前言
在服装 B2B 领域,搜索一直是个痛点。店主们往往只有一张样衣照片,却叫不出名字;或者想找"格子衫",搜出来的却是"条纹衫"。
最近,我带领团队完成了一次 AI 搜索架构的迭代------从基于 MacBook 的本地分布式 POC(概念验证),到正式迁移至火山引擎云搜索(OpenSearch)PaaS 方案。这篇文章将带你深度复盘这其中的架构选型、填坑经历以及实测效果。
1. 阶段一:手搓自研 POC 阶段
在项目初期,为了快速验证 Fashion-CLIP 模型的跨模态能力,我们搭建了一套"全栈手搓"环境:
- 向量库:Docker 部署 Qdrant。
- 模型推理:FastAPI 封装 Fashion-CLIP,运行在 MacBook 上。
- 业务逻辑:Java 扫描本地图片并调用 Python 获取向量,存入 Qdrant。
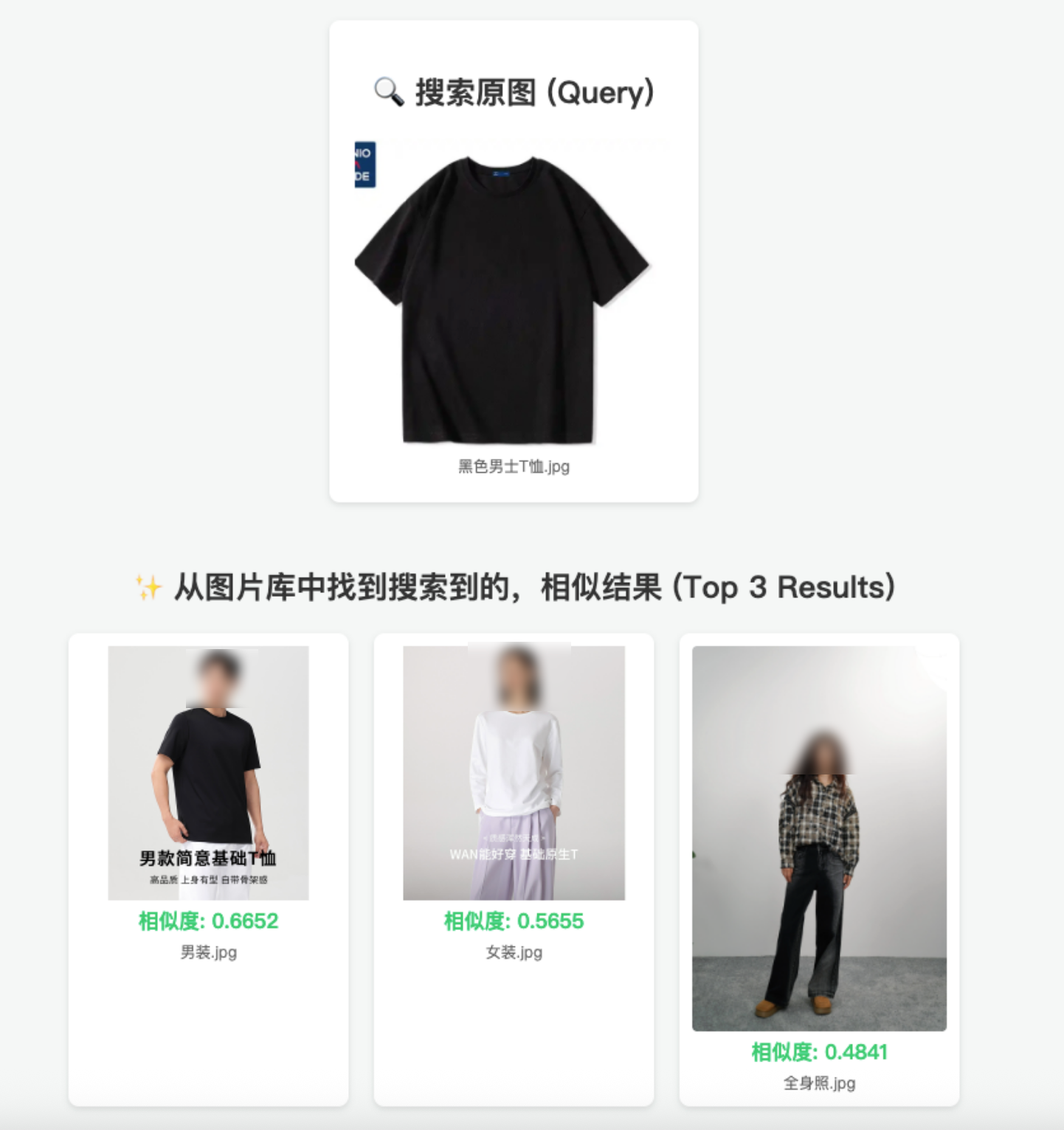
结论:自研方案成本低,但面对百万级 SKU 时,分布式运维、GPU 资源调度和内网安全成为了难以逾越的障碍。
