影响,以实现更好的输入处理。介绍使用跨语言自然语言推理 (Cross-Lingual Natural Language Inference, XNLI) 语料库进行跨语言句子相似性任务。此外,介绍跨语言分类以及利用跨语言句子表示进行"在一种语言上训练、在另一种语言上测试"的任务,并解决实际的自然语言处理 (Natural Language Processing, NLP) 问题(例如多语言意图分类)。
同时,本节还将介绍大规模多语言翻译,多语言模型 (mBART 和 M2M100 等) 能够在多种语言之间执行翻译任务。
1. 翻译语言建模与跨语言知识共享
我们已经学习了掩码语言建模 (Masked Language Modeling, MLM)作为填空任务的工作原理。而基于神经网络的语言建模根据其方法和实际用途可以分为以下三类:
- 掩码语言建模 (
Masked Language Modeling,MLM) - 因果语言建模 (
Causal Language ModelingCLM) - 翻译语言建模 (
Translation Language Modeling,TLM)
需要注意的是,除了这些方法外,还有其他预训练方法,例如下一句预测 (next-sentence prediction, NSP) 和句子顺序预测 (sentence order prediction, SOP),但本节我们只考虑基于词元的语言建模。MLM 与语言学习中的完形填空任务非常相似。
CLM 的定义是通过前面的词元 (token) 预测下一个词元。例如,如果看到以下的上下文,可以很容易地预测下一个词元:
shell
<s> Transformers changed the natural language ...如上所示,只有最后一个词元被掩码,前面的词元提供给模型以预测最后一个词元。这个词元可能是 "processing",如果提供包含该词元的上下文,模型可能会输出 "</s>" 词元结束句子。为了使这种方法的训练效果更好,需要避免掩码第一个词元,因为模型将只有一个句子起始词元来生成句子,例如:
shell
<s> ...模型可以预测任何内容。为了获得更好的训练效果,至少需要提供第一个词元,例如:
python
<s> Transformers ...模型需要预测 "changed"; 在提供 "Transformers changed ..." 后,模型需要预测 "the",依此类推。这种方法与N-grams和基于长短期记忆 (Long Short-Term Memory, LSTM)的方法非常相似,因为它基于概率 p ( w n ∣ w n − 1 , w n − 2 , . . . , w 0 ) p(w_n|w_{n-1}, w_{n-2}, ..., w_0) p(wn∣wn−1,wn−2,...,w0) 从左到右建模,其中 w n w_n wn 是需要预测的词元,其他部分表示它之前的词元,概率最大的词元就是预测结果。
这些方法通常用于单语模型,而跨语言模型使用 TLM,它与 MLM 非常相似,不同之处在于,MLM 提供单一语言的句子,而 TLM 将来自不同语言的句子对提供给模型,句子之间通过一个特殊的标记进行分隔。模型需要预测被随机掩码的词元,这些词元可能出现在句子对中的任意一种语言里。
以下是一个 TLM 任务的示例句子对:

给定这两个掩码句子,模型需要预测缺失的词元。在这个任务中,模型能访问到句子对中另一种语言的词元(例如图中句子对中的"自然"和 "language")。
