Freebase + Virtuoso 大规模导入实战:切片 Chunk、调大缓存、脚本化监控进度(可复现)
在 KBQA / KGQA 工作流中,Freebase(尤其是 WebQSP、CWQ 生态)仍然被广泛使用。Virtuoso 是最经典的 Freebase/SPARQL 本地部署方案之一,但一旦进入"百 GB 级 RDF 导入",通常会遇到三个高频痛点:
- 单文件过大,中断后难以恢复 :崩溃/重启后
ll_state可能卡住,无法可靠断点续跑; - 默认缓存极小,I/O 等待严重 :典型表现是日志里反复出现
Write wait on column page ...,导入极慢甚至更容易异常; - 缺乏可观测性:导入到底在推进还是卡住,只能靠猜,排查成本极高。
本文给出一套可直接复现的解决方案:切片(chunk 化)+ 缓存参数调优 + 监控脚本。你只需按章节顺序执行,每一步都有"检查点"确认是否正确。
前置部署过程可参考上一篇:Freebase + Virtuoso 部署全流程(含踩坑排查与可复现验证)。
0. Virtuoso 导入机制:你需要掌握的最小知识
Virtuoso 的 bulk loader 典型流程只有三步:
ld_dir(<目录>, <通配符>, <graph>):将目录中匹配的 RDF 文件入队 到DB.DBA.LOAD_LISTrdf_loader_run():启动 loader,从LOAD_LIST中取任务导入- 使用 SQL /
status()/ SPARQL 验证进度与结果
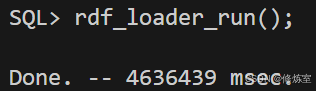
核心事实:rdf_loader_run() 很快返回不代表导入完成。
导入是否真的在跑,必须看 LOAD_LIST 的状态统计和 status() 的运行语句。
1) 为什么一定要"切片(chunk 化)"导入?
过滤后的 Freebase(例如 FilterFreebase.nt)往往是 100GB+ 的单文件。单文件导入的两个硬伤:
- 中断恢复困难 :Virtuoso bulk loader 不会可靠记录"读到文件哪个 offset/哪一行"。一旦崩溃或重启,很容易出现
ll_state=1卡住但导入线程不再推进。 - 故障不可控:哪怕只存在极少量坏行/坏片段,单文件策略也会导致"整包失败或整包重跑",成本极高。
chunk 化的工程收益非常明确:
- 可恢复:失败只影响一个 chunk(例如 1GB),重跑成本可控;
- 可定位:哪个 chunk 出错就处理哪个 chunk;
- 可观测:done/pending 的变化就是进度条;
- 可扩展:后续可以分批、甚至在条件允许时做并行策略。
2) Freebase .nt 大文件切片(推荐 0.5--2GB/片)
假设你已经得到过滤后的 N-Triples 文件:
text
/home/liang/PoG/Preprocessing/FilterFreebase_dir/FilterFreebase.nt2.1 使用 split -C 按大小切片(保证按行切,不会把三元组切断)
bash
mkdir -p /home/liang/PoG/Preprocessing/FilterFreebase_chunks
# 以 1024MB 为例;-d 数字后缀;-a 4 四位编号
split -C 1024m -d -a 4 \
/home/liang/PoG/Preprocessing/FilterFreebase_dir/FilterFreebase.nt \
/home/liang/PoG/Preprocessing/FilterFreebase_chunks/fb_
# 统一加 .nt 后缀,便于 ld_dir 用 *.nt 一把匹配
for f in /home/liang/PoG/Preprocessing/FilterFreebase_chunks/fb_*; do
mv "$f" "$f.nt"
done2.2 切片后的自检(强烈建议做;这是后续排查的"锚点")
