这篇论文《V-STaR: Training Verifiers for Self-Taught Reasoners》发表于COLM 2024,提出了一种名为V-STaR的新方法,旨在通过更高效地利用模型自身生成的数据来提升大型语言模型在复杂推理任务(如数学解题和代码生成)中的性能。
论文下载地址:https://arxiv.org/pdf/2402.06457
泛读篇
现有自我改进方法(如STaR, RFT)的核心流程是让LLM为自己生成解决方案,然后仅使用那些被验证为正确 的解决方案来进一步微调模型。这种方法丢弃了大量的错误解决方案,而论文认为这些错误方案中同样包含有价值的信息(例如,错误的推理模式),未能充分利用数据。
V-STaR的核心思想是:同时利用迭代自我改进过程中产生的正确和错误解决方案 ,不仅用于训练一个更好的生成器 ,还用于训练一个验证器。
V-STaR方法详解
V-STaR的流程主要包括两个并行且迭代的训练过程:生成器训练 和验证器训练。
-
迭代数据收集与生成器训练:
-
从基础模型开始,在初始监督微调数据集上训练一个生成器。
-
在每一轮迭代中,使用当前的生成器为训练集中的每个问题生成多个解决方案。
-
通过测试用例或最终答案判断每个生成方案的正确性。
-
仅将正确的解决方案加入生成器训练缓冲区。
-
在下一轮迭代中,使用 augmented 后的缓冲区数据微调基础模型,得到一个更强的生成器。
-
这个过程反复进行,生成器随着迭代不断进步,能产生更高质量的正确和错误方案。
-
2.验证器训练:
-
在每一轮数据收集中,**将所有解决方案(无论对错)** 连同其正确性标签加入验证器训练缓冲区。
-
使用这些数据构建一个偏好数据集:对于同一个问题,将正确的方案作为"优选",错误的方案作为"非优选"。
-
采用**直接偏好优化(DPO)** 方法来训练验证器,而不是传统的基于二元分类的奖励模型方法。论文发现DPO训练验证器更有效。DPO的目标是让验证器给优选方案分配比非优选方案高得多的概率。
-
测试阶段:
-
对于一个新的问题,让最终训练好的生成器生成大量(例如128个)候选解决方案。
-
使用最终训练好的验证器为每个候选方案打分。
-
选择验证器评分最高的解决方案作为最终答案。这种方法被称为 Best-of-k。
-
关键创新与贡献
-
数据高效利用:V-STaR的核心创新在于将错误解决方案纳入训练循环,提升了数据利用效率。
-
迭代式改进:通过迭代过程,生成器和验证器相互促进。更好的生成器产生更难的"负例",从而训练出更强的验证器。
-
使用DPO训练验证器:论文证明,用DPO目标训练验证器比传统的ORM方法更有效。
-
提出可靠的Best-of-k评估公式:论文提出了一个无偏且高效的公式来准确计算Best-of-k的性能,避免了通过多次采样估算带来的高方差和计算成本。
实验结果
论文在数学推理(GSM8K, MATH子集)和代码生成(MBPP, HumanEval)任务上进行了实验,基座模型为LLaMA2和CodeLLaMA。
-
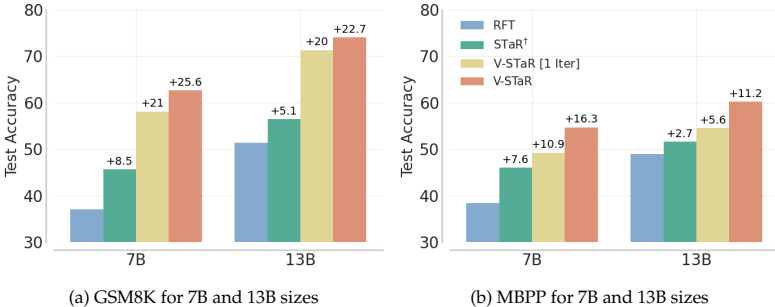
显著提升 :V-STaR显著超越了现有的自我改进方法(如STaR+, RFT)和验证方法(如ORM),在测试准确率上取得了4%到17%的绝对提升。
-
小模型媲美大模型:经过V-STaR训练的7B参数模型在GSM8K上超越了70B参数的LLaMA2(8-shot),在HumanEval上接近34B参数的CodeLLaMA(zero-shot)的性能。
-
迭代的有效性:多轮迭代的V-STaR明显优于仅进行一轮数据收集的基线方法(V-STaR1 Iter),证明了迭代过程的价值。
-
DPO的优势:DPO训练的验证器在从大量候选答案中筛选正确答案方面,性能优于ORM风格的验证器。
精读篇
第一部分:传统研究方法与局限性
如何让大语言模型(LLM)在数学推理、代码生成上做得更好?