接下来,观察以下中文和法语句子对,在第二个句子中"星星"词元可以关注第一个句子中的多个词元(其中一个被掩码):
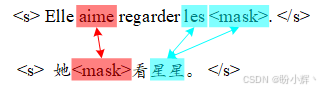
因此,模型可以学习这些含义之间的映射。就像翻译模型一样,TLM 也必须学习语言之间的复杂性,因为机器翻译 (Machine Translation, MT) 不仅仅是词元到词元的映射。
我们已经学习了跨语言模型如何通过翻译语言建模来进行学习。接下来,将介绍两个经典跨语言模型,XLM 和 mBERT。
2. XLM 和 mBERT
在本节中,我们将深入探讨多语言双向 Transformer 编码器 (multilingual bidirectional encoder representations from transformer, mBERT)和跨语言语言模型 (cross-lingual language model, XLM),这两个模型是多语言模型的典型代表。mBERT 是一个多语言模型,使用 MLM 建模,在不同语言的语料库上进行训练,可以单独处理多种语言;而 XLM 使用 MLM、CLM 和 TLM 语言建模在不同语料库上进行训练,能够解决跨语言任务。例如,它可以通过将句子映射到公共向量空间来测量两种不同语言句子的相似性,而这是 mBERT 无法做到的。
2.1 mBERT
我们已经学习了BERT 自编码器模型,以及如何在指定的语料库上使用 MLM 进行训练。假设提供的语料库不是单一语言,而是来自 104 种语言的广泛语料库。在这种语料库上进行训练将会产生一个多语言版本的 BERT (mBERT)。但使用如此广泛的语言进行训练会增加模型的大小,这在 BERT 的情况下是不可避免的。词汇表的大小将增加,因此嵌入层的大小也会变得更大。
与单语言预训练的 BERT 相比,mBERT 能够在单一模型中处理多种语言。但这种建模方法的缺点是,模型无法在不同语言之间进行映射。这意味着,在预训练阶段,模型并没有学习不同语言中的词元 (token) 之间语义的映射关系。为了让该模型具备跨语言映射和理解能力,需要在一些跨语言的监督任务上进行训练,例如使用跨语言自然语言推理 (Cross-Lingual Natural Language Inference, XNLI) 数据集中的任务。
(1) 使用 mBERT 模型执行各种语言的填空任务 (fill-mask):
python
from transformers import pipeline
unmasker = pipeline('fill-mask', model='bert-base-multilingual-uncased')
sentences = [
"Transformers changed the [MASK] language processing",
"Transformerlar [MASK] dil işlemeyi değiştirdiler",
"ترنسفرمرها پردازش زبان [MASK] را تغییر دادند"
]
for sentence in sentences:
print(sentence)
print(unmasker(sentence)[0]["sequence"])
print("="*50)输出如下所示,可以看到,mBERT 可以执行各种语言的填空任务:

