📖标题:Training AI Co-Scientists Using Rubric Rewards
🌐来源:arXiv, 2512.23707
🌟摘要
AI 科学家正在成为帮助人类研究人员实现其研究目标的工具。这些人工智能科学家的一个关键特征是在给定一组目标和约束的情况下生成研究计划的能力。该计划可能会被研究人员用于头脑风暴,甚至可以在进一步细化后实现。然而,由于任务的开放性,语言模型目前难以生成遵循所有约束和隐含要求的研究计划。此外,通过执行实验来验证研究计划是缓慢且昂贵的。在这项工作中,我们研究了如何利用现有研究论文的大量语料库来训练生成更好研究计划的语言模型。我们通过从多个领域的论文中自动提取研究目标和目标特定的评分量规来构建可扩展的、多样化的训练语料库。然后,我们通过具有自分级的强化学习训练模型进行研究计划生成。初始策略的冻结副本充当分级器,访问量规作为特权信息来评估训练策略生成的计划。此设置创建了一个生成器验证器间隙,无需外部人工监督即可改进。为了验证这种方法,我们对人类专家进行了研究,用于机器学习研究目标,跨越 225 小时。专家更喜欢我们的微调 Qwen3-30B-A3B 模型生成的计划,而不是初始模型 70% 的研究目标,并批准 84% 自动提取的目标特定评分标准。为了评估通用性,我们还将我们的方法扩展到医学论文和目标,以及新的 arXiv 预印本,使用边界模型陪审团进行评估。我们的微调产生了 12-22% 的相对改进和显着的跨域泛化,即使在执行反馈不可行的医学研究等问题设置中也被证明是有效的。总之,这些发现证明了可扩展、自动化的训练配方作为改进一般 AI 科学家迈出的一步的潜力。
🛎️文章简介
🔸研究问题:如何利用现有科研论文中的信息训练语言模型生成更高质量、符合特定研究目标和约束的研究计划?
🔸主要贡献:论文提出了一种可扩展的训练方法,使用语言模型从科研论文中自动提取研究目标和评价量表,并通过强化学习自评分来提高生成研究计划的质量,无需外部人类监督。
📝重点思路
🔸利用语言模型自动从科研论文中提取研究目标和目标特定的评价量表,构建可扩展、多样化的训练语料库。
🔸训练研究计划生成模型通过强化学习,使用自评分机制,其中初始模型的冻结副本作为评分者,利用提取的评价量表作为评分依据。
🔸教授评分者模型识别生成计划的弱点,并列出未满足的通用评价准则,以便细化评分和分析。
🔸使用生成的研究计划和评分者的自评分机制,结合群模型评估,验证生成计划的质量,并确保训练方法的有效性。
🔎分析总结
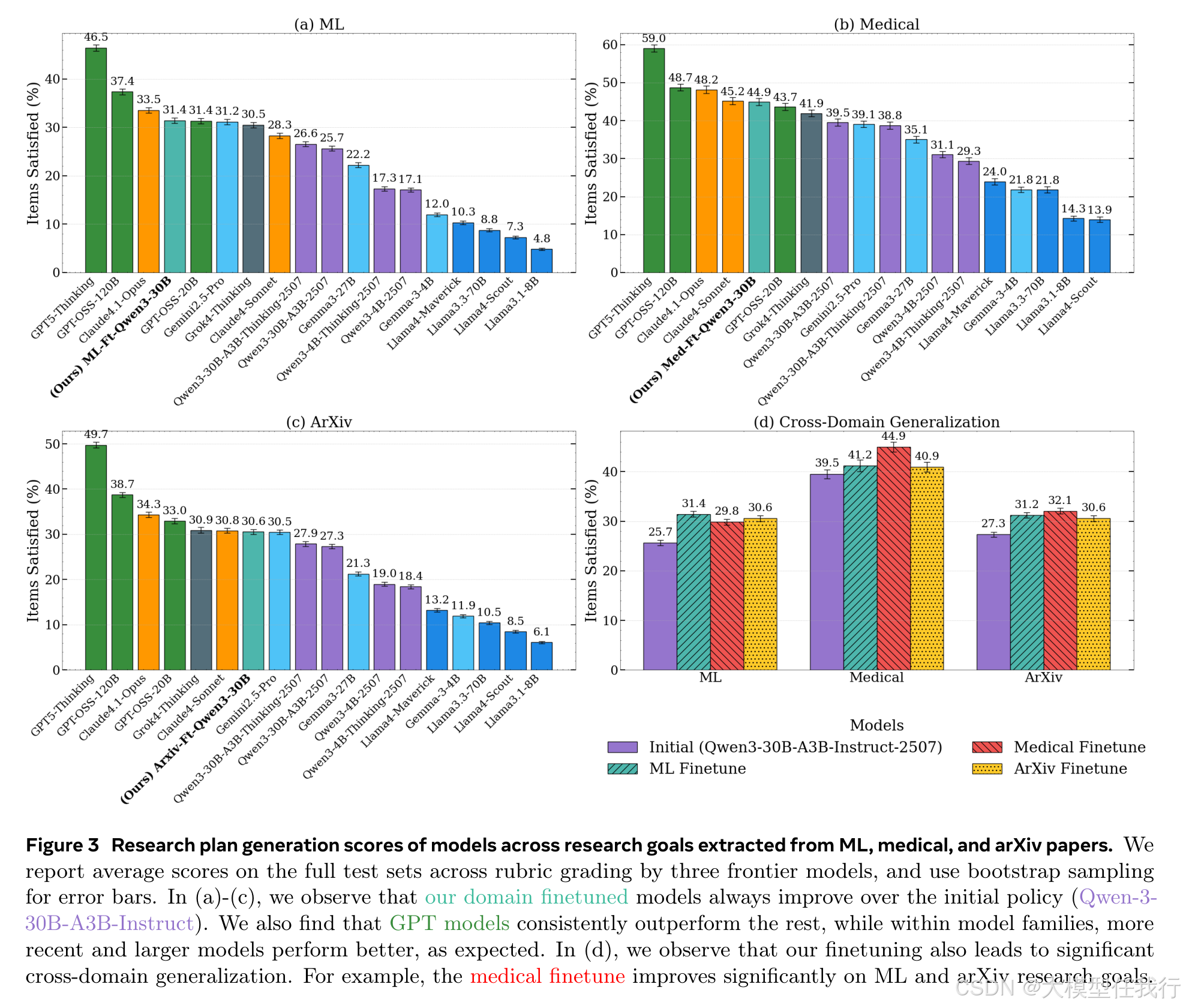
🔸通过专家评估,70%的研究目标生成计划得到了改进,84%的自动生成的评价量表被认为是必要的。
🔸研究计划生成模型在机器学习、医学和arXiv预印本等多个领域的研究目标上均表现出显著的改善,具有较强的跨领域泛化能力。
🔸在医学领域,生成的研究计划显著提高了在机器学习和arXiv研究目标上的质量,即使在执行反馈不可行的问题设置中也能有效改进。
🔸监督微调(SFT)在生成研究计划的任务上表现不佳,而强化学习(RL)则显著提高了生成计划的质量。
💡个人观点
论文利用现有科研论文中的信息和自评分机制,有效地提高了语言模型无监督学习生成研究计划的质量。
🧩附录