一、深度学习的介绍
深度学习(DL, Deep Learning)是机器学习(ML, Machine Learning)领域中一个新的研究方向。是一种人工智能的子领域,它基于人工神经网络的概念和结构,通过模拟人脑的工作方式来进行机器学习。深度学习的主要特点是使用多层次的神经网络来提取和学习数据中的特征,并通过反向传播算法来优化网络参数,从而实现对复杂数据的建模与分类。深度学习在图像识别、语音识别、自然语言处理等领域取得了显著的成果,并被广泛应用于各种领域。
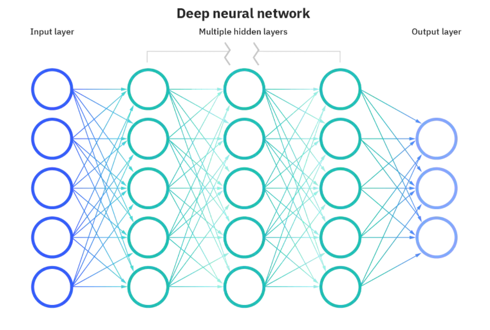
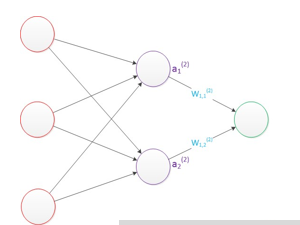
神经网络是一种由多个神经元(或称为节点)组成的计算模型,它模拟了生物神经系统中神经元之间的连接方式。神经网络有输入层、隐藏层和输出层组成,其中输入层用于接收外界的输入信号,输出层用于输出预测结果,隐藏层则用于处理输入信号并产生中间结果。
1、神经网络构造
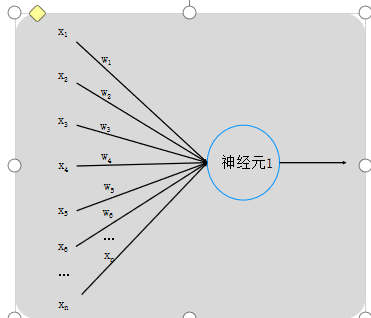
神经元1为输入层,而外部传入的x1、x2、x3、x4、x5、......全部都是外界即将传入神经元的电信号,这些电信号在传入途中可能会有所损耗,而损耗完剩下的才会传入神经元,这些传入的实际信号就用w1x1、w2x2、w3x3、w4x4、w5x5、......来表示,w叫做权重。
神经网络:每个节点代表一种特定的是由大量的节点(或称"神经元")和之间相互的联接构成。
输出函数:称为激励函数、激活函数(activation function)。
每两个节点间的联接都代表一个对于通过该连接信号的加权值,称之为权重,这相当于人工神经网络的记忆。
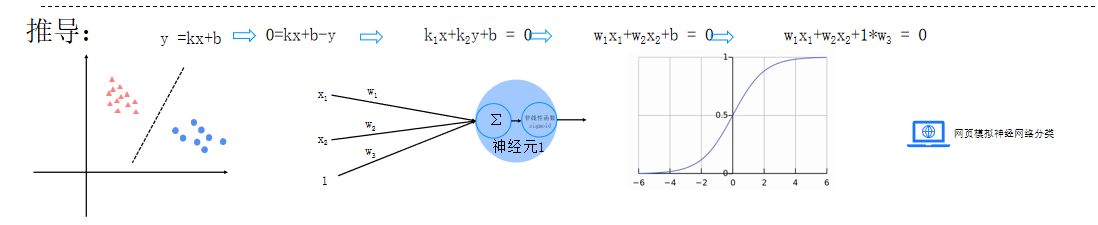
推导
需要记忆:
1、设计一个神经网络时,输入层与输出层的节点数往往是固定的,中间层则可以自由指定;
2、神经网络结构图中的拓扑与箭头代表着预测过程时数据的流向,跟训练时的数据流有一定的区别;
3、结构图里的关键不是圆圈(代表"神经元"),而是连接线(代表"神经元"之间的连接)。每个连接线对应一个不同的权重(其值称为权值),这是需要训练得到的。
中间层该如何确定
输入层的节点数:与特征的维度匹配
输出层的节点数:与目标的维度匹配。
中间层的节点数:目前业界没有完善的理论来指导这个决策。一般是根据经验来设置。较好的方法就是预先设定几个可选值,通过切换这几个值来看整个模型的预测效果,选择效果最好的值作为最终选择。
2、感知器
由两层神经元组成的神经网络--"感知器"(Perceptron),感知器只能线性划分数据。
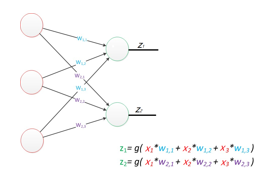
公式是线性代数方程组,因此可以用矩阵乘法来表达这两个公式
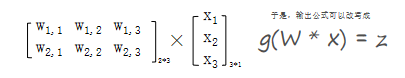
输出的结果与训练集标签进行损失函数计算,与逻辑回归基本一致。
神经网络的本质:通过参数与激活函数来拟合特征与目标之间的真实函数关系。但在一个神经网络的程序中,不需要神经元和线,本质上是矩阵的运算,实现一个神经网络最需要的是线性代数库。
3.多层感知器
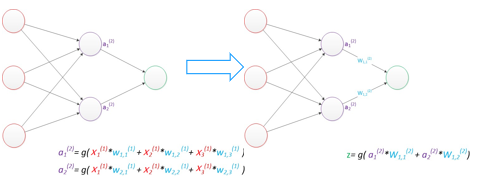
增加了一个中间层。即隐含层,它是神经网络可以做非线性分类的关键
假设我们的预测目标是一个向量,那么与前面类似,只需要在"输出层"再增加节点即可。
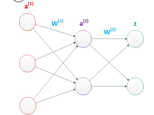
偏置
在神经网络中需要默认增加偏置神经元(节点),这些节点是默认存在的。 它本质上是一个只含有存储功能,且存储值永远为1的单元。 在神经网络的每个层次中,除了输出层以外,都会含有这样一个偏置单元。
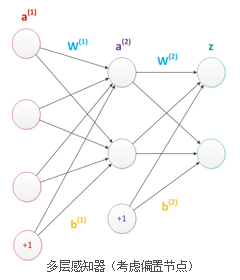
