0. 前言
Robot Lab 是基于 NVIDIA Isaac Lab 构建的机器人强化学习扩展库,专注于足式机器人的运动控制任务。该项目由 Ziqi Fan 开发维护,目前已支持包括 Unitree Go2、G1、H1 在内的十余款主流机器人平台。与原生 Isaac Lab 相比,Robot Lab 提供了更加完善的奖励函数库、域随机化配置以及针对不同机器人形态优化的训练参数。
在深入技术细节之前,有必要先理解 Isaac Lab 的基本架构。Isaac Lab 构建于 Isaac Sim 之上,采用分层设计:最底层是 Omniverse 渲染引擎与 PhysX 物理引擎,中间层是 Isaac Sim 提供的机器人仿真接口,最上层则是 Isaac Lab 封装的强化学习环境。Robot Lab 在此基础上进一步抽象,将运动控制任务的通用配置提取为基类,使得添加新机器人变得简单高效。
1. 配置继承体系解析
1.1 整体架构概览
Robot Lab 的环境配置采用面向对象的继承体系,这一设计决策源于对机器人强化学习任务共性的深刻理解。无论是四足机器人、人形机器人还是轮式机器人,其速度跟踪任务都包含相似的核心组件:观测空间定义、动作空间设计、奖励函数构建等。将这些共性抽象为基类,可以显著减少重复代码,同时保持各机器人配置的独立性与可维护性。
以 Unitree G1 人形机器人为例,其配置继承链如下图所示:
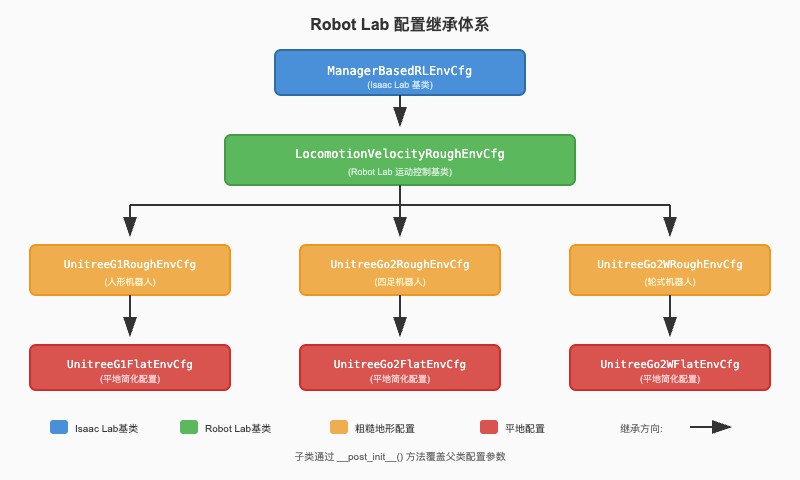
继承链从 Isaac Lab 的 ManagerBasedRLEnvCfg 基类开始,该类定义了强化学习环境的基本框架。Robot Lab 在此基础上派生出 LocomotionVelocityRoughEnvCfg,封装了运动控制任务的通用配置。针对具体机器人,如 G1,则进一步派生出粗糙地形配置 UnitreeG1RoughEnvCfg,最后是针对平地训练的简化配置 UnitreeG1FlatEnvCfg。
这种多层继承结构带来三个核心优势。首先是代码复用:基类中定义的 30 余个奖励项、8 种域随机化事件、多组传感器配置等均可被所有子类继承,无需重复编写。其次是灵活定制:每个机器人可以通过 __post_init__ 方法选择性地覆盖父类参数,例如 G1 需要启用摔倒惩罚而四足机器人可能不需要。最后是易于维护:当基类的奖励函数实现优化后,所有子类自动受益,无需逐一修改。
1.2 基类详解:LocomotionVelocityRoughEnvCfg
LocomotionVelocityRoughEnvCfg 是 Robot Lab 运动控制任务的核心基类,位于 velocity_env_cfg.py 文件中。该类定义了构成马尔可夫决策过程(MDP)的全部要素,包括状态空间、动作空间、奖励函数、状态转移规则等。理解这个基类的设计,是掌握整个 Robot Lab 配置体系的关键。
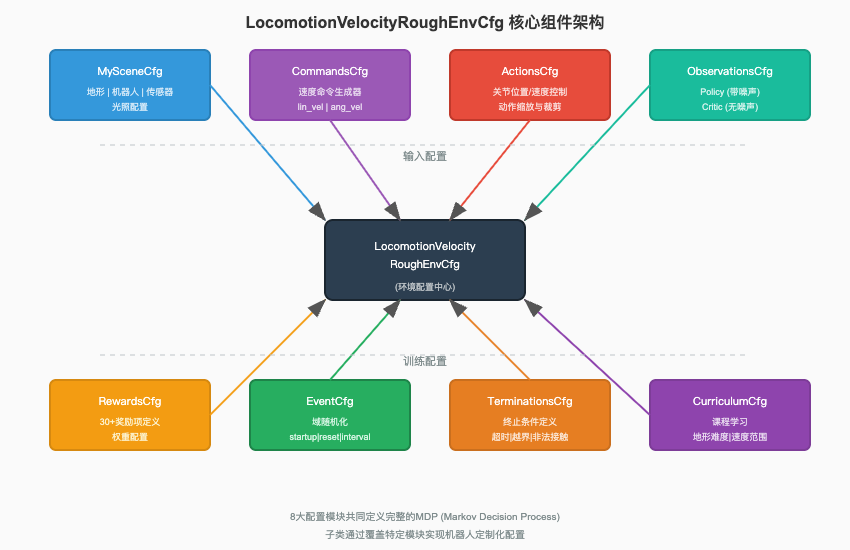
基类的核心结构如下,包含 8 个配置模块:
python
@configclass
class LocomotionVelocityRoughEnvCfg(ManagerBasedRLEnvCfg):
"""运动速度跟踪环境配置基类"""
# 场景配置:定义物理世界
scene: MySceneCfg = MySceneCfg(num_envs=4096, env_spacing=2.5)
# MDP 输入配置
observations: ObservationsCfg = ObservationsCfg() # 观测空间
actions: ActionsCfg = ActionsCfg() # 动作空间
commands: CommandsCfg = CommandsCfg() # 目标命令
# MDP 训练配置
rewards: RewardsCfg = RewardsCfg() # 奖励函数
terminations: TerminationsCfg = TerminationsCfg() # 终止条件
events: EventCfg = EventCfg() # 域随机化
curriculum: CurriculumCfg = CurriculumCfg() # 课程学习这 8 个模块可以分为两类:输入配置(Scene、Commands、Actions、Observations)定义了智能体与环境的交互接口;训练配置(Rewards、Terminations、Events、Curriculum)则控制训练过程的行为。以下逐一详解各模块的设计原理与关键参数。
1.2.1 场景配置 (MySceneCfg)
场景配置定义了仿真环境中的物理世界,包括地形、机器人模型以及各类传感器。在 Isaac Lab 的架构中,场景是所有物理实体的容器,其配置直接影响仿真的物理真实性与计算效率。
python
@configclass
class MySceneCfg(InteractiveSceneCfg):
"""场景配置:定义地形、机器人、传感器"""
# 地形配置
terrain = TerrainImporterCfg(
prim_path="/World/ground",
terrain_type="generator", # 程序化地形生成
terrain_generator=ROUGH_TERRAINS_CFG, # 使用预定义的粗糙地形配置
max_init_terrain_level=5, # 课程学习的初始最大难度等级
collision_group=-1, # 碰撞组,-1 表示与所有物体碰撞
physics_material=sim_utils.RigidBodyMaterialCfg(
friction_combine_mode="multiply", # 摩擦力计算采用乘法模式
static_friction=1.0, # 静摩擦系数
dynamic_friction=1.0, # 动摩擦系数
),
)
# 机器人配置(由子类具体指定)
robot: ArticulationCfg = MISSING
# 高度扫描传感器:用于感知前方地形起伏
height_scanner = RayCasterCfg(
prim_path="{ENV_REGEX_NS}/Robot/base",
offset=RayCasterCfg.OffsetCfg(pos=(0.0, 0.0, 20.0)), # 从 20m 高度向下发射射线
pattern_cfg=patterns.GridPatternCfg(resolution=0.1, size=[1.6, 1.0]),
mesh_prim_paths=["/World/ground"],
)
# 接触力传感器:检测机器人与环境的接触
contact_forces = ContactSensorCfg(
prim_path="{ENV_REGEX_NS}/Robot/.*", # 监测所有机器人部件
history_length=3, # 保存 3 帧历史数据
track_air_time=True, # 追踪腾空时间
)这里有几个关键设计值得深入理解。首先是 {ENV_REGEX_NS} 占位符,这是 Isaac Lab 实现大规模并行仿真的核心机制。当设置 num_envs=4096 时,Isaac Lab 会自动将场景中的机器人克隆 4096 份,每份位于独立的命名空间中。{ENV_REGEX_NS} 在运行时会被替换为 /World/envs/env_0、/World/envs/env_1 等具体路径,从而实现单个配置支持大规模并行训练。
其次是高度扫描传感器的设计。该传感器模拟了真实机器人上常见的激光雷达或深度相机,通过向下发射射线网格来感知前方地形。默认配置采用 0.1m 分辨率、1.6m×1.0m 范围的网格,这一参数需要根据机器人的尺寸和任务需求进行调整。对于小型四足机器人,可能需要更高的分辨率;对于高速运动场景,则可能需要更大的感知范围。
1.2.2 命令配置 (CommandsCfg)
命令配置定义了策略需要跟踪的目标速度。在速度跟踪任务中,命令生成器会周期性地产生新的目标速度,策略的目标是使机器人的实际速度尽可能接近这些命令值。命令的设计直接影响训练出的策略的泛化能力------如果训练时只使用单一速度,策略在面对其他速度时可能表现不佳。
python
@configclass
class CommandsCfg:
"""命令配置:定义目标速度的采样范围与重采样策略"""
base_velocity = mdp.UniformThresholdVelocityCommandCfg(
asset_name="robot",
resampling_time_range=(10.0, 10.0), # 每 10 秒重新采样一次目标速度
rel_standing_envs=0.02, # 2% 的环境会收到零速度命令(站立)
rel_heading_envs=1.0, # 100% 的环境使用朝向命令模式
heading_command=True, # 启用朝向命令
heading_control_stiffness=0.5, # 朝向控制的刚度参数
ranges=mdp.UniformThresholdVelocityCommandCfg.Ranges(
lin_vel_x=(-1.0, 1.0), # 前后方向线速度范围 [m/s]
lin_vel_y=(-1.0, 1.0), # 左右方向线速度范围 [m/s]
ang_vel_z=(-1.0, 1.0), # 偏航角速度范围 [rad/s]
heading=(-math.pi, math.pi), # 目标朝向范围 [rad]
),
)rel_standing_envs=0.02 这个参数看似简单,实则蕴含重要的训练技巧。在强化学习训练过程中,如果所有环境都持续发送非零速度命令,策略可能学不会站立不动。通过让 2% 的环境持续发送零速度命令,可以确保策略具备稳定站立的能力。这一技巧在实际机器人部署时尤为重要------用户下达的命令不可能永远是非零的。
1.2.3 动作配置 (ActionsCfg)
动作配置定义了策略网络输出如何转换为机器人的控制指令。Robot Lab 主要采用关节位置控制模式,即策略输出目标关节角度,底层 PD 控制器负责跟踪这些目标角度。这种控制方式相比直接输出力矩更加稳定,也更容易迁移到真实机器人。
python
@configclass
class ActionsCfg:
"""动作配置:定义策略输出到关节控制的映射"""
joint_pos = mdp.JointPositionActionCfg(
asset_name="robot",
joint_names=[".*"], # 正则表达式匹配所有关节
scale=0.5, # 动作缩放因子
use_default_offset=True, # 使用默认关节位置作为偏移基准
clip=None, # 不对动作进行裁剪
preserve_order=True, # 保持关节的定义顺序
)scale 参数是动作配置中最关键的超参数之一。策略网络通常输出 -1, 1 范围内的归一化动作值,scale=0.5 意味着将其映射为 -0.5, 0.5 弧度的关节角度偏移。这个值的选择需要权衡:过小会限制机器人的运动幅度,可能导致步幅不足;过大则可能导致动作过于剧烈,引发不稳定。不同机器人由于关节限位和动力学特性的差异,需要针对性地调整这一参数。
对于轮式机器人如 Go2W,动作配置需要更复杂的设计,因为腿部关节和轮子关节需要不同的控制模式:
python
# 轮式机器人的混合动作配置
@configclass
class UnitreeGo2WActionsCfg(ActionsCfg):
# 腿部关节:位置控制
joint_pos = mdp.JointPositionActionCfg(
