目录:
- 一、项目简介和项目结构
- 二、代码分析
- 三、扩展多轮对话且支持上下文
-
- 1、方案1:客户端维护简易对话历史(适合临时测试)
- 2、方案2:后端实现会话管理(适合生产环境)
-
- 1、添加会话ID参数:
- 2、后端存储历史对话
- 3、使用redis/数据库进行后端存储历史对话
-
- 3.1、安装依赖
- [3.2、Redis 存储实现](#3.2、Redis 存储实现)
- 3.3、数据库方案(以PostgreSQL为例)
- [四、Human Feedback人类反馈](#四、Human Feedback人类反馈)
一、项目简介和项目结构
本项目实现一个营销战略协作智能体;实现如何让任务以格式化数据输出,如自定义JSON数据格式并最终以JSON格式输出。
二、代码分析
1、main.py
python
# 导入依赖包
import os
import sys
import re
import uuid
import time
import json
import asyncio
from contextlib import asynccontextmanager
from pydantic import BaseModel, Field # Pydantic 模型(数据验证类)需继承BaseModel并显式定义字段
from typing import List, Optional, Dict
from fastapi import FastAPI, HTTPException, Request
from fastapi.responses import JSONResponse, StreamingResponse
import uvicorn
from langchain_openai import ChatOpenAI
from crew import CrewtestprojectCrew
# 模型全局参数配置 根据自己的实际情况进行调整
# openai模型相关配置 根据自己的实际情况进行调整
OPENAI_API_BASE = "https://api.wlai.vip/v1"
OPENAI_CHAT_API_KEY = "sk-EVzO0zDYzkXOLN5p60A435FbAb3b457496C329A1915f5859"
# OPENAI_CHAT_MODEL = "gpt-4o"
OPENAI_CHAT_MODEL = "gpt-4o-mini"
# 非gpt大模型相关配置(oneapi方案 通义千问为例) 根据自己的实际情况进行调整
ONEAPI_API_BASE = "http://139.224.72.218:3000/v1"
ONEAPI_CHAT_API_KEY = "sk-0FxX9ncd0yXjTQF877Cc9dB6B2F44aD08d62805715821b85"
ONEAPI_CHAT_MODEL = "qwen-max"
# 本地大模型相关配置(Ollama方案 llama3.1:latest为例) 根据自己的实际情况进行调整
OLLAMA_API_BASE = "http://192.168.2.9:11434/v1"
OLLAMA_CHAT_API_KEY = ""
OLLAMA_CHAT_MODEL = "llama3.1:latest"
# 谷歌搜索引擎
SERPER_API_KEY = "9d2aa95f5a0831110a3ec837996ff37b906e99dd"
# 初始化LLM模型
model = None
# API服务设置相关 根据自己的实际情况进行调整
PORT = 8012 # 服务访问的端口
# openai:调用gpt大模型;oneapi:调用非gpt大模型;ollama:调用本地大模型
MODEL_TYPE = "openai"
# 定义Message类
class RequestMessage(BaseModel):
role: str
customer_domain: str
project_description: str
class ResponseMessage(BaseModel):
role: str
content: str
# 定义ChatCompletionRequest类
class ChatCompletionRequest(BaseModel):
messages: List[RequestMessage]
stream: Optional[bool] = False #流式传输控制
# 定义ChatCompletionResponseChoice类
class ChatCompletionResponseChoice(BaseModel):
index: int
message: ResponseMessage
finish_reason: Optional[str] = None
# 定义ChatCompletionResponse类
class ChatCompletionResponse(BaseModel):
id: str = Field(default_factory=lambda: f"chatcmpl-{uuid.uuid4().hex}")
object: str = "chat.completion"
created: int = Field(default_factory=lambda: int(time.time()))
choices: List[ChatCompletionResponseChoice]
system_fingerprint: Optional[str] = None
# 定义了一个异步函数lifespan,它接收一个FastAPI应用实例app作为参数。这个函数将管理应用的生命周期,包括启动和关闭时的操作
# 函数在应用启动时执行一些初始化操作
# 函数在应用关闭时执行一些清理操作
# @asynccontextmanager 装饰器用于创建一个异步上下文管理器,它允许在yield之前和之后执行特定的代码块,分别表示启动和关闭时的操作
@asynccontextmanager
async def lifespan(app: FastAPI):
# 启动时执行
# 申明引用全局变量,在函数中被初始化,并在整个应用中使用
global MODEL_TYPE, model
global ONEAPI_API_BASE, ONEAPI_CHAT_API_KEY, ONEAPI_CHAT_MODEL
global OPENAI_API_BASE, OPENAI_CHAT_API_KEY, OPENAI_CHAT_MODEL
global OLLAMA_API_BASE, OLLAMA_CHAT_API_KEY, OLLAMA_CHAT_MODEL
global SERPER_API_KEY
# 根据自己实际情况选择调用model和embedding模型类型
try:
print("正在初始化模型")
# 设置google搜索引擎
os.environ["SERPER_API_KEY"] = SERPER_API_KEY
# 根据MODEL_TYPE选择初始化对应的模型,默认使用gpt大模型
if MODEL_TYPE == "oneapi":
# 实例化一个oneapi客户端对象
model = ChatOpenAI(
base_url=ONEAPI_API_BASE,
api_key=ONEAPI_CHAT_API_KEY,
model=ONEAPI_CHAT_MODEL, # 本次使用的模型