偏置节点没有输入(前一层中没有箭头指向它)。 一般情况下,我们都不会明确画出偏置节点
4、训练方法-损失函数
模型训练的目的:使得参数尽可能的与真实的模型逼近。
具体做法:
1、首先给所有参数赋上随机值。我们使用这些随机生成的参数值,来预测训练数据中的样本。 2、计算预测值为yi,真实值为y。那么,定义一个损失值loss,损失值用于判断预测的结果和真实值的误差,误差越小越好。
常用的损失函数:
1.0-1损失函数
🔹 公式
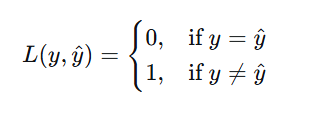

🔹 特点与用途
-
离散型损失,非连续不可导,不能直接用于梯度下降。
-
主要用于分类任务,直接度量分类错误率。
-
实际训练中很少直接优化它(因为无法求导),但在理论分析和模型评估中常见
2.均方差损失
🔹 公式
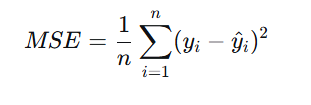
🔹 特点与用途
-
连续可导,对异常值敏感(因为平方会放大大误差)。
-
常用于回归任务,假设误差服从高斯分布时,MSE 是极大似然估计的结果。
-
在神经网络中,如果最后一层是线性激活,常用 MSE 作为损失函数。
3.平均绝对差损失
🔹 公式
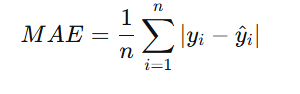
🔹 特点与用途
-
对异常值不敏感,比 MSE 稳健。
-
在零点不可导,但可用次梯度方法优化。
-
常用于回归任务,尤其是在数据含有噪声或离群点时。
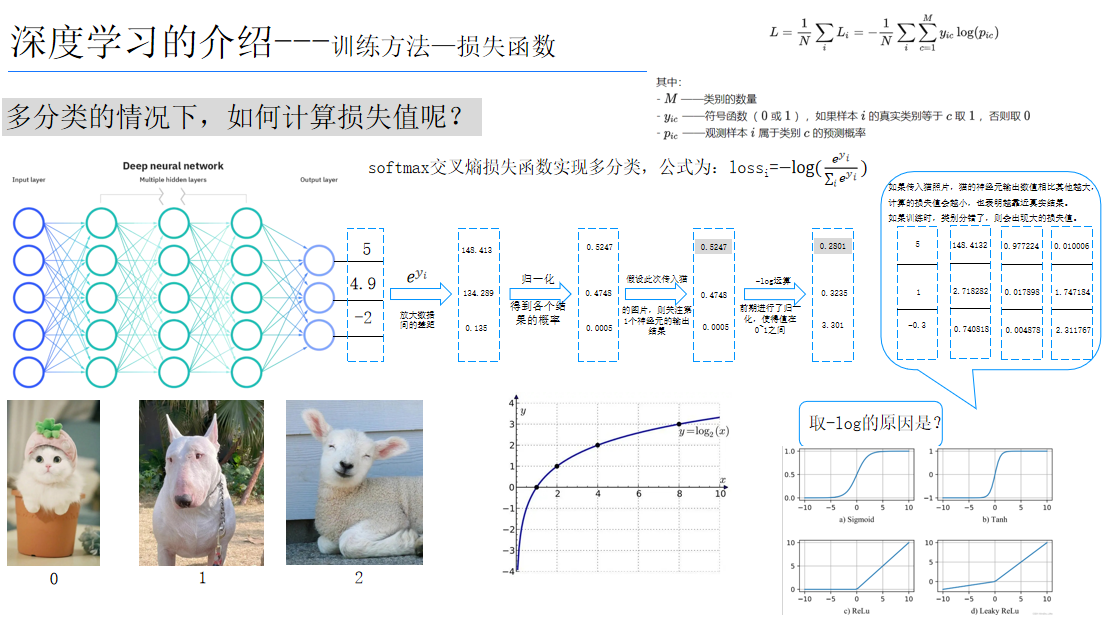
4.交叉熵损失
🔹 公式(二分类)
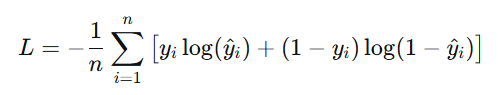
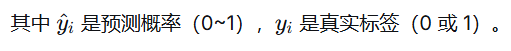
🔹 多分类(Softmax + Cross-Entropy)
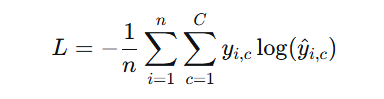

🔹 特点与用途
-
源自信息论,衡量两个概率分布的差异。
-
用于分类任务,特别是神经网络中配合 Softmax/Sigmoid 输出。
-
在概率预测上比 MSE 更合适,梯度形式利于优化。
5.合页损失
🔹 公式(用于 SVM 的二分类)
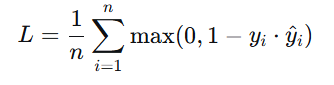

🔹 特点与用途
-
用于支持向量机(SVM),鼓励间隔最大化。
-
对分类正确的样本(yiy^i≥1yiy^i≥1)损失为 0,否则线性增加。
-
不是概率输出,常用于最大间隔分类。
5、神经网络构造--正则化惩罚

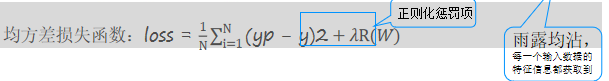
正则化惩罚的功能:主要用于惩罚权重参数w,一般有L1和L2正则化
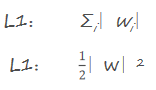
至此,整个神经网络从前往后数据计算方法已经全部完成,但还没有实现w的更新方法
6、神经网络构造--梯度下降
1.偏导数
我们知道一个多变量函数的偏导数,就是它关于其中一个变量的导数而保持其他变量恒定。该函数的整个求导:
例如:计算像 f(w0,w1)=w0x1²* w1x2 这样的多变量函数的过程可以分解如下:
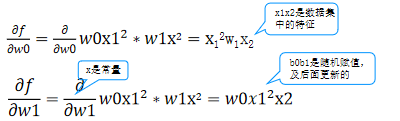
2.梯度
梯度可以定义为一个函数的全部偏导数构成的向量,梯度向量的方向即为函数值增长最快的方向
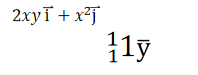
3.梯度下降法
是一个一阶最优化算法,通常也称为最陡下降法 ,要使用梯度下降法找到一个函数的局部极小值
步长(学习率) :梯度可以确定移动的方向。学习率将决定我们采取步长的大小。不易过小和过大 **如何解决全局最小的问题:**产生多个随机数在不同的位置分别求最小值。
7、BP神经网络
BP(Back-propagation,反向传播)前向传播得到误差,反向传播调整误差,再前向传播,再反向传播一轮一轮得到最优解的。