joint_names=[".*_hip_joint", ".*_thigh_joint", ".*_calf_joint"],
scale=0.25,
)
# 轮子关节:速度控制
joint_vel = mdp.JointVelocityActionCfg(
joint_names=[".*_foot_joint"],
scale=5.0, # 轮子速度控制需要更大的缩放
)1.2.4 观测配置 (ObservationsCfg)
观测配置是连接环境状态与策略输入的桥梁。Robot Lab 采用了非对称 Actor-Critic 架构的观测设计:策略网络(Actor)接收带噪声的观测,模拟真实传感器的测量误差;评论家网络(Critic)则接收无噪声的"特权信息",这有助于训练过程的稳定性。这种设计是 Sim-to-Real 迁移成功的关键因素之一。
python
@configclass
class ObservationsCfg:
"""观测配置:定义策略和评论家的输入"""
@configclass
class PolicyCfg(ObsGroup):
"""策略网络观测组 - 带噪声以模拟真实传感器"""
# 基座线速度(机体坐标系)
base_lin_vel = ObsTerm(
func=mdp.base_lin_vel,
noise=Unoise(n_min=-0.1, n_max=0.1), # 均匀噪声 ±0.1 m/s
clip=(-100.0, 100.0),
scale=1.0,
)
# 基座角速度
base_ang_vel = ObsTerm(
func=mdp.base_ang_vel,
noise=Unoise(n_min=-0.2, n_max=0.2), # 角速度噪声更大
)
# 重力投影向量(用于感知姿态倾斜)
projected_gravity = ObsTerm(
func=mdp.projected_gravity,
noise=Unoise(n_min=-0.05, n_max=0.05),
)
# 目标速度命令
velocity_commands = ObsTerm(func=mdp.generated_commands)
# 关节位置(相对于默认位置)
joint_pos = ObsTerm(func=mdp.joint_pos_rel, noise=Unoise(n_min=-0.01, n_max=0.01))
# 关节速度
joint_vel = ObsTerm(func=mdp.joint_vel_rel, noise=Unoise(n_min=-1.5, n_max=1.5))
# 上一步动作(提供时序信息)
actions = ObsTerm(func=mdp.last_action)
# 高度扫描(地形感知)
height_scan = ObsTerm(func=mdp.height_scan, noise=Unoise(n_min=-0.1, n_max=0.1))
def __post_init__(self):
self.enable_corruption = True # 启用噪声
self.concatenate_terms = True # 将所有观测项拼接为单一向量
@configclass
class CriticCfg(ObsGroup):
"""评论家网络观测组 - 无噪声的特权信息"""
# 与 PolicyCfg 相同的观测项,但不添加噪声
# ... (结构相同,省略噪声参数)
def __post_init__(self):
self.enable_corruption = False # 不启用噪声
policy: PolicyCfg = PolicyCfg()
critic: CriticCfg = CriticCfg()观测设计中有几个值得关注的细节。首先,projected_gravity 提供了机器人姿态的关键信息。该向量表示重力方向在机体坐标系中的投影,当机器人直立时接近 0, 0, -1,倾斜时则会发生变化。相比直接使用欧拉角或四元数,重力投影在数值上更加稳定,不存在万向锁问题。
其次,last_action 的加入为策略提供了时序连续性。强化学习中的马尔可夫假设要求当前状态包含决策所需的全部信息,但单帧观测往往不足以推断关节速度的变化趋势。加入历史动作可以帮助策略预测当前关节的运动状态,从而做出更加平滑的控制决策。
噪声的设置也有讲究。关节位置的噪声相对较小(±0.01 rad),因为真实机器人的编码器精度通常较高。关节速度的噪声则较大(±1.5 rad/s),因为速度通常是通过差分计算得到的,噪声会被放大。这种差异化的噪声设计使得训练出的策略更接近真实部署场景。
1.2.5 事件配置 (EventCfg) - 域随机化
域随机化(Domain Randomization)是弥合仿真与现实差距的核心技术。其基本思想是:如果策略能够在具有广泛物理参数变化的仿真环境中稳定工作,那么它很可能也能在真实世界中表现良好。Robot Lab 的事件配置将域随机化事件分为三类,分别在不同的时间点触发。
python
@configclass
class EventCfg:
"""事件配置:定义域随机化策略"""
# ========== startup 事件:每个仿真会话执行一次 ==========
# 这类事件在整个训练过程中只执行一次,用于设置不会动态变化的参数
randomize_rigid_body_material = EventTerm(
func=mdp.randomize_rigid_body_material,
mode="startup",
params={
"asset_cfg": SceneEntityCfg("robot", body_names=".*"),
"static_friction_range": (0.3, 1.0), # 静摩擦系数范围
"dynamic_friction_range": (0.3, 0.8), # 动摩擦系数范围
"restitution_range": (0.0, 0.5), # 弹性恢复系数
"num_buckets": 64, # 离散化桶数
},
)
randomize_rigid_body_mass_base = EventTerm(
func=mdp.randomize_rigid_body_mass,
mode="startup",
params={
"asset_cfg": SceneEntityCfg("robot", body_names="base"),
"mass_distribution_params": (-1.0, 3.0), # 质量变化范围 kg
"operation": "add", # 加法操作
"recompute_inertia": True, # 重新计算惯性张量
},
)
# ========== reset 事件:每个 episode 开始时执行 ==========
# 这类事件在每次环境重置时触发,用于模拟初始条件的不确定性
randomize_actuator_gains = EventTerm(
func=mdp.randomize_actuator_gains,
mode="reset",
params={
"asset_cfg": SceneEntityCfg("robot", joint_names=".*"),
"stiffness_distribution_params": (0.5, 2.0), # 刚度缩放范围
"damping_distribution_params": (0.5, 2.0), # 阻尼缩放范围
"operation": "scale",
},
)
randomize_reset_base = EventTerm(
func=mdp.reset_root_state_uniform,
mode="reset",
params={
"pose_range": {"x": (-0.5, 0.5), "y": (-0.5, 0.5), "yaw": (-3.14, 3.14)},
"velocity_range": {"x": (-0.5, 0.5), "y": (-0.5, 0.5)},
},
)
# ========== interval 事件:episode 进行中周期执行 ==========
# 这类事件在 episode 运行过程中按指定间隔触发,模拟外部扰动
randomize_push_robot = EventTerm(
func=mdp.push_by_setting_velocity,
mode="interval",
interval_range_s=(10.0, 15.0), # 每 10-15 秒触发一次
params={"velocity_range": {"x": (-0.5, 0.5), "y": (-0.5, 0.5)}},
)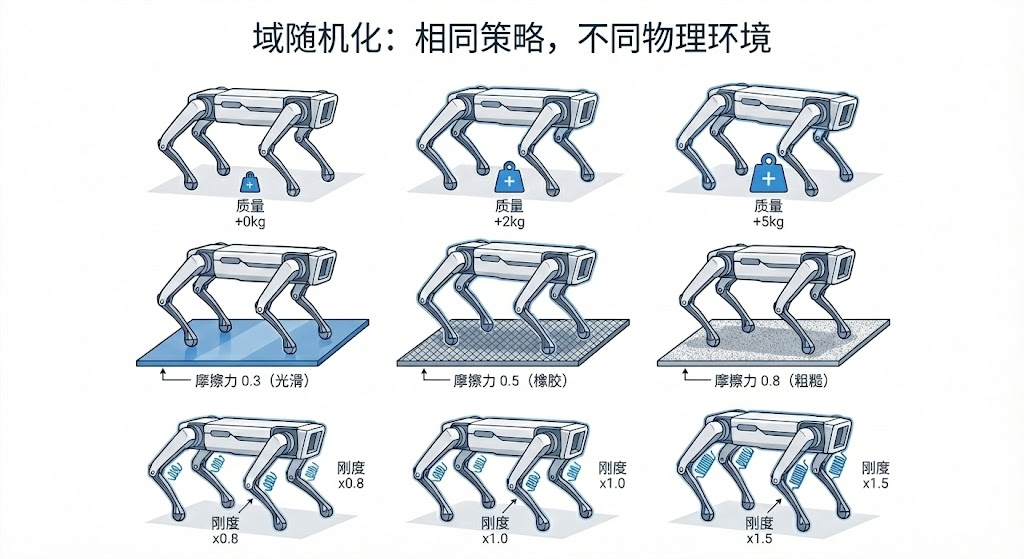
三种事件模式的设计体现了对真实世界不确定性来源的深刻理解。Startup 事件模拟的是制造公差------每台机器人出厂时的摩擦系数、质量等参数都略有不同,但在使用过程中基本保持不变。Reset 事件模拟的是使用场景的多样性------机器人每次启动时可能面对不同的初始姿态和地面条件。Interval 事件则模拟运行时的外部干扰------如被推撞、风力作用等。
执行器增益的随机化特别值得关注。stiffness_distribution_params=(0.5, 2.0) 意味着 PD 控制器的刚度参数可能是标称值的 50% 到 200%。这种大范围的随机化迫使策略学习对执行器特性不敏感的控制策略,从而提高对真实机器人执行器特性变化的鲁棒性。
1.2.6 奖励配置 (RewardsCfg)
奖励函数是强化学习的核心,它定义了我们希望智能体学习的行为。Robot Lab 提供了超过 30 个预定义的奖励项,涵盖速度跟踪、能耗优化、姿态稳定、步态协调等多个维度。设计良好的奖励函数是训练成功的关键,而 Robot Lab 的模块化设计使得奖励调优变得相对简单------只需调整权重,无需修改底层实现。
python
@configclass
class RewardsCfg:
"""奖励配置:定义强化学习的目标函数"""
# ==================== 核心任务奖励 ====================
# 线速度跟踪(指数形式,越接近目标奖励越高)
track_lin_vel_xy_exp = RewTerm(
func=mdp.track_lin_vel_xy_exp,
weight=0.0, # 默认禁用,由子类设置具体权重
params={"command_name": "base_velocity", "std": math.sqrt(0.25)},
)
# 角速度跟踪
track_ang_vel_z_exp = RewTerm(
func=mdp.track_ang_vel_z_exp,
weight=0.0,
params={"command_name": "base_velocity", "std": math.sqrt(0.25)},
)
# ==================== 基座稳定性惩罚 ====================
lin_vel_z_l2 = RewTerm(func=mdp.lin_vel_z_l2, weight=0.0) # 垂直速度
ang_vel_xy_l2 = RewTerm(func=mdp.ang_vel_xy_l2, weight=0.0) # 横滚/俯仰角速度
flat_orientation_l2 = RewTerm(func=mdp.flat_orientation_l2, weight=0.0) # 姿态水平
# ==================== 能耗与平滑性惩罚 ====================
joint_torques_l2 = RewTerm(func=mdp.joint_torques_l2, weight=0.0) # 关节力矩