要让 LLM 在数学和代码这种"逻辑严密、容错率低"的任务上表现更好,目前的业界共识是:不能只靠"堆参数"和"背答案",必须让模型学会"慢思考"。
1. 训练阶段:从"结果导向"转向"过程导向"
传统的 LLM 训练像教鹦鹉学舌,只要最后说对就行。但数学和代码需要逻辑链条,中间一步错,步步错。
过程奖励模型 (Process Reward Models, PRM):
原理: 以前我们只奖励模型"做对答案"(Outcome Reward Model, ORM)。现在,我们像老师改卷子一样,按步骤给分。如果模型推理了 10 步,第 3 步错了,PRM 会立刻指出来,而不是等到最后。
与 V-STaR 的关系: V-STaR 训练的验证器(Verifier)其实就是一种 PRM 的变体。通过 DPO 让验证器学会分辨"好的步骤"和"坏的步骤",这比只看最终答案有效得多。
思维链微调 (Chain-of-Thought Fine-tuning):
不再直接喂给模型 问题 -> 答案 的数据。
而是喂给它 问题 -> 详细的推导过程 -> 答案。
合成数据 : 由于高质量的推理数据(如详细的数学证明)很稀缺,现在的趋势是用强模型生成数据,然后用 V-STaR 这样的方法过滤掉错误的,把剩下的"精品过程"拿去训练小模型。
2. 推理阶段:用"时间"换"智能" (Test-time Compute)
这是 2024-2025 年最火的概念(OpenAI o1 的核心)。既然模型一次性生成的答案不一定对,那就让它在输出结果前**"多想一会儿"**。
-
思维链提示 (Chain-of-Thought, CoT):
- 最基础的方法。在 Prompt 里加上
Let's think step by step,强迫模型把隐式推理显式化。这能大幅减少计算错误。
- 最基础的方法。在 Prompt 里加上
-
思维树 (Tree of Thoughts, ToT) 与 搜索策略:
-
模型不只生成一条路,而是生成多条可能的路径。
-
如果发现某条路走不通(例如代码报错、逻辑矛盾),就回溯(Backtrack),换一条路走。这就很像人类下围棋时的"推演"。
-
-
自我修正与验证 (Self-Correction & Verification):
-
Generate-then-Verify(生成后验证): 这正是 V-STaR 论文中提到的推理策略。生成 10 个代码方案,用验证器打分,选分最高的。
-
Majority Voting(多数投票): 让模型做 100 次这道数学题,选出现次数最多的那个答案(利用统计学原理消除随机误差)。
-
3. 工具辅助:承认模型的局限性
LLM 本质是概率模型,计算 239 * 817 对它来说是预测下一个 token,而不是真正的算术运算,所以很容易"一本正经地胡说八道"。
-
代码解释器 (Code Interpreter / Sandbox):
-
这是目前提升数学/代码能力最立竿见影的方法。
-
模型不再直接给出答案,而是写一段 Python 代码来计算答案,然后在沙箱里运行代码,把运行结果作为最终回答。
-
例子: 问"斐波那契数列第 100 项是多少?",模型写个递归或循环函数运行一下,绝对不会算错。
-
现有方法局限性:
1. 自我改进方法 (Self-Improvement)
代表算法: STaR (Self-Taught Reasoner), RFT (Rejection Sampling Fine-Tuning)
局限性深度解析:数据利用的"幸存者偏差"
-
核心流程回顾:
模型就像一个学生在做题库。做完后,对着答案改卷。
-
做对了 \\rightarrow 记住这个解法(加入训练集)。
-
做错了 \\rightarrow 直接扔进垃圾桶(丢弃)。
-
-
为何这是巨大的浪费?
