文章目录
- 一、大模型为什么要连接外部世界?
- [二、Function Calling 是什么?](#二、Function Calling 是什么?)
- [三、为什么需要 Function Calling ?](#三、为什么需要 Function Calling ?)
- [四、Function Calling 的工作原理](#四、Function Calling 的工作原理)
- [五、Function Calling 代码实战](#五、Function Calling 代码实战)
-
- [1. 大模型调用单个方法](#1. 大模型调用单个方法)
- [2. 大模型调用个多方法](#2. 大模型调用个多方法)
- [3. 大模型生成sql查询数据库](#3. 大模型生成sql查询数据库)
- [六、Function Calling 的注意事项](#六、Function Calling 的注意事项)
- [七、Function Calling 解决的问题](#七、Function Calling 解决的问题)
Function Calling 是 OpenAI 最先引入的一项技术,允许开发者将大语言模型(如 GPT-4)与外部函数或工具集成。通过 Function Calling,模型可以理解用户请求并生成调用外部函数所需的参数,从而实现更复杂、更动态的任务处理。下面我们一起来详细了解 Function Calling 技术吧。
一、大模型为什么要连接外部世界?
大模型连接外部世界,不是为了更"聪明",而是为了更"可靠、可用、可控"。
- 大模型知识有限 :大模型的知识来源于训练数据,一旦训练完成,知识就停止更新。
- 不知道最新新闻、政策变化、股价、天气。
- 不知道某个网站是否已经下线。
- 不知道你刚刚发生了什么事。
- 大模型没有真逻辑 :大模型表现出得逻辑、推理是训练文本的统计规律,它擅长语言概率预测,而不是事实验证,所以存在幻觉。
- 可能虚构不存在的论文、法律条文、产品。
- 对不确定问题给出"自信但错误"的答案。
- 会说话不等于真正有用:如果不能连接外部世界,大模型只能聊天、写文章、做理论推理,但实际需求是调用搜索引擎、访问数据库、访问第三方系统、执行程序等。
- 增强感知和行动能力:现实世界是一直在变动的,大模型需要连接外部世界,不断读取外部数据,感知外界变化,基于外部数据,给出正确的行动能力。
二、Function Calling 是什么?
Function Calling 技术是一种让大模型连接外部世界的桥梁技术。通过Function Calling,大模型可以与外部系统、实时数据库、历史数据等进行交互,并以结构化方式传递参数。
它的核心作用是让大模型负责"想清楚要做什么",再由函数负责"真的去做"。
三、为什么需要 Function Calling ?
-
让模型"能做事":没有 Function Calling,模型只能输出文本。有了它,模型可以:
- 查数据库。
- 调用 API。
- 执行业务逻辑。
- 操作系统或服务。
-
减少胡编乱造:让大模型不自己编结果,而是:
- 明确调用函数。
- 用真实返回值回答。
- 大幅降低幻觉问题。
-
更安全、可控:控制大模型的行为能力,只允许他做规定的事,让行为更加可控、正确。
- 大模型不能随便执行代码。
- 只能调用你事先定义好的函数。
- 参数结构清晰、可校验、可审计。
四、Function Calling 的工作原理
Function Calling 的工作流程如下图:
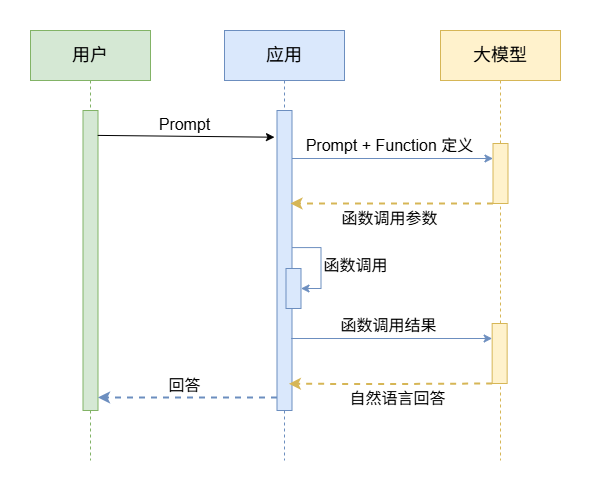
- 当用户请求后,应用程序提取propmt信息后调用大模型,给出场景提示词和函数定义。
- 大模型通过上下文判断给出结构化输出,应用程序调用结构化输出对应的函数。
- 将执行结果作为输入给到大模型,大模型转换成自然语言将结果返回。
大模型可以根据上下文判断调用哪个函数,大模型通过循环调用应用程序函数可以实现复杂场景。
五、Function Calling 代码实战
1. 大模型调用单个方法
模拟大模型调用单个方法。
python
# 导入依赖库
import os
import json
from openai import OpenAI
from math import *
# 定义一个辅助函数,用来打印日志
def print_json(data):
"""
如果参数是有结构的(如字典或列表),则以 JSON 形式打印,否则直接打印。
"""
if hasattr(data, 'model_dump_json'):
