目录
- 前言
- 一、选题意义背景
- 二、数据集
- 三、功能模块介绍
- 四、算法理论
- 五、核心代码介绍
-
- 可变形注意力模块实现
- [Inner-MPD IoU Loss损失函数实现](#Inner-MPD IoU Loss损失函数实现)
- C2f-Ghostsim轻量化模块实现
- 六、重难点和创新点
- 七、总结
- 八、参考文献
- 最后
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
** 选题指导:**
最新最全计算机专业毕设选题精选推荐汇总
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于YOLOv8改进的密集场景口罩佩戴实时检测方法研究
一、选题意义背景
在期间,全球公共卫生安全面临着新的挑战和机遇。随着社会活动逐步恢复正常,人口流动频繁,密集人群场景下的公共卫生管理变得尤为重要。口罩作为一种简单有效的防护手段,在传染病防控和空气质量不佳的环境中发挥着关键作用。准确、高效地监测密集人群中的口罩佩戴情况,成为公共卫生管理和安全防控的重要需求。传统的口罩佩戴检测方法主要依赖人工巡检,这种方式不仅耗费大量人力资源,而且容易受到主观因素影响,检测效率和准确性难以保证。随着计算机视觉和深度学习技术的快速发展,基于深度学习的目标检测算法为口罩佩戴检测提供了新的解决方案。然而,在密集人群场景下,传统的目标检测算法面临着诸多挑战:目标之间相互遮挡、姿态变化多样、光照条件复杂、背景干扰严重等,这些因素都极大地影响了检测的准确性和鲁棒性。
YOLO系列算法作为一种单阶段目标检测算法,因其检测速度快、精度高等优点,被广泛应用于各种实际场景。最新的YOLOv8算法在网络结构、特征提取和损失函数等方面进行了全面升级,进一步提升了检测性能。然而,在密集人群场景下,YOLOv8算法仍然存在一些不足:特征提取不够精准、对小目标和遮挡目标的检测能力有限、模型参数量大导致难以在资源受限设备上部署等。研究如何改进现有的目标检测算法,使其在密集人群场景下能够更准确、更高效地检测口罩佩戴情况,具有重要的理论意义和实际应用价值。一方面,通过引入先进的注意力机制和轻量化策略,可以有效提升模型的特征提取能力和检测精度,同时降低模型的计算复杂度和参数量;另一方面,开发出的轻量化检测模型可以部署在边缘设备上,实现实时检测,为公共卫生管理提供技术支持。
从应用前景来看,密集人群口罩佩戴检测技术不仅可以应用于疫情防控,还可以广泛应用于公共场所安全管理、智能监控、智慧城市建设等领域。在机场、火车站、商场、学校等人员密集场所,实时监测人群口罩佩戴情况,可以及时发现潜在风险,提高管理效率。同时,随着技术的不断成熟和成本的降低,该技术有望进一步普及,为社会公共安全提供更全面的保障。综上所述,研究基于深度学习的密集人群口罩佩戴检测方法,对于提升公共卫生管理水平、保障社会安全稳定具有重要意义。本研究旨在通过改进现有的目标检测算法,提出一种高精度、高效率的口罩佩戴检测方法,为实际应用提供技术支持和理论参考。
二、数据集
本研究使用的数据集主要包括两个部分:AIZOO补充数据集和Face Mask Detection数据集。这两个数据集涵盖了不同场景、不同光照条件下的密集人群口罩佩戴图像,为模型的训练和评估提供了丰富的数据支持。
数据获取
AIZOO补充数据集是在原有AIZOO数据集的基础上进行扩充和优化的。原AIZOO数据集包含了一定数量的口罩佩戴图像,但在密集人群场景下的样本数量和多样性不足。为了更好地适应密集人群场景下的口罩佩戴检测任务,研究团队通过多种渠道采集了大量真实场景下的密集人群口罩佩戴图像。这些图像主要来源于公共监控视频、网络公开数据集以及研究团队实地拍摄的照片。采集的图像覆盖了不同的时间(白天、夜晚)、不同的地点(商场、街道、车站、学校等)和不同的人群密度,确保了数据集的多样性和代表性。

Face Mask Detection数据集是一个公开的口罩佩戴检测数据集,包含了大量人脸口罩佩戴和未佩戴的图像样本。该数据集通过网络公开渠道获取,研究团队对其进行了筛选和预处理,确保数据质量符合实验要求。
数据格式
两个数据集的图像均采用JPEG格式存储,分辨率根据原始图像来源有所不同,主要集中在640×480到1920×1080之间。为了统一处理和提高模型训练效率,所有图像在训练前都被调整为统一的尺寸。
在数据规模方面,AIZOO补充数据集包含约10,000张密集人群口罩佩戴图像,其中训练集、验证集和测试集的比例为7:1:2。每张图像中平均包含15-30个人脸目标,总计约20万个标注样本。Face Mask Detection数据集包含约3,000张图像,其中训练集、验证集和测试集的比例同样为7:1:2,总计约5万个标注样本。
类别定义
数据集中的目标类别主要分为两类:佩戴口罩(mask)和未佩戴口罩(no_mask)。其中,佩戴口罩类别定义为:人脸区域被口罩完全或大部分覆盖(覆盖率超过70%);未佩戴口罩类别定义为:人脸区域未被口罩覆盖,或覆盖率低于30%。对于口罩部分遮挡(覆盖率在30%-70%之间)的情况,根据具体遮挡程度和遮挡位置进行判断,确保标注的准确性和一致性。
数据分割策略
为了保证模型训练、验证和测试的有效性,研究团队采用了科学的数据分割策略。首先,对所有采集的图像进行初步筛选,去除质量不佳、标注困难或不符合任务要求的图像。然后,将剩余图像按照7:1:2的比例划分为训练集、验证集和测试集。在分割过程中,采用了分层抽样的方法,确保三个集合中的数据分布尽可能一致,避免因数据分布不均导致的模型过拟合或泛化能力不足的问题。
具体来说,在划分训练集时,优先选择包含不同场景、不同光照条件、不同人群密度和不同姿态变化的图像,确保训练数据的多样性和代表性。验证集用于在训练过程中评估模型性能,及时调整超参数,防止过拟合。测试集则完全独立于训练过程,用于最终评估模型的泛化能力和检测精度。
数据预处理
为了提高模型的训练效果和鲁棒性,研究团队对原始数据进行了一系列预处理操作:
首先,对所有图像进行尺寸调整,统一缩放至模型所需的输入尺寸。考虑到YOLOv8算法的特性,将图像调整为640×640大小,既保证了足够的细节信息,又不会增加过多的计算负担。