joint_acc_l2 = RewTerm(func=mdp.joint_acc_l2, weight=0.0) # 关节加速度
action_rate_l2 = RewTerm(func=mdp.action_rate_l2, weight=0.0) # 动作变化率
joint_power = RewTerm(func=mdp.joint_power, weight=0.0) # 关节功率
# ==================== 步态相关奖励 ====================
feet_air_time = RewTerm(func=mdp.feet_air_time, weight=0.0) # 腾空时间
feet_gait = RewTerm(func=mdp.GaitReward, weight=0.0) # 步态同步(对角小跑)
feet_slide = RewTerm(func=mdp.feet_slide, weight=0.0) # 滑动惩罚
feet_stumble = RewTerm(func=mdp.feet_stumble, weight=0.0) # 绊倒惩罚
# ==================== 安全与约束 ====================
joint_pos_limits = RewTerm(func=mdp.joint_pos_limits, weight=0.0) # 关节限位
undesired_contacts = RewTerm(func=mdp.undesired_contacts, weight=0.0) # 非期望接触
is_terminated = RewTerm(func=mdp.is_terminated, weight=0.0) # 终止惩罚奖励函数的设计遵循几个核心原则。第一是稀疏与稠密的平衡:track_lin_vel_xy_exp 使用指数形式而非简单的误差平方,是因为指数函数在目标附近提供更强的梯度信号,有助于精细调整,而在远离目标时梯度平缓,避免策略陷入局部最优。
第二是正负奖励的平衡:正权重鼓励期望行为,负权重惩罚不期望行为。一个经验法则是确保在理想行为下总奖励为正,这有助于训练稳定性。例如,如果速度跟踪奖励权重为 3.0,各类惩罚项的总权重绝对值不应超过这个值太多。
第三是物理意义的清晰性:每个奖励项都对应明确的物理含义。joint_torques_l2 惩罚大力矩输出,这既是能耗优化的需要,也有助于保护电机;feet_slide 惩罚脚在接触地面时的滑动,这在真实机器人上会导致磨损和不稳定。
基类中所有奖励项的默认权重都是 0,这意味着它们默认处于禁用状态。子类根据具体机器人的特性选择性地启用并设置权重。这种设计既保证了基类的通用性,又给予子类充分的定制空间。
1.2.7 终止条件配置 (TerminationsCfg)
终止条件定义了 episode 何时结束。合理的终止条件对训练效率至关重要------如果机器人已经摔倒或偏离任务目标,继续运行只会浪费计算资源并可能引入无效的训练样本。
python
@configclass
class TerminationsCfg:
"""终止条件配置"""
# 超时终止:达到最大 episode 长度
time_out = DoneTerm(func=mdp.time_out, time_out=True)
# 越界终止:机器人离开地形边界
terrain_out_of_bounds = DoneTerm(
func=mdp.terrain_out_of_bounds,
params={"asset_cfg": SceneEntityCfg("robot"), "distance_buffer": 3.0},
time_out=True, # 标记为超时而非失败,不影响价值估计
)
# 非法接触终止:检测到不期望的接触(如躯干碰地)
illegal_contact = DoneTerm(
func=mdp.illegal_contact,
params={"sensor_cfg": SceneEntityCfg("contact_forces", body_names=""), "threshold": 1.0},
)time_out=True 参数区分了两类终止:超时终止和失败终止。这一区分在 PPO 等算法中用于正确估计价值函数------超时终止意味着 episode 被人为截断,理论上机器人还可以继续获得奖励;而失败终止则表示真正的任务失败,后续奖励为零。
1.2.8 课程学习配置 (CurriculumCfg)
课程学习是一种渐进式训练策略,通过逐步增加任务难度来提高学习效率。Robot Lab 支持地形难度课程和命令范围课程两种形式。
python
@configclass
class CurriculumCfg:
"""课程学习配置"""
# 地形难度课程:根据表现自动调整地形难度
terrain_levels = CurrTerm(func=mdp.terrain_levels_vel)
# 线速度命令课程:逐步增加速度命令范围
command_levels_lin_vel = CurrTerm(
func=mdp.command_levels_lin_vel,
params={"reward_term_name": "track_lin_vel_xy_exp", "range_multiplier": (0.1, 1.0)},
)
# 角速度命令课程
command_levels_ang_vel = CurrTerm(
func=mdp.command_levels_ang_vel,
params={"reward_term_name": "track_ang_vel_z_exp", "range_multiplier": (0.1, 1.0)},
)range_multiplier=(0.1, 1.0) 意味着训练初期只使用目标范围的 10%,随着策略改进逐步增加到 100%。这种设计的好处是策略可以先学会在低速下稳定行走,然后逐步挑战高速运动,而不是从一开始就面对全范围的速度命令可能导致的训练不稳定。
1.3 子类配置示例:UnitreeG1RoughEnvCfg
理解了基类的设计之后,我们来看如何通过子类实现机器人特定的配置。以 Unitree G1 人形机器人为例,其粗糙地形配置继承自 LocomotionVelocityRoughEnvCfg,并通过 __post_init__ 方法覆盖需要定制的参数。
python
@configclass
class UnitreeG1RoughEnvCfg(LocomotionVelocityRoughEnvCfg):
"""Unitree G1 人形机器人粗糙地形环境配置"""
# 机器人结构信息
base_link_name = "torso_link" # 基座链接名称
foot_link_name = ".*_ankle_roll_link" # 足部链接(正则匹配)
def __post_init__(self):
# 必须首先调用父类初始化
super().__post_init__()
# ==================== 场景配置 ====================
# 指定机器人资产(29 自由度配置)
self.scene.robot = UNITREE_G1_29DOF_CFG.replace(prim_path="{ENV_REGEX_NS}/Robot")
# 配置传感器安装位置
self.scene.height_scanner.prim_path = "{ENV_REGEX_NS}/Robot/" + self.base_link_name
# ==================== 观测配置 ====================
# 调整观测缩放因子(人形机器人的速度范围与四足不同)
self.observations.policy.base_lin_vel.scale = 2.0
self.observations.policy.base_ang_vel.scale = 0.25
self.observations.policy.joint_vel.scale = 0.05
# 禁用不需要的观测项
self.observations.policy.base_lin_vel = None # G1 不使用线速度观测
self.observations.policy.height_scan = None # 禁用地形扫描
# ==================== 动作配置 ====================
# 使用针对 G1 优化的动作缩放参数
self.actions.joint_pos.scale = UNITREE_G1_29DOF_ACTION_SCALE
# ==================== 奖励配置(核心定制部分)====================
# 人形机器人需要强烈惩罚摔倒
self.rewards.is_terminated.weight = -200.0
# 速度跟踪奖励
self.rewards.track_lin_vel_xy_exp.weight = 3.0
self.rewards.track_lin_vel_xy_exp.func = mdp.track_lin_vel_xy_yaw_frame_exp
self.rewards.track_ang_vel_z_exp.weight = 3.0
# 姿态稳定性惩罚(人形机器人更容易翻倒)
self.rewards.ang_vel_xy_l2.weight = -0.1
self.rewards.flat_orientation_l2.weight = -0.2
# 能耗惩罚(人形机器人关节更多,使用更小的系数)
self.rewards.joint_torques_l2.weight = -1.5e-7
self.rewards.joint_acc_l2.weight = -1.25e-7
self.rewards.action_rate_l2.weight = -0.005
# 步态相关
self.rewards.feet_air_time.weight = 0.25
self.rewards.feet_air_time.func = mdp.feet_air_time_positive_biped
self.rewards.feet_slide.weight = -0.2
# 保持直立
self.rewards.upward.weight = 1.0
# 禁用零权重奖励项以优化性能
if self.__class__.__name__ == "UnitreeG1RoughEnvCfg":
self.disable_zero_weight_rewards()
# ==================== 课程学习配置 ====================
# 人形机器人训练初期不稳定,禁用地形课程
self.curriculum.terrain_levels = None
self.curriculum.command_levels_lin_vel = None
self.curriculum.command_levels_ang_vel = None这段配置代码展示了几个重要的定制点。首先,is_terminated.weight = -200.0 的设置反映了人形机器人与四足机器人的本质差异------人形机器人一旦摔倒几乎无法自主恢复,因此需要强烈惩罚摔倒行为,而四足机器人由于重心低、支撑面大,可能不需要如此强的惩罚。
其次,观测缩放因子的调整体现了对不同机器人动力学特性的适配。G1 的 base_ang_vel.scale = 0.25 意味着角速度观测被压缩到 1/4,这可能是因为 G1 的角速度范围较大,需要归一化到与其他观测相近的数值范围,以便神经网络更好地处理。