data = json.loads(data.model_dump_json())
if (isinstance(data, (list))):
for item in data:
print_json(item)
elif (isinstance(data, (list, dict))):
print(json.dumps(data, indent=4, ensure_ascii=False))
else:
print(data)
# 初始化 OpenAI 客户端
client = OpenAI(
# 若没有配置环境变量,请用百炼API Key将下行替换为:api_key="sk-xxx",
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
# 定义一个函数
def get_completion(prompt, response_format="text", model="qwen3-max-preview"):
print_json(prompt)
response = client.chat.completions.create(
model=model,
messages=prompt,
temperature=0.6, # 取值范围: [0, 2),temperature越高,生成的文本更多样,反之,生成的文本更确定。
response_format={"type": response_format}, # 返回消息的格式
tools=[{
"type": "function",
"function": {
"name": "calc",
"description": "数鸭子,计算一共有几只鸭子",
"parameters": {
"type": "object",
"properties": {
"numbers": {
"type": "array",
"items": {
"type": "number"
}
}
}
}
}
}]
)
return response.choices[0].message
# 请求提示词
prompt="河里有1个人,2条船,3只白鸭子,4条红鲤鱼,5只黑天鹅,6只黑鸭子,7只白鹭,8只乌龟,一共有几只鸭子?"
messages=[
{"role": "system", "content": "你是一个天才数学家"},
{"role": "user", "content": prompt}
]
print("===== 第一次调用大模型 =====")
response=get_completion(messages)
# 把大模型返回加入上下文中
messages.append(response)
print(response.content)
if(response.tool_calls is not None):
tool_call=response.tool_calls[0]
if(tool_call.function.name == "calc"):
args=json.loads(tool_call.function.arguments)
result=sum(args["numbers"])
messages.append({
"role": "tool",
"content": str(result),
"tool_call_id": tool_call.id,
"name": "calc"
})
print("===== 第二次调用大模型 =====")
response=get_completion(messages)
messages.append(response)
print("===== 大模型最终回复结果 =====")
print_json(response.content)返回结果:
===== 第一次调用大模型 =====
{
"role": "system",
"content": "你是一个天才数学家"
}
{
"role": "user",
"content": "河里有1个人,2条船,3只白鸭子,4条红鲤鱼,5只黑天鹅,6只黑鸭子,7只白鹭,8只乌龟,一共有几只鸭子?"
}
===== 第二次调用大模型 =====
{
"role": "system",
"content": "你是一个天才数学家"
}
{
"role": "user",
"content": "河里有1个人,2条船,3只白鸭子,4条红鲤鱼,5只黑天鹅,6只黑鸭子,7只白鹭,8只乌龟,一共有几只鸭子?"
