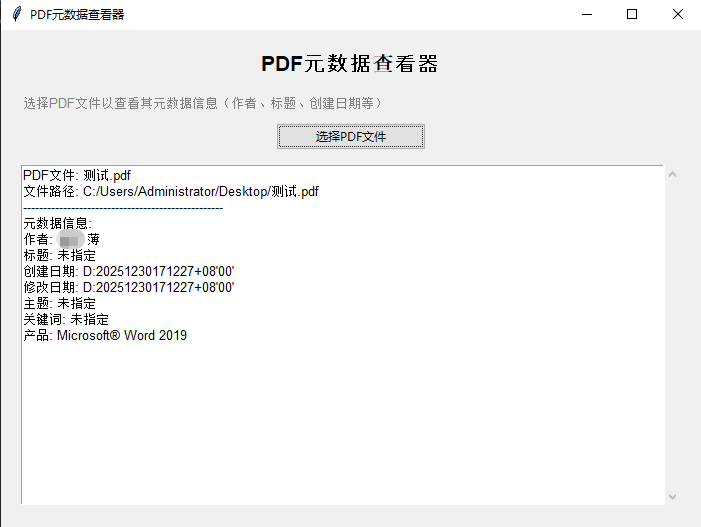
下面是一个完整的Python GUI程序,用于查看PDF文件的元数据(包括作者信息),使用Tkinter作为GUI框架。这个程序可以提取PDF的作者、标题、创建日期等信息。
完整代码如下(有需要运行版软件的留言邮箱):
import os
import PyPDF2
import tkinter as tk
from tkinter import filedialog, messagebox, ttk
from tkinter.scrolledtext import ScrolledText
class PDFMetadataViewer:
def __init__(self, root):
self.root = root
self.root.title("PDF元数据查看器")
self.root.geometry("700x500")
self.root.configure(bg="#f5f5f5")
# 创建主框架
main_frame = ttk.Frame(root, padding="20")
main_frame.pack(fill=tk.BOTH, expand=True)
# 标题
title_label = ttk.Label(main_frame, text="PDF元数据查看器", font=("Arial", 16, "bold"))
title_label.pack(pady=(0, 15))
# 说明文字
info_label = ttk.Label(main_frame,
text="选择PDF文件以查看其元数据信息(作者、标题、创建日期等)",
foreground="gray",
font=("Arial", 10))
info_label.pack(anchor="w")
# 选择文件按钮
self.btn_browse = ttk.Button(main_frame, text="选择PDF文件", command=self.browse_file, width=20)
self.btn_browse.pack(pady=10)
# 显示区域
self.text_area = ScrolledText(main_frame, wrap=tk.WORD, font=("Arial", 10), state=tk.DISABLED)
self.text_area.pack(fill=tk.BOTH, expand=True, pady=5)
# 操作按钮
btn_frame = ttk.Frame(main_frame)
btn_frame.pack(pady=5)
self.btn_save = ttk.Button(btn_frame, text="保存为文本文件", command=self.save_to_file, width=20)
self.btn_save.pack(side=tk.LEFT, padx=5)
self.btn_clear = ttk.Button(btn_frame, text="清除显示", command=self.clear_display, width=20)
self.btn_clear.pack(side=tk.LEFT, padx=5)
# 状态栏
self.status_var = tk.StringVar()
self.status_var.set("就绪 - 请选择PDF文件")
self.status_bar = ttk.Label(root, textvariable=self.status_var, relief=tk.SUNKEN, anchor=tk.W)
self.status_bar.pack(side=tk.BOTTOM, fill=tk.X)
# 信息提示
info_note = ttk.Label(main_frame,
text="注意:PDF文件中不包含计算机MAC地址信息,这些信息仅来自PDF的元数据",
foreground="red",
font=("Arial", 9))
info_note.pack(pady=(10, 0), anchor="w")
def browse_file(self):
"""打开文件选择对话框"""
file_path = filedialog.askopenfilename(
title="选择PDF文件",
filetypes=[("PDF文件", "*.pdf"), ("所有文件", "*.*")]
)
if file_path:
self.display_metadata(file_path)
def display_metadata(self, file_path):
"""显示PDF元数据"""
try:
self.text_area.config(state=tk.NORMAL)
self.text_area.delete(1.0, tk.END)
# 提取元数据
metadata = self.get_pdf_metadata(file_path)
if '错误' in metadata:
self.text_area.insert(tk.END, f"错误: {metadata['错误']}")
else:
# 显示元数据
self.text_area.insert(tk.END, f"PDF文件: {os.path.basename(file_path)}\n")
self.text_area.insert(tk.END, f"文件路径: {file_path}\n")
self.text_area.insert(tk.END, f"{'-'*50}\n")
self.text_area.insert(tk.END, "元数据信息:\n")
self.text_area.insert(tk.END, f"作者: {metadata.get('作者', '未指定')}\n")
self.text_area.insert(tk.END, f"标题: {metadata.get('标题', '未指定')}\n")