其次,进行数据增强操作。针对密集人群场景的特点,采用了多种增强策略:
-
Mosaic增强:将四张不同的图像随机裁剪后拼接成一张新的图像,增加小目标样本和上下文信息的多样性,提高模型对小目标的检测能力。
-
随机翻转:包括水平翻转和垂直翻转,增加数据的多样性,减少过拟合风险。
-
随机旋转:对图像进行小角度旋转(±10度),增强模型对不同姿态目标的适应能力。
-
颜色变换:调整图像的亮度、对比度、饱和度和色调,模拟不同光照条件下的场景,提高模型的鲁棒性。
-
随机裁剪:对图像进行随机裁剪,增加局部特征的训练样本,提高模型对部分遮挡目标的检测能力。
此外,还进行了标注数据的转换和格式化。将原始标注数据转换为YOLO格式,便于模型训练。YOLO格式的标注文件为每个图像生成一个对应的txt文件,文件中每一行代表一个目标的标注信息,包括类别索引和归一化的中心坐标、宽度和高度。
最后,对数据进行统计分析,计算各类别的样本数量、分布情况等统计指标,为模型训练和评估提供参考依据。通过这些预处理操作,不仅提高了数据的质量和多样性,还增强了模型的泛化能力和鲁棒性,为后续的模型训练和实验奠定了坚实的基础。
三、功能模块介绍
数据采集与预处理模块
数据采集与预处理模块是整个系统的基础,负责获取原始数据并进行清洗、标注和增强,为模型训练提供高质量的数据集。该模块主要包括数据采集、数据清洗、数据标注和数据增强四个子模块。

数据采集子模块通过多种渠道获取密集人群口罩佩戴图像,包括公共监控视频截取、网络公开数据集下载以及实地拍摄等方式。该子模块具备自动爬取和筛选功能,可以根据预设条件从网络资源中筛选出符合要求的图像,并支持批量下载和存储。同时,针对视频资源,该子模块还提供了关键帧提取功能,能够自动识别视频中的关键帧并保存为图像。
数据清洗子模块负责对采集到的原始数据进行质量评估和筛选。该子模块采用基于图像质量评估的算法,对图像的清晰度、对比度、光照条件等进行自动检测,去除模糊、过暗或过亮的低质量图像。同时,还对图像中的噪声进行初步过滤,确保数据的基本质量。此外,该子模块还提供了重复图像检测功能,避免重复样本对模型训练的影响。
数据标注子模块是整个预处理流程的核心环节,负责为图像中的目标进行准确的类别标注和位置标注。该子模块集成了半自动标注工具,结合深度学习预训练模型,可以快速识别图像中的人脸区域,并自动生成初步的标注框。标注人员可以在半自动标注的基础上进行人工审核和修正,大大提高了标注效率。标注结果保存为YOLO格式的txt文件,包含类别索引和归一化的目标位置信息。
数据增强子模块通过多种图像变换技术,扩充数据集规模,提高模型的泛化能力和鲁棒性。该子模块实现了Mosaic增强、随机翻转、随机旋转、颜色变换等多种增强策略,并支持参数化配置,可以根据不同的任务需求调整增强强度和方式。增强后的图像和对应的标注信息自动保存到指定目录,为后续的模型训练提供输入数据。
通过数据采集与预处理模块的处理,原始数据被转化为高质量、多样化的训练数据集,为后续的模型训练和优化提供了坚实的数据基础。该模块的高效运行大大缩短了数据准备的时间,提高了整个系统的工作效率。
模型训练与优化模块
模型训练与优化模块是系统的核心部分,负责构建、训练和优化口罩佩戴检测模型。该模块主要包括模型构建、损失函数设计、优化策略选择和模型评估四个子模块。
模型构建子模块基于YOLOv8算法框架,实现了基础模型和改进模型的构建。该子模块支持网络结构的灵活配置,可以根据任务需求调整网络的深度、宽度和特征提取能力。针对密集人群场景的特点,该子模块还集成了可变形注意力机制和C2f-Ghostsim轻量化模块,实现了YOLOv8-DA和YOLOv8-DA-Ghostsim两种改进模型的构建。模型构建完成后,自动生成模型的网络结构图和参数量统计,为后续的优化提供参考。
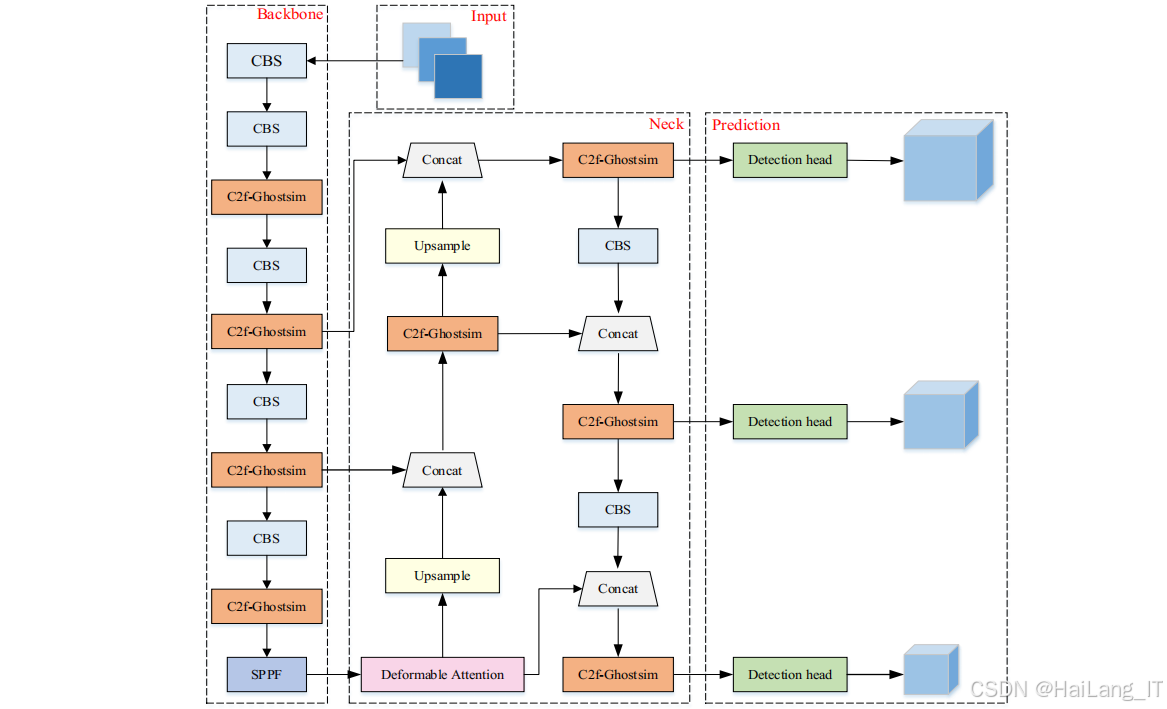
损失函数设计子模块负责设计和实现适合口罩佩戴检测任务的损失函数。该子模块不仅实现了YOLOv8原有的损失函数组合(VFL损失、CIoU损失和DFL损失),还开发了针对密集人群场景优化的Inner-MPD IoU损失函数。该损失函数结合了Inner-IoU的辅助边框思想和MPD IoU的边界框几何特性,能够更有效地处理密集人群中的目标重叠问题,提高边界框回归的准确性。损失函数设计子模块支持多种损失函数的组合使用,可以根据实验需求灵活调整各部分损失的权重。
优化策略选择子模块负责选择和配置模型训练的优化算法和超参数。该子模块支持多种优化器(如SGD、Adam等),并提供了学习率调整策略(如余弦退火、多项式衰减等)。针对口罩佩戴检测任务的特点,选择了SGD优化器,设置了合适的初始学习率、动量和权重衰减系数,以保证模型训练的稳定性和收敛速度。同时,该子模块还实现了早停机制和模型保存策略,可以自动保存性能最优的模型权重,避免过拟合。
模型评估子模块负责在训练过程中实时评估模型性能,并生成详细的评估报告。该子模块支持多种评估指标,包括准确率、召回率、精确率、mAP@0.5、mAP@0.95等。在验证集上,该子模块定期评估模型性能,并生成性能曲线和热力图,直观展示模型的学习过程和检测效果。同时,该子模块还实现了模型性能对比功能,可以对不同模型在相同数据集上的表现进行对比分析,为模型选择提供依据。
通过模型训练与优化模块的处理,系统能够自动构建和训练适合密集人群口罩佩戴检测任务的深度学习模型,并通过持续优化提高模型性能。该模块的灵活性和可扩展性使其能够适应不同的应用场景和需求,为实际应用提供了强有力的技术支持。
模型部署与应用模块
模型部署与应用模块负责将训练好的模型部署到实际应用环境中,实现对图像和视频中密集人群口罩佩戴情况的实时检测。该模块主要包括模型转换、推理优化、应用接口设计和可视化展示四个子模块。
模型转换子模块负责将训练好的模型转换为适合部署的格式。该子模块支持将PyTorch模型转换为ONNX格式,便于在不同平台和设备上部署。同时,还支持模型量化和剪枝操作,可以进一步减小模型体积,提高推理速度。模型转换完成后,自动生成部署所需的配置文件和依赖库列表,确保模型能够在目标环境中正常运行。