bash
# chunk 数量
ls -1 /home/liang/PoG/Preprocessing/FilterFreebase_chunks/*.nt | wc -l
# 抽查 N-Triples 格式:每行一个三元组,末尾有 .
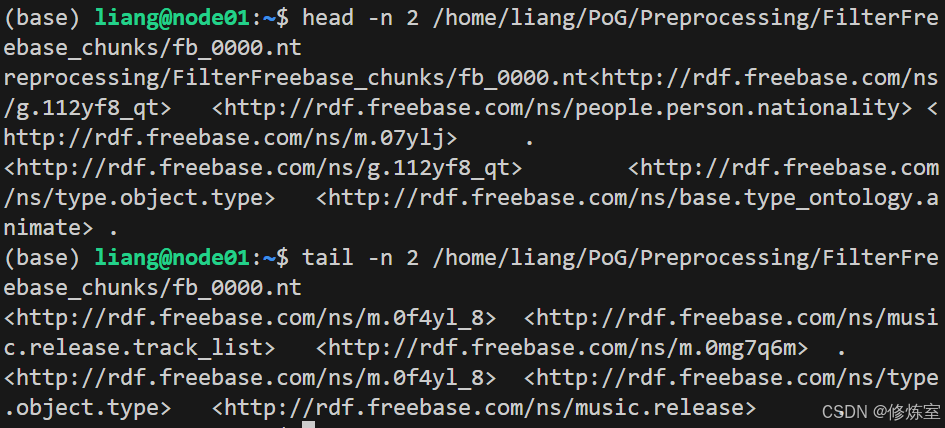
head -n 2 /home/liang/PoG/Preprocessing/FilterFreebase_chunks/fb_0000.nt
tail -n 2 /home/liang/PoG/Preprocessing/FilterFreebase_chunks/fb_0000.nt- 图 1:
ls | wc -l显示 chunk 数量

- 图 2:
head/tail展示 N-Triples 行尾.的格式
3) 调大 Virtuoso 缓存:让导入从"能跑"变成"跑得快、跑得稳"
Virtuoso 默认配置里常见:
ini
;NumberOfBuffers = 10000
;MaxDirtyBuffers = 6000这对百 GB 级导入几乎必然导致:
- 大量刷盘等待(日志里反复出现
Write wait on column page ...) - 导入速度极慢
- 更容易触发异常退出或不一致问题
3.1 Virtuoso 官方 ini 的推荐档位(直接来自 sample 注释)
当数据量很大时,Virtuoso 推荐使用可用内存的 2/3~3/5 作为进程内存,并尽可能在多磁盘上条带化存储(多盘/RAID 环境通常更有优势)。
你可以直接根据机器内存选择档位。以下为官方 sample 的典型配置段(原样保留):
ini
;; When running with large data sets, one should configure the Virtuoso
;; process to use between 2/3 to 3/5 of free system memory and to stripe
;; storage on all available disks.
;; Uncomment next two lines if there is 2 GB system memory free
;NumberOfBuffers = 170000
;MaxDirtyBuffers = 130000
;; Uncomment next two lines if there is 4 GB system memory free
;NumberOfBuffers = 340000
; MaxDirtyBuffers = 250000
;; Uncomment next two lines if there is 8 GB system memory free
;NumberOfBuffers = 680000
;MaxDirtyBuffers = 500000
;; Uncomment next two lines if there is 16 GB system memory free
;NumberOfBuffers = 1360000
;MaxDirtyBuffers = 1000000
;; Uncomment next two lines if there is 32 GB system memory free
;NumberOfBuffers = 2720000