self.text_area.insert(tk.END, f"创建日期: {metadata.get('创建日期', '未指定')}\n")
self.text_area.insert(tk.END, f"修改日期: {metadata.get('修改日期', '未指定')}\n")
self.text_area.insert(tk.END, f"主题: {metadata.get('主题', '未指定')}\n")
self.text_area.insert(tk.END, f"关键词: {metadata.get('关键词', '未指定')}\n")
self.text_area.insert(tk.END, f"产品: {metadata.get('产品', '未指定')}\n")
self.text_area.config(state=tk.DISABLED)
self.status_var.set(f"已加载: {os.path.basename(file_path)}")
except Exception as e:
self.text_area.config(state=tk.NORMAL)
self.text_area.delete(1.0, tk.END)
self.text_area.insert(tk.END, f"错误: {str(e)}")
self.text_area.config(state=tk.DISABLED)
self.status_var.set("错误: 无法加载文件")
def get_pdf_metadata(self, file_path):
"""获取PDF元数据"""
try:
with open(file_path, 'rb') as file:
pdf_reader = PyPDF2.PdfReader(file)
if pdf_reader.metadata:
return {
'作者': pdf_reader.metadata.get('/Author', '未指定'),
'标题': pdf_reader.metadata.get('/Title', '未指定'),
'创建日期': pdf_reader.metadata.get('/CreationDate', '未指定'),
'修改日期': pdf_reader.metadata.get('/ModDate', '未指定'),
'主题': pdf_reader.metadata.get('/Subject', '未指定'),
'关键词': pdf_reader.metadata.get('/Keywords', '未指定'),
'产品': pdf_reader.metadata.get('/Producer', '未指定')
}
else:
return {'错误': 'PDF文件不包含元数据'}
except Exception as e:
return {'错误': str(e)}
def save_to_file(self):
"""保存元数据到文本文件"""
if self.text_area.cget("state") == tk.DISABLED:
# 获取当前显示的文本
text = self.text_area.get(1.0, tk.END)
# 移除末尾的换行符
text = text.strip()
if not text or "错误" in text or "未指定" in text:
messagebox.showinfo("提示", "没有可保存的元数据")
return
# 选择保存位置
save_path = filedialog.asksaveasfilename(
defaultextension=".txt",
filetypes=[("文本文件", "*.txt"), ("所有文件", "*.*")],
initialfile="pdf_metadata.txt"
)
if save_path:
try:
with open(save_path, 'w', encoding='utf-8') as f:
f.write(text)
messagebox.showinfo("成功", f"元数据已保存到: {save_path}")
self.status_var.set(f"已保存到: {os.path.basename(save_path)}")
except Exception as e:
messagebox.showerror("错误", f"无法保存文件: {str(e)}")
else:
messagebox.showinfo("提示", "请先加载一个PDF文件")
def clear_display(self):
"""清除显示区域"""
self.text_area.config(state=tk.NORMAL)
self.text_area.delete(1.0, tk.END)
self.text_area.config(state=tk.DISABLED)
self.status_var.set("已清除显示内容")
if __name__ == "__main__":
try:
# 检查是否安装了PyPDF2
import PyPDF2
except ImportError:
# 如果没有安装PyPDF2,提示用户安装
messagebox.showerror("缺少库", "需要安装PyPDF2库。请运行: pip install PyPDF2")
exit(1)
root = tk.Tk()
app = PDFMetadataViewer(root)
root.mainloop()使用说明
1.安装依赖:
pip install PyPDF22.运行程序:
- 点击"选择PDF文件"按钮
- 从文件浏览器中选择一个PDF文件
- 程序将显示PDF的元数据信息
功能说明
- 元数据提取:从PDF中提取作者、标题、创建日期、修改日期等信息
- 用户友好界面:使用Tkinter创建的GUI,简单直观
- 错误处理:处理常见错误(如文件不存在、PDF格式错误等)
界面展示