temperature=0.7,# 发散的程度
# timeout=None,# 服务请求超时
# max_retries=2,# 失败重试最大次数
)
elif MODEL_TYPE == "ollama":
# 实例化一个ChatOpenAI客户端对象
os.environ["OPENAI_API_KEY"] = "NA"
model = ChatOpenAI(
base_url=OLLAMA_API_BASE,# 请求的API服务地址
api_key=OLLAMA_CHAT_API_KEY,# API Key
model=OLLAMA_CHAT_MODEL,# 本次使用的模型
temperature=0.7,# 发散的程度
# timeout=None,# 服务请求超时
# max_retries=2,# 失败重试最大次数
)
else:
# 实例化一个ChatOpenAI客户端对象
model = ChatOpenAI(
base_url=OPENAI_API_BASE,# 请求的API服务地址
api_key=OPENAI_CHAT_API_KEY,# API Key
model=OPENAI_CHAT_MODEL,# 本次使用的模型
# temperature=0.7,# 发散的程度,一般为0
# timeout=None,# 服务请求超时
# max_retries=2,# 失败重试最大次数
)
print("LLM初始化完成")
except Exception as e:
print(f"初始化过程中出错: {str(e)}")
# raise 关键字重新抛出异常,以确保程序不会在错误状态下继续运行
raise
# yield 关键字将控制权交还给FastAPI框架,使应用开始运行
# 分隔了启动和关闭的逻辑。在yield 之前的代码在应用启动时运行,yield 之后的代码在应用关闭时运行
yield
# 关闭时执行
print("正在关闭...")
# lifespan 参数用于在应用程序生命周期的开始和结束时执行一些初始化或清理工作
app = FastAPI(lifespan=lifespan)
# POST请求接口,与大模型进行知识问答
@app.post("/v1/chat/completions")
async def chat_completions(request: ChatCompletionRequest):
if not model:
print("服务未初始化")
raise HTTPException(status_code=500, detail="服务未初始化")
try:
# print(f"收到聊天完成请求: {request}")
print(f"已经进入到请求中")
customer_domain = request.messages[-1].customer_domain
project_description = request.messages[-1].project_description
print(f"接收到的信息customer_domain: {customer_domain},接收到的信息project_description: {project_description}")
# 执行crew
inputs = {
"customer_domain": customer_domain,
"project_description": project_description
}
# 传入model,指定crew中的Agent使用什么大模型
result = CrewtestprojectCrew(model).crew().kickoff(inputs=inputs)
# 将返回的数据转成string类型
formatted_response = str(result)
print(f"LLM最终回复结果: {formatted_response}")
# 处理流式响应
if request.stream:
# 定义一个异步生成器函数,用于生成流式数据
async def generate_stream():
# 为每个流式数据片段生成一个唯一的chunk_id
chunk_id = f"chatcmpl-{uuid.uuid4().hex}"
# 将格式化后的响应按行分割
lines = formatted_response.split('\n')
# 历每一行,并构建响应片段
for i, line in enumerate(lines):
# 创建一个字典,表示流式数据的一个片段
chunk = {
"id": chunk_id,
"object": "chat.completion.chunk",
"created": int(time.time()),
# "model": request.model,
"choices": [
{
"index": 0,
"delta": {"content": line + '\n'}, # if i > 0 else {"role": "assistant", "content": ""},
"finish_reason": None
}
]
}
# 将片段转换为JSON格式并生成
yield f"{json.dumps(chunk)}\n"
# 每次生成数据后,异步等待0.5秒
await asyncio.sleep(0.5)
# 生成最后一个片段,表示流式响应的结束
final_chunk = {
"id": chunk_id,
"object": "chat.completion.chunk",
"created": int(time.time()),
"choices": [
{
"index": 0,
"delta": {},
"finish_reason": "stop"
}
]
}
yield f"{json.dumps(final_chunk)}\n"
# 返回fastapi.responses中StreamingResponse对象,流式传输数据
# media_type设置为text/event-stream以符合SSE(Server-SentEvents) 格式
return StreamingResponse(generate_stream(), media_type="text/event-stream")
# 处理非流式响应处理
else:
response = ChatCompletionResponse(
choices=[
ChatCompletionResponseChoice(
index=0,
message=ResponseMessage(role="assistant", content=formatted_response),
finish_reason="stop"
)
]
)
# print(f"发送响应内容: \n{response}")
# 返回fastapi.responses中JSONResponse对象
# model_dump()方法通常用于将Pydantic模型实例的内容转换为一个标准的Python字典,以便进行序列化
return JSONResponse(content=response.model_dump())
except Exception as e:
print(f"处理聊天完成时出错:\n\n {str(e)}")
raise HTTPException(status_code=500, detail=str(e))