推理优化子模块负责优化模型的推理过程,提高检测速度和效率。该子模块实现了批处理推理、多线程处理和GPU加速等优化技术,可以充分利用硬件资源,提高模型的吞吐量。同时,还采用了图像预处理优化策略,如调整输入尺寸、采用适当的色彩空间转换等,在保证检测精度的前提下进一步提高推理速度。此外,该子模块还实现了模型缓存机制,可以缓存常用的中间计算结果,减少重复计算,提高实时性。
应用接口设计子模块提供了灵活的API接口,便于与其他系统集成。该接口支持图像和视频两种输入方式,并提供了同步和异步两种调用模式。同步调用模式适用于对实时性要求较高的场景,可以立即返回检测结果;异步调用模式适用于批量处理场景,可以提高系统的并发处理能力。接口返回的检测结果包括目标位置、类别和置信度等信息,便于上层应用进行进一步处理和展示。
可视化展示子模块负责将检测结果以直观的方式展示给用户。该子模块实现了检测结果的实时绘制和展示功能,可以在图像或视频上标注出检测到的目标,并显示目标的类别和置信度。同时,还提供了统计分析功能,可以实时统计检测到的佩戴口罩和未佩戴口罩的人数比例,并以图表形式展示。此外,该子模块还支持检测结果的保存和导出功能,可以将标注后的图像或视频保存为文件,便于后续分析和查看。
基于模型部署与应用模块,研究团队开发了一款界面简洁、功能完善的口罩佩戴检测系统。该系统支持图片检测和视频检测两种模式,可以实时检测图像或视频中的密集人群口罩佩戴情况,并将结果可视化展示。系统界面设计直观友好,操作简单便捷,用户可以轻松加载待检测的图像或视频,并查看实时的检测结果。同时,系统还提供了结果保存功能,可以将检测结果保存到指定目录,便于后续分析和管理。
通过模型部署与应用模块的处理,训练好的模型能够在实际应用环境中高效运行,为密集人群口罩佩戴检测提供了实用的解决方案。该模块的灵活性和可扩展性使其能够适应不同的应用场景和需求,为公共卫生管理和安全防控提供了有力的技术支持。
四、算法理论
卷积神经网络基础理论
卷积神经网络(CNN)是深度学习中用于图像处理的重要模型,其核心思想是通过卷积操作提取图像特征。CNN主要由卷积层、池化层和全连接层组成,各层各司其职,共同完成特征提取和分类任务。
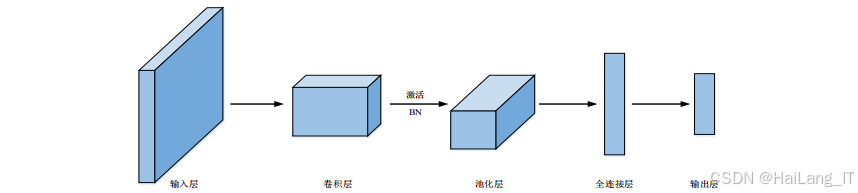
卷积层是CNN的核心组件,负责提取图像的局部特征。卷积操作通过一个可学习的卷积核在输入特征图上滑动,逐像素计算局部区域的加权和,生成新的特征图。卷积操作具有局部连接和参数共享的特点,大大减少了模型的参数量,提高了计算效率。在口罩佩戴检测任务中,卷积层能够有效提取人脸和口罩的边缘、纹理等局部特征,为后续的分类和定位提供基础。

池化层位于卷积层之后,用于降低特征图的维度,减少计算量,同时保持特征的空间不变性。常用的池化操作包括最大池化和平均池化,其中最大池化保留了特征图中的最大响应值,能够有效突出主要特征;平均池化则计算局部区域的平均值,对噪声有一定的抑制作用。在口罩佩戴检测任务中,池化层可以帮助模型关注人脸和口罩的关键区域,提高检测的鲁棒性。
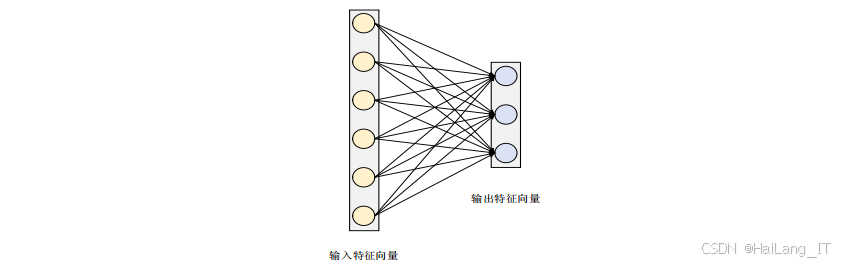
全连接层位于网络的最后部分,用于将提取到的特征映射到最终的输出类别。全连接层的每个神经元与上一层的所有神经元相连,可以整合不同位置的特征信息。在目标检测任务中,全连接层通常用于预测目标的类别和位置信息。
除了上述基本组件外,现代CNN还广泛使用了批量归一化(Batch Normalization)、激活函数和残差连接等技术。批量归一化可以加速模型训练,提高模型的稳定性;激活函数如ReLU及其变种可以引入非线性变换,增强模型的表达能力;残差连接则可以有效缓解深层网络的梯度消失问题,便于训练更深的网络。
YOLOv8算法详解
YOLOv8是Ultralytics公司于2023年发布的YOLO系列最新版本,在网络结构、特征提取、损失函数等方面进行了全面升级,进一步提升了检测性能。YOLOv8算法主要由输入端、主干网络(Backbone)、颈部网络(Neck)和输出端四部分组成。
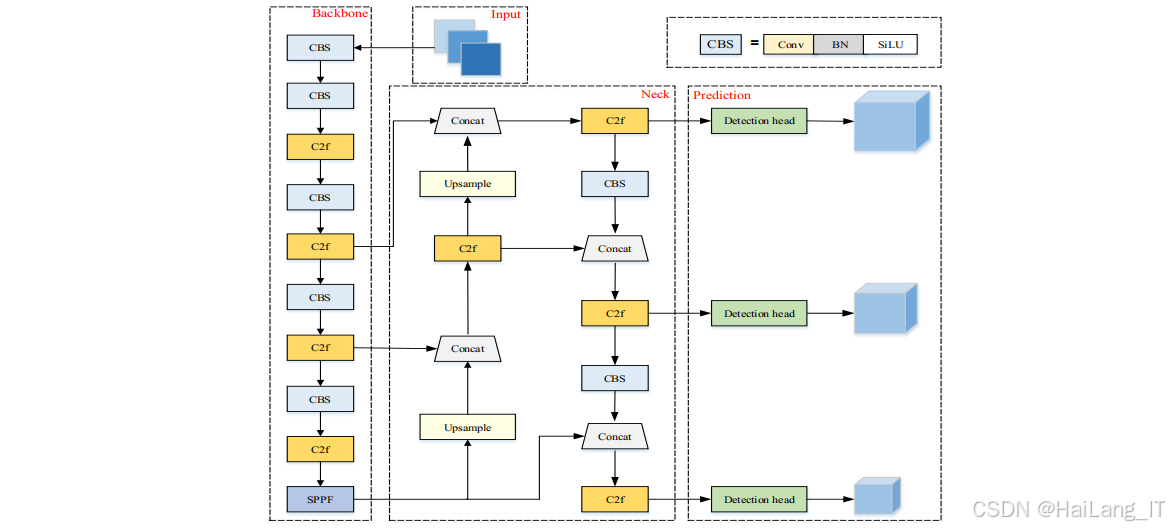
输入端负责图像预处理和数据增强。YOLOv8采用了Mosaic增强技术,将四张不同的图像随机裁剪后拼接成一张新的图像,增加小目标样本和上下文信息的多样性。同时,还采用了自适应锚框计算、自适应图像缩放等技术,提高模型的训练效率和鲁棒性。
主干网络(Backbone)负责特征提取,YOLOv8采用了C2f模块作为主要的特征提取单元。C2f模块是对YOLOv5中C3模块的改进,通过增加分支结构和更多的跳跃连接,增强了特征的重用能力,提高了特征提取效率。同时,YOLOv8还使用了SPPF(Spatial Pyramid Pooling - Fast)模块,通过多尺度池化操作,融合不同尺度的特征信息,增强模型对不同大小目标的适应能力。
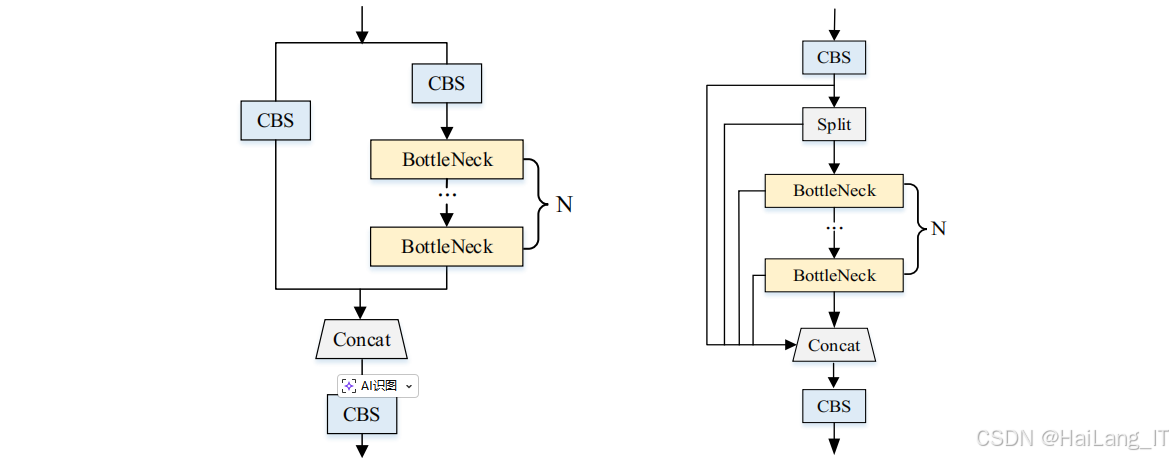
颈部网络(Neck)负责特征融合,YOLOv8采用了FPN(Feature Pyramid Network)+PAN(Path Aggregation Network)的结构。FPN通过自上而下的路径将高层语义特征传递到低层,PAN则通过自下而上的路径将低层细节特征传递到高层,两者结合可以有效融合不同尺度和不同层次的特征信息,提高模型的检测精度。
输出端负责目标分类和定位,YOLOv8采用了解耦的检测头设计,将分类和回归任务分开处理,提高了模型的收敛速度和检测精度。同时,YOLOv8采用了无锚框(Anchor-Free)的设计理念,直接预测目标的中心点和宽高比例,减少了超参数的调整,提高了检测的灵活性。在损失函数方面,YOLOv8使用了VFL(Varifocal Loss)作为分类损失,CIoU(Complete Intersection over Union)作为回归损失,DFL(Distribution Focal Loss)作为位置预测损失,这三种损失函数的组合能够有效提高模型的分类准确性和定位精度。
可变形注意力机制
