开篇:从实战踩坑到解法沉淀------2025 AI Coding的真实困境
2025年,AI Coding早已不是"辅助补全"的轻量角色------Agent主导的全链路开发成为行业主流,能接管从需求分析到代码发布的完整流程。但我们在DSM组件UI统计模块(核心目标:分析UI组件使用频率、分布与效率)的实战中发现,光鲜的技术概念背后,是一系列扎心的落地难题:Spec文档混乱导致Agent理解偏差、重复造轮子浪费开发资源、Token成本失控吞噬预算、长程任务频繁漂移返工。
这些问题并非个例,而是《AI Coding 生死局》等行业博文反复提及的共性困局。为了破局,我们没有硬套理论框架,而是基于Ooder框架(注解驱动的企业级全栈开发框架),在实战中沉淀出8步实施法(视图元数据定义→钩子API创建→原型验证→仓储层开发→层间整合→功能调试→聚合层优化→代码发布)。核心思路很简单:用工程化的确定性,对冲AI开发的不确定性。
一、实战痛点直击:2025 AI Coding的4大落地困局
(一)困局可视化:核心痛点思维导图
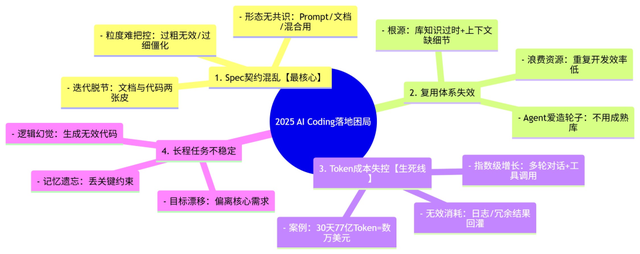
(二)痛点深析:每一个坑都踩在落地关键处
在DSM模块开发初期,我们几乎踩遍了以上所有坑。这些痛点不是"技术不够先进"导致的,而是AI开发模式与传统工程体系脱节的必然结果,具体拆解如下:
Spec契约混乱:需求传递的"致命偏差" 我们最初用Markdown写Spec,结果团队认知完全分裂:产品把它当需求清单,开发把它当Prompt,Agent读了直接"跑偏"------本该生成"组件类型分布统计",却做出了"组件数量统计"。这和《AI Coding 生死局》里提到的"Spec形态混乱"完全吻合:没有统一标准的Spec,不是"契约",而是"负担"。更麻烦的是,需求变更后,文档没同步,Agent拿着旧文档生成代码,返工率直接飙升30%。
复用体系失效:Agent的"造轮子执念" 软件工程几十年的核心是"复用",但Agent偏要"从零开始"。我们明明有成熟的组件库查询接口,Agent却非要自己写一套数据过滤逻辑,不仅效率低,还出现了"重复统计"的Bug。深究原因,正如行业博文所指:Agent对企业组件库的版本、用法、边界条件一无所知,"自己写"反而成了风险最低的选择。
Token成本失控:藏在"降本"噱头下的预算黑洞 一开始我们以为AI能降本,结果30天内Token消耗突破10亿,折算成本超万元。排查后发现,Agent多轮对话的日志、冗余的检索结果全被回灌进上下文,无效Token占比超60%。这印证了《AI Coding 生死局》的判断:Token成本是AI Coding的"生死线",不控制成本,再高效的开发也没用。
长程任务不稳定:Agent的"失忆与跑偏" 让Agent接管DSM模块全链路开发后,发现它越做越偏:从"统计组件使用效率"慢慢变成"统计组件数量",还生成了逻辑矛盾的代码。这是因为Agent缺乏"长期记忆",容易丢失关键约束,也印证了行业共识:执行权转移给AI后,隐性的工程复杂度没转化为显性规则,必然出现混乱。