步骤:
1.计算正向传播输出的结果
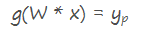
2.计算损失函数

3.计算w值的梯度下降
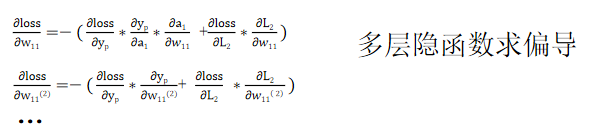
4、误差反向传播
将每个维度偏导数导入本次的w值,初次w值为随机初始化,并乘以步长,即得到新的w值。
5.循环调整w的值,直到损失值小于允许的范围
8、相关代码
python
import torch
import torchvision
import torchaudio
print(torch.__version__)#1.X
print(torchvision.__version__)#1.X
print(torchaudio.__version__)
'''mnist包含70.000张手写数字图像:60.000张用于训练,10.000张用于测试
图像是灰度的,28x28像素的,并且居中的,以减少预处理和加快运行
'''
import torch
from torch import nn#导入神经网络模块,
from torch.utils.data import DataLoader#数据包管理工具,打包数据
from torchvision import datasets # 封装了很多与图像相关的模型,数据集
from torchvision.transforms import ToTensor
#数据转换,张量,将其他类型的数据转换为tensor张量,numpy array
'''下载训练数据集(包含训练图片+标签)'''
training_data= datasets.MNIST( #跳转到函数的内部源代码,pycharm 按下ctrl +鼠标点击
root="data",#表示下载的手写数字 到哪个路径。60000
train=True,#读取下载后的数据 中的 训练集
download=True,#如果你之前已经下载过了,就不用再下载
transform=ToTensor(),#张量,图片是不能直接传入神经网络模型
)#对于pytorch库能够识别的数据一般是tensor张量
# datasets.MNIST的参数:
# root(string):表示数据集的根目录
# train(bool,optional):如果为true,则从trainingpt创建数据集,否则从test.pt创建数据集
# download(bool,optional):如果为true,则从internet下载数据集并将其放入根目录,如果数据集已经下载,则不会再次下载
# transform(callable,optional):接收pil图片并返回转换后版本图片的转换函数
'''下载测试数据集(包含训练图片+标签)'''
test_data = datasets.MNIST(
root="data",
train=False,
download=True,
transform=ToTensor(),#Tensor是在深度学习中提出并广泛应用的数据类型,它与深度学习框架(如 PyTorch、TensorFlow)紧密集成,方便进行神经网络的训练和)
)#NumPy 数组只能在CPU上运行。Tensor可以在GPU上运行,这在深度学习应用中可以显著提高计算速度。
print(len(training_data))
'''展示手写字图片,把训练数据集中前19000张图片展示一下'''
from matplotlib import pyplot as plt
figue=plt.figure()
for i in range(9):
img,label=training_data[i+59000]#提取第59000张图片
figue.add_subplot(3,3,i+1)#图像窗口中创建多个小窗口,小窗口用于显示图片
plt.title(label)