最后,课程学习的禁用是一个实践经验的体现。人形机器人在训练初期往往连基本的站立都难以完成,如果此时启用地形课程,所有机器人都会集中在最简单的地形上,无法获得多样化的训练样本。因此建议先在平地上训练稳定的策略,再考虑迁移到复杂地形。
1.4 简化配置:UnitreeG1FlatEnvCfg
在完成粗糙地形配置之后,Robot Lab 通常还会提供一个平地配置作为训练的入门版本。平地配置继承自粗糙地形配置,通过禁用复杂的地形生成和相关传感器,大幅降低训练难度。这种设计遵循"先易后难"的训练原则------在简单环境中先训练出基本稳定的策略,再逐步迁移到复杂环境。
python
@configclass
class UnitreeG1FlatEnvCfg(UnitreeG1RoughEnvCfg):
def __post_init__(self):
super().__post_init__()
# 改为平地
self.scene.terrain.terrain_type = "plane"
self.scene.terrain.terrain_generator = None
# 禁用高度扫描
self.scene.height_scanner = None
self.observations.policy.height_scan = None
# 禁用地形课程
self.curriculum.terrain_levels = None
# 调整奖励权重
self.rewards.track_ang_vel_z_exp.weight = 1.0平地配置的核心修改可以归纳为三个方面。第一是地形简化:将 terrain_type 设置为 "plane" 并禁用地形生成器,这意味着训练环境变成了一个无限大的平面,没有任何障碍物或坡度。第二是传感器简化:禁用高度扫描传感器和对应的观测项,因为平地上不需要感知地形起伏。这不仅减少了观测空间的维度,也降低了策略网络的输入复杂度。第三是课程禁用:由于只有一种地形,地形难度课程学习自然也失去了意义。
值得注意的是,track_ang_vel_z_exp.weight 从 3.0 降低到 1.0。这一调整反映了一个实践经验:在平地上,角速度跟踪相对容易实现,过高的权重可能导致策略过度关注旋转而忽略线速度跟踪。适当降低权重可以获得更加平衡的行为。
平地配置的另一个重要用途是调试。当新机器人的粗糙地形训练遇到困难时,可以先切换到平地配置排查问题。如果在平地上也无法训练成功,说明问题出在基础配置上(如奖励函数设计、动作空间定义等);如果平地训练成功但粗糙地形失败,则问题可能在于地形相关的配置或课程学习策略。
2. 强化学习 Agent 配置
Robot Lab 支持多种强化学习框架,其中 RSL-RL 是最常用的选择。RSL-RL 是由苏黎世联邦理工学院机器人系统实验室(Robotic Systems Lab)开发的高性能强化学习库,专门针对足式机器人运动控制任务进行了优化。它实现了 PPO(Proximal Policy Optimization)算法的高效 GPU 并行版本,能够充分利用 Isaac Lab 的大规模并行仿真能力。
Agent 配置定义了强化学习算法的超参数,包括网络架构、优化器设置、PPO 特定参数等。与环境配置类似,Agent 配置也采用继承机制,允许针对不同机器人进行定制。理解这些参数的含义和调优方法,是提高训练效率和最终策略质量的关键。
2.1 RSL-RL PPO 配置详解
RL Agent 配置位于各机器人目录下的 agents/rsl_rl_ppo_cfg.py 文件中。以 Unitree G1 为例,其配置继承自 RSL-RL 提供的基类,并针对人形机器人的特性进行了调整。
python
@configclass
class UnitreeG1RoughPPORunnerCfg(RslRlOnPolicyRunnerCfg):
# ===== 训练控制参数 =====
num_steps_per_env = 24 # 每个环境采样步数
max_iterations = 20000 # 最大训练迭代次数
save_interval = 200 # 模型保存间隔
experiment_name = "unitree_g1_rough"
# ===== 网络架构配置 =====
policy = RslRlPpoActorCriticCfg(
init_noise_std=1.0, # 初始动作噪声标准差
actor_obs_normalization=False, # Actor 观测归一化
critic_obs_normalization=False, # Critic 观测归一化
actor_hidden_dims=[512, 256, 128], # Actor 网络隐藏层
critic_hidden_dims=[512, 256, 128], # Critic 网络隐藏层
activation="elu", # 激活函数
)
# ===== PPO 算法超参数 =====
algorithm = RslRlPpoAlgorithmCfg(
value_loss_coef=1.0, # 价值损失系数
use_clipped_value_loss=True, # 使用裁剪价值损失
clip_param=0.2, # PPO 裁剪参数
entropy_coef=0.008, # 熵系数(探索)
num_learning_epochs=5, # 每次更新的 epoch 数
num_mini_batches=4, # mini-batch 数量
learning_rate=1.0e-3, # 学习率
schedule="adaptive", # 学习率调度策略
gamma=0.99, # 折扣因子
lam=0.95, # GAE lambda
desired_kl=0.01, # 目标 KL 散度
max_grad_norm=1.0, # 梯度裁剪
)2.2 关键参数说明
| 参数 | 默认值 | 说明 |
|---|---|---|
num_steps_per_env |
24 | 每个环境在一次更新中采样的步数 |
actor_hidden_dims |
512, 256, 128 | Actor 网络架构 |
clip_param |
0.2 | PPO 裁剪范围,防止策略更新过大 |
entropy_coef |
0.008-0.01 | 熵系数,控制探索程度 |
gamma |
0.99 | 折扣因子,决定对未来奖励的重视程度 |
lam |
0.95 | GAE 参数,平衡偏差和方差 |
desired_kl |
0.01 | 目标 KL 散度,用于自适应学习率 |
下面对几个关键参数进行深入解析。
num_steps_per_env(每环境采样步数) :这个参数决定了在每次策略更新前,每个并行环境需要收集多少步的经验数据。假设有 4096 个并行环境,num_steps_per_env=24 意味着每次更新前会收集 4096 × 24 = 98304 个样本。这个值的选择需要权衡:过小可能导致梯度估计方差大,训练不稳定;过大则会增加单次更新的时间,降低数据利用效率。对于运动控制任务,24 是一个经过验证的合理默认值。
clip_param(PPO 裁剪参数):这是 PPO 算法的核心超参数,用于限制策略更新的幅度。具体来说,PPO 的目标函数会裁剪重要性采样比率到 1-clip_param, 1+clip_param 范围内,防止单次更新导致策略变化过大。0.2 是论文推荐的默认值,在大多数任务中表现良好。如果训练过程中策略震荡,可以尝试减小这个值。
entropy_coef(熵系数):熵正则化用于鼓励策略保持一定程度的随机性,避免过早收敛到局部最优。较大的熵系数会增加探索性,但可能导致策略不够确定;较小的值则相反。Robot Lab 中人形机器人使用 0.008,四足机器人使用 0.01,这一差异反映了不同机器人对探索需求的不同------人形机器人的动作空间更大,可能需要更加确定的策略来保持稳定。
gamma 和 lam(折扣因子和 GAE 参数) :gamma=0.99 意味着智能体会重视未来约 100 步(1/(1-0.99))的累积奖励。lam=0.95 是 GAE(Generalized Advantage Estimation)的平滑参数,用于在偏差和方差之间取得平衡。这两个值在大多数连续控制任务中都是合理的默认选择。
schedule="adaptive"(自适应学习率) :RSL-RL 支持自适应学习率调整,当策略更新的 KL 散度超过 desired_kl 时自动降低学习率,反之则提高。这种机制可以在训练初期使用较大的学习率加速收敛,在后期自动降低学习率以稳定训练。
2.3 不同机器人的 Agent 配置对比
不同类型的机器人由于动力学特性和任务难度的差异,需要针对性地调整 Agent 配置。下表对比了三种典型机器人的配置差异:
| 参数 | G1 (人形) | GO2 (四足) | Agibot D1 |
|---|---|---|---|
max_iterations |
20000 | 20000 | 20000 |
entropy_coef |
0.008 | 0.01 | 0.01 |
save_interval |
200 | 100 | 100 |
从表中可以看出,人形机器人的熵系数略低于四足机器人。这是因为人形机器人的平衡更加困难,需要策略输出更加确定的动作来维持稳定。而四足机器人由于四个支撑点带来的天然稳定性,可以承受更多的探索。
save_interval 的差异则反映了训练监控的需求。人形机器人的训练过程更长且更不稳定,较大的保存间隔可以减少存储开销;四足机器人训练相对稳定,更频繁的保存有助于选择最佳检查点
3. 添加新机器人(以 Agibot 为例)
将新机器人集成到 Robot Lab 是一个结构化的过程,需要按照特定的步骤创建配置文件并注册环境。本节以 Agibot D1 四足机器人为例,详细介绍完整的添加流程。Agibot D1 是一款教育级四足机器人,拥有 12 个关节自由度(每条腿 3 个:外展、髋关节、膝关节),是学习 Robot Lab 配置体系的理想案例。
3.1 完整流程概览
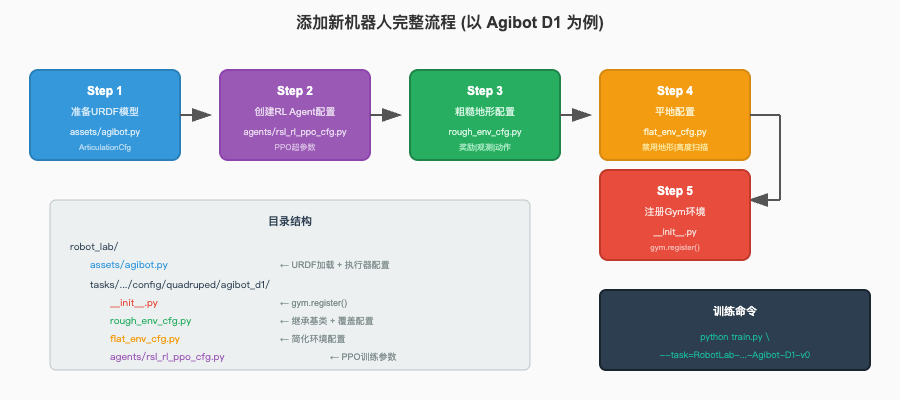
添加新机器人涉及 5 个核心步骤,需要在两个目录下创建相应的文件。assets/ 目录存放机器人资产配置,定义模型文件路径、关节参数、执行器特性等;tasks/.../config/ 目录存放任务配置,定义环境参数、奖励函数、训练算法等。这种分离设计使得同一机器人可以被多个不同任务复用。
robot_lab/
├── assets/
│ └── agibot.py # 步骤1: 资产配置
└── tasks/manager_based/locomotion/velocity/config/quadruped/agibot_d1/
├── __init__.py # 步骤5: 环境注册
├── rough_env_cfg.py # 步骤3: 粗糙地形配置
├── flat_env_cfg.py # 步骤4: 平地配置
└── agents/
├── __init__.py
├── rsl_rl_ppo_cfg.py # 步骤2: RL配置
└── cusrl_ppo_cfg.py3.2 步骤1: 创建资产配置
资产配置是添加新机器人的第一步,它定义了机器人的物理模型如何在仿真环境中加载和初始化。资产配置文件通常位于 robot_lab/assets/ 目录下,以机器人名称命名。
文件:robot_lab/assets/agibot.py
python
import isaaclab.sim as sim_utils
from isaaclab.actuators import DCMotorCfg
