1、下载Tesseract
Tesseract-OCR下载和安装,Python-OCR使用_tesseract-ocr python 下载-CSDN博客
在文文件里面有
2、PATH路径的添加,环境变量
这里有两个环境变量,其中一个是data后缀的
这个是你安装的文件路径
py
pip install Pillow
pip install pytesseract3、安装的时候,需要勾选相关的Chinese语言包
4、代码如下
py
import cv2
import pytesseract
import os
import time
import re
from PIL import Image, ImageDraw, ImageFont
import numpy as np
# 设置 pytesseract 可执行文件的路径(根据实际情况修改)
pytesseract.pytesseract.tesseract_cmd = r'C:\Users\47887\AppData\Local\Tesseract-OCR\tesseract.exe'
# 设置 TESSDATA_PREFIX 环境变量
os.environ['TESSDATA_PREFIX'] = r'C:\Users\47887\AppData\Local\Tesseract-OCR\tessdata'
myobject = ['微积分']
def preprocess_image(image):
# 灰度化
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 高斯模糊降噪
blurred = cv2.GaussianBlur(gray, (5, 5), 0)
# 自适应阈值处理
thresh = cv2.adaptiveThreshold(blurred, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY_INV, 11, 2)
return thresh
if __name__ == "__main__":
# 视频输入配置
cap = cv2.VideoCapture(1)
model_w, model_h = 640, 640 # 必须与训练时的图像尺寸一致
while True:
success, img0 = cap.read()
if success:
t1 = time.time()
# 图像预处理
preprocessed_img = preprocess_image(img0)
# 进行文字识别并获取文字及坐标信息,同时获取置信度
data = pytesseract.image_to_data(preprocessed_img, lang='chi_sim', output_type=pytesseract.Output.DICT)
t2 = time.time()
fps = 1 / (t2 - t1)
# 将 OpenCV 图像转换为 PIL 图像
pil_image = Image.fromarray(cv2.cvtColor(img0, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(pil_image)
# 加载中文字体文件,你可以根据实际情况修改字体文件路径
font = ImageFont.truetype("simhei.ttf", 18)
draw.text((10, 30), f'FPS: {fps:.2f}', font=font, fill=(0, 255, 0))
for i in range(len(data['text'])):
text = data['text'][i].strip()
conf = data['conf'][i] if isinstance(data['conf'][i], int) else 0
if text:
for obj in myobject:
if re.search(obj, text):
x = data['left'][i]
y = data['top'][i]
w = data['width'][i]
h = data['height'][i]
# 在图像上绘制矩形框
draw.rectangle((x, y, x + w, y + h), outline=(255, 0, 0), width=2)
# 显示匹配到的文字、坐标和置信度
info_text = f"{text} ({x}, {y}) 置信度: {conf:.2f}%"
draw.text((x, y - 20), info_text, font=font, fill=(0, 255, 0))
print(f"匹配文字: {text}, 坐标: 左上角({x}, {y}), 右下角({x + w}, {y + h}), 置信度: {conf:.2f}%")
# 将 PIL 图像转换回 OpenCV 图像
img0 = cv2.cvtColor(np.array(pil_image), cv2.COLOR_RGB2BGR)
cv2.imshow("Detection", img0)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
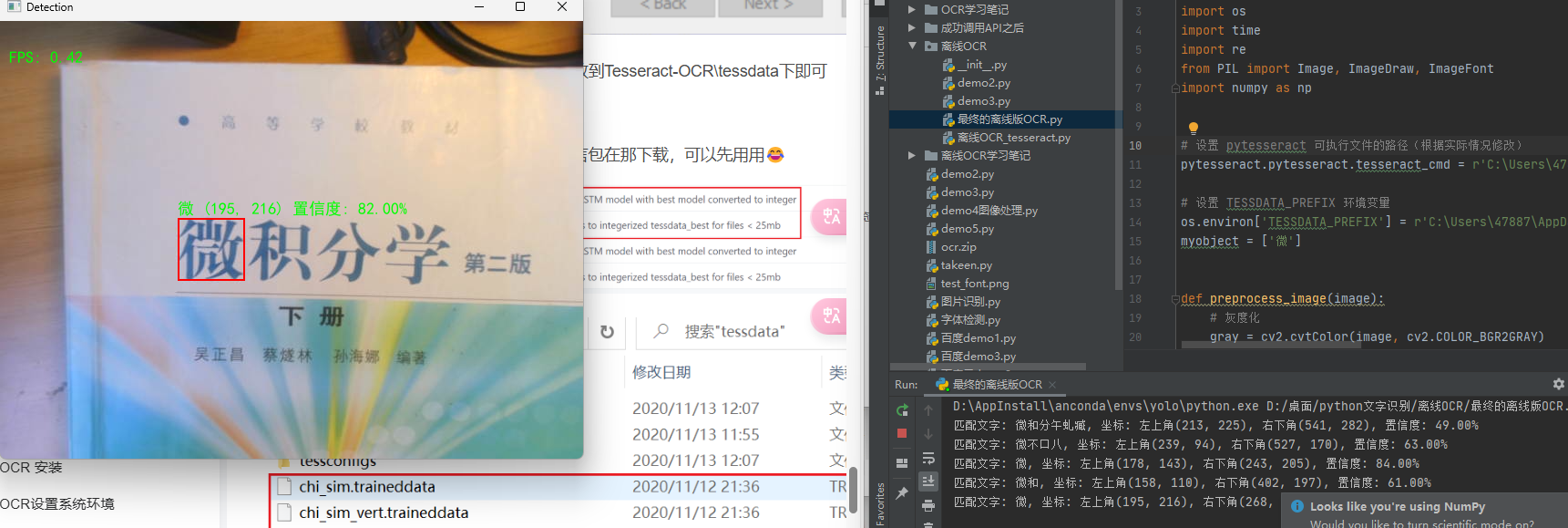
cv2.destroyAllWindows()5、效果如下