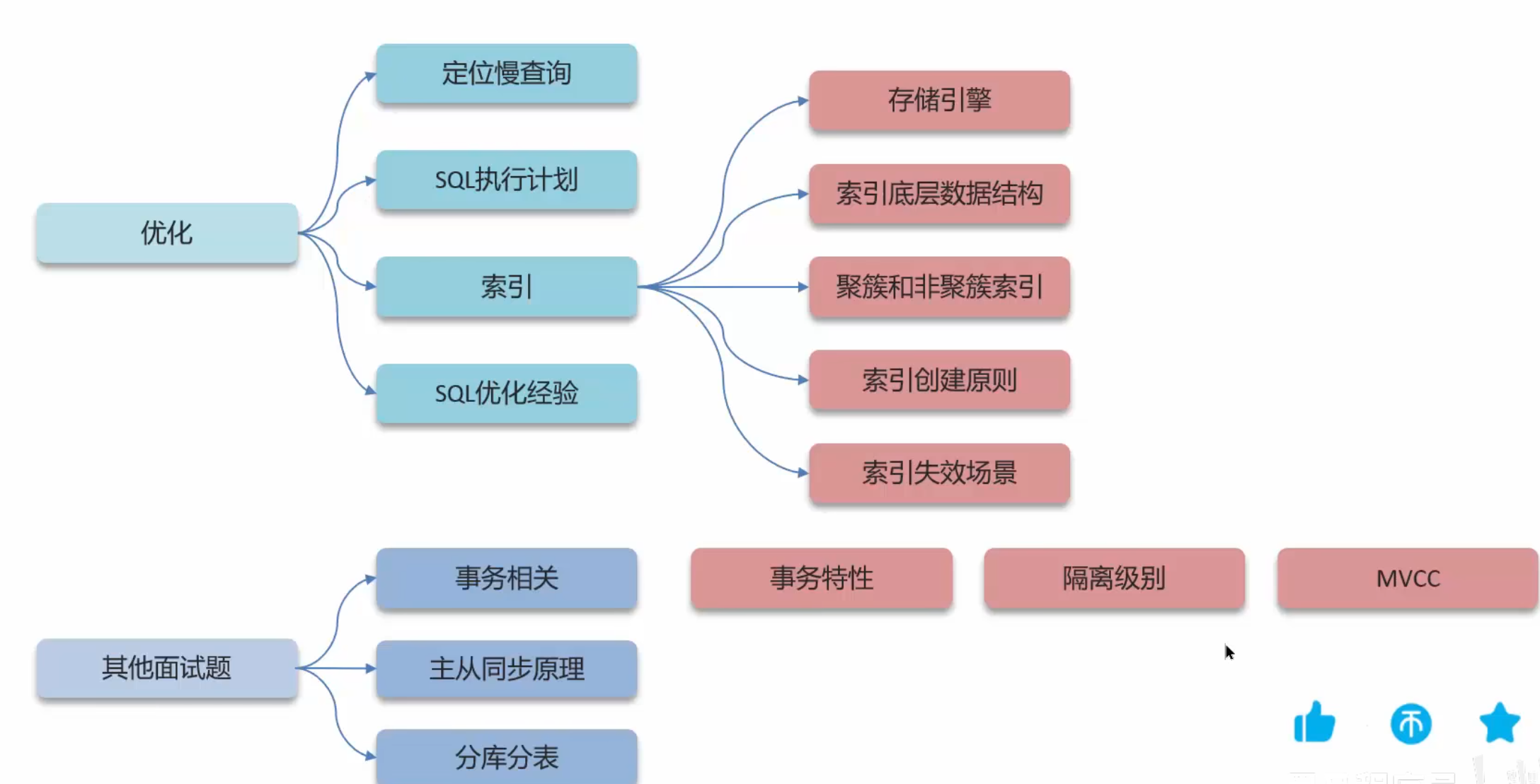
mysql优化
如何定位慢查询
-
慢查询的原因:聚合查询,多表查询,表数据量过大查询,深度分页查询。表现为页面加载慢,接口响应慢
-
定位方法:1,使用运维工具skywalking2,mysql自带的慢日志(mysql默认不开启,手动开启注意调试的时候才开,比较消耗性能)
- 解决慢查询:1,在查询语句前加explain2,
MySQL索引
索引的概念
索引的底层数据结构是B+树
-
在创建索引时就要排序,根据where条件决定走哪个索引
-
B+树叶子节点才存数据,叶子节点之间有双向指针,便于扫库、范围查询
聚簇索引,二级索引(非聚集索引),回表
-
聚集索引:数据索引放一块。叶子节点保存整行数据。必须有只能有一个
- 聚簇索引
-
二级索引:数据索引分开放。叶子节点保存的主键。可有多个
-
回表查询:先通过二级索引找到主键,再到聚集索引里找到整行的数据,使用了两次索引查询
-
覆盖索引:查询用了索引,在一个索引里就能找到想要的所有数据,就使用了一次索引
-
MySQL超大分页处理:覆盖索引+子查询
索引创建原则
-
答题方式
-
在实际工作中是怎么用的
-
主键索引
-
唯一索引
-
根据业务创建的索引(复合索引)
-
-
重点
-
数据量大,查询还频繁
-
针对于where,order by,group by操作字段创立索引
-
尽量使用联合索引
-
控制索引数量
-
索引失效
自己想一想自己遇到的情况,不要上来就背,适当思考,回想,更真实。可以使用explain判断是否失效
-
违反最左前缀原则(用到的是复合索引联合)
-
范围查询右边的列,不能使用索引
-
在索引上运算会失效
-
字符串不加单引号会造成失效,类型转换会导致
-
%开头的like模糊查询,可能失效
MySQL优化经验
表的设计优化,参考阿里开发手册《山高山版》
join优化,以小表为基础,小表放在外面循环
MySQL事务相关
-
事务特性
-
事务是一组操作的集合,一个不可分割的工作单位。同时成功,要么同时失败
-
ACID:
-
原子性:要么都成功要么都失败
-
一致性:数据保持一致
-
隔离性:不受其他并发操作影响
-
持久性:事务提交或回滚对数据库中数据的改变是永久的
-
-
并发事务会带来问题:脏读(读到另一个事务还没提交的数据),不可重复读(一个事务连读两次,数据不一样),幻读(查询没有,插入又说有。因为解决了前面的不可重复读,)
-
解决方法:隔离。
-
隔离级别有。默认使用可重复读。串行化最安全但效率太低了
-
undo log:记录数据被修改前的信息,一致性,原子性,作用包括:回滚(插入),mvcc(更新,删除)
-
redo log:记录事务提交时数据页的物理修改,实现事务持久性,服务器宕机,用来恢复数据
-
缓冲池(buffer pool):当一个缓存来,先操作内存中的缓冲池,
-
数据页:放在磁盘中
-
隔离性由:锁,mvcc保证
-
-
mvcc多版本并发控制:维护一个数据的多个版本,使得读写操作没有冲突
-
多个事务并发,到底访问哪个版本。
-
mvcc实现依赖于:隐式字段,undo log日志,readview
- 实现原理:
-
undolog版本链:修改记录的链子
-
readview快照读
-
当前读:最新记录,会加锁
-
快照读:没加锁,
-
分库分表