-
负样本不仅是垃圾,也是"错题本": 在机器学习(特别是对比学习)中,知道"什么是错的"往往比只知道"什么是对的"包含更多信息量。丢弃错误答案,意味着模型失去了学习避坑的机会。它只知道哪条路能通向终点,却不知道哪些路看似正确实则是死胡同。
-
样本效率极低 (Sample Inefficiency): 对于复杂的数学或代码问题,模型可能尝试 100 次才能蒙对 1 次。STaR 方法意味着你为了获得 1 条训练数据,浪费了 99 次的计算资源。
-
一句话痛点: 只学成功的经验,不总结失败的教训,导致学习效率低下。
2. 验证方法 (Verification)
代表算法: ORM (Outcome Reward Model), PRM (Process Reward Model)
局限性深度解析:验证能力的"天花板效应"
-
核心流程回顾: 我们要训练一个"老师"(验证器/Verifier)来给"学生"(生成器/LLM)打分。 通常的做法是:先让一个现有的模型(比如 GPT-3)生成一大堆答案,人工或者脚本标注好坏,然后拿这些数据去训练"老师"。
-
为何数据质量受限?
-
固定的生成器 = 固定的视野: 传统的验证器通常是在一个固定的模型生成的数据上训练的。如果这个生成器水平很烂(全是简单错误),验证器就只能学会识别简单错误。
-
分布偏移 (Distribution Shift): 当我们以后用这个验证器去指导一个更强的模型时,更强的模型可能会犯一些高级错误。因为验证器在训练时从未见过这种高级错误(因为它是由弱模型训练出来的),它就可能无法识别,甚至误判。
-
缺乏迭代进化: 验证器没有随着生成器的变强而变强。理想状态下,学生变强了,老师也得进修,否则老师就教不了学生了。
-
一句话痛点: 只有小学水平的错题集,训练不出能指导博士生的老师。
总结:V-STaR 是如何打破僵局的?
V-STaR 的精妙之处在于它将上述两个过程结合成了一个闭环,解决了各自的局限性:
| 现有方法的局限 | V-STaR 的解决方案 | 效果 |
|---|---|---|
| 自我改进: 丢弃错误答案 | 利用错误答案:将错误答案作为 DPO 训练中的"负样本"喂给验证器。 | 榨干了每一次生成的价值,不仅学"对",还学"辨错"。 |
| 验证方法: 数据源单一/固定 | 迭代生成:每一轮训练,生成器都会变强,从而生成更难区分的"错误答案"来磨练验证器。 | 验证器和生成器通过"左右互搏"螺旋上升,老师和学生一起进步。 |
第二部分:V-STaR 方法详解
1. 整体流程概览:双引擎驱动的螺旋上升
V-STaR 摒弃了传统的单向训练,采用了一个迭代式的闭环系统。这个系统由两个核心组件构成:
-
生成器(Generator,M):负责解题(相当于学生)。
-
验证器(Verifier,V):负责判题(相当于老师)。
核心逻辑: 每一轮迭代中,生成器产生的"作业"会被用来训练生成器自己(只看做对的题),同时也被用来训练验证器(对比做对和做错的题)。
-
生成器越强 = 生成的错误答案越具有迷惑性(Hard Negatives)。
-
错误越难辨别 = 迫使验证器的鉴别能力变得越强。
-
两者互相促进,实现共进化。
2. 迭代数据收集与生成器训练 (The Generator Loop)
这是 V-STaR 的"自我改进"部分,沿用了 STaR 的思路,但通过迭代强化了效果。
-
步骤 1:初始化
从一个基础模型(Base Model)开始,先在初始的高质量数据集上进行有监督微调(SFT),得到第 0 代生成器。
-
步骤 2:广泛采样 (Sampling)
对于训练集中的每一个问题 x,让当前的生成器生成 n个不同的答案
。通常使用较高的温度(Temperature)来保证多样性。
-
步骤 3:真值判断 (Oracle Filtering)
依靠"外部裁判"来判断对错:
-
