
1. 一段话总结
本文提出FinGPT ------一款由AI4Finance Foundation主导开发的开源金融大语言模型(FinLLMs),旨在解决金融领域高时间敏感性、高动态性、低信噪比(SNR) 的核心挑战。与BloombergGPT等专有模型(训练成本约 300万** )不同,FinGPT以**数据中心approach** 为核心,构建包含数据来源层、数据工程层、LLMs层、任务层、应用层的端到端框架,通过**Low-rank Adaptation(LoRA)** 轻量级微调(单次成本约 **300 ,可训练参数仅8.3M )、Reinforcement Learning on Stock Prices(RLSP) 及Retrieval Augmented Generation(RAG) 优化模型性能,在金融情感分析任务中以82.1%的准确率 超越FinBERT、ChatGPT等基线模型,最终目标是民主化金融数据与FinLLMs,并通过开源社区(代码仓库:https://github.com/AI4Finance-Foundation/FinGPT、https://github.com/AI4Finance-Foundation/FinNLP)推动开放金融的创新与协作。
2. 思维导图(mindmap)
mindmap
## **FinGPT:开源金融大语言模型(FinLLMs)**
- 研究背景与挑战
- 金融领域独特挑战
- 高时间敏感性(市场信息窗口期短)
- 高动态性(需频繁更新模型,传统重训不现实)
- 低信噪比(有用信息隐藏于噪声数据)
- 专有模型局限(BloombergGPT)
- 训练成本高(约$300万/次)
- 数据与训练协议不透明
- accessibility受限
- 核心定位与贡献
- 定位:端到端开源FinLLMs框架
- 三大核心贡献
- 数据中心approach(强调数据清洗与预处理)
- 五层全栈框架(覆盖数据到应用全流程)
- 民主化FinLLMs(开放数据与模型,降低使用门槛)
- 端到端框架结构
- 数据来源层:多源数据采集(新闻、社交媒體、监管文件等)
- 数据工程层:实时NLP处理(清洗、分词、向量嵌入等)
- LLMs层:轻量级微调(LoRA/QLoRA、RLSP、RAG)
- 任务层:基础基准任务(摘要、NER、情感分析等)
- 应用层:实际金融场景(智能投顾、量化交易、ESG评分等)
- 关键技术
- 数据处理:实时数据curation pipeline(含自标注标签生成)
- 模型微调:LoRA(减少99.9%可训练参数)、RLSP(用股价作反馈)
- 增强生成:RAG(结合检索与LLM,提升输出准确性)
- 实验验证(金融情感分析)
- 数据集:620,000+条清洁金融新闻(2016-2024年)
- 基线对比:FinBERT、ChatGPT、Llama3.1-8B
- 核心结果:SFT+RLSP配置达82.1%准确率、80.9%Macro-F1
- 潜在应用场景
- 智能投顾(个性化财务建议)
- 量化交易(生成交易信号)
- 风险管控(欺诈检测、AML)
- 企业服务(ESG评分、M&A预测)
- 未来工作
- 建立行业级FinLLMs标准
- 优化参数高效微调方法(LoRA/QLoRA)
