第三章-数据仓库
定义
数据仓库是一个主题导向 (Subject-oriented) 、集成 (Integrated) 、时变 (Time-variant)、**非易失 (Nonvolatile)**的数据集合,用以支持管理层的决策制定过程。
特性
-
面向主题的 (Subject-Oriented):
- 数据是围绕主要的业务主题(如客户、产品、销售)来组织的 。
- 它关注于对决策者有用的数据的建模和分析,而不是日常运营或事务处理 。
- 通过排除对决策支持过程无用的数据,提供围绕特定主题的简洁视图 。
-
集成 (Integrated):
- 数据仓库是从多个异构数据源(如关系数据库、平面文件、在线交易记录)集成构建的
- 必须应用数据清洗和数据集成技术 。
- 关键是确保在不同的数据源之间,命名约定、编码结构、属性度量 等的一致性 。例如,统一处理不同来源中酒店价格在货币、税费、是否包含早餐等方面的差异 。当数据移入仓库时,它必须被转换成统一的格式 。
-
时变 (Time-Variant):
- 数据仓库的时间范围明显长于操作型系统(通常是过去 5-10 年) 。
- 运营数据库通常只包含当前值数据 。
- 数据仓库中的每个关键结构都显式或隐式地包含时间元素 。
-
非易失 (Nonvolatile):
- 数据仓库是与操作环境物理分离的数据存储 。
- 一旦加载,数据就相对静态,操作型数据更新不会发生在数据仓库环境中 。
- 它不需要事务处理、恢复和并发控制机制 。
- 数据访问只需要两种操作:初始数据加载 和数据访问
为什么需要单独的数据仓库? 主要原因是为了实现高性能 和满足不同的功能需求 。
性能调优: 事务系统(OLTP)和分析系统(OLAP)需要不同的调优(如访问方法、索引、并发控制) 。
数据缺失: 决策支持需要历史数据,而运营数据库通常不保留 。
数据整合: 决策支持需要将来自异构源的数据进行整合、聚合和汇总 。
数据质量: 不同来源的数据表示、编码、格式不一致,需要协调统一 。
OLTP vs. OLAP

数据仓库 (Data Warehouse) 的建立,本质上就是为了把 OLTP 系统里产生的数据,清洗整理后存起来,专门供 OLAP 系统去分析
ETL 过程
(Extraction, Transformation, and Loading): 这是构建数据仓库的关键步骤:
数据提取 (Extraction): 从多个、异构和外部源获取数据 。
数据清洗 (Cleaning): 检测并尽可能纠正数据中的错误 。
数据转换 (Transformation): 将数据从传统或主机格式转换为仓库格式 。
加载 (Load): 包括排序、汇总、合并、计算视图、检查完整性、构建索引和分区等 。
刷新 (Refresh): 将数据源的更新传播到数据仓库 。
架构与模型

新一代数据架构:数据湖、湖仓一体与数据网格 (Data Lake, Lakehouse, Data Mesh)
数据湖 (Data Lake) (重要):
- 一个集中式存储库,按任意规模 存储所有结构化和非结构化数据 。
- 数据按原样存储,无需预先结构化 。
- 支持从仪表板、可视化到大数据处理、实时分析和机器学习等不同类型的分析 。
- 挑战: 数据集数量庞大 ,查询复杂 ,核心任务是元数据管理 和数据清洗
数据湖仓一体 (Data Lakehouse) :
- 一种新的开放数据管理架构 。
- 结合了数据湖的灵活性、成本效益和规模 ,以及数据仓库的数据管理和 ACID 事务
- 关键特征: 事务支持 、模式强制和治理 、BI 支持 、存储和计算解耦 、开放存储格式 、支持多样化的数据类型和工作负载(DS, ML, SQL) 。
数据网格 (Data Mesh):
- 一种架构模式,专注于数据管理 。
- 创建多个领域特定的系统,使数据更接近消费者
数据仓库建模
数据仓库建模:模式和度量 (Data Warehouse Modeling: Schema and Measures)
数据立方体计算


在数据立方体的格结构(Lattice) 中,顶端方体是所有维度都被聚合(取ALL值) 的方体。它位于整个立方体格的最顶端 ,包含对全部数据的完全聚合。




顶点立方体类似求所有事务的和,其他立方体则是根据不同的情况,如:

第四章-关联规则挖掘
基本概念
支持度与置信度

模式的压缩表达

算法
Apriori算法
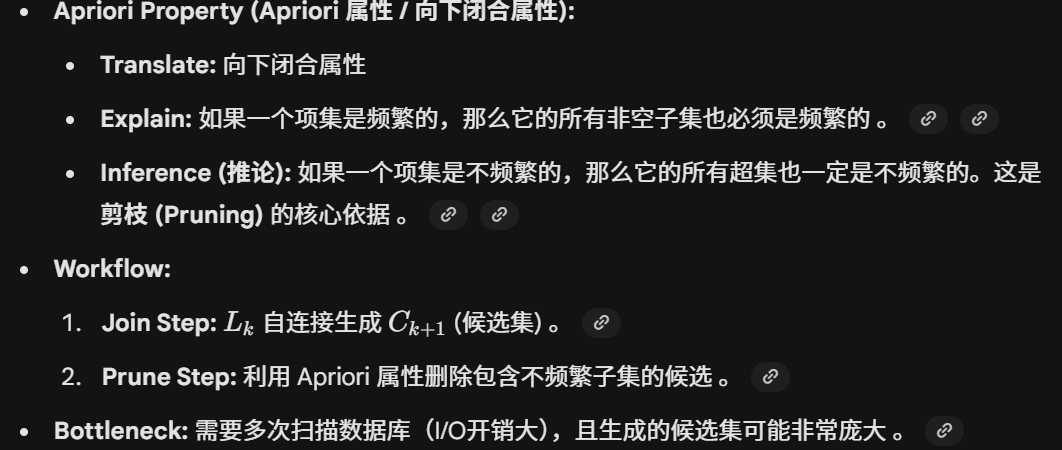
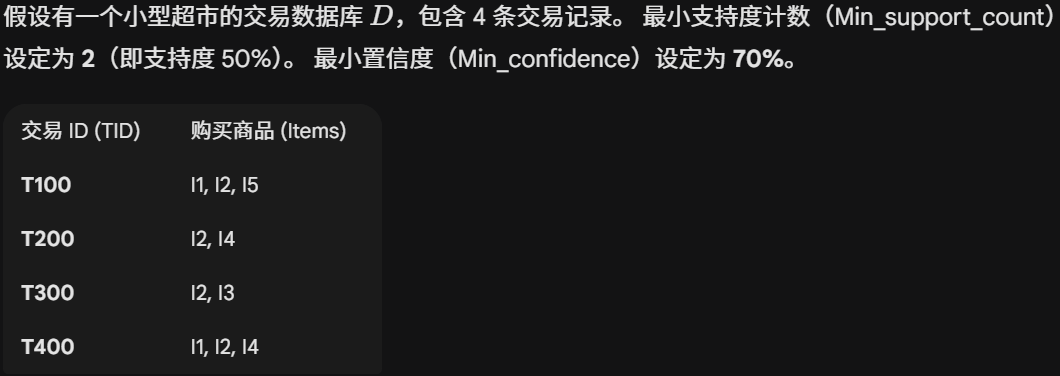



最终的所有频繁项集: {I1}, {I2}, {I4}, {I1, I2}, {I2, I4}


ECLAT
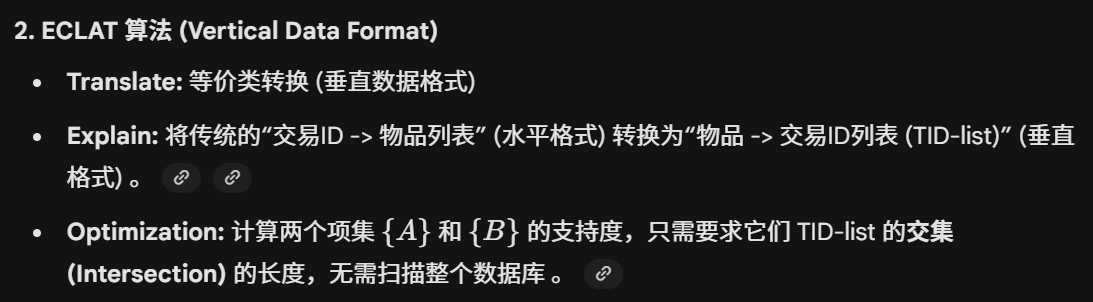
有点类似搜索引擎中的倒排索引
FPGrowth









模式评估
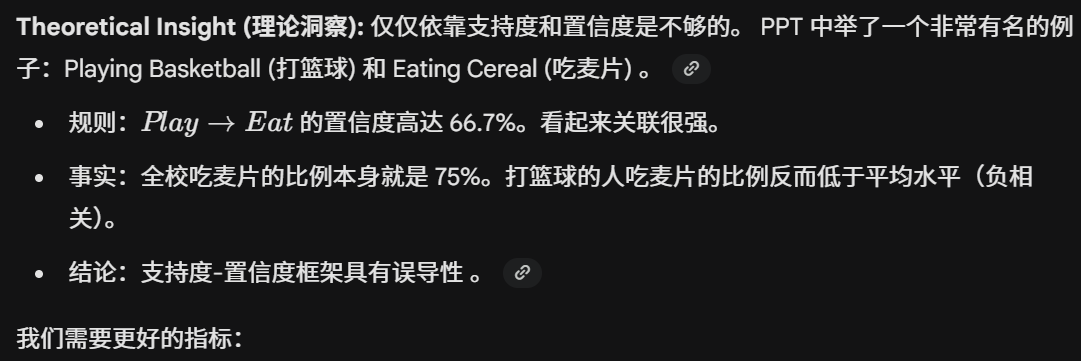
指标
Lift

重要性质:空值不变性