}
{
"content": "",
"refusal": null,
"role": "assistant",
"annotations": null,
"audio": null,
"function_call": null,
"tool_calls": [
{
"id": "call_40e59c608e9f4e6cb359ca",
"function": {
"arguments": "{\"numbers\": [3, 6]}",
"name": "calc"
},
"type": "function",
"index": 0
}
]
}
{
"role": "tool",
"content": "9",
"tool_call_id": "call_40e59c608e9f4e6cb359ca",
"name": "calc"
}
===== 大模型最终回复结果 =====
河里一共有9只鸭子(3只白鸭子 + 6只黑鸭子)。2. 大模型调用个多方法
模拟大模型循环调用多个方法。
python
# 导入依赖库
import os
import json
from openai import OpenAI
from math import *
# 定义一个辅助函数,用来打印日志
def print_json(data):
"""
如果参数是有结构的(如字典或列表),则以 JSON 形式打印,否则直接打印。
"""
if hasattr(data, 'model_dump_json'):
data = json.loads(data.model_dump_json())
if (isinstance(data, (list))):
for item in data:
print_json(item)
elif (isinstance(data, (list, dict))):
print(json.dumps(data, indent=4, ensure_ascii=False))
else:
print(data)
# 初始化 OpenAI 客户端
client = OpenAI(
# 若没有配置环境变量,请用百炼API Key将下行替换为:api_key="sk-xxx",
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
# 定义一个函数
def get_completion(prompt, response_format="text", model="qwen3-max-preview"):
print_json(prompt)
response = client.chat.completions.create(
model=model,
messages=prompt,
temperature=0, # 取值范围: [0, 2),temperature越高,生成的文本更多样,反之,生成的文本更确定。
seed=1024, # 随机种子保持不变,当temperature和prompt不变时,输出结果不变。
response_format={"type": response_format}, # 返回消息的格式
tools=[{
"type": "function",
"function": {
"name": "get_landmark",
"description": "通过城市编号city_no,获取对应城市的热门旅游景点",
"parameters": {
"type": "object",
"properties": {
"city_no": {
"type": "string",
"description": "城市编号,比如:BJ"
}
}
}
}
},
{
"type": "function",
"function": {
"name": "get_city_no",
"description": "通过城市名称获取城市编号",
"parameters": {
"type": "object",
"properties": {
"city_name": {
"type": "string",
"description": "城市名称,比如:北京"
}
}
}
}
}]
)
return response.choices[0].message
def get_city_no(city_name: str) -> str:
if city_name == "北京":
city_no="BJ"
elif city_name == "上海":
city_no="SH"
elif city_name == "广州":
city_no="GZ"
elif city_name == "深圳":
city_no="SZ"
return city_no
def get_landmark(city_no: str) -> str:
if city_no == "BJ":
ans="""
城市:北京
城市编号:BJ
热门景点:北京是我们中国的首都,他有很多著名的旅游景点,比如:天安门、故宫、天坛、圆明园、颐和园、八达岭长城等。
"""
elif city_no == "SH":
ans="""
城市:上海
城市编号:SH
热门景点:上海是我国的国际化大都市,它有很多著名的旅游景点,比如:东方明珠广播电视塔、外滩、豫园、上海野生动物园、上海科技馆、广富林遗址等。
"""
elif city_no == "GZ":
ans="""
城市:广州
城市编号:GZ
热门景点:广州是我国广东省的省会,它有很多著名的旅游景点,比如:广州塔(小蛮腰)、白云山、陈家祠、沙面岛、圣心大教堂、珠江夜游等。
"""
elif city_no == "SZ":
ans="""
城市:深圳
城市编号:SZ
热门景点:深圳是我国的经济特区,它有很多著名的旅游景点,比如:世界之窗、深圳欢乐谷、东部华侨城、深圳湾公园、南头古城、较场尾等。
"""
return ans
# 请求提示词
prompt="我想去北京和深圳玩,你可以给我推荐一些景点吗?"
messages=[
{"role": "system", "content": "你是一个导游,你非常清楚全国城市都有哪些著名的旅游景点。"},
{"role": "user", "content": prompt}
]
count=1
response=get_completion(messages)
# 把大模型返回加入上下文中
messages.append(response)
print("===== 第 "+str(count)+" 次大模型调用 =====")
print(response.content)
while(response.tool_calls is not None):
for tool_call in response.tool_calls:
args=json.loads(tool_call.function.arguments)
print_json(args)
# 函数路由
if(tool_call.function.name == "get_city_no"):
print("===== 开始执行方法:get_city_no() =====")
result=get_city_no(**args)
elif(tool_call.function.name == "get_landmark"):
print("===== 开始执行方法:get_landmark() =====")
result=get_landmark(**args)
print_json("===== 方法执行完成,返回结果 =====")
print_json(result)
messages.append({
"role": "tool",
"content": str(result),
"tool_call_id": tool_call.id,
"name": tool_call.function.name
})
count=count+1
response=get_completion(messages)
print("===== 第 "+str(count)+" 次大模型调用 =====")
print_json(response)
messages.append(response)
print("===== 大模型最终回复结果 =====")
print_json(response.content)
# print("===== 大模型全部对话上下文 =====")
# print_json(messages)返回结果:
{
"role": "system",
"content": "你是一个导游,你非常清楚全国城市都有哪些著名的旅游景点。"
}
{
"role": "user",
"content": "我想去北京和深圳玩,你可以给我推荐一些景点吗?"