- 扩展统一数据curation pipeline3. 详细总结
1. 研究背景与金融领域挑战
金融领域对大语言模型(LLMs)需求迫切,但存在三大核心挑战:
- 高时间敏感性:市场新闻、政策等信息窗口期极短,需实时捕捉以辅助投资决策(如"alpha收益"获取);
- 高动态性 :新闻、社交舆情等数据持续更新,传统模型全量重训成本高(如BloombergGPT需130万GPU小时)且不现实;
- 低信噪比(SNR):金融数据中有用信息常被大量噪声掩盖,需专业技术提取关键内容。
同时,现有专有金融LLMs(如BloombergGPT)存在数据封闭、训练不透明、使用成本高(约$300万/次训练) 等问题,亟需开源替代方案以民主化金融数据与模型。
2. FinGPT核心定位与核心贡献
- 核心定位 :由AI4Finance Foundation(非营利开源组织)主导的端到端开源金融大语言模型框架,旨在降低FinLLMs使用门槛,推动开放金融创新。
- 三大核心贡献 :
- 数据中心approach:将数据采集、清洗、预处理作为核心,针对金融数据特性设计专属处理流程;
- 全栈五层框架:覆盖"数据-工程-模型-任务-应用"全流程,支持灵活定制;
- 民主化FinLLMs:开源代码(仓库:https://github.com/AI4Finance-Foundation/FinGPT、https://github.com/AI4Finance-Foundation/FinNLP)与数据,允许用户基于私有数据微调,适配个性化需求。
3. FinGPT端到端框架结构(五层)
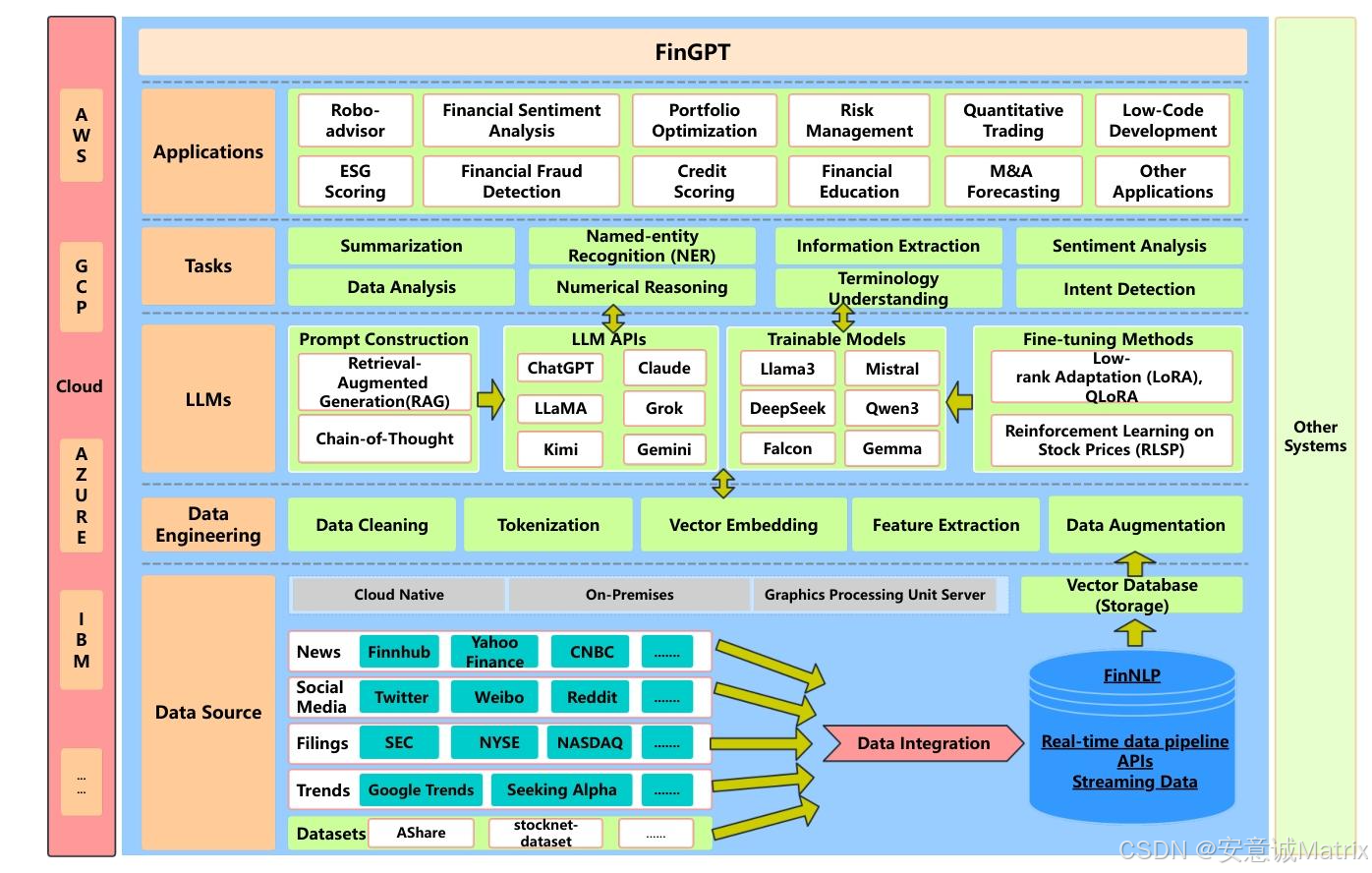
| 框架层级 | 核心功能 | 关键技术/特性 |
|---|---|---|
| 数据来源层 | 覆盖全市场数据,解决时间敏感性问题 | 数据源:路透社/CNBC等新闻、Twitter/微博等社交平台、SEC/NYSE等监管文件、Seeking Alpha等趋势平台 |
| 数据工程层 | 实时NLP处理,解决低信噪比与时间敏感性问题 | 步骤:数据清洗(去噪声/补缺失)→ 分词 → 向量嵌入(含实体与时间元数据)→ 特征提取 → 数据增强 |
| LLMs层 | 轻量级微调,解决金融数据动态性问题 | 方法:LoRA/QLoRA(轻量适配)、RLSP(股价反馈强化)、RAG(检索增强生成)、Prompt Engineering |
| 任务层 | 提供基础基准任务,支撑性能评估与对比 | 任务:摘要生成、命名实体识别(NER)、信息提取、情感分析、数值推理、术语理解等 |
| 应用层 | 落地金融实际场景,展示模型实用价值 | 应用:智能投顾、量化交易、ESG评分、欺诈检测、KYC自动化、金融教育等 |
4. 关键技术与方法
-
数据中心方法:
- 针对不同数据源特性定制处理:如金融新闻(时效性优先)、监管文件(可靠性优先)、社交媒体(实时 sentiment 捕捉);
- 自标注标签生成:用新闻发布后股票价格相对变化(r) 作为标签,按阈值分为正(r>θₚ)、负(r<-θₙ)、中性(|r|≤θ),避免人工标注成本。
-
轻量级微调技术(LoRA):
- 原理:通过低秩矩阵分解,将可训练参数从Llama3.1-8B的80亿 降至8.3M(仅占原模型0.1%);