可变形注意力机制是基于可变形卷积和Transformer自注意力机制发展而来的一种新型注意力机制,能够自适应地关注图像中的关键区域,提高模型的特征提取能力。传统的卷积操作在固定的感受野内提取特征,难以适应目标形状和大小的变化。可变形卷积通过在标准卷积的基础上增加偏移量,使卷积核能够根据目标的形状和位置进行自适应调整,提高了模型对变形目标的适应能力。可变形注意力机制进一步发展了这一思想,通过计算特征图上不同位置的注意力权重,动态调整特征的聚合方式,使模型能够更有效地关注目标的关键区域。
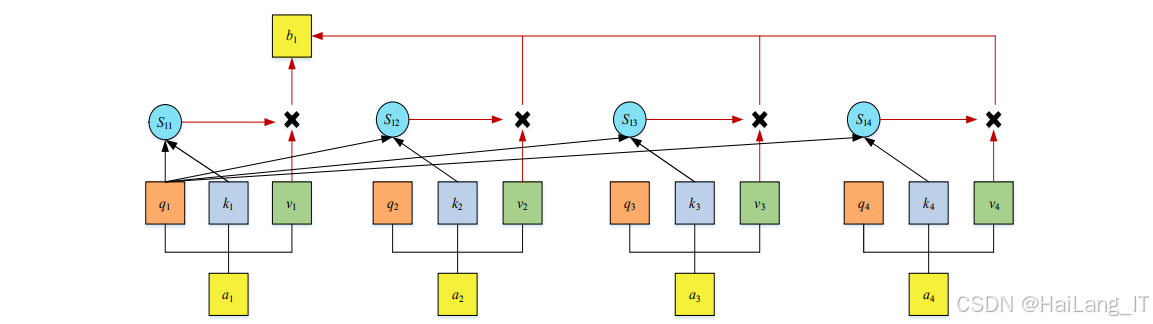
可变形注意力机制的核心在于注意力权重的计算。该机制首先通过线性变换将输入特征映射到查询、键和值三个特征空间,然后计算查询和键之间的相似度,得到注意力权重。与传统的自注意力机制不同,可变形注意力机制通过可学习的偏移量调整查询和键的位置,使注意力计算更加灵活和自适应。最后,根据注意力权重对值进行加权求和,得到最终的注意力特征。
在口罩佩戴检测任务中,可变形注意力机制能够有效提高模型对密集人群中人脸和口罩的关注度,尤其是在目标相互遮挡、姿态变化多样的情况下,能够更准确地提取目标特征,提高检测精度。
GhostNetV2轻量化网络
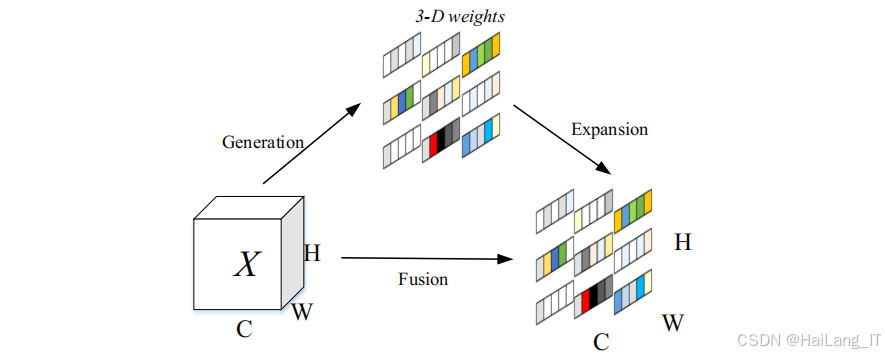
GhostNetV2是华为诺亚方舟实验室于2022年提出的一种轻量级神经网络,在GhostNet的基础上加入了解耦全连接注意力机制,既保持了模型的轻量化特性,又增强了特征表示能力。GhostNet的核心设计理念是通过Ghost模块减少冗余计算。传统卷积生成的特征图中存在大量冗余信息,Ghost模块通过分阶段的卷积操作,首先生成少量的基础特征图,然后通过廉价的线性运算生成额外的特征图,有效减少了计算量和参数量。
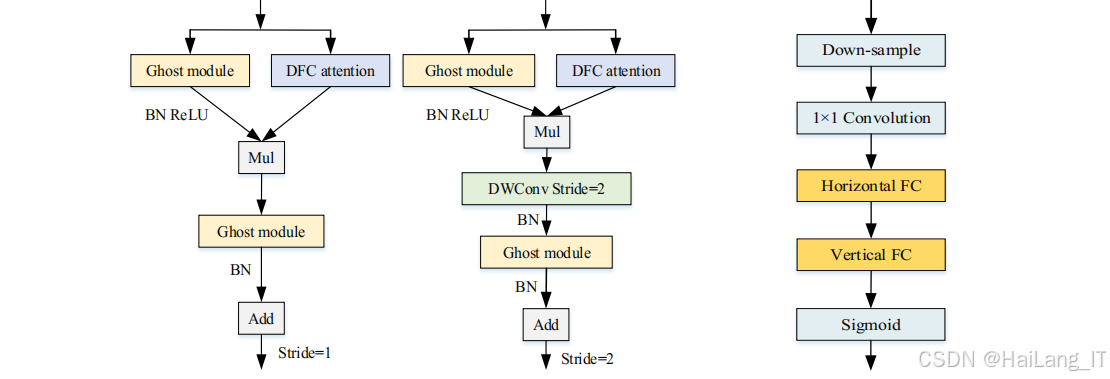
GhostNetV2在GhostNet的基础上引入了解耦全连接注意力机制,解决了Ghost模块在处理全局信息时的局限性。解耦全连接注意力机制将一个全连接层分解为水平全连接层和垂直全连接层,分别沿水平和垂直方向建模长距离依赖关系,然后将两个方向的注意力特征融合,得到全局的注意力信息。这种设计不仅有效减少了计算复杂度,还能够捕获特征图中的长距离依赖关系,增强模型的特征表示能力。在口罩佩戴检测任务中,GhostNetV2轻量化网络能够在保证检测精度的前提下,有效减少模型的参数量和计算量,使其更适合在资源受限的设备上部署和应用。
SimAM注意力机制
SimAM是一种简单、高效的无参数注意力模块,由YANG等人于2021年提出。该模块不依赖额外的参数,通过对特征图中每个位置的相对重要性进行计算,自适应地调整特征的权重分布,增强模型的特征提取能力。SimAM模块的设计灵感来源于人脑的注意力机制,旨在模拟人脑处理信息时的聚焦和忽略过程。该模块通过衡量神经元间的线性区分能力,实现对网络中神经元的优化,培养更有识别力的神经元。具体来说,SimAM模块基于神经科学理论,利用SVM算法的特征,设计了一种能量函数,用于评估每个神经元的重要性。能量函数的最小值对应神经元的最优状态,能量越低,神经元的重要性越高。
在口罩佩戴检测任务中,SimAM模块能够有效突出与口罩佩戴相关的特征信息,抑制无关的噪声干扰,提高模型在复杂环境下的检测精度和鲁棒性。同时,由于SimAM是一种无参数的注意力机制,不会增加模型的参数量和计算复杂度,非常适合与轻量化网络结合使用。
五、核心代码介绍
可变形注意力模块实现
可变形注意力模块是YOLOv8-DA模型的核心组件,通过动态调整特征的聚合方式,提高了模型对密集人群中人脸和口罩的特征提取能力。以下是可变形注意力模块的核心代码实现:
python
class DeformableAttention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, dropout=0.):
super().__init__()
self.dim = dim
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = head_dim ** -0.5
# 定义查询、键、值的投影层
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
# 定义可变形偏移量的预测层
self.offset_pred = nn.Linear(dim, num_heads * 2)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(dropout)
def forward(self, x):
B, N, C = x.shape
# 计算查询、键、值
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # B, H, N, C
# 预测可变形偏移量
offset = self.offset_pred(x).reshape(B, N, self.num_heads, 2)
offset = offset.permute(0, 2, 1, 3) # B, H, N, 2
# 应用可变形偏移量到键位置
k_positions = self.get_position_embedding(B, N, x.device).unsqueeze(1).repeat(1, self.num_heads, 1, 1)
k_deformed = k_positions + offset
k = self.sample_features(k, k_deformed, B, N, self.num_heads, C // self.num_heads)
# 计算注意力权重
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
# 应用注意力到值
v_positions = self.get_position_embedding(B, N, x.device).unsqueeze(1).repeat(1, self.num_heads, 1, 1)
v_deformed = v_positions + offset
