在大语言模型(LLM)飞速发展的今天,其在自然语言理解、生成等领域展现出强大能力,但同时也存在"知识滞后""事实性错误"等固有缺陷。检索增强生成(Retrieval-Augmented Generation,简称RAG)技术应运而生,通过将"检索外部知识库"与"LLM生成"相结合,有效弥补了LLM的不足,让生成内容更具准确性、时效性和专业性。本文将从RAG技术的核心原理、工作流程、核心组件出发,结合完整代码示例,带大家从零搭建一个简单的RAG系统。
一、RAG技术核心原理
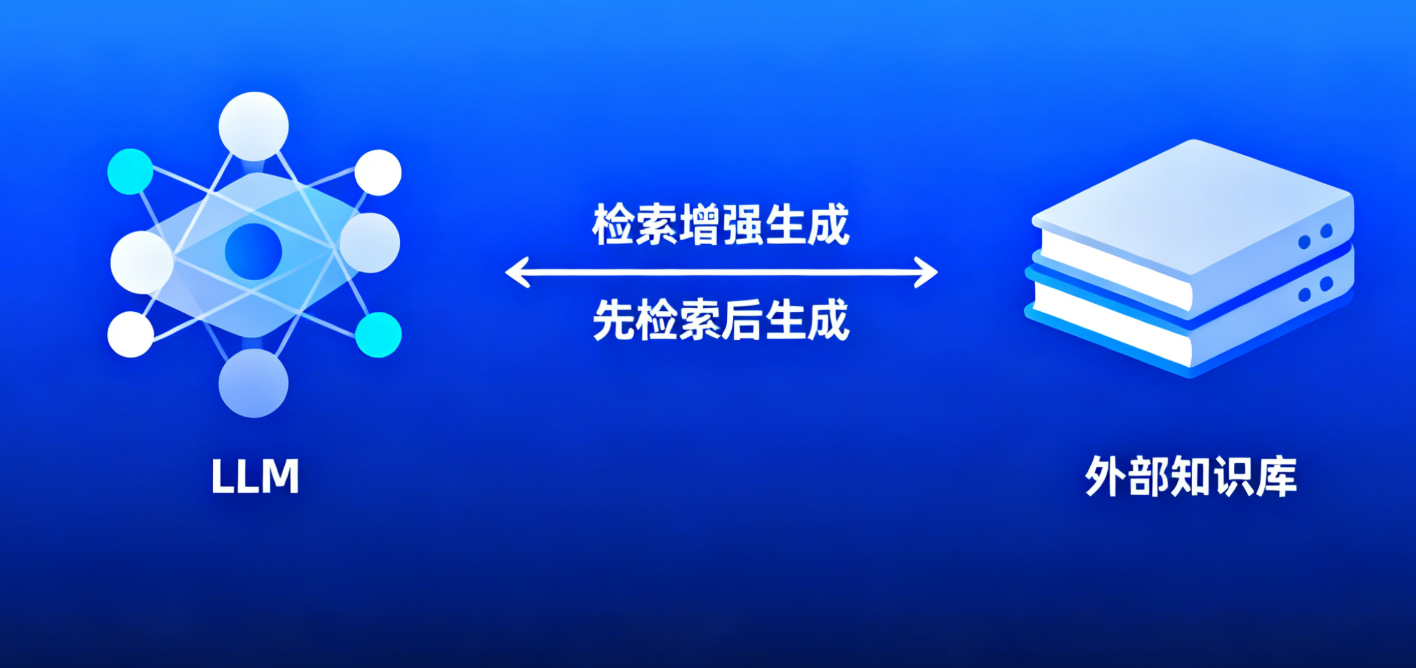
RAG的核心思想是"先检索,后生成":在LLM生成回复之前,先从外部知识库中检索与用户问题相关的信息,将这些信息作为"上下文"与用户问题一起输入给LLM,让LLM基于检索到的准确信息进行回复。其核心价值在于:
-
解决知识滞后:外部知识库可实时更新,无需重新训练庞大的LLM,就能让模型掌握最新信息(如行业动态、政策更新等);
-
提升事实准确性:减少LLM"一本正经地胡说八道"的概率,生成内容有外部知识支撑;
-
降低应用成本:相较于微调LLM,RAG无需大量标注数据和高额计算资源,落地门槛更低。
二、RAG技术工作流程
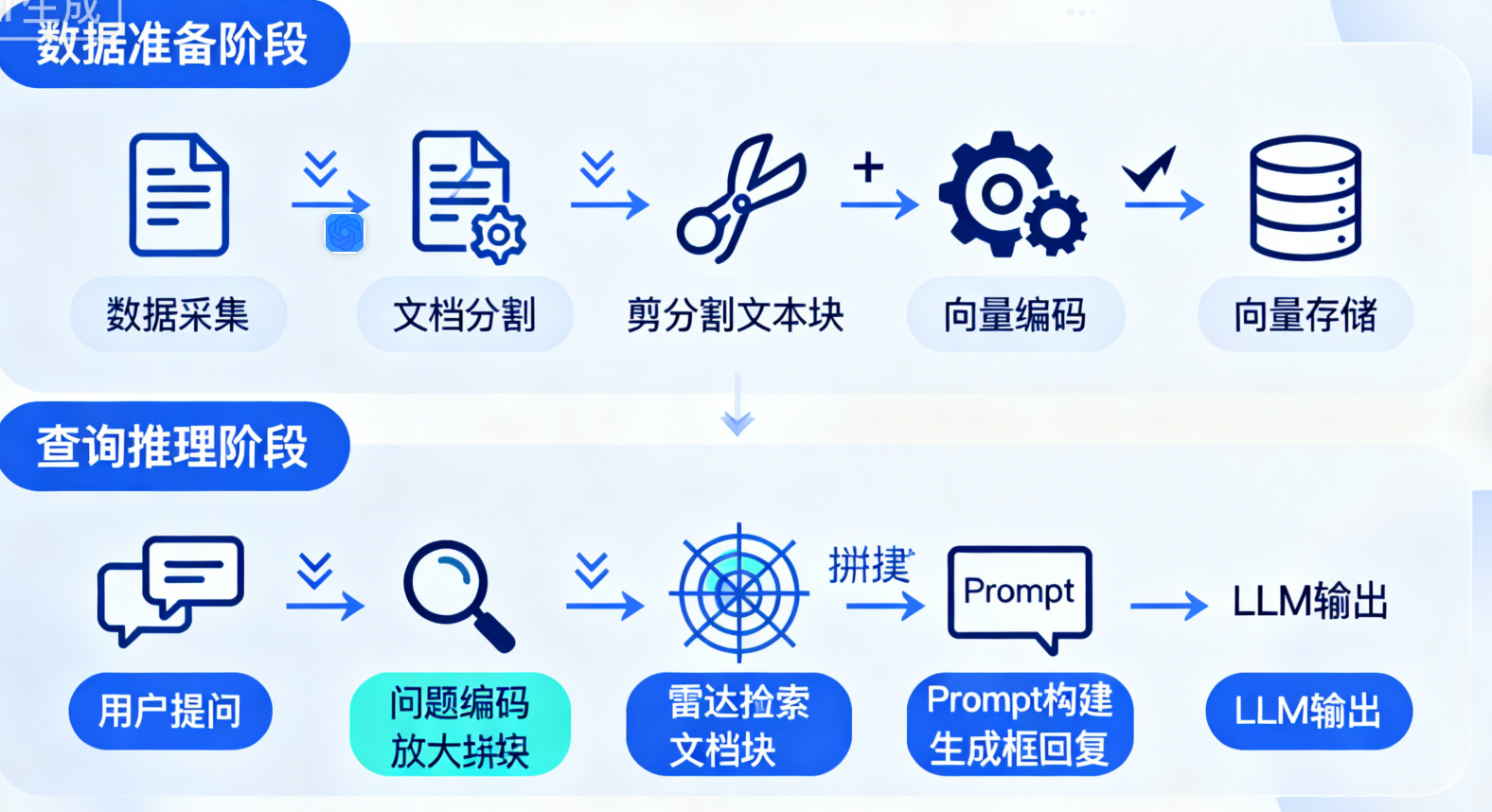
一个完整的RAG系统主要包含两大阶段:数据准备阶段 和查询推理阶段,具体流程如下:
-
数据准备阶段:
-
数据采集:收集领域相关的文档(如PDF、Word、网页文本等);
-
文档分割:将长文档拆分为短文本片段(Chunk),避免因文本过长导致检索不准确;
-
向量编码:使用嵌入模型(Embedding Model)将文本片段转换为高维向量(Embedding);
-
向量存储:将向量片段存入向量数据库(Vector Database),构建检索知识库。
-
-
查询推理阶段:
-
用户提问:用户输入自然语言问题;
-
问题编码:使用与文档编码相同的嵌入模型,将用户问题转换为向量;
-
相似检索:在向量数据库中检索与问题向量最相似的Top N文本片段;
-
prompt构建:将检索到的文本片段作为上下文,与用户问题组合成新的prompt;
-