}
===== 第 1 次大模型调用 =====
{
"city_name": "北京"
}
===== 开始执行方法:get_city_no() =====
===== 方法执行完成,返回结果 =====
BJ
{
"city_name": "深圳"
}
===== 开始执行方法:get_city_no() =====
===== 方法执行完成,返回结果 =====
SZ
{
"role": "system",
"content": "你是一个导游,你非常清楚全国城市都有哪些著名的旅游景点。"
}
{
"role": "user",
"content": "我想去北京和深圳玩,你可以给我推荐一些景点吗?"
}
{
"content": "",
"refusal": null,
"role": "assistant",
"annotations": null,
"audio": null,
"function_call": null,
"tool_calls": [
{
"id": "call_892a88c2045c48a1b34f44",
"function": {
"arguments": "{\"city_name\": \"北京\"}",
"name": "get_city_no"
},
"type": "function",
"index": 0
},
{
"id": "call_b0e6821ebaec4f8691a08a",
"function": {
"arguments": "{\"city_name\": \"深圳\"}",
"name": "get_city_no"
},
"type": "function",
"index": 1
}
]
}
{
"role": "tool",
"content": "BJ",
"tool_call_id": "call_892a88c2045c48a1b34f44",
"name": "get_city_no"
}
{
"role": "tool",
"content": "SZ",
"tool_call_id": "call_b0e6821ebaec4f8691a08a",
"name": "get_city_no"
}
===== 第 2 次大模型调用 =====
{
"content": "",
"refusal": null,
"role": "assistant",
"annotations": null,
"audio": null,
"function_call": null,
"tool_calls": [
{
"id": "call_7d3800976adc4418a501dd",
"function": {
"arguments": "{\"city_no\": \"BJ\"}",
"name": "get_landmark"
},
"type": "function",
"index": 0
},
{
"id": "call_cc6927249062467f83e2f3",
"function": {
"arguments": "{\"city_no\": \"SZ\"}",
"name": "get_landmark"
},
"type": "function",
"index": 1
}
]
}
{
"city_no": "BJ"
}
===== 开始执行方法:get_landmark() =====
===== 方法执行完成,返回结果 =====
城市:北京
城市编号:BJ
热门景点:北京是我们中国的首都,他有很多著名的旅游景点,比如:天安门、故宫、天坛、圆明园、颐和园、八达岭长城等。
{
"city_no": "SZ"
}
===== 开始执行方法:get_landmark() =====
===== 方法执行完成,返回结果 =====
城市:深圳
城市编号:SZ
热门景点:深圳是我国的经济特区,它有很多著名的旅游景点,比如:世界之窗、深圳欢乐谷、东部华侨城、深圳湾公园、南头古城、较场尾等。
{
"role": "system",
"content": "你是一个导游,你非常清楚全国城市都有哪些著名的旅游景点。"
}
{
"role": "user",
"content": "我想去北京和深圳玩,你可以给我推荐一些景点吗?"