v = self.sample_features(v, v_deformed, B, N, self.num_heads, C // self.num_heads)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
def get_position_embedding(self, B, N, device):
# 生成位置嵌入
h = w = int(math.sqrt(N))
grid_y, grid_x = torch.meshgrid(torch.arange(h), torch.arange(w), indexing='ij')
grid = torch.stack([grid_x, grid_y], dim=-1).float().reshape(1, -1, 2).repeat(B, 1, 1)
return grid.to(device)
def sample_features(self, features, positions, B, N, H, C):
# 根据变形位置采样特征
h = w = int(math.sqrt(N))
positions = positions.reshape(B, H, h, w, 2)
features = features.reshape(B, H, h, w, C)
# 确保位置在有效范围内
positions[..., 0] = 2.0 * positions[..., 0] / (w - 1) - 1.0
positions[..., 1] = 2.0 * positions[..., 1] / (h - 1) - 1.0
# 使用双线性插值采样特征
output = F.grid_sample(
features.permute(0, 4, 1, 2, 3).reshape(B * C, H, h, w),
positions.reshape(B, H, h, w, 2),
mode='bilinear',
padding_mode='zeros',
align_corners=False
)
output = output.reshape(B, C, H, h, w).permute(0, 2, 3, 4, 1).reshape(B, H, N, C)
return output可变形注意力模块的核心功能。首先,模块通过线性变换将输入特征映射到查询、键、值三个特征空间。然后,预测可变形偏移量,并将其应用到键和值的位置上,使注意力计算能够自适应地关注图像中的关键区域。最后,通过注意力权重对值进行加权求和,得到增强后的特征表示。该模块的设计充分考虑了密集人群场景的特点,能够有效提高模型对人脸和口罩的特征提取能力,从而提升检测精度。
Inner-MPD IoU Loss损失函数实现
Inner-MPD IoU Loss是针对密集人群场景优化的损失函数,结合了Inner-IoU的辅助边框思想和MPD IoU的边界框几何特性,能够更有效地处理密集人群中的目标重叠问题。以下是Inner-MPD IoU Loss的核心代码实现:
python
def inner_mpd_iou_loss(pred, target, alpha=0.5, gamma=2.0):
"""
Inner-MPD IoU Loss计算函数
pred: 预测的边界框坐标 [batch_size, num_boxes, 4],格式为 [x1, y1, x2, y2]
target: 目标边界框坐标 [batch_size, num_boxes, 4],格式为 [x1, y1, x2, y2]
alpha: 平衡Inner-IoU和MPD IoU的权重参数
gamma: 焦点损失的聚焦参数
"""
# 计算传统IoU
iou = bbox_iou(pred, target, CIoU=False)
# 计算Inner-IoU
# 提取边界框中心点
pred_center_x = (pred[..., 0] + pred[..., 2]) / 2
pred_center_y = (pred[..., 1] + pred[..., 3]) / 2
target_center_x = (target[..., 0] + target[..., 2]) / 2
target_center_y = (target[..., 1] + target[..., 3]) / 2
# 计算Inner-Box
inner_x1 = torch.max(pred[..., 0], target[..., 0])
inner_y1 = torch.max(pred[..., 1], target[..., 1])
inner_x2 = torch.min(pred[..., 2], target[..., 2])
inner_y2 = torch.min(pred[..., 3], target[..., 3])
# 计算Inner-Box的面积
inner_area = torch.clamp(inner_x2 - inner_x1, min=0) * torch.clamp(inner_y2 - inner_y1, min=0)
# 计算最小外接矩形面积
outer_x1 = torch.min(pred[..., 0], target[..., 0])
outer_y1 = torch.min(pred[..., 1], target[..., 1])
outer_x2 = torch.max(pred[..., 2], target[..., 2])
outer_y2 = torch.max(pred[..., 3], target[..., 3])
outer_area = (outer_x2 - outer_x1) * (outer_y2 - outer_y1)
# 计算Inner-IoU
inner_iou = inner_area / outer_area
# 计算MPD IoU (Minimum Point Distance IoU)
# 计算预测框和目标框四个角点之间的最小距离
pred_corners = torch.stack([