- 成本优势:单次微调成本约**300\*\*,较BloombergGPT(300万)降低约1000倍,支持频繁更新以适配金融动态。
-
Reinforcement Learning on Stock Prices(RLSP):
- 替代传统RLHF(人类反馈强化),以股票价格变化(Δp) 作为奖励信号(R=f(Δp)),使模型输出与市场实际反应对齐;
- 优势:客观量化、实时反馈,提升模型对金融事件的推理能力(如识别"特斯拉降价"的负面市场含义)。
-
Retrieval Augmented Generation(RAG):
- 结合"检索上下文"与"LLM生成",从向量数据库中调取相关金融文档辅助生成,避免模型"幻觉",提升输出准确性与相关性。
5. 实验验证:金融情感分析任务
5.1 实验设置
- 数据集:620,000+条清洁金融新闻(2016-2024年),来源含CNBC、路透社、雅虎财经等,标签由"股价变化自标注"生成;
- 模型配置:基础模型为Llama3.1-8B-Instruct,分两阶段微调:① LoRA-SFT(rank=8,α=16,批次=64,学习率=2e-4,epoch=3);② RLSP(以股价变化为奖励);
- 基线模型:ChatGPT(零样本)、Llama3.1-8B(零样本)、FinBERT;
- 评估指标:准确率(Acc.)、Macro-F1、各类别F1(正/负/中性)。
5.2 实验结果
| 模型 | 准确率(Acc.) | Macro-F1 | 正向F1(Pos-F1) | 负向F1(Neg-F1) | 中性F1(Neu-F1) |
|---|---|---|---|---|---|
| ChatGPT(零样本) | 63.4 | 61.7 | 64.0 | 59.1 | 62.0 |
| Llama3.1-8B(零样本) | 57.9 | 54.4 | 56.1 | 53.2 | 54.0 |
| FinBERT | 71.2 | 69.9 | 73.0 | 69.1 | 67.5 |
| FinGPT(LoRA-SFT) | 78.8 | 77.3 | 79.6 | 76.8 | 75.4 |
| FinGPT(SFT+RLSP) | 82.1 | 80.9 | 83.4 | 81.5 | 77.8 |
5.3 消融实验(验证关键组件作用)
| 配置 | Macro-F1 | 结论 |
|---|---|---|
| Base Llama3.1-8B | 54.4 | 基础模型金融适配性差 |
| + LoRA-SFT | 77.3 | LoRA是金融适配核心 |
| + RLSP | 80.9 | RLSP进一步提升市场对齐度 |
6. 潜在应用场景
FinGPT可覆盖多类金融场景,核心应用包括:
- 智能投顾(Robo-advisor):基于用户风险偏好提供个性化财务建议,减少人工依赖;
- 量化交易:生成实时交易信号,辅助投资决策;
- 风险管控:欺诈检测(识别异常交易模式)、反洗钱(AML,分析资金流向);
- 企业服务:ESG评分(分析企业公开报告)、M&A预测(基于公司财务数据与市场趋势);
- 基础服务:KYC自动化(验证身份与文档)、金融教育(简化专业术语解释)。
7. 未来工作