生成回复:将新prompt输入LLM,生成基于准确上下文的回复。
-
三、RAG核心组件选型
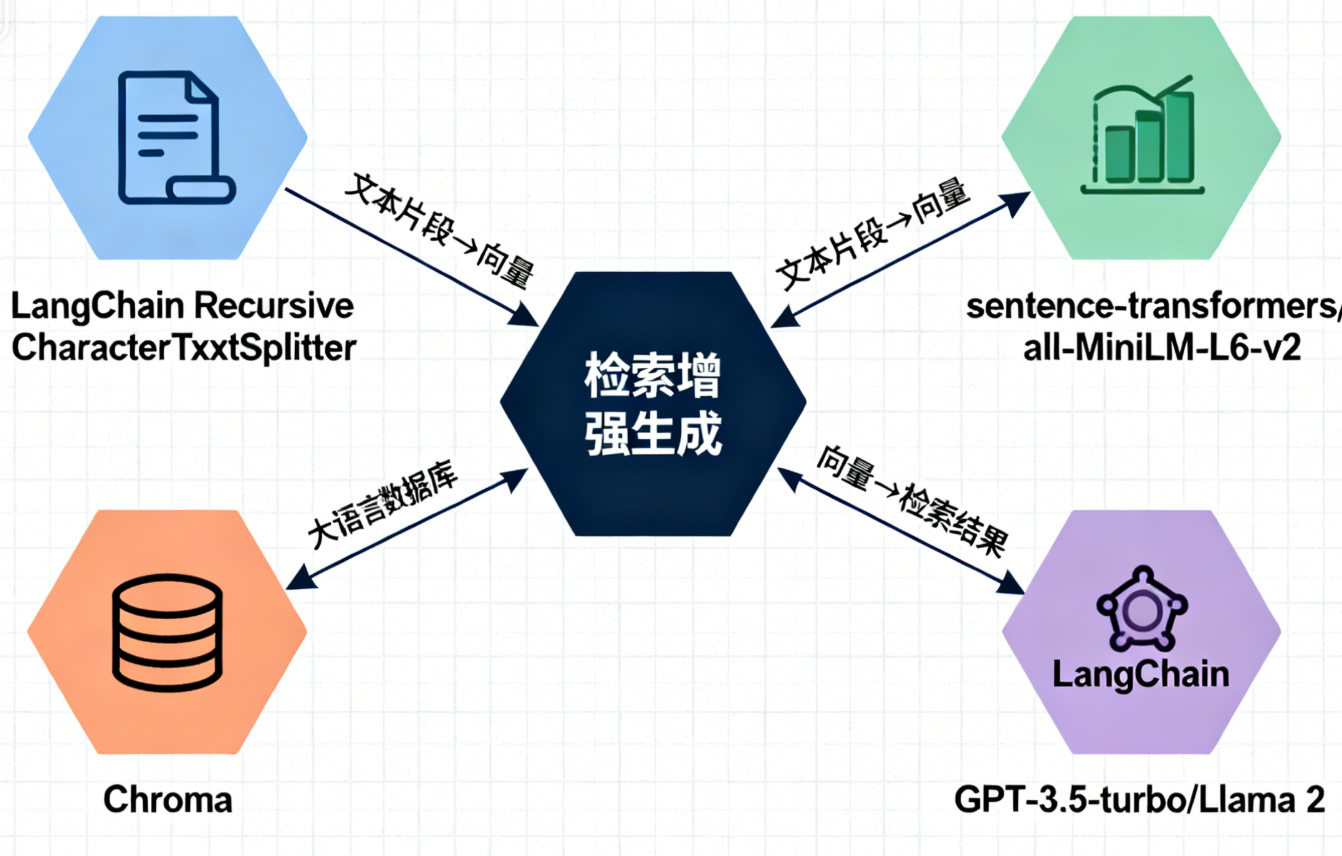
搭建RAG系统需选择合适的核心组件,以下是主流且易上手的组件组合(适合初学者):
| 组件类型 | 推荐选型 | 优势 |
|---|---|---|
| 文档分割工具 | LangChain RecursiveCharacterTextSplitter | 自适应不同文档格式,可自定义片段长度和重叠度 |
| 嵌入模型 | Hugging Face sentence-transformers/all-MiniLM-L6-v2 | 轻量高效,开源免费,支持多语言,适合小规模场景 |
| 向量数据库 | Chroma | 轻量级,无需复杂部署,支持内存模式,适合快速验证 |
| 大语言模型 | OpenAI GPT-3.5-turbo(或开源的Llama 2) | GPT-3.5-turbo生成质量高、调用便捷;Llama 2可本地部署,隐私性好 |
| 开发框架 | LangChain | 封装了RAG全流程组件,降低开发难度,支持多组件灵活集成 |
四、实战:从零搭建RAG系统(附完整代码)
本部分将使用上述组件,搭建一个"Python学习知识库"的RAG系统,支持用户查询Python相关知识点。
4.1 环境准备
首先安装所需依赖库:
# 安装LangChain(RAG开发框架)
pip install langchain
# 安装嵌入模型依赖
pip install sentence-transformers
# 安装向量数据库Chroma
pip install chromadb
# 安装OpenAI SDK(调用GPT模型)
pip install openai
# 安装文档加载工具(用于加载文本文件)
pip install python-dotenv4.2 完整代码实现
代码分为5个模块:环境配置、数据准备(加载+分割+编码+存储)、检索模块、生成模块、RAG整体流程封装。
import os
from dotenv import load_dotenv
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import Chroma