2.2 XLM
跨语言预训练的语言模型(如 XLM),基于三种不同的预训练目标:掩码语言模型 (Masked Language Model, MLM),因果语言模型 (Causal Language Model, CLM),和翻译语言模型 (Translation Language Model, TLM)。XLM 预训练的顺序是通过在所有语言之间共享字节对编码 (Byte Pair Encoding, BPE) 分词器来进行的。共享分词的原因是,对于那些具有相似词元或子词的语言,共享分词可以减少分词数量,同时这些共享词元可以在预训练过程中提供共享的语义。例如,一些词元在多种语言中具有非常相似的写法和含义,因此这些词元会被 BPE 共享给所有语言。此外,某些在不同语言中拼写相同的词元可能有不同的含义------例如,"was" 在德语和英语中的含义不同。但自注意力机制可以通过上下文来消除 "was" 的含义歧义。
这种跨语言建模的另一个重要改进是,它通过 CLM 任务进行预训练,使得在需要句子预测或补全的推理任务中更加合理。换句话说,XLM 模型能够理解语言,并且能够补全句子、预测缺失的词元,甚至通过使用其他语言来预测缺失的词元。
下图展示了跨语言建模的整体结构:
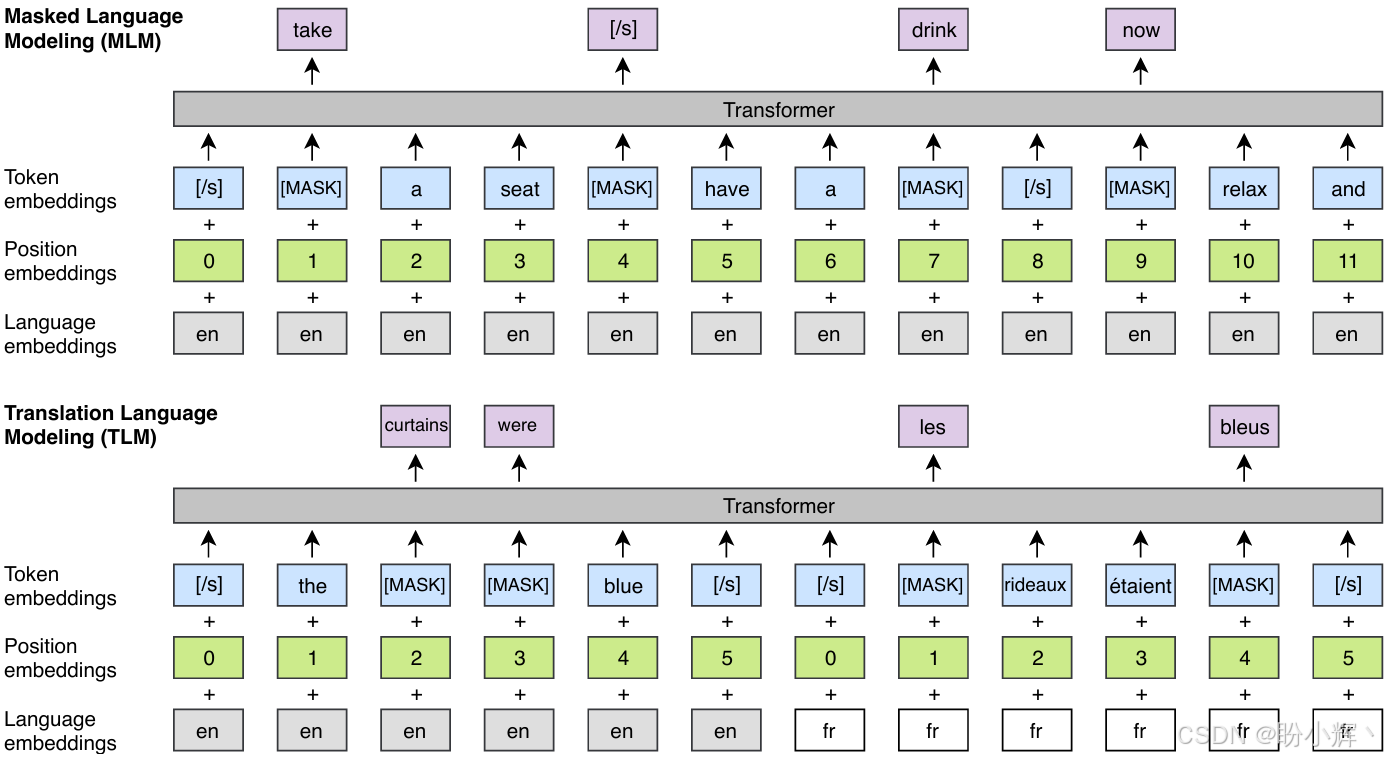
XLM 模型的一个改进版本是 XLM-R (XLM-Robust),它在训练和使用的语料库上进行了改进。XLM-R 与 XLM 模型基本相同,但它在更多语言和更大的语料库上进行训练。整合了 CommonCrawl 和 Wikipedia 语料库,XLM-R 在这个语料库上进行了 MLM 预训练,XNLI 数据集也用来进行 TLM 任务。下图展示了 XLM-R 预训练使用的数据量:
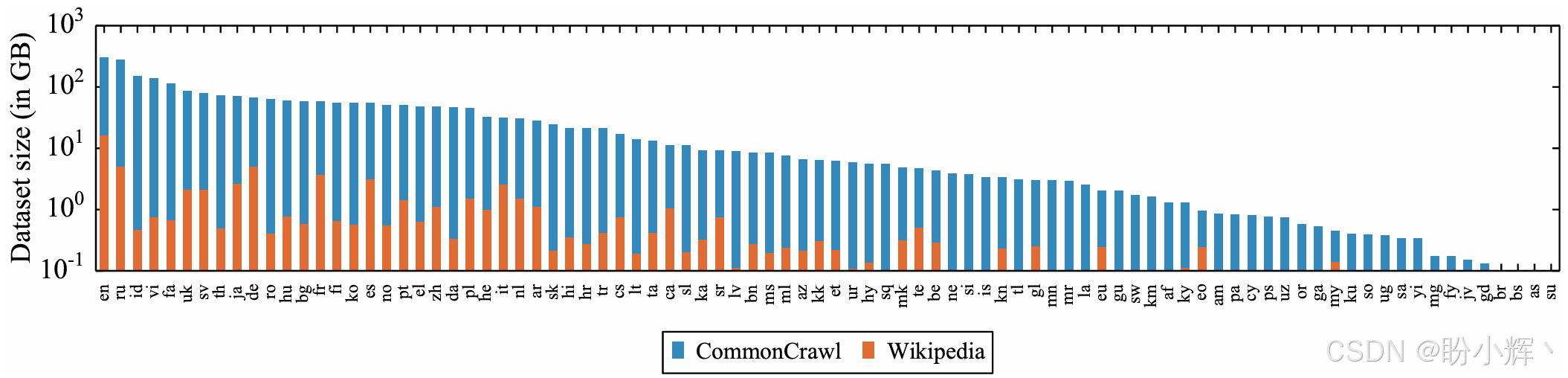
在添加新语言作为训练数据时,有优点也有缺点;例如,添加新语言并不总是能提高自然语言推理 (Natural Language Inference, NLI) 模型的整体性能。
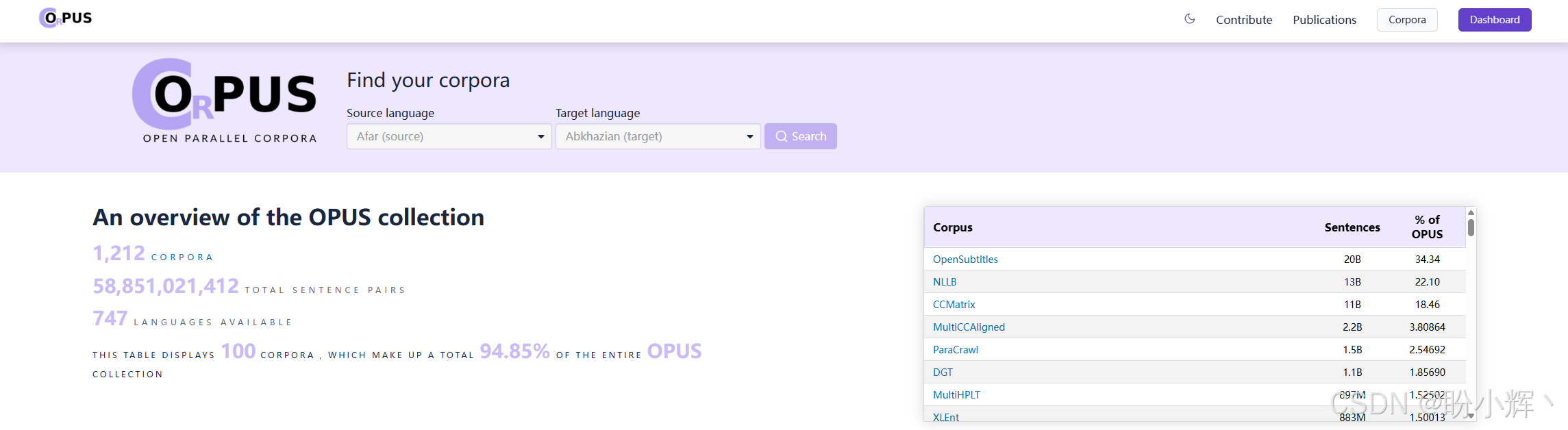
跨语言自然语言推理 (Cross-Lingual Natural Language Inference, XNLI) 数据集通常用于多语言和跨语言的 NLI 任务。XNLI 数据集几乎与用于英语的 MNLI (Multi-Genre NLI) 数据集相同,但包含了更多语言,并且还包含句子对。然而,仅仅在这个任务上进行训练是不够的,它无法覆盖 TLM 预训练。对于 TLM 预训练,通常会使用更广泛的数据集,比如 OPUS (Open Source Parallel Corpus) 的平行语料库,该数据集包含来自不同语言的文本,这些文本经过对齐和清理,每种语言的翻译对应项都在同一文件中,以便用于训练和评估模型。下图展示了OPUS及其用于搜索和获取数据集信息的主页:
接下来,介绍使用跨语言模型的一般步骤,使用 XLM-R 执行掩码填充。
(1) 首先,加载模型:
python
unmasker = pipeline('fill-mask', model='xlm-roberta-base')(2) 接下来,将掩码词元设为 <mask>,这是 XLM-R 的特殊词元(或者直接调用 tokenizer.mask_token):
python
sentences = [