- 建立行业级FinLLMs标准,统一数据与评估基准;
- 优化参数高效微调方法(如LoRA/QLoRA),支持更多金融机构低成本定制;
- 扩展统一数据curation pipeline,提升数据质量与标准化程度;
- 完善开源生态,提供更多可复现基准与透明工作流。
8. 免责声明
- 代码仅用于学术目的(MIT教育许可证);
- 内容不构成金融建议,不推荐实际资金交易;
- 实际投资需咨询专业顾问。
4. 关键问题
问题1:FinGPT相比BloombergGPT等专有金融大语言模型,核心竞争优势是什么?
答案:FinGPT的优势集中在"可及性、成本、灵活性"三大维度:
- 开源可及性:BloombergGPT数据与训练协议封闭,仅内部使用;FinGPT开源代码(双仓库)与数据处理流程,允许研究者/企业自由访问、修改,推动协作创新;
- 成本优势 :BloombergGPT单次训练需130万GPU小时,成本约**300万\*\*;FinGPT采用LoRA轻量级微调,单次成本仅\*\*300**,降低约1000倍,支持频繁更新以适配金融动态;
- 定制灵活性:BloombergGPT为通用金融模型,难以适配个性化需求;FinGPT支持用户基于私有数据微调(如企业内部财报),并通过RLSP(股价反馈)与RAG(检索增强)优化特定场景性能。
问题2:FinGPT的"实时数据curation pipeline"包含哪些关键步骤?为何该pipeline对金融领域至关重要?
答案:
-
关键步骤:该pipeline针对金融数据"实时性、低信噪比"设计,核心步骤为:
- 数据清洗:去除噪声(如无关文本)、处理缺失值、文本归一化(如小写);
- 分词(Tokenization):实时将文本流拆解为模型可识别的单元;
- 向量嵌入:用领域适配模型将文本编码为含"实体(如股票代码)、时间元数据"的语义向量,存入向量数据库;
- 特征提取:用TF-IDF、Word2Vec等技术提取关键特征;
- 数据增强:生成模拟金融数据,提升模型鲁棒性。
-
金融领域必要性:
- 解决"高时间敏感性":实时处理确保模型捕捉市场窗口期信息(如新闻发布后股价波动),避免延迟导致的决策失效;
- 解决"低信噪比":通过清洗与特征提取过滤噪声,确保模型基于有效信息学习,提升金融任务(如情感分析)准确性。
问题3:FinGPT在金融情感分析任务中表现优于FinBERT、ChatGPT的核心原因是什么?
答案:性能优势源于"数据标签、模型适配、反馈机制"三大设计创新:
- 市场驱动的自标注标签:传统模型(如FinBERT)依赖人工标注(成本高、主观性强),ChatGPT零样本无金融适配标签;FinGPT用"新闻发布后股票价格相对变化"作为自标注标签,直接对齐市场真实反应,提升标签客观性;
- LoRA轻量级金融适配:基础模型(如Llama3.1-8B)无金融领域知识,FinGPT通过LoRA将可训练参数降至8.3M(仅0.1% of 8B模型),高效注入金融语义,避免全量重训成本;
- RLSP市场反馈机制:相比传统监督学习(如FinBERT),FinGPT新增RLSP(以股价变化为奖励),使模型输出与市场实际反应进一步对齐(如识别"特斯拉降价"的负面金融含义),最终实现82.1%准确率(较FinBERT提升10.9个百分点)。