if __name__ == "__main__":
print(f"在端口 {PORT} 上启动服务器")
# uvicorn是一个用于运行ASGI应用的轻量级、超快速的ASGI服务器实现
# 用于部署基于FastAPI框架的异步PythonWeb应用程序
uvicorn.run(app, host="0.0.0.0", port=PORT)2、crew.py
python
# 核心功能:在CrewAI中定义Agent和Task,并通过Crew来管理这些Agent和Task的执行流程
# 导入相关的依赖包
from typing import List
from crewai import Agent, Crew, Process, Task
# CrewBase是一个装饰器,标记一个类为CrewAI项目。agent、task和crew装饰器用于定义agent、task和crew
from crewai.project import CrewBase, agent, crew, task
# 使用CrewAI官方提供的工具
# https://github.com/crewAIInc/crewAI-tools/tree/main/crewai_tools/tools
from crewai_tools import SerperDevTool, ScrapeWebsiteTool
from pydantic import BaseModel, Field
class MarketStrategy(BaseModel):
"""Market strategy model"""
name: str = Field(..., description="市场战略名称")
tatics: List[str] = Field(..., description="市场战略中使用的战术清单")
channels: List[str] = Field(..., description="市场战略中使用的渠道清单")
KPIs: List[str] = Field(..., description="市场战略中使用的关键绩效指标清单")
class CampaignIdea(BaseModel):
"""Campaign idea model"""
name: str = Field(..., description="活动创意名称")
description: str = Field(..., description="Description of the campaign idea")
audience: str = Field(..., description="活动创意说明")
channel: str = Field(..., description="活动创意渠道")
#定义的json结构
class Copy(BaseModel):
"""Copy model"""
title: str = Field(..., description="副本标题")
body: str = Field(..., description="正文")
# 定义了一个CrewtestprojectCrew类并应用了@CrewBase装饰器初始化项目
# 这个类代表一个完整的CrewAI项目
@CrewBase
class CrewtestprojectCrew():
# agents_config和tasks_config分别指向agent和task的配置文件,存放在config目录下
agents_config = 'config/agents.yaml'
tasks_config = 'config/tasks.yaml'
def __init__(self, model):
# Agent使用的大模型
self.model = model
# 通过@agent装饰器定义一个函数researcher,返回一个Agent实例
# 该代理读取agents_config中的researcher配置
# 参数verbose=True用于输出调试信息
# 参数tools=[MyCustomTool()] 可以加载自定义工具
@agent
def lead_market_analyst(self) -> Agent:
return Agent(
config=self.agents_config['lead_market_analyst'],
verbose=True,
llm=self.model,
tools=[SerperDevTool(), ScrapeWebsiteTool()],
)
@agent
def chief_marketing_strategist(self) -> Agent:
return Agent(
config=self.agents_config['chief_marketing_strategist'],
verbose=True,
llm=self.model,
tools=[SerperDevTool(), ScrapeWebsiteTool()],
)
@agent
def creative_content_creator(self) -> Agent:
return Agent(
config=self.agents_config['creative_content_creator'],
verbose=True,
llm=self.model
)
# 通过@task装饰器定义research_task,返回一个Task实例
# 配置文件为tasks.yaml中的research_task部分
@task
def research_task(self) -> Task:
return Task(
config=self.tasks_config['research_task'],
)
@task
def project_understanding_task(self) -> Task:
return Task(
config=self.tasks_config['project_understanding_task'],
)
@task
def marketing_strategy_task(self) -> Task:
return Task(
config=self.tasks_config['marketing_strategy_task'],
output_json=MarketStrategy
)
@task
def campaign_idea_task(self) -> Task:
return Task(
config=self.tasks_config['campaign_idea_task'],
output_json=CampaignIdea
)
@task
def copy_creation_task(self) -> Task:
return Task(
config=self.tasks_config['copy_creation_task'],
context=[self.marketing_strategy_task(), self.campaign_idea_task()],
output_json=Copy #最后一个任务输出参数已copy定义的格式返回
)