from langchain.chat_models import ChatOpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import RetrievalQA
# ---------------------- 1. 环境配置 ----------------------
# 加载环境变量(需在.env文件中配置OPENAI_API_KEY)
load_dotenv()
openai_api_key = os.getenv("OPENAI_API_KEY")
# 配置组件参数
# 文档分割参数:片段长度500字符,重叠度50字符(保证上下文连贯性)
CHUNK_SIZE = 500
CHUNK_OVERLAP = 50
# 嵌入模型:使用sentence-transformers的轻量模型
EMBEDDING_MODEL_NAME = "all-MiniLM-L6-v2"
# 向量数据库存储路径
VECTOR_DB_PATH = "./chroma_python_knowledge"
# LLM模型:GPT-3.5-turbo
LLM_MODEL_NAME = "gpt-3.5-turbo"
# ---------------------- 2. 数据准备:构建知识库 ----------------------
def build_knowledge_base(document_paths):
"""
加载文档、分割、编码并存储到向量数据库
:param document_paths: 文档路径列表(本示例使用.txt文档)
:return: 向量数据库检索器
"""
# 1. 加载文档(此处简化处理,加载.txt文本)
texts = []
for path in document_paths:
with open(path, "r", encoding="utf-8") as f:
texts.append(f.read())
# 2. 文档分割
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=CHUNK_SIZE,