;MaxDirtyBuffers = 2000000
;; Uncomment next two lines if there is 48 GB system memory free
;NumberOfBuffers = 4000000
;MaxDirtyBuffers = 3000000
;; Uncomment next two lines if there is 64 GB system memory free
;NumberOfBuffers = 5450000
;MaxDirtyBuffers = 4000000
;; Note the default settings will take very little memory
;; but will not result in very good performance
;NumberOfBuffers = 10000
;MaxDirtyBuffers = 6000实战建议:先按 sample 选择一个"保守但有效"的档位(例如 64GB 档位),稳定后再考虑进一步上调;不要一步到位拉满。
3.2 参数含义与内存估算(用最直观的方式记住)
- Virtuoso 的 buffer 是"数据库页缓存",每页通常 8KB
- 近似内存占用:
NumberOfBuffers × 8KB
示例:
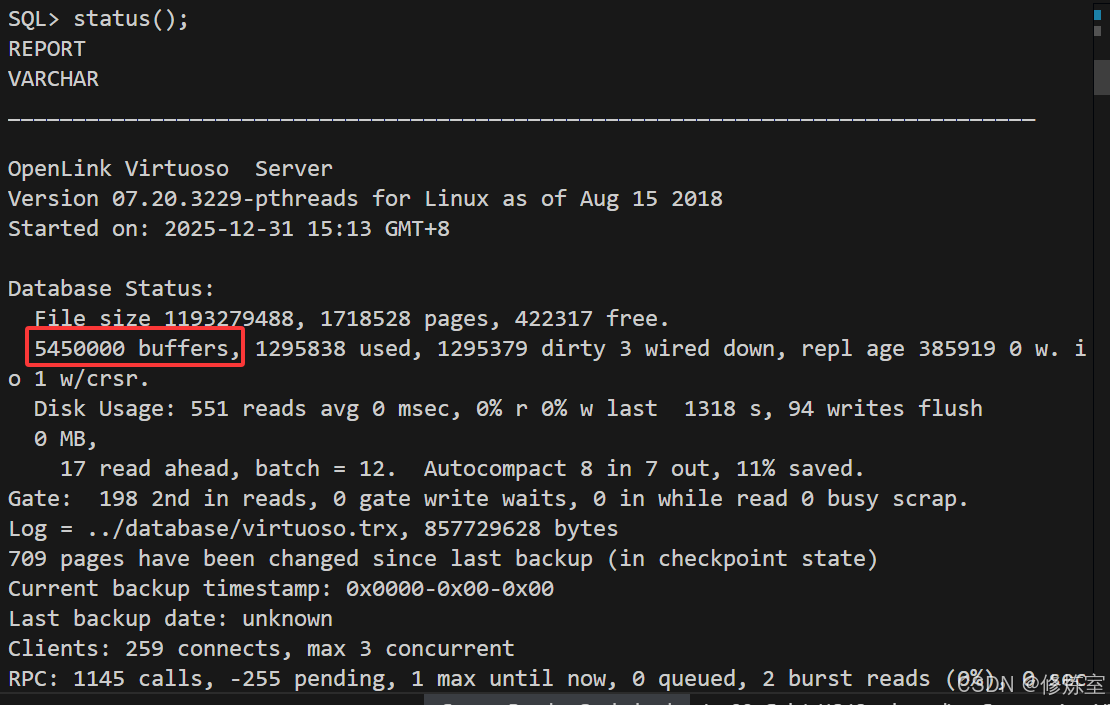
5,450,000 × 8KB ≈ 41.6 GiB(量级符合 sample 的 64GB 档位)
MaxDirtyBuffers:允许的"脏页"上限。太小会导致频繁刷盘;太大可能让 checkpoint 抖动。按 sample 的比例(约 70%--80%)通常较稳。
3.3 修改后必须重启才生效(建议前台启动观察日志)
bash
cd /home/liang/PoG/Preprocessing/virtuoso-opensource/database
# 停库:建议用 isql 的 shutdown(更安全)
../bin/isql 1111 dba dba
# isql 内执行:
# checkpoint;
# shutdown;
# 启动(前台,便于观察)
../bin/virtuoso-t -fstatus()中显示5450000 buffers、dirty非 0、Running Statements: rdf_loader_run()
4) 用 chunks 入队并启动导入(关键检查点:入队数必须匹配 chunk 数)
4.1 确保 DirsAllowed 放行 chunks 目录(否则 ld_dir 会 FA003)
在 virtuoso.ini 的 [Parameters] 加入:
ini
DirsAllowed = ., /home/liang/PoG/Preprocessing/FilterFreebase_chunks改完后重启 Virtuoso。
4.2 isql 入队 + 启动 loader
sql
ld_dir('/home/liang/PoG/Preprocessing/FilterFreebase_chunks', '*.nt', 'http://freebase.com');
SELECT COUNT(*) FROM DB.DBA.LOAD_LIST;
rdf_loader_run();
checkpoint;4.3 检查点:入队数量必须等于 chunk 数量