torch.stack([pred[..., 0], pred[..., 1]], dim=-1), # 左上
torch.stack([pred[..., 2], pred[..., 1]], dim=-1), # 右上
torch.stack([pred[..., 0], pred[..., 3]], dim=-1), # 左下
torch.stack([pred[..., 2], pred[..., 3]], dim=-1), # 右下
], dim=-2)
target_corners = torch.stack([
torch.stack([target[..., 0], target[..., 1]], dim=-1), # 左上
torch.stack([target[..., 2], target[..., 1]], dim=-1), # 右上
torch.stack([target[..., 0], target[..., 3]], dim=-1), # 左下
torch.stack([target[..., 2], target[..., 3]], dim=-1), # 右下
], dim=-2)
# 计算所有角点对之间的距离
corner_dist = torch.cdist(pred_corners, target_corners, p=2)
# 找到最小距离
min_corner_dist, _ = torch.min(corner_dist, dim=-1)
min_corner_dist, _ = torch.min(min_corner_dist, dim=-1)
# 计算预测框和目标框的对角线长度
pred_diag = torch.sqrt((pred[..., 2] - pred[..., 0])**2 + (pred[..., 3] - pred[..., 1])**2)
target_diag = torch.sqrt((target[..., 2] - target[..., 0])**2 + (target[..., 3] - target[..., 1])**2)
max_diag = torch.max(pred_diag, target_diag)
# 计算MPD IoU
mpd_term = 1.0 - torch.exp(-gamma * min_corner_dist / (max_diag + 1e-16))
# 组合Inner-IoU和MPD IoU
loss = (1 - inner_iou) * alpha + mpd_term * (1 - alpha)
# 应用焦点损失
loss = (1 - iou) * loss
return loss.mean()
class InnerMPDIoULoss(nn.Module):
def __init__(self, alpha=0.5, gamma=2.0):
super().__init__()
self.alpha = alpha
self.gamma = gamma
def forward(self, pred, target):
return inner_mpd_iou_loss(pred, target, self.alpha, self.gamma)Inner-MPD IoU Loss损失函数的核心逻辑。该损失函数由两部分组成:Inner-IoU和MPD IoU。Inner-IoU通过计算预测框和目标框的重叠区域与最小外接矩形的比例,有效处理了密集人群中的目标重叠问题;MPD IoU则通过计算预测框和目标框角点之间的最小距离,增强了对边界框几何特性的约束。通过alpha参数平衡这两部分的权重,并结合焦点损失策略,进一步提高了模型对困难样本的关注度。该损失函数的设计充分考虑了密集人群场景下目标检测的特点,能够有效提高边界框回归的准确性,从而提升口罩佩戴检测的精度。
C2f-Ghostsim轻量化模块实现
C2f-Ghostsim模块是YOLOv8-DA-Ghostsim模型的核心组件,结合了GhostNetV2的轻量化思想和SimAM无参数注意力机制,在保证检测精度的前提下,有效降低了模型的参数量和计算量。以下是C2f-Ghostsim模块的核心代码实现:
python
class SimAM(nn.Module):
def __init__(self, e_lambda=1e-4):
super().__init__()
self.act = nn.Sigmoid()
self.e_lambda = e_lambda
def forward(self, x):
b, c, h, w = x.size()
# 计算每个通道的均值和方差
n = w * h - 1
x_minus_mu_sq = (x - x.mean(dim=[2, 3], keepdim=True)).pow(2)
sum_x_minus_mu_sq = x_minus_mu_sq.sum(dim=[2, 3], keepdim=True)
var = sum_x_minus_mu_sq / (n + 1e-5)
# 计算能量函数
e = (x.square() / (4 * (var + self.e_lambda))) + 0.5 * torch.log(var + self.e_lambda)
# 计算注意力权重
w = self.act(1 - e)
return x * w
class GhostModule(nn.Module):
def __init__(self, inp, oup, kernel_size=1, ratio=2, dw_size=3, stride=1, relu=True):
super().__init__()
self.oup = oup
init_channels = math.ceil(oup / ratio)
new_channels = init_channels * (ratio - 1)
# 主卷积
self.primary_conv = nn.Sequential(
nn.Conv2d(inp, init_channels, kernel_size, stride, kernel_size//2, bias=False),