chunk_overlap=CHUNK_OVERLAP,
length_function=len
)
splits = text_splitter.split_text("\n\n".join(texts)) # 合并所有文本后分割
# 3. 初始化嵌入模型
embeddings = HuggingFaceEmbeddings(model_name=EMBEDDING_MODEL_NAME)
# 4. 构建并存储向量数据库
db = Chroma.from_texts(
texts=splits,
embedding=embeddings,
persist_directory=VECTOR_DB_PATH
)
db.persist() # 持久化存储
# 5. 创建检索器(返回Top 3最相似片段)
retriever = db.as_retriever(search_kwargs={"k": 3})
return retriever
# ---------------------- 3. 构建RAG生成链 ----------------------
def build_rag_chain(retriever):
"""
构建检索-生成链
:param retriever: 向量数据库检索器
:return: RAG链
"""
# 定义Prompt模板:将检索到的上下文和用户问题组合
prompt_template = """
你是一个Python学习助手,仅基于提供的上下文信息回答用户问题。
如果上下文没有相关信息,直接说明"没有找到相关知识点",不要编造内容。
上下文信息:
{context}
用户问题:
{question}
回答:
"""
# 初始化Prompt模板
prompt = PromptTemplate(
template=prompt_template,
input_variables=["context", "question"]
)
# 初始化LLM
llm = ChatOpenAI(
model_name=LLM_MODEL_NAME,
api_key=openai_api_key,
temperature=0.3 # 降低随机性,保证回答准确性
)