bash
ls -1 /home/liang/PoG/Preprocessing/FilterFreebase_chunks/*.nt | wc -l
sql
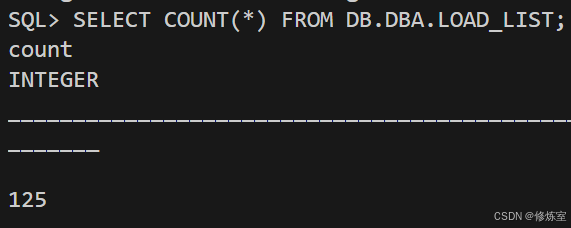
SELECT COUNT(*) FROM DB.DBA.LOAD_LIST;- 图:shell 里的 chunk 数量
- 图:isql 里
LOAD_LIST COUNT=125
若两边不一致,优先检查:
ld_dir第一个参数必须是"目录",不是文件- 通配符是否为
*.nt DirsAllowed是否放行- chunk 是否真的以
.nt结尾
5) 监控导入进度:三条 SQL 检查点(最重要的一节)
5.1 进度条:按 ll_state 聚合统计
sql
SELECT ll_state, COUNT(*)
FROM DB.DBA.LOAD_LIST
GROUP BY ll_state
ORDER BY ll_state;建议读者理解成:
0:排队中(pending)1:正在导入(running)2:已完成(done)ll_error非空:失败(必须处理)
图片建议放这里(1 张即可):
ll_state=0/1/2的统计输出
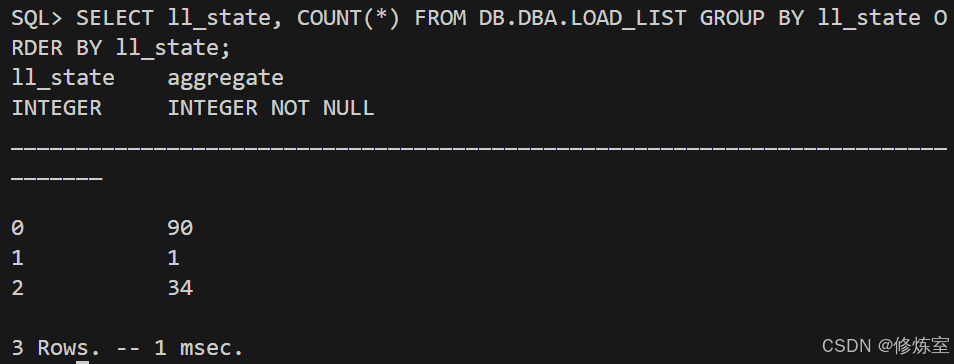
5.2 错误检查:尽早发现,避免最后返工
sql
SELECT TOP 20 ll_file, ll_state, ll_error
FROM DB.DBA.LOAD_LIST
WHERE ll_error IS NOT NULL;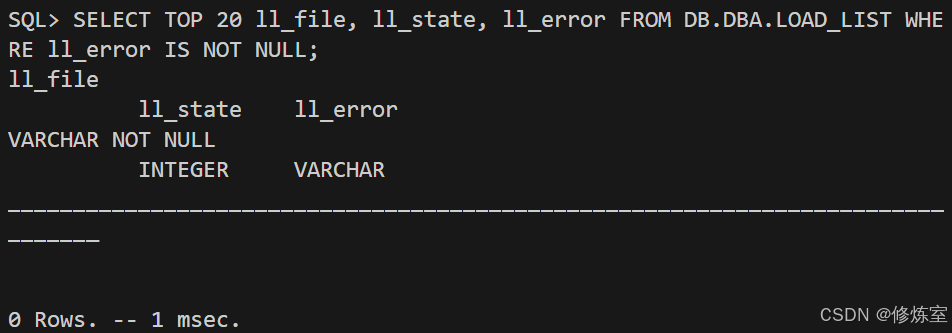
5.3 服务健康:用 status() 看导入是否仍在跑
sql
status();你希望看到:
Running Statements出现rdf_loader_run()dirty不为 0 且动态变化(导入期正常)- db 文件大小持续增长、磁盘空间持续消耗
6) 一键监控脚本:每 N 秒输出 done/pending/error + 当前导入文件 + db 大小 + 磁盘余量
保存为:monitor_virtuoso_load.sh
bash
#!/usr/bin/env bash
set -euo pipefail
VIRT_BASE="${VIRT_BASE:-/home/liang/PoG/Preprocessing/virtuoso-opensource}"
VIRT_DB_DIR="${VIRT_DB_DIR:-$VIRT_BASE/database}"
ISQL_BIN="${ISQL_BIN:-$VIRT_BASE/bin/isql}"
ISQL_PORT="${ISQL_PORT:-1111}"
ISQL_USER="${ISQL_USER:-dba}"
ISQL_PASS="${ISQL_PASS:-dba}"
SPARQL_URL="${SPARQL_URL:-http://127.0.0.1:8890/sparql}"
INTERVAL="${1:-60}"
LOG_FILE="${LOG_FILE:-$VIRT_DB_DIR/load_monitor.log}"
ISQL_TIMEOUT_SEC="${ISQL_TIMEOUT_SEC:-20}"
DB_FILE="$VIRT_DB_DIR/virtuoso.db"