"Transformers changed the <mask> language processing",
"Transformerlar <mask> dil işlemeyi değiştirdiler",
"ترنسفرمرها پردازش زبان <mask> را تغییر دادند"
](3) 执行掩码填充任务:
python
for sentence in sentences:
print(sentence)
print(unmasker(sentence)[0]["sequence"])
print("="*50) 结果如下所示:

(4) 可以看到,模型仍然会出现一些问题;例如,对于英语句子,模型填充了 "human",虽然句子并没有错误,但并不是预期的结果。但使用经过 TLM 训练的跨语言模型,我们可以通过将两个句子连接起来,并给模型一些额外的提示来使用它:
python
print(unmasker("Transformers changed the natural language processing. </s> Transformerlar <mask> dil işlemeyi değiştirdiler.")[0]["sequence"]) 结果如下所示,可以看到模型输出了预期结果:
shell
Transformers changed the natural language processing. Transformerlar doğal dil işlemeyi değiştirdiler.(5) 继续进行测试:
python
print(unmasker("Earth is a great place to live in. </s> زمین جای خوبی برای <mask> کردن است.")[0]["sequence"]) 输出结果如下所示:
shell
Earth is a great place to live in. زمین جای خوبی برای زندگی کردن است.我们已经学习了多语言和跨语言模型,包括 mBERT 和 XLM。我们可以使用这些模型进行多语言文本相似性任务,并将其应用于多语言抄袭检测。
3. 大规模多语言翻译
对于跨语言模型以及能够在多语言数据上表现优异的模型而言,翻译任务是一项重要课题。但翻译有不同的实现方法,可以为每种语言对使用不同的模型,也可以使用一个单一模型来处理所有语言对。
(1) M2M100 是机器翻译领域最重要的模型之一,能够支持 100 种语言之间的 9900 个翻译方向。借助 transformers 库,使用该模型进行翻译任务非常简单:
python
from transformers import (M2M100ForConditionalGeneration, M2M100Tokenizer)
model = M2M100ForConditionalGeneration.from_pretrained("facebook/m2m100_1.2B")
tokenizer = M2M100Tokenizer.from_pretrained("facebook/m2m100_1.2B")(2) 在将输入传递给模型之前,还需要设置文本的源语言:
python
text_turkish = "ne olacak bu insanlik hali?"
tokenizer.src_lang = "tr"