from isaaclab.assets.articulation import ArticulationCfg
from robot_lab.assets import ISAACLAB_ASSETS_DATA_DIR
AGIBOT_D1_CFG = ArticulationCfg(
# 模型加载配置
spawn=sim_utils.UrdfFileCfg(
fix_base=False, # 基座不固定
merge_fixed_joints=True, # 合并固定关节
asset_path=f"{ISAACLAB_ASSETS_DATA_DIR}/Robots/agibot/d1/urdf/edu.urdf",
activate_contact_sensors=True, # 启用接触传感器
rigid_props=sim_utils.RigidBodyPropertiesCfg(
disable_gravity=False,
max_linear_velocity=1000.0,
max_angular_velocity=1000.0,
),
articulation_props=sim_utils.ArticulationRootPropertiesCfg(
enabled_self_collisions=False,
solver_position_iteration_count=4,
),
),
# 初始状态配置
init_state=ArticulationCfg.InitialStateCfg(
pos=(0.0, 0.0, 0.42), # 初始位置 (x, y, z)
joint_pos={
".*L_ABAD_JOINT": 0.0, # 左侧外展关节
".*R_ABAD_JOINT": 0.0, # 右侧外展关节
"F.*_HIP_JOINT": 0.8, # 前腿髋关节
"R.*_HIP_JOINT": 0.8, # 后腿髋关节
".*_KNEE_JOINT": -1.5, # 膝关节
},
joint_vel={".*": 0.0}, # 初始速度为0
),
# 执行器配置
actuators={
"legs": DCMotorCfg(
joint_names_expr=[".*_(ABAD|HIP|KNEE)_JOINT"],
effort_limit=33.5, # 力矩限制 Nm
saturation_effort=33.5, # 饱和力矩
velocity_limit=21.0, # 速度限制 rad/s
stiffness=20.0, # PD 控制刚度
damping=0.5, # PD 控制阻尼
),
},
)资产配置的核心包含三个部分。首先是 spawn 配置,指定了机器人模型的加载方式。Isaac Lab 支持 URDF 和 USD 两种格式,其中 URDF 是 ROS 生态系统的标准格式,大多数机器人厂商都会提供。fix_base=False 表示机器人基座可以自由移动(非固定安装),这是运动控制任务的标准设置。merge_fixed_joints=True 会合并所有固定关节以简化动力学计算。
其次是 init_state 配置,定义了机器人的初始姿态。pos=(0.0, 0.0, 0.42) 将机器人放置在离地 0.42 米的位置,这个高度应该足够让机器人在默认关节角度下站立而不会与地面穿透。joint_pos 使用正则表达式匹配关节名称,为不同类型的关节设置初始角度。这种设计允许用简洁的配置覆盖大量关节。
最后是 actuators 配置,定义了执行器(电机)的物理特性。DCMotorCfg 模拟直流电机的行为,包括力矩限制、速度限制以及 PD 控制的刚度和阻尼参数。这些参数应该尽可能接近真实机器人的规格,以便训练出的策略能够迁移到实际硬件
3.3 步骤2: 创建 RL Agent 配置
在定义好机器人资产之后,下一步是配置强化学习训练的超参数。Agent 配置决定了网络架构、优化算法、采样策略等训练相关的设置。对于新机器人,通常可以从类似机器人的配置开始,然后根据训练表现进行微调。
文件:agents/rsl_rl_ppo_cfg.py
python
from isaaclab.utils import configclass
from isaaclab_rl.rsl_rl import RslRlOnPolicyRunnerCfg, RslRlPpoActorCriticCfg, RslRlPpoAlgorithmCfg
@configclass
class AgibotD1RoughPPORunnerCfg(RslRlOnPolicyRunnerCfg):
num_steps_per_env = 24
max_iterations = 20000
save_interval = 100
experiment_name = "agibot_d1_rough"
policy = RslRlPpoActorCriticCfg(
init_noise_std=1.0,
actor_hidden_dims=[512, 256, 128],
critic_hidden_dims=[512, 256, 128],
activation="elu",
)
algorithm = RslRlPpoAlgorithmCfg(
clip_param=0.2,
entropy_coef=0.01,
learning_rate=1.0e-3,
gamma=0.99,
lam=0.95,
)
@configclass
class AgibotD1FlatPPORunnerCfg(AgibotD1RoughPPORunnerCfg):
def __post_init__(self):
super().__post_init__()
self.max_iterations = 5000
self.experiment_name = "agibot_d1_flat"Agent 配置采用了与环境配置类似的继承模式。AgibotD1FlatPPORunnerCfg 继承自 AgibotD1RoughPPORunnerCfg,只需修改实验名称和迭代次数。这是因为平地训练通常更容易收敛,不需要那么多的训练步数。
网络架构 [512, 256, 128] 是一个递减的三层 MLP 结构,这种设计已经在大量运动控制任务中证明了其有效性。对于关节数量较少的机器人(如 Agibot D1 的 12 个关节),可以考虑使用更小的网络(如 [256, 128, 64])以加快训练速度;对于更复杂的机器人,则可能需要更大的网络容量。
3.4 步骤3: 创建粗糙地形环境配置
环境配置是添加新机器人最核心的部分,它决定了训练任务的具体定义。粗糙地形配置继承自 LocomotionVelocityRoughEnvCfg 基类,并通过 __post_init__ 方法定制机器人特定的参数。
文件:rough_env_cfg.py
python
from isaaclab.utils import configclass
from robot_lab.tasks.manager_based.locomotion.velocity.velocity_env_cfg import LocomotionVelocityRoughEnvCfg
from robot_lab.assets.agibot import AGIBOT_D1_CFG
@configclass
class AgibotD1RoughEnvCfg(LocomotionVelocityRoughEnvCfg):
# 机器人特定参数
base_link_name = "BASE_LINK"
foot_link_name = ".*_FOOT_LINK"
joint_names = [
"FR_ABAD_JOINT", "FR_HIP_JOINT", "FR_KNEE_JOINT",
"FL_ABAD_JOINT", "FL_HIP_JOINT", "FL_KNEE_JOINT",
"RR_ABAD_JOINT", "RR_HIP_JOINT", "RR_KNEE_JOINT",
"RL_ABAD_JOINT", "RL_HIP_JOINT", "RL_KNEE_JOINT",
]
def __post_init__(self):
super().__post_init__()
# === 场景配置 ===
self.scene.robot = AGIBOT_D1_CFG.replace(prim_path="{ENV_REGEX_NS}/Robot")
self.scene.height_scanner.prim_path = "{ENV_REGEX_NS}/Robot/" + self.base_link_name
# === 观测配置 ===
self.observations.policy.base_lin_vel.scale = 2.0
self.observations.policy.base_ang_vel.scale = 0.25
self.observations.policy.base_lin_vel = None
self.observations.policy.height_scan = None
self.observations.policy.joint_pos.params["asset_cfg"].joint_names = self.joint_names
# === 动作配置 ===
self.actions.joint_pos.scale = {".*_ABAD_JOINT": 0.125, "^(?!.*_ABAD_JOINT).*": 0.25}
self.actions.joint_pos.joint_names = self.joint_names
# === 奖励配置 ===
self.rewards.lin_vel_z_l2.weight = -2.0
self.rewards.ang_vel_xy_l2.weight = -0.05
self.rewards.joint_torques_l2.weight = -2.5e-5
self.rewards.joint_acc_l2.weight = -2.5e-7
self.rewards.track_lin_vel_xy_exp.weight = 3.0
self.rewards.track_ang_vel_z_exp.weight = 1.5
self.rewards.action_rate_l2.weight = -0.01
self.rewards.feet_height_body.weight = -5.0
self.rewards.upward.weight = 1.0
# 步态配置
self.rewards.feet_gait.params["synced_feet_pair_names"] = (
("FL_FOOT_LINK", "RR_FOOT_LINK"),
("FR_FOOT_LINK", "RL_FOOT_LINK"),
)
# === 终止条件 ===
self.terminations.illegal_contact = None
# 禁用零权重奖励
if self.__class__.__name__ == "AgibotD1RoughEnvCfg":
self.disable_zero_weight_rewards()这段配置代码展示了几个重要的定制技巧。首先是动作缩放的差异化设置:外展关节(ABAD)使用 0.125 的较小缩放,而髋关节和膝关节使用 0.25 的较大缩放。这反映了四足机器人的运动特性------外展动作通常幅度较小,过大的外展角度可能导致步态不稳。正则表达式 "^(?!.*_ABAD_JOINT).*" 使用否定前瞻匹配所有非外展关节。
步态配置中的 synced_feet_pair_names 定义了对角步态的足部配对:前左与后右同步,前右与后左同步。这是四足机器人最常见的小跑步态(trot),在中速行走时具有较好的稳定性和能效。