数学题: 检查最终数值是否与标准答案一致。
-
代码题: 运行单元测试(Unit Tests),看是否通过。
-
-
步骤 4:正样本筛选
只保留那些被判定为正确的答案路径,构成生成器的微调数据集
-
步骤 5:微调迭代
使用
核心点: 随着迭代进行,生成器开始能解出上一轮解不出的难题,训练数据的覆盖面和质量不断提升。
3. 验证器训练:DPO 的巧妙应用 (The Verifier Loop)
这是 V-STaR 最大的创新点。传统的验证器通常被当作一个分类问题(这是对的吗?),而 V-STaR 把它变成了一个偏好问题(哪个更好?)。
-
数据利用:变废为宝
在生成器训练中被丢弃的错误答案,在这里成为了宝贵的资源。V-STaR 利用所有生成数据(正确 + 错误)来训练验证器。
-
构建偏好数据集 (Preference Pairs)
对于同一个问题
-
一个正确答案
-
一个错误答案
构成成对数据
-
-
训练方法:直接偏好优化 (DPO)
论文放弃了传统的二元分类(Binary Classification)或逻辑回归训练 ORM,而是直接使用 DPO (Direct Preference Optimization) 损失函数。
-
DPO 的目标:
DPO 的数学目标是最大化正确答案与错误答案之间的似然差 (Log-likelihood Gap)。
简单来说,它强迫验证器认为:在给定问题
优势(伏笔): 实验表明,DPO 训练出来的验证器比传统的 ORM 更鲁棒。因为随着生成器变强,错误答案
4. 推理阶段:Best-of-N (Generate-then-Rank)
当训练结束后,我们得到了最强的生成器和最强的验证器。在实际应用(测试)时,采用以下策略:
-
大规模生成: 给定一个新问题,让生成器生成大量的候选答案(例如 N=64 到 128 个)。
-
验证器打分: 让 DPO 训练出的验证器计算每个候选答案的"似然得分"或"奖励值"。
-
择优输出: 也就是 Best-of-N 策略。直接选取验证器评分最高的那个答案作为最终回答。
总结 V-STaR 的"独门秘籍"
如果说 STaR 是"只看标准答案的自学者",那么 V-STaR 就是"既学标准答案,又专门分析错题集的自学者"。通过 DPO 将错误答案转化为训练信号,是 V-STaR 性能超越基线的关键所在。
附:DPO讲解
DPO (Direct Preference Optimization,直接偏好优化) 是 2023 年由斯坦福大学团队提出的一种用于对齐(Align)大语言模型的技术。
在 V-STaR 这篇论文中,DPO 起到了至关重要的作用。为了让你彻底理解它,我们先看它解决了什么问题,再看它是如何工作的。
1. DPO 解决了什么问题?(取代 RLHF 中的 PPO)
在 DPO 出现之前,要让模型符合人类偏好(例如:要礼貌,不要暴力;或者在 V-STaR 中:要选对的,别选错的),通常使用 RLHF(基于人类反馈的强化学习)。
传统的 RLHF 流程非常繁琐,分为三步:
-
SFT(有监督微调): 教模型说话。
-
RM(训练奖励模型): 训练一个打分器,告诉模型哪句说得好。
-
PPO(强化学习): 用这个打分器通过强化学习不断调整模型参数。
痛点: 第 3 步的 PPO 非常不稳定,计算成本高,超参数极难调试,经常训练失败。
DPO 的出现: 它跳过了训练奖励模型和强化学习这两个步骤,直接通过数据来优化模型。
2. DPO 是如何工作的?(核心原理)
DPO 的核心洞察是数学上的推导:我们不需要显式地训练一个奖励模型,因为语言模型本身就可以隐式地代表奖励。
它的训练过程非常直观:
-
输入数据: 成对的数据
-
-
-
-
-
优化目标:
DPO 的损失函数直接调整模型的权重,目的是:在保持模型不过度偏离原始能力的前提下,让模型生成
简单公式理解:
这意味着:只要好答案的得分比坏答案高,损失就小;反之,损失就大。