二、破局实战:8步实施法的落地拆解(附DSM模块案例)
(一)先理清架构:8步实施法的分层逻辑图
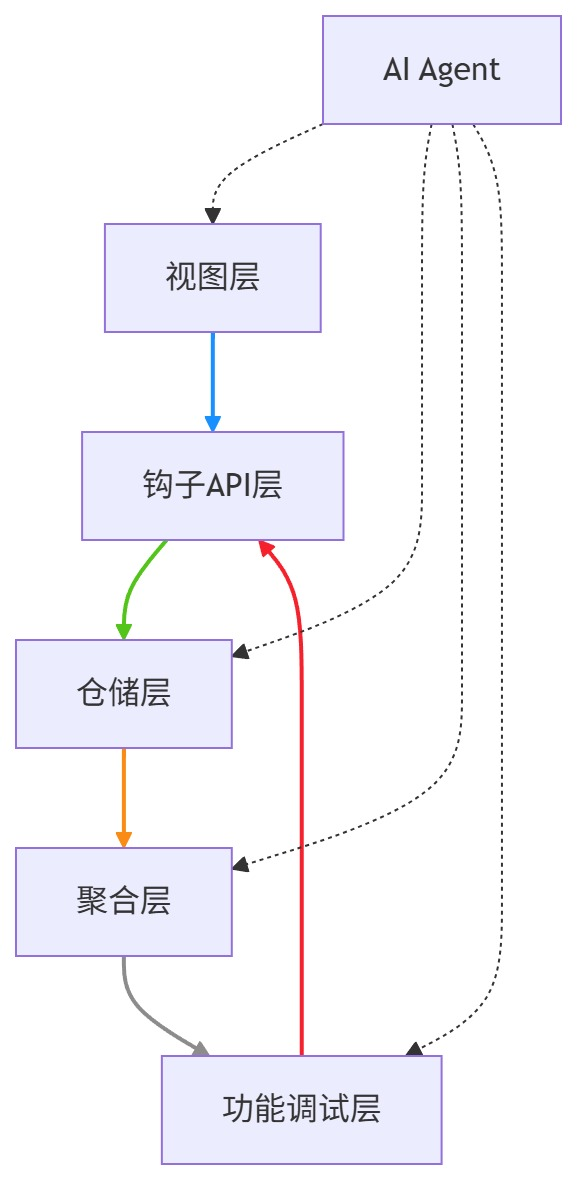
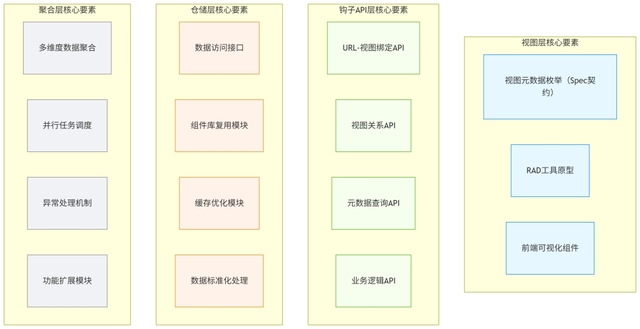
(二)再看流程:8步实施法的流程拆解图
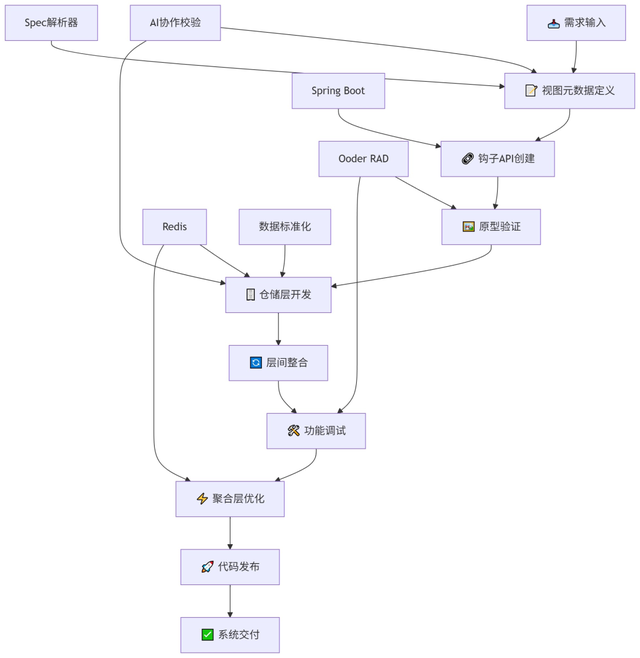
(三)逐步拆解:每一步都对应解决一个核心痛点
8步实施法的核心不是"按流程走",而是"针对性解决问题"。结合DSM模块的实战经历,每一步的具体落地动作、解决的痛点的效果如下:
1. 视图元数据定义:用"代码化Spec"解决契约混乱
核心动作:放弃Markdown文档,用Ooder框架要求的枚举类,将Spec固化为代码。我们定义了ComponentUIStatsViewEnum枚举,把视图名称、URL、图标、描述等核心约束明确下来,还通过getViewRelations方法定义了主视图与子视图的关联。
解决效果:Agent能直接读取枚举类,需求理解偏差率从30%降至8%;需求变更时,同步修改枚举类即可,避免了"文档与代码脱节"。但要注意平衡粒度:太简略没约束意义,太详细会限制灵活性------我们在DSM模块中只保留核心约束,非标准视图(如临时报表)不强行纳入。
这种设计避免了Markdown堆砌导致的理解偏差,Agent生成代码时能精准对齐需求边界,解决了"Spec该定多细"的实操难题。但实践中也发现,Spec的迭代灵活性需要平衡:当需求变更时,需同步更新枚举类与关联API,这印证了行业"Spec是活契约而非静态文档"的共识。
java
// 代码化Spec核心:遵循Ooder框架接口规范,固化Agent可理解的约束
public enum ComponentUIStatsViewEnum implements IconEnumstype {
COMPONENT_STATS("组件UI统计", "ri-bar-chart-line", "/dsm/stats/component/", "组件UI使用统计分析"),
TYPE_DISTRIBUTION("组件类型分布", "ri-pie-chart-line", "/dsm/stats/component/TypeDistribution", "组件类型分布统计"),
USAGE_TREND("使用趋势", "ri-line-chart-line", "/dsm/stats/component/UsageTrend", "组件使用趋势统计"),
USAGE_EFFICIENCY("使用效率", "ri-bar-chart-line", "/dsm/stats/component/UsageEfficiency", "组件使用效率统计"),