3.5 步骤4: 创建平地环境配置
平地配置是粗糙地形配置的简化版本,通过禁用地形生成器和相关传感器来降低训练复杂度。这一步骤相对简单,主要是继承和覆盖几个关键参数。
文件:flat_env_cfg.py
python
from isaaclab.utils import configclass
from .rough_env_cfg import AgibotD1RoughEnvCfg
@configclass
class AgibotD1FlatEnvCfg(AgibotD1RoughEnvCfg):
def __post_init__(self):
super().__post_init__()
# 改为平地
self.scene.terrain.terrain_type = "plane"
self.scene.terrain.terrain_generator = None
# 禁用高度扫描和地形课程
self.scene.height_scanner = None
self.observations.policy.height_scan = None
self.curriculum.terrain_levels = None
if self.__class__.__name__ == "AgibotD1FlatEnvCfg":
self.disable_zero_weight_rewards()平地配置的代码非常简洁,只需要覆盖与地形相关的几个参数。这体现了配置继承体系的优势------大部分参数从父类继承,只需修改必要的差异部分。
3.6 步骤5: 注册 Gym 环境
最后一步是将配置好的环境注册到 Gymnasium(OpenAI Gym 的继任者)框架中,使其可以通过标准的环境 ID 进行访问。注册代码位于任务配置目录的 __init__.py 文件中。
文件:__init__.py
python
import gymnasium as gym
from . import agents
# 注册平地环境
gym.register(
id="RobotLab-Isaac-Velocity-Flat-Agibot-D1-v0",
entry_point="isaaclab.envs:ManagerBasedRLEnv",
disable_env_checker=True,
kwargs={
"env_cfg_entry_point": f"{__name__}.flat_env_cfg:AgibotD1FlatEnvCfg",
"rsl_rl_cfg_entry_point": f"{agents.__name__}.rsl_rl_ppo_cfg:AgibotD1FlatPPORunnerCfg",
},
)
# 注册粗糙地形环境
gym.register(
id="RobotLab-Isaac-Velocity-Rough-Agibot-D1-v0",
entry_point="isaaclab.envs:ManagerBasedRLEnv",
disable_env_checker=True,
kwargs={
"env_cfg_entry_point": f"{__name__}.rough_env_cfg:AgibotD1RoughEnvCfg",
"rsl_rl_cfg_entry_point": f"{agents.__name__}.rsl_rl_ppo_cfg:AgibotD1RoughPPORunnerCfg",
},
)环境 ID 的命名遵循 Robot Lab 的约定:RobotLab-Isaac-Velocity-{Terrain}-{Manufacturer}-{Model}-v{Version}。这种结构化的命名便于识别环境的用途和适用的机器人。entry_point 指向 Isaac Lab 提供的通用环境类,而 kwargs 中的 env_cfg_entry_point 和 rsl_rl_cfg_entry_point 则指定了具体的配置类。
完成以上五个步骤后,新机器人就成功集成到 Robot Lab 中了。可以通过以下命令验证注册是否成功:
bash
python -c "import gymnasium as gym; print([e for e in gym.envs.registry if 'Agibot' in e])"如果输出包含刚才注册的环境 ID,说明集成成功,可以开始训练了,训练后效果走路没有问题

4. 调参指南
奖励函数的调优是强化学习训练成功的关键因素之一。不同类型的机器人由于其物理结构、动力学特性和任务需求的差异,需要针对性地设置奖励权重。本节将从实践角度出发,分别介绍四足机器人、人形机器人和轮式机器人的调参策略,帮助读者快速定位和解决常见的训练问题。
Robot Lab 目前支持超过 24 款机器人,涵盖三种主要形态:
| 类型 | 支持的机器人 |
|---|---|
| 人形机器人 | Unitree G1、Unitree H1、FFTAI GR1T1/GR1T2、Magiclab MagicBot Gen1/Z1、Booster T1、Robotera XBot、OpenLoong Loong、RoboParty Atom01 |
| 四足机器人 | Unitree Go2/A1/B2、Anymal D、Agibot D1、Magiclab MagicDog、DeepRobotics Lite3、ZSIBot ZSL1 |
| 轮式机器人 | Unitree Go2W、DeepRobotics M20 等 |
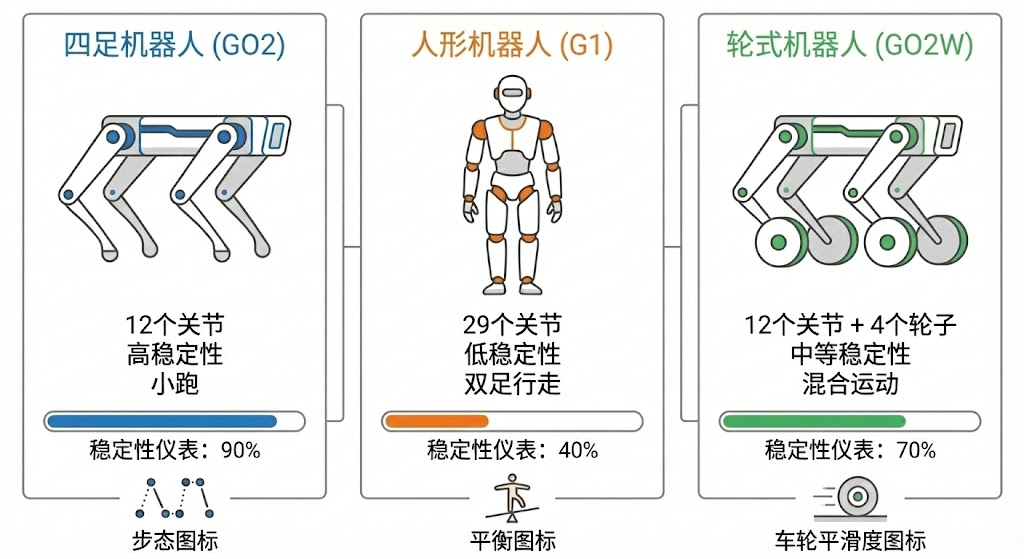
4.1 四足机器人调参(以 GO2 为例)
四足机器人是 Robot Lab 中支持最完善的机器人类型,Unitree GO2 作为代表性的研究平台,其配置经过了大量的调优和验证。理解 GO2 的参数设置,可以为其他四足机器人的调参提供参考基线。
4.1.1 核心奖励权重
| 奖励项 | 推荐值 | 作用 |
|---|---|---|
track_lin_vel_xy_exp |
3.0 | 线速度跟踪(核心目标) |
track_ang_vel_z_exp |
1.5 | 角速度跟踪 |
lin_vel_z_l2 |
-2.0 | 抑制垂直跳动 |
ang_vel_xy_l2 |
-0.05 | 抑制翻滚 |
joint_torques_l2 |
-2.5e-5 | 能耗惩罚 |
joint_acc_l2 |
-2.5e-7 | 动作平滑 |
action_rate_l2 |
-0.01 | 动作变化率 |
feet_air_time |
0.1 | 腾空时间奖励 |
feet_gait |
0.5 | 步态同步 |
feet_slide |
-0.1 | 滑动惩罚 |
upward |
1.0 | 保持直立 |
上表中的权重值经过大量实验验证,可以作为四足机器人的起点配置。其中正权重的奖励项(如速度跟踪、腾空时间)鼓励期望行为,负权重的惩罚项则抑制不期望行为。一个重要的设计原则是确保在理想行为下总奖励为正,这有助于训练的稳定性。
4.1.2 调参技巧
问题1:速度跟踪不收敛
当训练曲线显示线速度跟踪奖励长时间不增长时,可能是因为其他惩罚项过强,压制了策略探索更快速度的动机。解决方法是增大速度跟踪奖励或减小其他惩罚项的权重。
python
# 增大速度跟踪奖励
self.rewards.track_lin_vel_xy_exp.weight = 5.0 # 从3.0增加
# 减小其他惩罚
self.rewards.action_rate_l2.weight = -0.005问题2:步态不稳定
如果机器人能够跟踪速度但步态杂乱(例如四条腿的运动不协调),需要加强步态相关的奖励。feet_gait 奖励鼓励对角腿同步运动,feet_air_time_variance 惩罚四条腿腾空时间的差异。
python
# 增大步态奖励
self.rewards.feet_gait.weight = 1.0 # 从0.5增加
# 增大腾空时间方差惩罚
self.rewards.feet_air_time_variance.weight = -2.0问题3:能耗过高
如果训练出的策略动作幅度过大、力矩输出过高,会导致真实机器人上的能耗问题和电机过热。通过增大力矩和功率相关的惩罚可以引导策略学习更加节能的运动方式。
python
# 增大力矩惩罚
self.rewards.joint_torques_l2.weight = -5e-5 # 加倍
# 增大关节功率惩罚
self.rewards.joint_power.weight = -4e-54.2 人形机器人调参(以 G1 为例)
人形机器人的调参与四足有着本质的不同。由于只有两条腿支撑,人形机器人的平衡余量极小,一旦失去平衡很难恢复。因此,人形机器人的配置更加侧重于姿态稳定性和防摔倒,而对能耗的约束相对宽松。
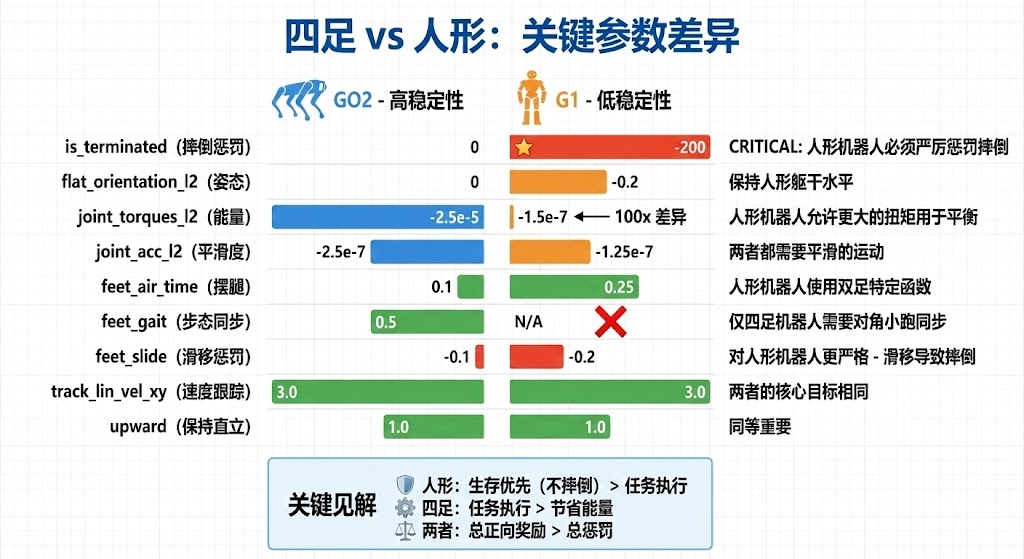
4.2.1 核心奖励权重
下表对比了 Robot Lab 中支持的主要人形机器人的奖励权重配置:
| 奖励项 | G1 | H1 | GR1T2 | XBot | 说明 |
|---|---|---|---|---|---|
track_lin_vel_xy_exp |
3.0 | 3.0 | 5.0 | 2.0 | 核心任务奖励 |
track_ang_vel_z_exp |
3.0 | 3.0 | 5.0 | 2.0 | 角速度跟踪 |
feet_air_time |
0.25 | 1.0 | 1.0 | 2.0 | 迈腿奖励(关键) |
upward |
1.0 | 1.0 | 1.0 | 0.2 | 站立奖励(关键) |
is_terminated |
-200 | -200 | -200 | -200 | 摔倒惩罚 |
flat_orientation_l2 |
-0.2 | -0.2 | -0.5 | 0 | 姿态惩罚 |
joint_torques_l2 |
-1.5e-7 | -1.0e-8 | -2.5e-5 | -2.5e-5 | 能耗惩罚 |
joint_acc_l2 |
-1.25e-7 | -2.5e-7 | -2.5e-7 | -2.5e-7 | 动作平滑 |
action_rate_l2 |
-0.005 | -0.01 | -0.005 | -0.01 | 动作变化率 |
feet_slide |
-0.2 | -0.4 | -0.2 | -0.2 | 滑动惩罚 |
关键发现 :从上表可以看出,feet_air_time(腾空时间奖励)和 upward(站立奖励)是人形机器人学会行走的关键。如果这两个奖励没有启用或权重太低,机器人很可能会"坐着不走"。
4.2.2 人形机器人"坐着不走"问题诊断
典型症状:训练 10 万步后,平均 reward 到达 15-25,但机器人保持蹲坐姿态不迈腿。
这是人形机器人训练中最常见的问题之一。根本原因是策略发现"不动"是获取奖励的局部最优解 ------站着不动不会摔倒(没有 is_terminated 惩罚),关节不动没有能耗(没有 joint_torques_l2 惩罚),只是损失了速度跟踪奖励。
诊断检查清单:
| 检查项 | 正确配置 | 常见错误 |
|---|---|---|
feet_air_time.weight |
≥ 0.25 | 0 或未设置 |
feet_air_time.func |
mdp.feet_air_time_positive_biped |
使用四足函数 |
upward.weight |
≥ 1.0 | 0 或未设置 |
track_lin_vel_xy_exp.weight |
≥ 3.0 | 太小(< 2.0) |
joint_pos_penalty.weight |
0 或较小 | 太大(> -2.0) |
解决方案:
python
# 方案1:启用并增大迈腿奖励(最重要)
self.rewards.feet_air_time.weight = 1.0 # 从 0.25 增加到 1.0
self.rewards.feet_air_time.func = mdp.feet_air_time_positive_biped # 必须用双足函数
self.rewards.feet_air_time.params["threshold"] = 0.4 # 腾空时间阈值
# 方案2:增大站立奖励
self.rewards.upward.weight = 2.0 # 从 1.0 增加
# 方案3:增大速度跟踪奖励
self.rewards.track_lin_vel_xy_exp.weight = 5.0 # 从 3.0 增加
self.rewards.track_ang_vel_z_exp.weight = 3.0
# 方案4:减小关节位置惩罚(让机器人敢于动)
self.rewards.joint_pos_penalty.weight = -0.5 # 或直接设为 04.2.3 人形特殊配置
人形机器人需要一些四足机器人不需要的特殊配置,包括双足专用的腾空时间函数和关节偏差惩罚。
python
# 使用双足专用腾空时间函数(关键配置!)
self.rewards.feet_air_time.func = mdp.feet_air_time_positive_biped
self.rewards.feet_air_time.params["threshold"] = 0.4 # 最小站立相时间
self.rewards.feet_air_time.params["sensor_cfg"].body_names = self.foot_link_name
# 使用偏航坐标系速度跟踪(适应身体朝向变化)
self.rewards.track_lin_vel_xy_exp.func = mdp.track_lin_vel_xy_yaw_frame_exp
# 关节偏差惩罚(保持自然姿态,但不要太大)
self.rewards.create_joint_deviation_l1_rewterm("joint_deviation_hip_l1", -0.1, [".*hip_yaw.*", ".*hip_roll.*"])
self.rewards.create_joint_deviation_l1_rewterm("joint_deviation_arms_l1", -0.1, [".*shoulder.*", ".*elbow.*"])
self.rewards.create_joint_deviation_l1_rewterm("joint_deviation_torso_l1", -0.1, [".*torso.*", ".*waist.*"])feet_air_time_positive_biped 函数与四足版本的关键区别在于:它只在单腿支撑、交替迈步时给予正奖励。如果两只脚同时离地或同时着地,奖励为零。这迫使策略学习正确的双足行走步态。
4.2.4 观测配置对行走的影响
观测空间的配置对人形机器人学习行走同样重要。错误的观测缩放会导致策略无法正确感知状态:
python
# 推荐的观测缩放配置
self.observations.policy.base_lin_vel.scale = 2.0 # 放大线速度感知
self.observations.policy.base_ang_vel.scale = 0.25 # 压缩角速度(范围较大)
self.observations.policy.joint_pos.scale = 1.0 # 关节位置保持原始
self.observations.policy.joint_vel.scale = 0.05 # 压缩关节速度(范围很大)
# 注意:G1/H1 禁用了 base_lin_vel 观测
# 如果你的机器人学不会行走,尝试启用它
self.observations.policy.base_lin_vel = None # 原配置禁用
# 改为:
self.observations.policy.base_lin_vel.scale = 2.0 # 启用并设置缩放4.2.5 常见问题诊断
问题1:机器人坐着不走(最常见)
详见 4.2.2 节。核心是启用 feet_air_time 和 upward 奖励,使用正确的双足腾空函数,并增加训练步数。
问题2:容易摔倒
如果机器人在训练过程中频繁摔倒,需要进一步强化防摔倒的惩罚:
python
# 增大终止惩罚
self.rewards.is_terminated.weight = -500.0
# 增大姿态惩罚
self.rewards.flat_orientation_l2.weight = -0.5
# 增大角速度惩罚(抑制身体晃动)
self.rewards.ang_vel_xy_l2.weight = -0.2问题3:姿态不稳/身体晃动
如果机器人能够行走但身体晃动明显:
python
# 增大直立奖励
self.rewards.upward.weight = 2.0
# 增大角速度惩罚
self.rewards.ang_vel_xy_l2.weight = -0.2
# 增大姿态惩罚
self.rewards.flat_orientation_l2.weight = -0.3问题4:迈腿幅度太小/原地踏步
机器人有迈腿动作但位移很小:
python
# 增大速度跟踪奖励
self.rewards.track_lin_vel_xy_exp.weight = 5.0
# 增大腾空时间奖励
self.rewards.feet_air_time.weight = 1.5
# 减小动作变化率惩罚(允许更大动作)
self.rewards.action_rate_l2.weight = -0.001
# 增大动作缩放
self.actions.joint_pos.scale = 0.35 # 从 0.25 增加问题5:步态不对称/单腿支撑时间不均
python
# 调整腾空时间阈值
self.rewards.feet_air_time.params["threshold"] = 0.5 # 增大站立相要求
# 增大关节对称性惩罚(如果有)
self.rewards.joint_mirror.weight = -0.1问题6:训练初期不稳定/所有机器人集中在最简单地形
人形机器人在训练初期往往连站立都难以完成。必须禁用地形课程学习:
python
# 禁用地形课程(关键!)
self.curriculum.terrain_levels = None
# 禁用速度命令课程
self.curriculum.command_levels_lin_vel = None
self.curriculum.command_levels_ang_vel = None4.3 轮式机器人调参(以 GO2W 为例)
轮式机器人(如 Unitree GO2W,GO2 的轮足版本)结合了腿式和轮式运动的优点,但也带来了独特的控制挑战。最大的区别在于需要同时处理两种不同类型的关节:腿部关节使用位置控制保持身体高度和姿态,轮子关节则使用速度控制实现行进。
4.3.1 特殊配置
轮式机器人的关键是分离腿部和轮子的控制逻辑。这需要在动作空间和奖励函数中都做出相应的调整。
python
# 分离腿部和轮子控制
self.actions.joint_pos.joint_names = self.leg_joint_names # 位置控制
self.actions.joint_vel.joint_names = self.wheel_joint_names # 速度控制
# 分离腿部和轮子惩罚
self.rewards.joint_torques_l2.params["asset_cfg"].joint_names = self.leg_joint_names
self.rewards.joint_acc_wheel_l2.weight = -2.5e-9 # 轮子加速度惩罚较小
self.rewards.joint_acc_wheel_l2.params["asset_cfg"].joint_names = self.wheel_joint_names腿部关节使用 joint_pos 动作(位置控制),轮子使用 joint_vel 动作(速度控制)。奖励函数也需要分别处理:腿部的力矩惩罚和轮子的加速度惩罚使用不同的权重和参数。轮子的加速度惩罚权重(-2.5e-9)比腿部小很多,这是因为轮子需要持续旋转,过强的惩罚会限制其运动能力。
4.3.2 核心差异
| 配置项 | GO2W (轮式) | GO2 (四足) |
|---|---|---|
feet_air_time |
0 (禁用) | 0.1 |
feet_gait |
0 (禁用) | 0.5 |
feet_slide |
0 (禁用) | -0.1 |
base_height_l2.target_height |
0.40 | 0.33 |
joint_acc_wheel_l2 |
-2.5e-9 | N/A |
轮式机器人禁用了所有与步态相关的奖励(腾空时间、步态同步、滑动惩罚),因为轮子始终接触地面,这些概念不再适用。目标基座高度也有所不同------轮式版本需要更高的身体位置(0.40m vs 0.33m),以便轮子有足够的空间运动。
4.3.3 调参技巧
问题1:轮子抖动
如果轮子速度输出不稳定、出现高频振动,需要增大轮子加速度惩罚来平滑控制信号。
python
# 增大轮子加速度惩罚
self.rewards.joint_acc_wheel_l2.weight = -2.5e-8问题2:腿部不稳
轮式机器人的腿部只需要维持身体高度和姿态,但如果位置控制不够精确,可能出现身体晃动。参考四足机器人的调参方法,增大关节位置相关的惩罚。
python
# 参考四足调参,增大相关惩罚
self.rewards.joint_pos_penalty.weight = -2.0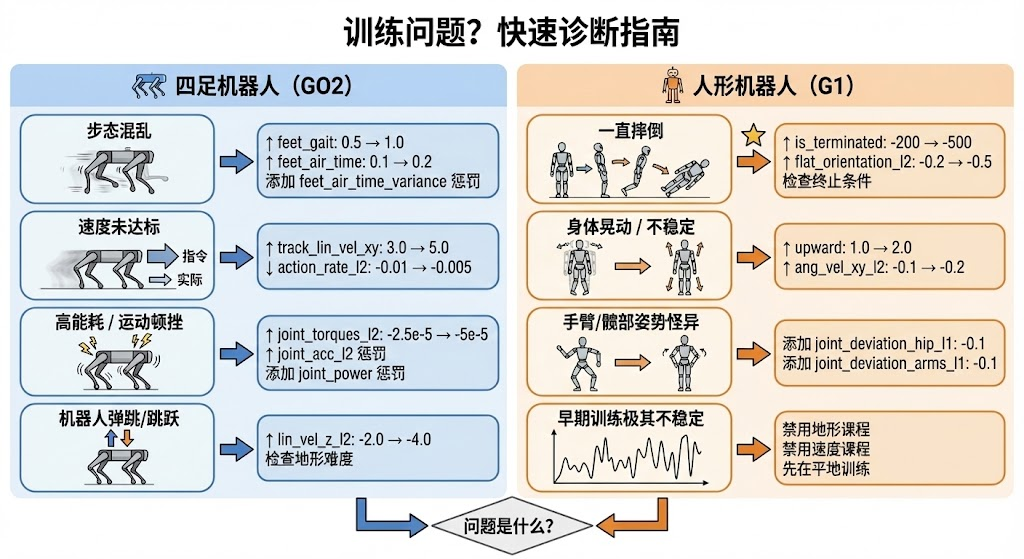
4.4 综合调参策略与奖励函数设计
本节汇总了 Robot Lab 中所有奖励函数的详细说明,以及根据训练问题进行系统性调参的方法论。
4.4.1 奖励函数完整列表
Robot Lab 基类 LocomotionVelocityRoughEnvCfg 定义了 40+ 个奖励项,以下按类别整理:
核心任务奖励(正权重,鼓励行为):
| 奖励项 | 函数 | 推荐范围 | 说明 |
|---|---|---|---|
track_lin_vel_xy_exp |
指数形式速度跟踪 | 2.0-5.0 | 线速度跟踪,核心目标 |
track_ang_vel_z_exp |
指数形式角速度跟踪 | 1.5-5.0 | 角速度跟踪 |
feet_air_time |
腾空时间奖励 | 0.1-2.0 | 鼓励迈腿,人形必需 |
feet_gait |
步态同步 | 0.3-1.0 | 四足对角步态 |
upward |
直立奖励 | 0.5-2.0 | 保持身体直立 |
基座稳定性惩罚(负权重,抑制行为):
| 奖励项 | 函数 | 推荐范围 | 说明 |
|---|---|---|---|
lin_vel_z_l2 |
垂直速度L2 | -1.0 ~ -3.0 | 抑制蹦跳 |
ang_vel_xy_l2 |
横滚俯仰角速度 | -0.05 ~ -0.3 | 抑制身体晃动 |
flat_orientation_l2 |
姿态偏差 | -0.1 ~ -0.5 | 保持水平 |
base_height_l2 |
高度偏差 | 0 ~ -1.0 | 保持目标高度 |
能耗与平滑性惩罚:
| 奖励项 | 函数 | 四足推荐值 | 人形推荐值 | 说明 |
|---|---|---|---|---|
joint_torques_l2 |
关节力矩L2 | -2.5e-5 | -1.5e-7 | 能耗惩罚 |
joint_acc_l2 |
关节加速度L2 | -2.5e-7 | -1.25e-7 | 动作平滑 |
action_rate_l2 |
动作变化率 | -0.01 | -0.005 | 控制平滑 |
joint_power |
关节功率 | -4e-5 | 0 | 机械功率 |
joint_vel_l2 |
关节速度L2 | 0 | 0 | 速度惩罚 |
足部行为惩罚:
| 奖励项 | 函数 | 推荐范围 | 说明 |
|---|---|---|---|
feet_slide |
滑动惩罚 | -0.1 ~ -0.4 | 脚接触时的滑动 |
feet_stumble |
绊倒惩罚 | -0.5 ~ -2.0 | 脚部意外碰撞 |
feet_height |
抬脚高度 | 0 ~ -5.0 | 控制抬脚高度 |
feet_height_body |
相对身体抬脚 | 0 ~ -5.0 | 四足常用 |
安全与约束惩罚:
| 奖励项 | 函数 | 推荐范围 | 说明 |
|---|---|---|---|
is_terminated |