now_ts() { date "+%F %T"; }
human_db_size() { [[ -f "$DB_FILE" ]] && ls -lh "$DB_FILE" | awk '{print $5}' || echo "N/A"; }
disk_free() { df -h "$VIRT_DB_DIR" 2>/dev/null | awk 'NR==2{print $4}'; }
http_code() { command -v curl >/dev/null 2>&1 && curl -s -o /dev/null -w "%{http_code}" "$SPARQL_URL" || echo "no-curl"; }
# 用 CSV 输出,解析稳定
isql_csv() {
local sql="$1"
timeout "${ISQL_TIMEOUT_SEC}s" "$ISQL_BIN" "$ISQL_PORT" "$ISQL_USER" "$ISQL_PASS" <<EOF
SET CSV=ON;
${sql}
EXIT;
EOF
}
parse_4ints_csv_row() {
awk -F';' '$1 ~ /^[0-9]+$/ && $2 ~ /^[0-9]+$/ && $3 ~ /^[0-9]+$/ && $4 ~ /^[0-9]+$/ {print $1, $2, $3, $4; exit}'
}
parse_1int_csv_row() { awk -F';' '$1 ~ /^[0-9]+$/ {print $1; exit}'; }
current_running_file() {
local out
out="$(isql_csv "SELECT TOP 1 ll_file FROM DB.DBA.LOAD_LIST WHERE ll_state = 1;" 2>/dev/null || true)"
echo "$out" | awk -F';' 'NR>1 && $1 ~ /^\// {print $1; exit}'
}
error_samples() {
local out
out="$(isql_csv "SELECT TOP 3 ll_file, ll_error FROM DB.DBA.LOAD_LIST WHERE ll_error IS NOT NULL;" 2>/dev/null || true)"
echo "$out" | awk -F';' 'NR>1 && $1 ~ /^\// {print $1 " | " $2}' | head -n 3
}
{
echo "[$(now_ts)] Start monitoring. interval=${INTERVAL}s log=${LOG_FILE}"
echo "VIRT_DB_DIR=$VIRT_DB_DIR"
echo "ISQL=$ISQL_BIN $ISQL_PORT $ISQL_USER ******"
echo "SPARQL_URL=$SPARQL_URL"
echo "------------------------------------------------------------"
} | tee -a "$LOG_FILE"
prev_done=-1
prev_time=0
while true; do
ts="$(now_ts)"
epoch_now="$(date +%s)"