encoded_text = tokenizer(text_turkish, return_tensors="pt")(3) 为了生成翻译结果,还需要将目标语言的语言ID传递给模型,以指导模型生成指定语言的翻译:
python
generated_tokens = model.generate(**encoded_text, forced_bos_token_id=tokenizer.get_lang_id("fa"))
text_persian = tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
print(text_persian[0])可以看到翻译后的波斯语输出:
shell
این وضعیت بشری چه خواهد بود؟可以使用该模型支持的 101 种语言中的任何一种作为源语言和目标语言。我们已经学习了大规模机器翻译模型的工作原理。接下来,我们将进一步了解多语言模型的局限性。
4. 多语言模型的局限性
尽管多语言和跨语言模型在自然语言处理 (Natural Language Processing, NLP) 中具有巨大的潜力,但它们在像 BERT 这样的较小语言模型中的表现仍然有限。例如,mBERT 模型在各类任务中的表现不如单语言模型,这也是后者在分类任务中仍然被广泛使用的原因。另一方面,近年来大语言模型的发展在很大程度上解决了多语言模型的局限性,并提高了它们的性能。这一改进归功于参数数量的增加、训练数据集的扩展以及强化学习等先进的训练方法。因此,涌现了许多成功的多语言模型,如 mT5、Bloomz、Bactrian-x 和 Aya-101 等。
研究表明,多语言模型在试图恰当表示所有语言时,会受到"多语言诅咒" (curse of multilingualism) 困扰。向多语言模型中添加新语言在一定程度上提升其性能,但超过某个临界点后,继续添加语言反而会降低性能,这可能是由于共享词汇表的原因。与单语言模型相比,多语言模型在参数预算方面受到显著限制,因为它们需要为超过 100 种语言分配词汇表。
单语言模型和多语言模型之间的性能差异可以归因于指定分词器的能力。研究表明,当多语言模型配备专用的语言特定分词器(而非通用的共享多语言分词器)时,其在该语言上的性能会有所提升。
同时研究发现,目前由于不同语言资源分布的不平衡,不可能在单一模型中表示世界上所有的语言。作为一种解决方案,可以对资源较少的语言进行过采样,而对资源丰富的语言进行欠采样。此外,当两种语言相近时,它们之间的知识迁移可能会更有效;如果语言差异较大,这种迁移可能效果甚微。
但随着研究的不断推进,这些局限性随时可能被克服。例如,XML-R 团队最近提出了两个新模型------XLM-R XL 和 XLM-R XXL,它们在 XNLI 任务上的平均准确率分别比原始 XLM-R 模型高出 1.8% 和 2.4%。
小结
在本节中,我们学习了多语言和跨语言语言模型的预训练,以及单语言和多语言预训练之间的差异。还介绍了因果语言建模 (Causal Language Modeling, CLM) 和翻译语言建模 (Translation Language Modeling, TLM),对它们有了更深入的了解。还学习了如何使用跨语言模型,利用一种语言的数据集进行训练,对完全不同语言的数据进行测试。此外,我们还了解了可以进行大规模翻译的模型,例如 M2M100,它支持 100 种语言的 9900 个翻译方向,并且我们学习了如何使用 M2M100 模型。