2. 阶段二:云原生 PaaS 架构升级
为了应对生产环境的高并发和弹性需求,我们转向了火山引擎的 OpenSearch AI 搜索方案。
核心架构图 (Mermaid)
这套方案的核心是将推理能力下沉到搜索底座,实现业务层与算法层的完全解耦。
云端 AI 搜索闭环
以文搜图/以图搜图
触发 Search Pipeline
特征提取
读取图片
返回向量
执行 k-NN 检索
用户/App
Java 业务后端
OpenSearch 2.9.0
AI 推理服务: 8vCPU 32GiB
Fashion-CLIP 模型
对象存储 TOS
相似度 Top K 结果

3. 生产环境部署的三个"巨坑"
在 PaaS 集成过程中,我们总结了三个必须避开的"硬坑":
3.1 端口寻址陷阱
- 现象 :创建管道后,写入数据频发
connect_exception。 - 真相 :云端推理服务容器默认监听 8000 端口,而非标准的 80 端口。在配置 Pipeline 时必须显式指定端口。
3.2 5000ms 硬超时限制
- 现象 :执行批量(Bulk)入库时,频繁出现
socket_timeout_exception。 - 对策 :PaaS 环境下的模型推理需要时间。我们将入库逻辑改为 50 张图为一个批次(Batching),并加入 0.5s 的间隔,成功平滑了流量波峰。
3.3 索引 Mapping 冲突
- 坑位 :未预定义 Schema 导致向量字段被识别为普通的
float。 - 对策 :必须显式声明
"type": "knn_vector"并指定维度(如 512 维)和算法(HNSW),否则向量检索无法生效。
4. 实测效果复盘:图与文的"冰火两重天"
4.1 以图搜图:视觉的巅峰
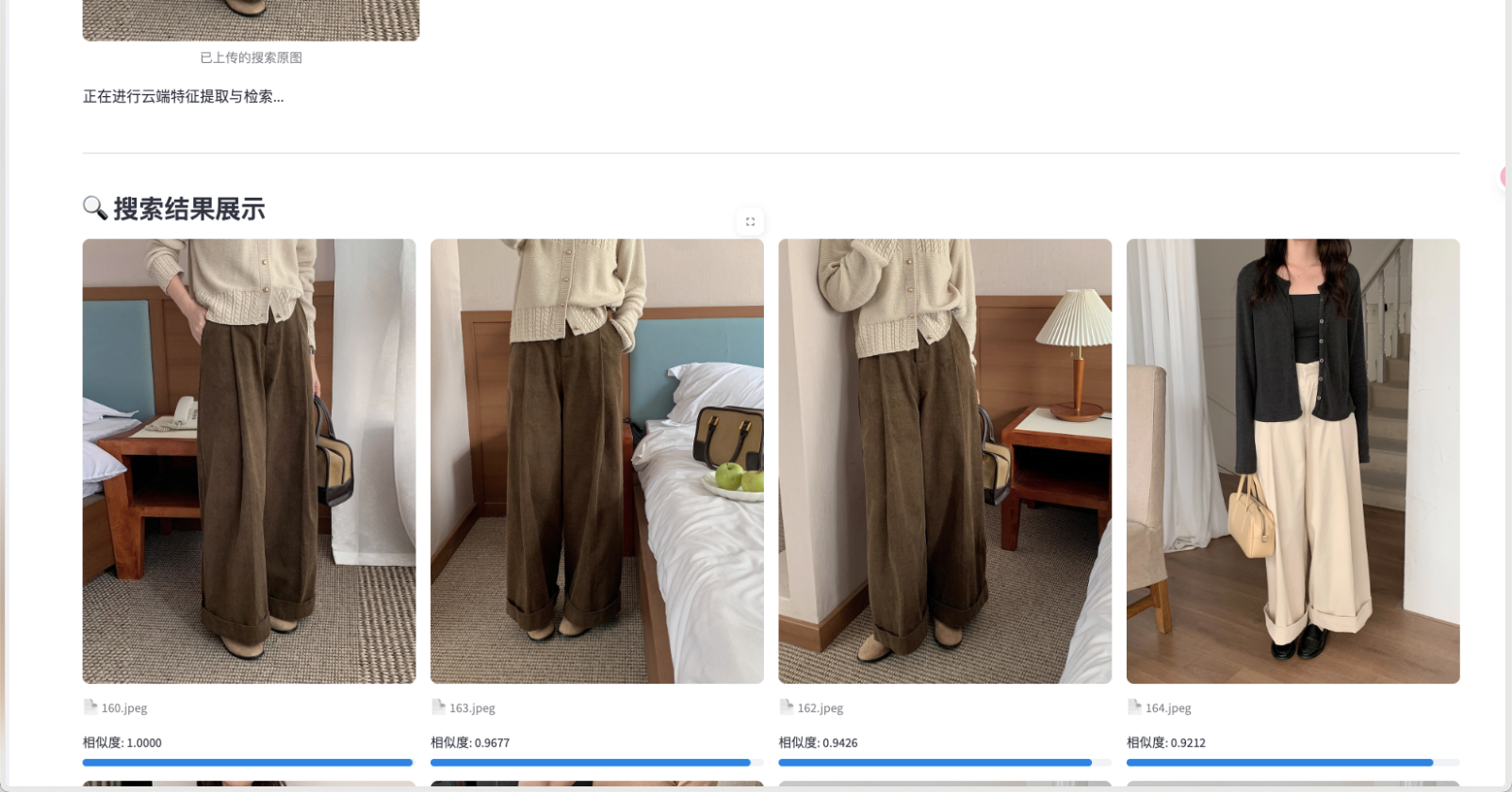
在服装这种高度依赖视觉特征的类目下,AI 表现惊艳。上传一张阔腿裤样照,系统在 219ms 内即可找回库中所有剪裁相似的单品,相似度分数极高。
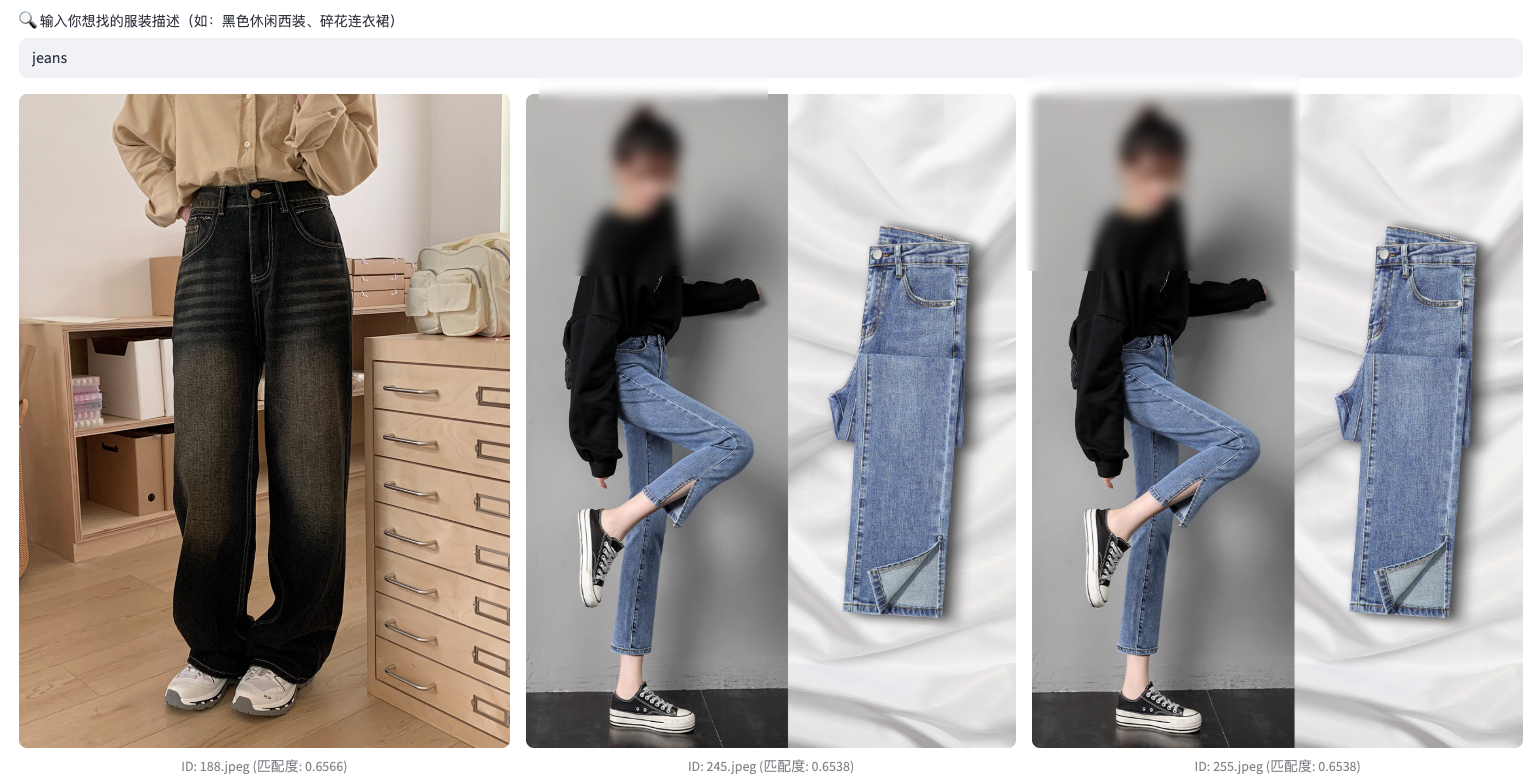
4.2 以文搜图:跨模态的"中文壁垒"
- Bug:搜 "jeans" 准确,但搜"牛仔裤"却出了"西裤"。
- 原因 :公开模型(如
fashion-clip)大多在英文数据集上预训练,缺乏对中文服装词汇的语义对齐。 - 解决方案 :在 Java 业务端增加 Query Translation(查询翻译)层 。输入"格子衫"先翻译为 "plaid shirt",准确率瞬间从 30% 提升至 90% 以上。
5. 开发者建议:业务层如何深度集成?
在实际 Java 开发中,不建议将商品所有详情(价格、库存)全塞进 OpenSearch。
推荐方案:ID 映射法
- OpenSearch 仅存储
sku_id和向量。 - 搜索返回
sku_id后,Java 端通过 Redis/MySQL 聚合实时业务数据。 - 这种方案保证了价格修改的实时性,同时减轻了搜索索引的维护压力。
结语
AI 搜索不是魔法,而是工程、算法与存储的精妙结合。火山引擎 PaaS 方案虽然在初期配置上有一定的门槛,但其提供的全链路内网传输 和弹性算力引擎,确实为 B2B 平台在百万级数据下的搜索体验提供了坚实的底座。