}
{
"content": "",
"refusal": null,
"role": "assistant",
"annotations": null,
"audio": null,
"function_call": null,
"tool_calls": [
{
"id": "call_892a88c2045c48a1b34f44",
"function": {
"arguments": "{\"city_name\": \"北京\"}",
"name": "get_city_no"
},
"type": "function",
"index": 0
},
{
"id": "call_b0e6821ebaec4f8691a08a",
"function": {
"arguments": "{\"city_name\": \"深圳\"}",
"name": "get_city_no"
},
"type": "function",
"index": 1
}
]
}
{
"role": "tool",
"content": "BJ",
"tool_call_id": "call_892a88c2045c48a1b34f44",
"name": "get_city_no"
}
{
"role": "tool",
"content": "SZ",
"tool_call_id": "call_b0e6821ebaec4f8691a08a",
"name": "get_city_no"
}
{
"content": "",
"refusal": null,
"role": "assistant",
"annotations": null,
"audio": null,
"function_call": null,
"tool_calls": [
{
"id": "call_7d3800976adc4418a501dd",
"function": {
"arguments": "{\"city_no\": \"BJ\"}",
"name": "get_landmark"
},
"type": "function",
"index": 0
},
{
"id": "call_cc6927249062467f83e2f3",
"function": {
"arguments": "{\"city_no\": \"SZ\"}",
"name": "get_landmark"
},
"type": "function",
"index": 1
}
]
}
{
"role": "tool",
"content": "\n 城市:北京\n 城市编号:BJ\n 热门景点:北京是我们中国的首都,他有很多著名的旅游景点,比如:天安门、故宫、天坛、圆明园、颐和园、八达岭长城等。\n ",
"tool_call_id": "call_7d3800976adc4418a501dd",
"name": "get_landmark"
}
{
"role": "tool",
"content": "\n 城市:深圳\n 城市编号:SZ\n 热门景点:深圳是我国的经济特区,它有很多著名的旅游景点,比如:世界之窗、深圳欢乐谷、东部华侨城、深圳湾公园、南头古城、较场尾等。\n ",
"tool_call_id": "call_cc6927249062467f83e2f3",
"name": "get_landmark"
}
===== 第 3 次大模型调用 =====
{
"content": "当然可以!以下是为您推荐的北京和深圳的热门旅游景点:\n\n### 北京\n北京是中国的首都,拥有丰富的历史文化和名胜古迹,推荐景点包括:\n- **天安门**:中国的象征性建筑之一。\n- **故宫**:明清两代的皇家宫殿,世界文化遗产。\n- **天坛**:古代皇帝祭天祈福的地方。\n- **圆明园**:昔日皇家园林,充满历史韵味。\n- **颐和园**:中国现存规模最大、保存最完整的皇家园林。\n- **八达岭长城**:举世闻名的万里长城精华段。\n\n### 深圳\n深圳是中国的经济特区,现代化与自然风光兼具,推荐景点包括:\n- **世界之窗**:微缩世界著名景观的主题公园。\n- **深圳欢乐谷**:适合家庭游玩的大型主题乐园。\n- **东部华侨城**:集生态旅游、休闲度假为一体的综合景区。\n- **深圳湾公园**:沿海风景优美的城市公园。\n- **南头古城**:感受岭南文化与历史的好去处。\n- **较场尾**:被称为"深圳鼓浪屿",文艺小清新的海滨小镇。\n\n希望这些推荐能为您的旅行提供帮助,祝您旅途愉快!",
"refusal": null,
"role": "assistant",
"annotations": null,
"audio": null,
"function_call": null,
"tool_calls": null
}
===== 大模型最终回复结果 =====
当然可以!以下是为您推荐的北京和深圳的热门旅游景点:
### 北京
北京是中国的首都,拥有丰富的历史文化和名胜古迹,推荐景点包括:
- **天安门**:中国的象征性建筑之一。
- **故宫**:明清两代的皇家宫殿,世界文化遗产。
- **天坛**:古代皇帝祭天祈福的地方。
- **圆明园**:昔日皇家园林,充满历史韵味。
- **颐和园**:中国现存规模最大、保存最完整的皇家园林。
- **八达岭长城**:举世闻名的万里长城精华段。
### 深圳
深圳是中国的经济特区,现代化与自然风光兼具,推荐景点包括:
- **世界之窗**:微缩世界著名景观的主题公园。
- **深圳欢乐谷**:适合家庭游玩的大型主题乐园。
- **东部华侨城**:集生态旅游、休闲度假为一体的综合景区。
- **深圳湾公园**:沿海风景优美的城市公园。
- **南头古城**:感受岭南文化与历史的好去处。
- **较场尾**:被称为"深圳鼓浪屿",文艺小清新的海滨小镇。
希望这些推荐能为您的旅行提供帮助,祝您旅途愉快!3. 大模型生成sql查询数据库
通过提示词和function定义,让大模型自动生成sql返回我们想要的结果。
python
# 导入依赖库
import os
import json
import sqlite3
from openai import OpenAI
from math import *
# 模拟数据库数据准备
database_schema_string="""
CREATE TABLE orders(
id INT PRIMARY KEY NOT NULL, -- 主键,不允许为空
customer_id INT NOT NULL, -- 客户ID,不允许为空
product_id STR NOT NULL, -- 产品ID,不允许为空
price DECIMAL(10,2) NOT NULL, -- 价格,不允许为空
status INT NOT NULL, -- 订单状态,整数类型,不允许为空。0代表待支付,1代表已支付,2代表已退款
create_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP, -- 订单创建时间,默认为当前系统时间