# 构建检索-生成链
rag_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff", # 将所有检索到的上下文塞入Prompt
retriever=retriever,
chain_type_kwargs={"prompt": prompt},
return_source_documents=True # 返回检索到的原始上下文(用于验证)
)
return rag_chain
# ---------------------- 4. 核心查询函数 ----------------------
def rag_query(rag_chain, question):
"""
执行RAG查询
:param rag_chain: RAG链
:param question: 用户问题
:return: 生成的回答和检索到的上下文
"""
result = rag_chain({"query": question})
answer = result["result"]
source_documents = result["source_documents"]
return answer, source_documents
# ---------------------- 5. 测试运行 ----------------------
if __name__ == "__main__":
# 准备测试文档(需提前创建,示例文档内容为Python基础知识点)
test_documents = ["./python_basics.txt"] # 文档内容示例:Python变量、函数、列表操作等基础知识点
# 步骤1:构建知识库
print("正在构建Python学习知识库...")
retriever = build_knowledge_base(test_documents)
# 步骤2:构建RAG链
print("正在初始化RAG生成链...")
rag_chain = build_rag_chain(retriever)
# 步骤3:测试查询
test_questions = [
"Python中如何定义函数?",
"列表和元组的区别是什么?",
"Python的装饰器有什么作用?"