plt.axis("off")#plt.show()#显示矢量
plt.imshow(img.squeeze(),cmap="gray")#plt.imshow()将NumPy数组data中的数据显示为图像,并在图形窗口中显示该图像
a=img.squeeze()# img.squeeze()从张量imng中去掉维度为1的。如果该维度的大小不为1则张量不会改变。#cmap="gray"表示使用灰度色彩映射来显示图像。
# plt.show()
'''创建数据dataloader(数据加载器)
batch_size:将数据集分成多分,每一份为batch------size个数据
优点:可以减少内存的使用,提高训练速度'''
train_dataloader = DataLoader(training_data, batch_size=64)
#64张图片为一个包,更换批次的大小也可以调整最后准确率(2的指数)
test_dataloader = DataLoader(test_data, batch_size=64)
for X,y in test_dataloader:#X是表示打包好的每一个数据包
print(f"Shape of X[N,C,H,W]:{X.shape}")
print(f"Shape of y:{y.shape} {y.dtype}")
break
'''判断当前设备是否支持GPU,其中mps是苹果m系列芯片的GPU'''#返回cuda,mps,cpu m1,m2,集显cpu+gpu rtx3060
device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else 'cpu'
print(f"Using {device} device")#字符串格式化。CUDA驱动软件的功能,pytorch能够去执行cuda的命令,cuda通过GPU指令集去控制GPU
#神经网络的模型也需要传入到GPU,1个batchsize的数据集也需要传入GPU才可以进行训练
'''定义神经网络 类的继承'''
class NeuralNetwork(nn.Module):#通过调用类的形式来使用神经网络,神经网络的模型,nn.module
def __init__(self):#python的基础关于类,self类自己本身
super().__init__()#继承的父类初始化
self.a = 10
self.flatten=nn.Flatten()#展开,创建一个展开对象flatten
self.hidden1=nn.Linear(28*28,out_features=128)#第一个参数:有多少个神经元传入进来,第二个参数:有多少个数据
self.hidden2=nn.Linear(in_features=128,out_features=256)
self.hidden3=nn.Linear(in_features=256,out_features=512)
self.out=nn.Linear(in_features=512,out_features=10)#输出必须和标签的类别相同,输入必须是上一层的神经元个数
self.dropout=nn.Dropout(0.2)
def forward(self,x):#前向传播,你要告诉他数据的流向,视神经网络层连接起来,函数名称不能改。
# x= self.flatten(x)#图像进行展开
# x= self.hidden1(x)
# x= torch.sigmoid(x)#激活函数,torch使用的relu函数relu:tanh
# x= self.hidden2(x)
# x= torch.sigmoid(x)
# x= self.out(x)
x= self.flatten(x)#图像进行展开
x= torch.relu(self.hidden1(x))#图像进行展开
x= self.dropout(x)