终止惩罚 | -100 ~ -500 | 人形必需 |
joint_pos_limits |
关节限位 | -0.5 ~ -2.0 | 接近限位惩罚 |
undesired_contacts |
非期望接触 | -0.5 ~ -2.0 | 膝盖/手肘触地 |
joint_pos_penalty |
关节位置偏差 | 0 ~ -2.0 | 保持默认姿态 |
4.4.2 人形 vs 四足 配置差异总结
| 配置类别 | 四足机器人 | 人形机器人 | 原因 |
|---|---|---|---|
| 速度跟踪 | 3.0 | 3.0-5.0 | 人形需要更强激励 |
| 腾空时间 | 0.1 | 0.25-2.0 | 人形步态关键 |
| 腾空函数 | feet_air_time |
feet_air_time_positive_biped |
双足专用 |
| 步态同步 | 0.5 | 0(禁用) | 人形无对角步态 |
| 直立奖励 | 1.0 | 1.0-2.0 | 人形平衡困难 |
| 终止惩罚 | 0 | -200 | 人形摔倒不可恢复 |
| 力矩惩罚 | -2.5e-5 | -1.5e-7 | 人形需要更大力矩 |
| 地形课程 | 启用 | 禁用 | 人形初期无法应对复杂地形 |
| 训练步数 | 200k | 500k-1M | 人形收敛慢 |
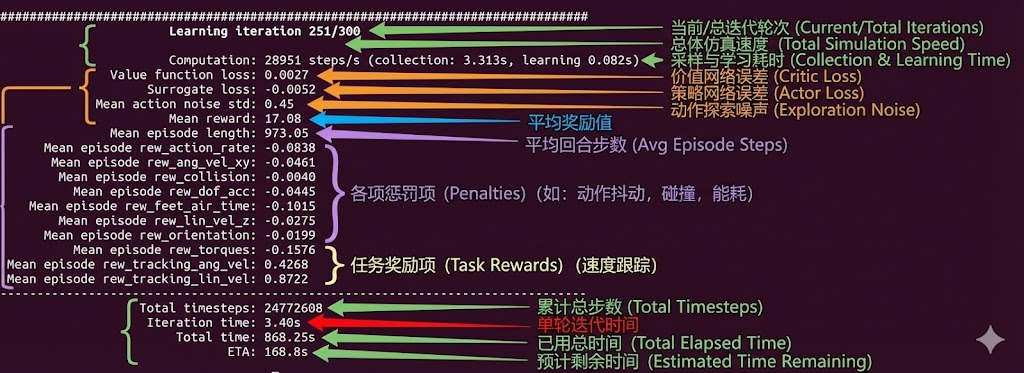
4.4.3 从 TensorBoard 诊断问题
训练过程中通过观察 TensorBoard 指标可以快速定位问题:
| 指标模式 | 可能问题 | 解决方向 |
|---|---|---|
| Mean Reward 不增长 | 策略困在局部最优 | 增大探索(entropy_coef)或调整奖励权重 |
| Episode Length 很短 | 机器人频繁摔倒 | 增大 is_terminated 惩罚,检查终止条件 |
| Episode Length 满值但 Reward 低 | 机器人站着不动 | 增大 feet_air_time、track_lin_vel |
| track_lin_vel 奖励为 0 | 没有速度跟踪 | 检查命令配置,确认速度范围 |
| feet_air_time 奖励为 0 | 没有迈腿 | 检查函数是否正确,权重是否为 0 |
| joint_torques 惩罚很大 | 力矩输出过高 | 检查执行器配置,增大力矩惩罚 |
4.4.4 调参优先级
当训练出现问题时,按以下优先级逐步排查:
第一优先级:确保机器人有动力行走
track_lin_vel_xy_exp.weight ≥ 3.0feet_air_time.weight ≥ 0.25(人形)upward.weight ≥ 1.0
第二优先级:确保使用正确的函数
- 人形机器人必须用
feet_air_time_positive_biped - 人形机器人用
track_lin_vel_xy_yaw_frame_exp - 检查
foot_link_name正则匹配是否正确
第三优先级:禁用不适合的配置
- 人形禁用
curriculum.terrain_levels - 人形禁用
feet_gait(步态同步是四足专用) - 检查
joint_pos_penalty是否太大
第四优先级:调整平衡参数
- 增大
is_terminated惩罚(人形) - 调整能耗惩罚权重
- 调整动作缩放
actions.joint_pos.scale
4.4.5 快速调参模板
人形机器人快速起步配置:
python
def __post_init__(self):
super().__post_init__()
# ===== 核心奖励(让机器人动起来)=====
self.rewards.track_lin_vel_xy_exp.weight = 3.0
self.rewards.track_lin_vel_xy_exp.func = mdp.track_lin_vel_xy_yaw_frame_exp
self.rewards.track_ang_vel_z_exp.weight = 3.0
# ===== 关键:腾空时间奖励(让机器人迈腿)=====
self.rewards.feet_air_time.weight = 1.0 # 必须 > 0
self.rewards.feet_air_time.func = mdp.feet_air_time_positive_biped # 必须用双足函数
self.rewards.feet_air_time.params["threshold"] = 0.4
# ===== 直立奖励(让机器人站起来)=====
self.rewards.upward.weight = 1.0
# ===== 摔倒惩罚 =====
self.rewards.is_terminated.weight = -200.0
# ===== 稳定性惩罚 =====
self.rewards.flat_orientation_l2.weight = -0.2
self.rewards.ang_vel_xy_l2.weight = -0.1
# ===== 能耗惩罚(人形用较小值)=====
self.rewards.joint_torques_l2.weight = -1.5e-7
self.rewards.joint_acc_l2.weight = -1.25e-7
self.rewards.action_rate_l2.weight = -0.005
# ===== 足部惩罚 =====
self.rewards.feet_slide.weight = -0.2
# ===== 关键:禁用地形课程 =====
self.curriculum.terrain_levels = None
self.curriculum.command_levels_lin_vel = None
self.curriculum.command_levels_ang_vel = None四足机器人快速起步配置:
python
def __post_init__(self):
super().__post_init__()
# ===== 核心奖励 =====
self.rewards.track_lin_vel_xy_exp.weight = 3.0
self.rewards.track_ang_vel_z_exp.weight = 1.5
# ===== 步态奖励 =====
self.rewards.feet_air_time.weight = 0.1
self.rewards.feet_gait.weight = 0.5 # 对角步态同步
# ===== 直立奖励 =====
self.rewards.upward.weight = 1.0
# ===== 稳定性惩罚 =====
self.rewards.lin_vel_z_l2.weight = -2.0
self.rewards.ang_vel_xy_l2.weight = -0.05
# ===== 能耗惩罚 =====
self.rewards.joint_torques_l2.weight = -2.5e-5
self.rewards.joint_acc_l2.weight = -2.5e-7
self.rewards.action_rate_l2.weight = -0.01
# ===== 足部惩罚 =====
self.rewards.feet_slide.weight = -0.1
self.rewards.feet_height_body.weight = -5.0 # 控制抬脚高度5. 训练与测试命令
完成配置后,就可以开始训练和测试了。Robot Lab 提供了标准化的训练和测试脚本,支持多种常用选项。本节介绍常用的命令行用法和监控工具。
5.1 训练命令
训练脚本位于 scripts/reinforcement_learning/rsl_rl/train.py,支持多种命令行参数。以下是几个常用的训练场景:
bash
# RSL-RL 训练 - 粗糙地形
python scripts/reinforcement_learning/rsl_rl/train.py \
--task=RobotLab-Isaac-Velocity-Rough-Unitree-G1-v0 \
--headless \
--num_envs 4096
# RSL-RL 训练 - 平地
python scripts/reinforcement_learning/rsl_rl/train.py \
--task=RobotLab-Isaac-Velocity-Flat-Unitree-G1-v0 \
--headless \
--num_envs 4096
# 从检查点继续训练
python scripts/reinforcement_learning/rsl_rl/train.py \
--task=RobotLab-Isaac-Velocity-Rough-Unitree-G1-v0 \
--resume \
--load_run="2024-01-01_12-00-00"--headless 参数禁用图形渲染,可以显著提高训练速度。--num_envs 指定并行环境数量,4096 是大多数任务的推荐值,需要根据 GPU 显存大小调整。在 RTX 4090(24GB)上通常可以运行 4096 个环境;在显存较小的 GPU 上需要相应减少
5.2 测试命令
训练完成后,可以使用测试脚本加载模型并可视化机器人的行为。测试脚本会自动从最新的训练运行中加载模型权重。
bash
# 加载训练好的模型进行测试
python scripts/reinforcement_learning/rsl_rl/play.py \
--task=RobotLab-Isaac-Velocity-Rough-Unitree-G1-v0 \
--num_envs 16
# 录制视频
python scripts/reinforcement_learning/rsl_rl/play.py \
--task=RobotLab-Isaac-Velocity-Rough-Unitree-G1-v0 \
--video \
--video_length 200测试时 --num_envs 可以设置得较小(如 16),这样便于观察单个机器人的行为细节。--video 选项会自动录制视频并保存到日志目录中,--video_length 指定录制的帧数。
5.3 TensorBoard 监控
TensorBoard 是监控训练过程的重要工具。RSL-RL 会自动将训练指标写入日志文件,可以通过 TensorBoard 实时查看。
bash
# 启动 TensorBoard
tensorboard --logdir=logs/rsl_rl
# 在浏览器中打开
# http://localhost:6006在 TensorBoard 中,重点关注以下指标:
- Mean Reward:总奖励的移动平均值,是最重要的训练指标。理想情况下应该持续上升并最终收敛。
- Episode Length:每个 episode 的平均长度。如果机器人频繁摔倒,这个值会很低。
- Policy Loss / Value Loss:策略网络和价值网络的损失值。这些值应该在训练过程中逐渐下降。
- 各项奖励分解 :查看各个奖励项的贡献,有助于诊断训练问题。
6. 总结
本文系统性地介绍了 Robot Lab 强化学习项目的核心设计理念与实现细节。通过对配置继承体系、机器人添加流程和调参策略的深入剖析,读者应该能够:
-
理解配置继承机制 :从
ManagerBasedRLEnvCfg基类到机器人特定配置的完整继承链,以及各层配置的职责划分。通过__post_init__方法实现参数的层层覆盖,既保证了代码复用,又提供了充分的定制灵活性。 -
掌握新机器人添加流程:包括资产配置(URDF 加载、执行器参数)、环境配置(观测、动作、奖励)、Agent 配置(网络架构、PPO 参数)以及 Gym 环境注册的完整五步流程。
-
应用调参策略:针对四足、人形、轮式三种不同类型机器人的特点,给出了具体的奖励权重设置建议和常见问题的解决方案。
Robot Lab 的设计体现了软件工程中"开放封闭原则"的精髓------对扩展开放(轻松添加新机器人),对修改封闭(无需修改基类即可定制行为)。这种设计使得研究人员可以将精力集中在机器人特定的配置调优上,而不是重复实现通用的环境逻辑。
对于希望深入了解的读者,建议阅读 Robot Lab 源码中的 velocity_env_cfg.py 基类实现,以及各机器人配置文件中的具体参数设置。通过对比不同机器人的配置差异,可以更好地理解各参数的作用和调优方向。
参考资料
- Robot Lab GitHub 仓库 - 项目源码与文档
- Isaac Lab 官方文档 - 底层框架的详细说明
- RSL-RL 库 - 强化学习算法实现
- Proximal Policy Optimization 论文 - PPO 算法原论文