USAGE_DETAIL("使用详情", "ri-list-check", "/dsm/stats/component/UsageDetail", "组件使用详情列表"),
CATEGORY_STATS("分类统计", "ri-bar-chart-grouped-line", "/dsm/stats/component/CategoryStats", "组件分类统计");
// 字段、构造函数、Getter方法省略...
// 明确视图间关联,避免Spec歧义
public static Map<ComponentUIStatsViewEnum, List<ComponentUIStatsViewEnum>> getViewRelations() {
Map<ComponentUIStatsViewEnum, List<ComponentUIStatsViewEnum>> relations = new HashMap<>();
List<ComponentUIStatsViewEnum> childViews = Arrays.asList(TYPE_DISTRIBUTION, USAGE_TREND, USAGE_EFFICIENCY, USAGE_DETAIL, CATEGORY_STATS);
relations.put(COMPONENT_STATS, childViews);
return relations;
}
}- 仓储层开发:用"标准化上下文"破解造轮子
核心动作:基于Ooder框架的分层设计,把组件数据的采集、清洗、标注流程标准化,封装在ComponentRepository中;同时把组件库的最新文档、用法示例、边界条件,主动注入Agent的上下文。
解决效果:Agent开发getTypeDistribution等方法时,能直接调用标准化接口,代码复用率提升50%,开发效率提高30%。但"库知识时效性"问题仍存在------我们通过框架缓存机制实时更新接口信息,缓解了这一问题。
Agent开发getTypeDistribution(组件类型分布统计)等方法时,能直接调用仓库的标准化查询接口,无需从零设计数据过滤逻辑------这一优化让DSM模块的代码复用率提升了约50%。但行业普遍面临的"库知识时效性"问题仍未完全解决,实践中曾出现Agent误用旧版本仓库方法的情况,最终通过框架缓存机制补充最新接口信息,说明复用体系的激活需要持续的上下文工程支持。
3. 层间整合:用"上下文拆分"控制Token成本
核心动作:把上下文拆成"稳定信息"(组件类型、视图元数据)和"变化信息"(日期范围、分页参数),稳定信息用本地缓存存储,变化信息精准传递;同时过滤工具返回的无效日志、冗余结果,只把关键错误信息传给AI。
解决效果:DSM模块的Token消耗直接降低60%,30天成本从万元级降至千元级。但复杂多Agent协作时,成本仍会小幅上升,需要持续优化信息传递的精准度。