系列链接
Transformer实战(1)------词嵌入技术详解
Transformer实战(2)------循环神经网络详解
Transformer实战(3)------从词袋模型到Transformer:NLP技术演进
Transformer实战(4)------从零开始构建Transformer
Transformer实战(5)------Hugging Face环境配置与应用详解
Transformer实战(6)------Transformer模型性能评估
Transformer实战(7)------datasets库核心功能解析
Transformer实战(8)------BERT模型详解与实现
Transformer实战(9)------Transformer分词算法详解
Transformer实战(10)------生成式语言模型 (Generative Language Model, GLM)
Transformer实战(11)------从零开始构建GPT模型
Transformer实战(12)------基于Transformer的文本到文本模型
Transformer实战(13)------从零开始训练GPT-2语言模型
Transformer实战(14)------微调Transformer语言模型用于文本分类
Transformer实战(15)------使用PyTorch微调Transformer语言模型
Transformer实战(16)------微调Transformer语言模型用于多类别文本分类
Transformer实战(17)------微调Transformer语言模型进行多标签文本分类
Transformer实战(18)------微调Transformer语言模型进行回归分析
Transformer实战(19)------微调Transformer语言模型进行词元分类
Transformer实战(20)------微调Transformer语言模型进行问答任务
Transformer实战(21)------文本表示(Text Representation)
Transformer实战(22)------使用FLAIR进行语义相似性评估
Transformer实战(23)------使用SBERT进行文本聚类与语义搜索
Transformer实战(24)------通过数据增强提升Transformer模型性能
Transformer实战(25)------自动超参数优化提升Transformer模型性能
Transformer实战(26)------通过领域适应提升Transformer模型性能
Transformer实战(27)------参数高效微调(Parameter Efficient Fine-Tuning,PEFT)
Transformer实战(28)------使用 LoRA 高效微调 FLAN-T5
Transformer实战(29)------大语言模型(Large Language Model,LLM)
Transformer实战(30)------Transformer注意力机制可视化
Transformer实战(31)------解释Transformer模型决策
Transformer实战(32)------Transformer模型压缩
Transformer实战(33)------高效自注意力机制