summary_out="$(isql_csv "
SELECT
SUM(CASE WHEN ll_state = 2 THEN 1 ELSE 0 END) AS done,
SUM(CASE WHEN ll_state = 1 THEN 1 ELSE 0 END) AS running,
SUM(CASE WHEN ll_state = 0 THEN 1 ELSE 0 END) AS pending,
COUNT(*) AS total
FROM DB.DBA.LOAD_LIST;
" 2>/dev/null || true)"
summary_line="$(echo "$summary_out" | parse_4ints_csv_row || true)"
err_out="$(isql_csv "SELECT COUNT(*) AS err FROM DB.DBA.LOAD_LIST WHERE ll_error IS NOT NULL;" 2>/dev/null || true)"
err_n="$(echo "$err_out" | parse_1int_csv_row || true)"
err_n="${err_n:-0}"
db_sz="$(human_db_size)"
free_sz="$(disk_free)"
code="$(http_code)"
running_file="$(current_running_file || true)"
if [[ -z "$summary_line" ]]; then
echo "[$ts] cannot parse summary. http=$code db=$db_sz free=$free_sz" | tee -a "$LOG_FILE"
echo " raw_isql_output(head):" | tee -a "$LOG_FILE"
echo "$summary_out" | head -n 25 | sed 's/^/ /' | tee -a "$LOG_FILE"
sleep "$INTERVAL"
continue
fi
done_n="$(awk '{print $1}' <<<"$summary_line")"
running_n="$(awk '{print $2}' <<<"$summary_line")"
pending_n="$(awk '{print $3}' <<<"$summary_line")"
total_n="$(awk '{print $4}' <<<"$summary_line")"
rate="N/A"
if [[ "$prev_done" -ge 0 ]]; then
dt=$((epoch_now - prev_time))
dd=$((done_n - prev_done))
if [[ "$dt" -gt 0 ]]; then
rate="$(awk -v dd="$dd" -v dt="$dt" 'BEGIN{printf "%.2f", (dd*60.0)/dt}')"
fi
fi
prev_done="$done_n"
prev_time="$epoch_now"
pct="$(awk -v d="$done_n" -v t="$total_n" 'BEGIN{ if(t>0) printf "%.2f", (d*100.0)/t; else print "0.00"}')"