nn.BatchNorm2d(init_channels),
nn.ReLU(inplace=True) if relu else nn.Identity(),
)
# 廉价操作
self.cheap_operation = nn.Sequential(
nn.Conv2d(init_channels, new_channels, dw_size, 1, dw_size//2, groups=init_channels, bias=False),
nn.BatchNorm2d(new_channels),
nn.ReLU(inplace=True) if relu else nn.Identity(),
)
def forward(self, x):
x1 = self.primary_conv(x)
x2 = self.cheap_operation(x1)
# 拼接特征
out = torch.cat([x1, x2], dim=1)
# 确保输出通道数正确
return out[:, :self.oup, :, :]
class GhostBottleneckSim(nn.Module):
def __init__(self, in_chs, mid_chs, out_chs, dw_kernel_size=3, stride=1):
super().__init__()
# Ghost模块1
self.ghost1 = GhostModule(in_chs, mid_chs, relu=True)
# 深度可分离卷积
if stride > 1:
self.dwconv = nn.Conv2d(mid_chs, mid_chs, dw_kernel_size, stride, dw_kernel_size//2,
groups=mid_chs, bias=False)
self.bn = nn.BatchNorm2d(mid_chs)
# SimAM注意力
self.simam = SimAM()
# Ghost模块2
self.ghost2 = GhostModule(mid_chs, out_chs, relu=False)
# 残差连接
self.shortcut = nn.Sequential()
if stride > 1 or in_chs != out_chs:
self.shortcut = nn.Sequential(
nn.Conv2d(in_chs, out_chs, 1, stride, bias=False),
nn.BatchNorm2d(out_chs),
)
def forward(self, x):
residual = x
x = self.ghost1(x)
if hasattr(self, 'dwconv'):
x = self.dwconv(x)
x = self.bn(x)
x = self.simam(x)
x = self.ghost2(x)
x += self.shortcut(residual)
return x
class C2fGhostsim(nn.Module):
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
super().__init__()
self.c = int(c2 * e)
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1)
self.m = nn.ModuleList(GhostBottleneckSim(self.c, self.c, self.c) for _ in range(n))
self.add = shortcut and c1 == c2
def forward(self, x):
y = list(self.cv1(x).chunk(2, 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1)) if self.add else self.cv2(torch.cat(y, 1)) + xC2f-Ghostsim轻量化模块的核心组件。首先,定义了SimAM无参数注意力模块,通过计算特征的能量函数来评估每个神经元的重要性,自适应地调整特征权重。然后,实现了GhostModule,通过主卷积和廉价操作的组合,有效减少了计算量和参数量。接着,构建了GhostBottleneckSim模块,集成了GhostModule和SimAM注意力,既保持了轻量化特性,又增强了特征表示能力。最后,实现了C2f-Ghostsim模块,通过堆叠多个GhostBottleneckSim模块,并结合跳跃连接,形成了高效的特征提取网络。该模块的设计充分考虑了模型轻量化和检测精度的平衡,能够在保证检测性能的前提下,有效降低模型的计算复杂度和内存占用,使其更适合在资源受限设备上部署和应用。
六、重难点和创新点
研究重点
本研究的重点在于解决密集人群场景下口罩佩戴检测的关键问题,提高检测的准确性和效率。具体来说,主要包括以下几个方面:
首先,密集人群场景下的目标检测面临着目标相互遮挡、姿态变化多样、光照条件复杂等挑战。如何提高模型对密集人群中人脸和口罩的特征提取能力,是本研究的首要重点。通过引入可变形注意力机制,使模型能够自适应地关注图像中的关键区域,有效提高了特征提取的准确性。
其次,传统的边界框回归损失函数在处理密集人群中的目标重叠问题时效果不佳。如何设计更适合密集场景的损失函数,提高边界框回归的精度,是本研究的另一个重点。通过结合Inner-IoU和MPD IoU的优点,提出了Inner-MPD IoU Loss,有效提高了边界框回归的准确性。
最后,实际应用场景对模型的轻量化和实时性要求较高。如何在保证检测精度的前提下,有效降低模型的参数量和计算量,是本研究的第三个重点。通过结合GhostNetV2的轻量化思想和SimAM无参数注意力机制,提出了C2f-Ghostsim模块,实现了模型的轻量化和高效化。
研究难点
在研究过程中,遇到了一些技术难点,需要通过创新的方法和策略来解决:
数据收集和标注的难点。密集人群场景下的口罩佩戴图像数据收集和标注难度较大,需要大量的人力和时间投入。同时,由于隐私保护等原因,获取真实场景下的密集人群数据也面临一定的挑战。为了解决这一难点,研究团队通过多种渠道采集数据,并结合半自动标注工具,提高了数据收集和标注的效率。
模型优化的难点。在保证检测精度的前提下,实现模型的轻量化和实时化是一个复杂的优化问题。需要在网络结构设计、损失函数优化、训练策略选择等多个方面进行综合考虑和权衡。通过反复的实验和对比,研究团队找到了最佳的模型配置和优化策略。
算法鲁棒性的难点。密集人群场景下的口罩佩戴检测任务对模型的鲁棒性要求较高,需要模型能够适应不同的光照条件、背景环境、人群密度等变化。为了提高模型的鲁棒性,研究团队采用了多种数据增强技术,并在不同的数据集上进行了充分的训练和测试。
创新点
本研究在密集人群口罩佩戴检测方法上提出了多项创新,主要包括以下几个方面:
提出了YOLOv8-DA模型,在YOLOv8网络中引入可变形注意力机制,有效提高了模型对密集人群中人脸和口罩的特征提取能力。可变形注意力机制能够自适应地调整特征的聚合方式,关注图像中的关键区域,从而提高检测精度。
设计了Inner-MPD IoU Loss损失函数,结合了Inner-IoU的辅助边框思想和MPD IoU的边界框几何特性,更有效地处理密集人群中的目标重叠问题。该损失函数通过计算预测框和目标框的重叠区域与最小外接矩形的比例,以及角点之间的最小距离,增强了对边界框几何特性的约束,提高了边界框回归的准确性。
提出了C2f-Ghostsim轻量化模块,结合了GhostNetV2的轻量化思想和SimAM无参数注意力机制,在保证检测精度的前提下,有效降低了模型的参数量和计算量。C2f-Ghostsim模块通过主卷积和廉价操作的组合,以及无参数注意力机制的引入,既保持了轻量化特性,又增强了特征表示能力。
开发了一款功能完善的口罩佩戴检测系统,支持图片和视频的实时检测,并提供了直观的可视化界面。该系统基于PyQt5开发,界面简洁友好,操作简单便捷,能够满足实际应用场景的需求。系统的开发进一步验证了所提出算法的有效性和实用性。
七、总结
本研究针对密集人群场景下口罩佩戴检测的需求,提出了一系列改进策略和算法模型,主要工作总结如下:
首先,针对密集人群场景下目标检测的特点和挑战,深入分析了现有目标检测算法的不足,并提出了相应的改进思路。通过引入可变形注意力机制和优化损失函数,提高了模型对密集人群中人脸和口罩的特征提取能力和检测精度。
其次,设计并实现了YOLOv-DA模型,通过在YOLOv8网络中引入可变形注意力机制,并采用Inner-MPD IoU Loss作为边界框回归损失函数,有效提高了模型在密集人群场景下的检测性能。
再次,为了满足实际应用场景对模型轻量化和实时性的要求,提出了C2f-Ghostsim轻量化模块,并构建了YOLOv8-DA-Ghostsim模型。该模型在保证检测精度的前提下,有效降低了参数量和计算量,使其更适合在资源受限的设备上部署和应用。
最后,基于所提出的算法模型,开发了一款功能完善的口罩佩戴检测系统,支持图片和视频的实时检测,并提供了直观的可视化界面。系统的开发和测试验证了所提出算法的有效性和实用性,为密集人群口罩佩戴检测的实际应用提供了有力的技术支持。
本研究的成果不仅在理论上丰富了密集人群场景下的目标检测方法,也为实际应用提供了可行的解决方案。未来,研究团队将继续优化算法模型,进一步提高检测精度和效率,并探索更多的应用场景和领域。同时,也将关注数据隐私和安全等问题,确保技术的合理应用和发展。
八、参考文献
\[\] Tang Y, Han K, Guo J, et al. GhostNetv2: Enhance cheap operation with long-range attentionJ. Advances in Neural Information Processing Systems, 2022, 35: 9969-9982.
2 Yang L, Zhang R Y, Li L, et al. Simam: A simple, parameter-free attention module for convolutional neural networksC. International conference on machine learning. PMLR, 2021: 11863-11874.
3 Xia Z, Pan X, Song S, et al. Vision transformer with deformable attentionC. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022: 4794-4803.
4 Zhang H, Xu C, Zhang S. Inner-iou: more effective intersection over union loss with auxiliary bounding boxJ. arXiv preprint arXiv:2311.02877, 2023.
5 Siliang M, Yong X. MPDIoU: A Loss for Efficient and Accurate Bounding Box RegressionJ. arXiv preprint arXiv:2307.07662, 2023.
6 Wang Q, Wu B, Zhu P, et al. ECA-Net: Efficient channel attention for deep convolutional neural networksC. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020: 11534-11542.
7 Ouyang D, He S, Zhang G, et al. Efficient multi-scale attention module with cross-spatial learningC. ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023: 1-5.