pay_time TIMESTAMP -- 订单支付时间,可以为空
);
"""
conn=sqlite3.connect(':memory:')
cursor=conn.cursor()
cursor.execute(database_schema_string)
mock_data=[
(1,101,'xiaomi',998.00,0,'2025-09-11 10:00:00',None),
(2,101,'xiaomi_plus',1998.00,1,'2025-09-18 16:00:00','2025-09-18 17:00:00'),
(3,102,'huawei',9998.00,2,'2025-10-11 10:00:00','2025-10-11 10:10:00'),
(4,103,'huawei',9998.00,1,'2025-10-11 13:00:00','2025-10-11 14:00:00'),
(5,103,'iphone_19',6998.00,1,'2025-10-15 13:00:00','2025-10-15 15:00:00'),
(6,102,'iphone_18',4998.00,0,'2025-12-16 10:00:00',None),
]
for record in mock_data:
cursor.execute('''
INSERT INTO orders(id,customer_id,product_id,price,status,create_time,pay_time) VALUES(?,?,?,?,?,?,?)
''', record)
conn.commit
def select_database(query):
cursor.execute(query)
records=cursor.fetchall()
return records
# 定义一个辅助函数,用来打印日志
def print_json(data):
"""
如果参数是有结构的(如字典或列表),则以 JSON 形式打印,否则直接打印。
"""
if hasattr(data, 'model_dump_json'):
data = json.loads(data.model_dump_json())
if (isinstance(data, (list))):
for item in data:
print_json(item)
elif (isinstance(data, (list, dict))):
print(json.dumps(data, indent=4, ensure_ascii=False))
else:
print(data)
# 初始化 OpenAI 客户端
client = OpenAI(
# 若没有配置环境变量,请用百炼API Key将下行替换为:api_key="sk-xxx",
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
# 定义一个函数
def get_completion(prompt, response_format="text", model="qwen3-max-preview"):
print_json(prompt)
response = client.chat.completions.create(
model=model,
messages=prompt,
temperature=0, # 取值范围: [0, 2),temperature越高,生成的文本更多样,反之,生成的文本更确定。
response_format={"type": response_format}, # 返回消息的格式
tools=[{
"type": "function",
"function": {
"name": "select_database",
"description": "Use this function to answer users questions about business. Output should be a fully formed SQL query.",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": f"""
SQL query extracting info to answer the user's question.
SQL should be written using this database schema:
{database_schema_string}
The query should be returned in plain text, not in JSON.
The query should only contain grammars supported by SQLite.
"""
}
},
"required": ["query"]
}
}
}]
)
return response.choices[0].message
# 请求提示词
prompt="2025年10月份的总销售额是多少?"
messages=[
{"role": "system", "content": "你是一个数据分析师,基于数据库的数据来回答问题"},
{"role": "user", "content": prompt}
]
print("===== 第一次调用大模型 =====")
response=get_completion(messages)
# 把大模型返回加入上下文中
messages.append(response)
print(response.content)
if(response.tool_calls is not None):
tool_call=response.tool_calls[0]
if(tool_call.function.name == "select_database"):
args=json.loads(tool_call.function.arguments)
print("===== query SQL =====")
print(args["query"])
result=select_database(args["query"])
print("===== execute SQL return =====")
print(result)
messages.append({
"role": "tool",
"content": str(result),
"tool_call_id": tool_call.id,
"name": "calc"
})
response=get_completion(messages)
messages.append(response)
print("===== 大模型最终回复结果 =====")
print_json(response.content)返回结果:
===== 第一次调用大模型 =====
{
"role": "system",
"content": "你是一个数据分析师,基于数据库的数据来回答问题"
}
{
"role": "user",
"content": "2025年10月份的总销售额是多少?"