]
for question in test_questions:
print(f"\n用户问题:{question}")
answer, sources = rag_query(rag_chain, question)
print(f"回答:{answer}")
print("检索到的相关知识点:")
for i, source in enumerate(sources, 1):
print(f" {i}. {source.page_content}")4.3 代码说明与运行步骤
-
环境配置:
-
需要在项目根目录创建
.env文件,填入OpenAI API密钥:OPENAI_API_KEY=你的API密钥; -
若无法访问OpenAI,可替换为开源LLM(如Llama 2),需使用LangChain的
CTransformers封装调用本地模型。
-
-
文档准备:
- 创建
python_basics.txt文件,填入Python基础知识点(如变量定义、函数、列表操作等),示例内容:Python函数定义:使用def关键字,语法为def 函数名(参数): 函数体。例如: ``def add(a, b): `` return a + b `` ``列表和元组的区别: ``1. 列表是可变对象(mutable),可通过append、insert等方法修改元素; ``2. 元组是不可变对象(immutable),创建后无法修改元素; ``3. 列表使用[]包裹,元组使用()包裹。 `` ``Python装饰器:用于在不修改原函数代码的前提下,增强函数功能。使用@装饰器名语法,例如: ``def log_decorator(func): `` def wrapper(*args, **kwargs): `` print(f"调用函数:{func.__name__}") `` return func(*args, **kwargs) `` return wrapper `` ``@log_decorator ``def hello(): `` print("Hello Python")
- 创建
-
运行步骤:
-
执行代码,首先会构建向量数据库(存储在
./chroma_python_knowledge目录); -
然后对测试问题进行检索和生成,输出回答及对应的检索上下文。
-
4.4 效果验证
运行代码后,对于问题"Python中如何定义函数?",系统会从知识库中检索到"Python函数定义"相关的文本片段,然后让GPT-3.5-turbo基于该片段生成准确回答,避免了LLM编造错误语法的情况。若查询知识库中没有的内容(如"Python 4.0何时发布?"),系统会直接提示"没有找到相关知识点"。
五、RAG技术的优化方向
上述实现是基础版RAG系统,实际应用中需根据场景进行优化,核心优化方向包括:
-
文档分割优化:
-
针对不同文档类型(如PDF、Markdown)使用专用分割工具(如LangChain的
PyPDFLoader、MarkdownLoader); -
采用"语义分割"(如基于句子边界、段落边界),避免将完整语义拆分为多个片段。
-
-
嵌入模型优化:
-
对于专业领域(如医疗、法律),使用领域专用嵌入模型(如BioBERT嵌入模型);
-
通过微调嵌入模型,提升领域内文本的检索准确性。
-
-
检索策略优化:
-
使用"混合检索"(关键词检索+向量检索),提升检索召回率;
-
引入"重排序"(如使用Cross-BERT模型),对检索到的片段进行二次排序,筛选更相关的内容。
-
-
Prompt工程优化:
-
设计更精准的Prompt模板,明确LLM的角色和回答规则;
-
对于长文档检索结果,使用"映射-缩减"(Map-Reduce)策略,先对每个片段生成子回答,再汇总为最终回答。
-
-
向量数据库优化:
-
大规模场景下,替换为分布式向量数据库(如Milvus、Pinecone),提升检索性能;
-
定期清理和更新向量数据库,删除过期知识,保证知识库时效性。
-
六、RAG技术的应用场景
RAG技术因其低门槛、高准确性的特点,已广泛应用于多个领域:
-
企业知识库问答:如内部文档查询、员工培训问答、客户服务机器人(基于企业产品手册、FAQ等);
-
领域专业问答:如医疗问诊(基于医学文献)、法律咨询(基于法律法规文档)、金融研报分析(基于行业研报);
-
实时信息问答:如新闻资讯总结、股市动态分析(对接实时数据接口,将最新数据存入知识库);
-
个人知识管理:如笔记检索问答(基于个人笔记、阅读文档)、学习助手(基于教材、课件等)。
七、总结
RAG技术通过"检索增强生成"的核心逻辑,有效弥补了LLM的知识滞后和事实性缺陷,是当前LLM落地应用的关键技术之一。本文从原理、流程、组件选型出发,提供了可直接运行的基础版RAG系统代码,帮助读者快速入门。实际应用中,需根据具体场景优化文档分割、嵌入模型、检索策略等环节,才能实现更高性能的RAG系统。随着技术的发展,RAG与微调、Agent等技术的结合,将进一步拓展LLM的应用边界,推动AI在各行业的深度落地。