x= torch.relu(self.hidden2(x))#激活函数,torch使用的relu函数relu:tanh
x= self.dropout(x)
x= torch.relu(self.hidden3(x))
x= self.out(x)
return x
model =NeuralNetwork().to(device)#把刚刚创建的模型传入到GpU
print(model)
def train(dataloader,model,loss_fn,optimizer):
model.train()#告诉模型,我要开始训练,模型中w进行随机化操作,已经更新w,在训练过程中,w会被修改的
#pytorch提供2种方式来切换训练和测试的模式,分别是:model.train()和model.eval()
#一般用法是:在训练开始之前写上model.trian(),在测试时写上model.eval()
batch_size_num=1#统计训练的batch数量
for X,y in dataloader:#其中batch为每一个数据的编号
X,y = X.to(device),y.to(device) # 把训练数据集和标签传入cpu或GPU
pred = model.forward(X)#.forward可以被省略,父类中已经对此功能进行了设置,
loss = loss_fn(pred,y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_value = loss.item()
if batch_size_num %100==0:
print(f"loss:{loss_value:>7f} [number:{batch_size_num}]")
batch_size_num +=1
def test (dataloader,model,loss_fn):
'''测试函数'''
size=len(dataloader.dataset)
num_batchs=len(dataloader)
model.eval()
test_loss, correct = 0,0
with torch.no_grad():
for X,y in dataloader:
X,y = X.to(device),y.to(device)
pred = model.forward(X)
test_loss += loss_fn(pred,y).item() # test_loss是会自动累加每一个批次的损失值
correct +=(pred.argmax(1)== y).type(torch.float).sum().item() # 标量
a=(pred.argmax(1)== y) # dim=1表示每一行中的最大值对应的索引号,dim=日表示每一列中的最大值对应的索引号
b=(pred.argmax(1)== y).type(torch.float)
test_loss /= num_batchs
correct /= size
print(f"结果: \n Accuracy :{(100*correct)}%,Avg loss:{test_loss}")
loss_fn=nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(),lr=0.1)#尝试不同的值可以确保最后的准确率
#SGD改为Adom优化器(通常效果更好)
# train(train_dataloader,model,loss_fn,optimizer)
# test(test_dataloader,model,loss_fn)
epochs=10
for t in range(epochs):
print(f"Epoch{t+1}\n开始训练")
train(train_dataloader,model,loss_fn,optimizer)
print("训练结束!")
test(test_dataloader,model,loss_fn)