}
===== query SQL =====
SELECT SUM(price) AS total_sales FROM orders WHERE strftime('%Y-%m', create_time) = '2025-10';
===== execute SQL return =====
[(26994,)]
{
"role": "system",
"content": "你是一个数据分析师,基于数据库的数据来回答问题"
}
{
"role": "user",
"content": "2025年10月份的总销售额是多少?"
}
{
"content": "",
"refusal": null,
"role": "assistant",
"annotations": null,
"audio": null,
"function_call": null,
"tool_calls": [
{
"id": "call_db4011b2bd7e4ecf9210d5",
"function": {
"arguments": "{\"query\": \"SELECT SUM(price) AS total_sales FROM orders WHERE strftime('%Y-%m', create_time) = '2025-10';\"}",
"name": "select_database"
},
"type": "function",
"index": 0
}
]
}
{
"role": "tool",
"content": "[(26994,)]",
"tool_call_id": "call_db4011b2bd7e4ecf9210d5",
"name": "calc"
}
===== 大模型最终回复结果 =====
2025年10月份的总销售额为 **26,994** 元。到这里各位小伙伴应该就清楚了什么是Function Calling吧?
我们通过定义函数,然后让大模型自己内部控制选择调用某些函数,上面案例中的方法体if else内可以换成调用外系统、查数据库等等操作,来控制返回我们需要给大模型的信息。我们还可以通过添加某个格式化输出的函数,控制大模型最终的输出格式,以满足我们的业务需求,让大模型更靠谱。
六、Function Calling 的注意事项
使用Function Calling时需要注意以下问题:
- 函数职责要单一,最好一个函数只做一件事,有利于模型正确选择要调用的函数。
- 函数命名要清晰、可读,模型会根据函数名称猜他的用途。
- 函数与参数的描述,也是一种prompt,会影响模型调用函数的准确性,需要调优。
- 参数定义要明确、可约束,比如参数类型、枚举类型等,约束越强,模型越不容易搞错参数。
- 不要认为模型一定会调用某些函数,我们需要对模型返回结果进行校验。
- 函数返回结果要精简、结构化,避免返回无关数据和非结构化数据。
- 避免出现无限循环调用函数情况,比如函数返回结果不确定后又重新调用函数,或者返回结果很模糊,模型又需要继续调用函数,应设置最大调用次数。
- 避免将关键操作直接交给模型,比如数据更新删除、支付转账等。
- 需要对模型参数进行校验,避免出现prompt注入漏洞。
- 避免函数过多,导致模型选择困难,应将函数按场景拆分、按阶段加载。
- 记录模型调用跟踪日志,方便对模型查错和调优。
七、Function Calling 解决的问题
- 解决知识滞后问题:大语言模型的训练数据存在截止日期,无法获取此后更新的信息。Function Calling通过调用外部API获取实时数据,有效解决了这一问题。
- 解决计算能力不足问题:大语言模型在处理高精度数学计算、复杂逻辑推理等方面存在局限。Function Calling允许模型将计算任务委托给专业的计算工具或代码,如调用计算器函数计算复杂数学表达式,或调用数据分析函数处理用户上传的Excel表格。
- 解决系统交互限制:传统模型无法直接操作数据库、发送邮件或控制硬件设备等。Function Calling通过预定义的函数接口,使模型能够与外部系统交互。
- 参数校验与纠错:模型可以在函数调用过程中检测潜在错误,并提出修正意见,确保函数能够安全、正确的执行。
- 提升自动化能力:Function Calling支持任务分解和工具链集成,是智能体和自动化流程的底座能力。通过Chain-of-Thought或ReAct框架,模型可以将复杂任务拆分为多个子任务,逐步调用函数。