echo "[$ts] done=$done_n/$total_n (${pct}%) running=$running_n pending=$pending_n err=$err_n rate=${rate}chunks/min http=$code db=$db_sz free=$free_sz" | tee -a "$LOG_FILE"
[[ -n "$running_file" ]] && echo " running_file: $running_file" | tee -a "$LOG_FILE"
if [[ "$err_n" -gt 0 ]]; then
echo " errors(sample):" | tee -a "$LOG_FILE"
error_samples | sed 's/^/ - /' | tee -a "$LOG_FILE"
fi
if [[ "$done_n" -eq "$total_n" && "$running_n" -eq 0 && "$err_n" -eq 0 ]]; then
echo "[$ts] ALL DONE (no errors). Exiting." | tee -a "$LOG_FILE"
exit 0
fi
sleep "$INTERVAL"
done使用方法
bash
chmod +x monitor_virtuoso_load.sh
# 每 60 秒输出一次
./monitor_virtuoso_load.sh
# 每 30 秒输出一次
./monitor_virtuoso_load.sh 30
# 另一个窗口实时看日志
tail -f /home/liang/PoG/Preprocessing/virtuoso-opensource/database/load_monitor.log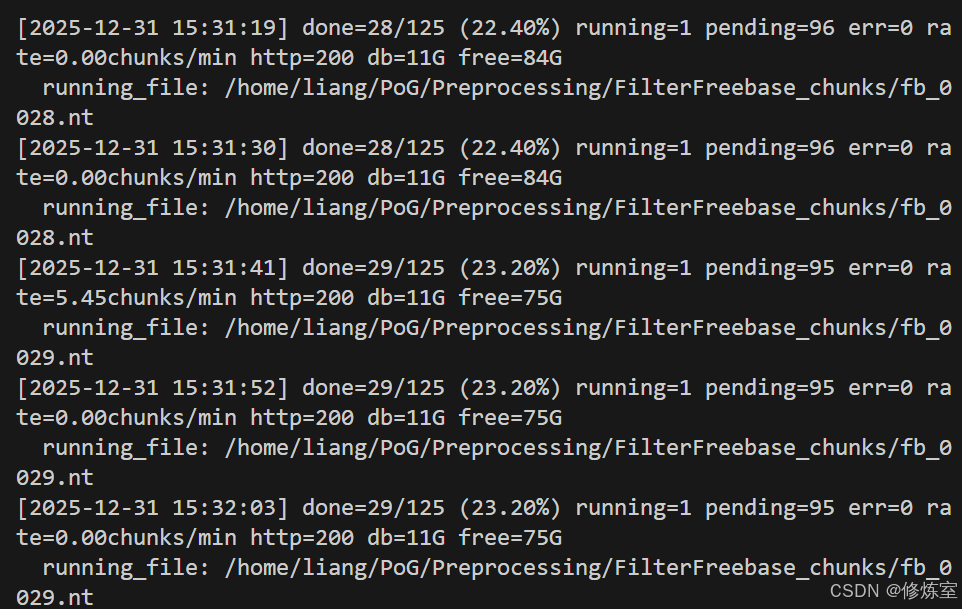
7) 何时可以认为"导入完成"?(三重校验,避免误判)
满足以下三个条件即可认为导入完成且质量可控:
7.1 LOAD_LIST 全部 done
sql
SELECT ll_state, COUNT(*)
FROM DB.DBA.LOAD_LIST
GROUP BY ll_state
ORDER BY ll_state;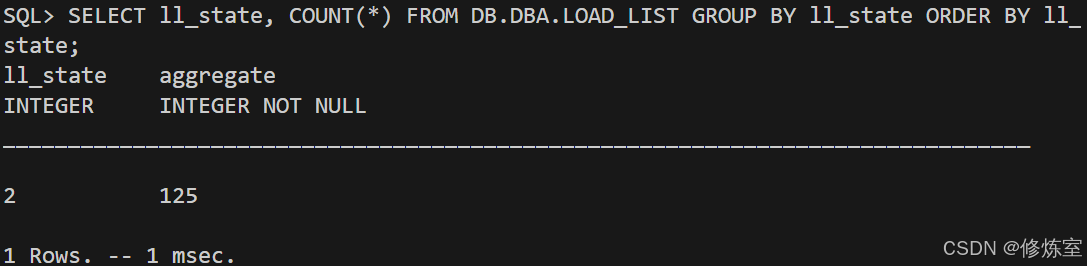
最终应当只有一行:ll_state=2 count=<chunk总数>。
7.2 没有任何错误
sql
SELECT COUNT(*)
FROM DB.DBA.LOAD_LIST
WHERE ll_error IS NOT NULL;结果应为 0。
7.3 graph 可查询到数据(快速 sanity check)
sql
SPARQL SELECT * FROM <http://freebase.com> WHERE { ?s ?p ?o } LIMIT 1;8) 总结:把"不可恢复、慢、不可观测"一次性解决
- chunk 化:解决单文件导入的不可恢复问题,把失败成本降低到"一个 chunk";
- 调大 buffers/dirty buffers:显著降低写等待与刷盘压力,让导入更快、更稳;
- 监控脚本:把导入过程变成可观测、可记录、可追踪的工程流程。
只要按本文的"检查点驱动"方式执行,你每一步都能自证正确与否,基本不会再落入"等了很久其实没在导入"的坑。