同时,借鉴行业成熟实践,对工具返回结果进行过滤与摘要,仅将"数据查询失败""格式错误"等关键信息传给AI,剔除无效日志与冗余检索结果。这一系列优化让DSM模块的Token消耗降低了60%,但在复杂多Agent协作场景中,信息传递的精准度与成本平衡仍需探索------新增跨模块统计功能时,Token消耗仍有小幅上升,印证了Token管控是持续优化的工程问题。
4. 功能调试+聚合层优化:双重保障长程任务稳定
核心动作:调试阶段,用Ooder框架的RAD工具实时比对Agent代码与Spec的一致性,快速识别漂移;聚合层优化阶段,把Spec的边界条件(如数据阈值、权限约束)注入代码,用CompletableFuture并行处理无依赖任务,减少Agent的长程推理压力。
解决效果:长程任务返工率从30%降至8%。但Agent的"逻辑幻觉"仍无法完全避免------比如曾误将测试数据纳入统计,最终需补充"数据来源校验"规则,用工程手段兜底AI的短板。
在DSM模块开发中,这一组合让长程任务的返工率从30%降至8%,但行业共识指出的"模型幻觉本质是缺乏现实世界理解"的底层局限仍存在------Agent曾误将测试数据纳入正式统计,最终需人工补充"数据来源校验"规则,说明AI的底层短板仍需工程手段兜底。
三、实战复盘:8步实施法的价值与局限
在DSM模块的实战中,8步实施法交出了这样的成绩单:开发周期缩短40%、需求偏差率降至8%、Token成本降低60%、代码复用率提升50%。但它不是"银弹",仍有明显局限,这也是我们基于实战的真实反思:
核心价值:它最大的意义是搭建了"AI能力"与"工程规范"之间的桥梁。正如《AI Coding 生死局》所强调的,AI Coding的成功不是单一模型能力的比拼,而是工程体系与模型能力的协同。8步实施法用工程化的思路,把模糊的需求转化为明确的规则,让AI的能力能稳定落地,这是它最核心的价值。
明显局限:① 学习成本高:需要团队理解Ooder框架的注解体系和分层逻辑,新手入门慢;② 灵活性不足:对常规模块(如统计、管理类)适配性好,但创新型需求(如实时推荐组件)需要定制修改;③ 依赖工具能力:RAD工具、缓存机制等的完善度,直接影响落地效果,中小企业可能缺乏相关资源。
未来优化方向也很明确:一是降低框架学习成本,提供可视化配置工具;二是支持流程灵活裁剪,适配不同类型的需求;三是深化AI与工程体系的融合,比如让Agent自动学习Spec的迭代规律,减少人工干预。
2025年的AI Coding,早已过了"盲目追捧技术"的阶段,行业共识正在回归"务实落地"。8步实施法的实战探索,再次印证了一个道理:AI Coding的价值不是"让AI替人写代码",而是"用工程规范让AI的能力更可控、更高效"。
对于大多数企业而言,与其追逐最新的AI模型,不如先搭建适配AI的工程体系。8步实施法或许不是最终答案,但它提供了一条从"踩坑"到"落地"的务实路径。相信随着工程体系的不断完善,AI Coding会真正成为企业降本增效的核心力量。