# Crew类将agent和task组合成一个执行队列,并根据指定的执行流程进行任务调度
# 通过@crew装饰器定义crew,创建一个Crew实例
# agents=self.agents和tasks=self.tasks分别自动获取@agent和@task装饰器生成的agent和task
# process=Process.sequential指定agent执行顺序为顺序执行模式
# process=Process.hierarchical指定agent执行顺序为层次化执行
@crew
def crew(self) -> Crew:
return Crew(
agents=self.agents,
tasks=self.tasks,
process=Process.sequential,
verbose=True
)三、扩展多轮对话且支持上下文
1、方案1:客户端维护简易对话历史(适合临时测试)
python
# 初始化对话历史列表(放在循环外)
chat_history = []
# 用户输入(可改为循环获取输入)
user_input = {"role": "user", "content": "第一次提问..."}
chat_history.append(user_input) # 添加到历史
# 发送请求时传入完整历史
data = {
"messages": chat_history, # 包含所有历史消息
"stream": stream_flag,
}
# 接收响应后,将助手回复添加到历史
assistant_response = response.json()['choices'][0]['message']
chat_history.append(assistant_response) # 保存助手回复2、方案2:后端实现会话管理(适合生产环境)
1、添加会话ID参数:
python
# 客户端请求新增 session_id(如UUID)
data = {
"session_id": "user123", # 用户唯一标识
"messages": [{"role": "user", "content": "当前问题"}],
"stream": stream_flag,
}2、后端存储历史对话
python
# 使用字典临时存储对话历史(生产环境建议用Redis/数据库)
session_store = {} # key: session_id, value: chat_history
@app.post("/v1/chat/completions")
async def chat_completions(request: ChatCompletionRequest):
session_id = request.session_id # 获取会话ID
# 从存储中加载历史对话(若无则初始化)
chat_history = session_store.get(session_id, [])
# 添加新的用户消息到历史
chat_history.append(request.messages[-1])
# 调用大模型时传入完整历史
result = CrewtestprojectCrew(model).crew().kickoff(inputs={"history": chat_history})
# 保存本轮助手回复到历史
assistant_msg = {"role": "assistant", "content": result}
chat_history.append(assistant_msg)
session_store[session_id] = chat_history # 更新存储
# 返回结果...3、使用redis/数据库进行后端存储历史对话
3.1、安装依赖
python
pip install redis3.2、Redis 存储实现
python
import redis
from typing import List, Dict
import json
# 连接Redis(生产环境建议用连接池)
redis_client = redis.Redis(
host='localhost',
port=6379,
db=0, # 选择数据库编号
decode_responses=True # 自动解码为字符串
)
def save_history(session_id: str, messages: List[Dict]):
"""存储对话历史(JSON序列化)"""
redis_client.set(
f"chat:{session_id}",
json.dumps(messages),
ex=86400 # 设置TTL(1天后自动过期)
)
def load_history(session_id: str) -> List[Dict]:
"""读取对话历史"""
data = redis_client.get(f"chat:{session_id}")
return json.loads(data) if data else []
# 使用示例
session_id = "user_123"
history = [
{"role": "user", "content": "EMQX是什么?"},
{"role": "assistant", "content": "EMQX是开源的MQTT消息中间件..."}
]
save_history(session_id, history)
loaded = load_history(session_id) # 获取完整历史3.3、数据库方案(以PostgreSQL为例)
python
# pip install psycopg2-binary
import psycopg2
from contextlib import contextmanager
# 数据库连接配置
DB_CONFIG = {
"host": "localhost",
"database": "chat_db",
"user": "postgres",
"password": "password"
}
@contextmanager
def db_connection():
conn = psycopg2.connect(**DB_CONFIG)
try:
yield conn
finally:
conn.close()
def init_db():
"""初始化表结构"""
with db_connection() as conn:
with conn.cursor() as cur:
cur.execute("""
CREATE TABLE IF NOT EXISTS chat_history (
session_id TEXT PRIMARY KEY,
messages JSONB NOT NULL,
updated_at TIMESTAMP DEFAULT NOW()
)
""")
def upsert_history(session_id: str, messages: List[Dict]):
"""插入/更新对话历史"""
with db_connection() as conn:
with conn.cursor() as cur:
cur.execute("""
INSERT INTO chat_history (session_id, messages)
VALUES (%s, %s)
ON CONFLICT (session_id)
DO UPDATE SET messages = EXCLUDED.messages
""", (session_id, json.dumps(messages)))
conn.commit()
# 使用方式与Redis类似四、Human Feedback人类反馈
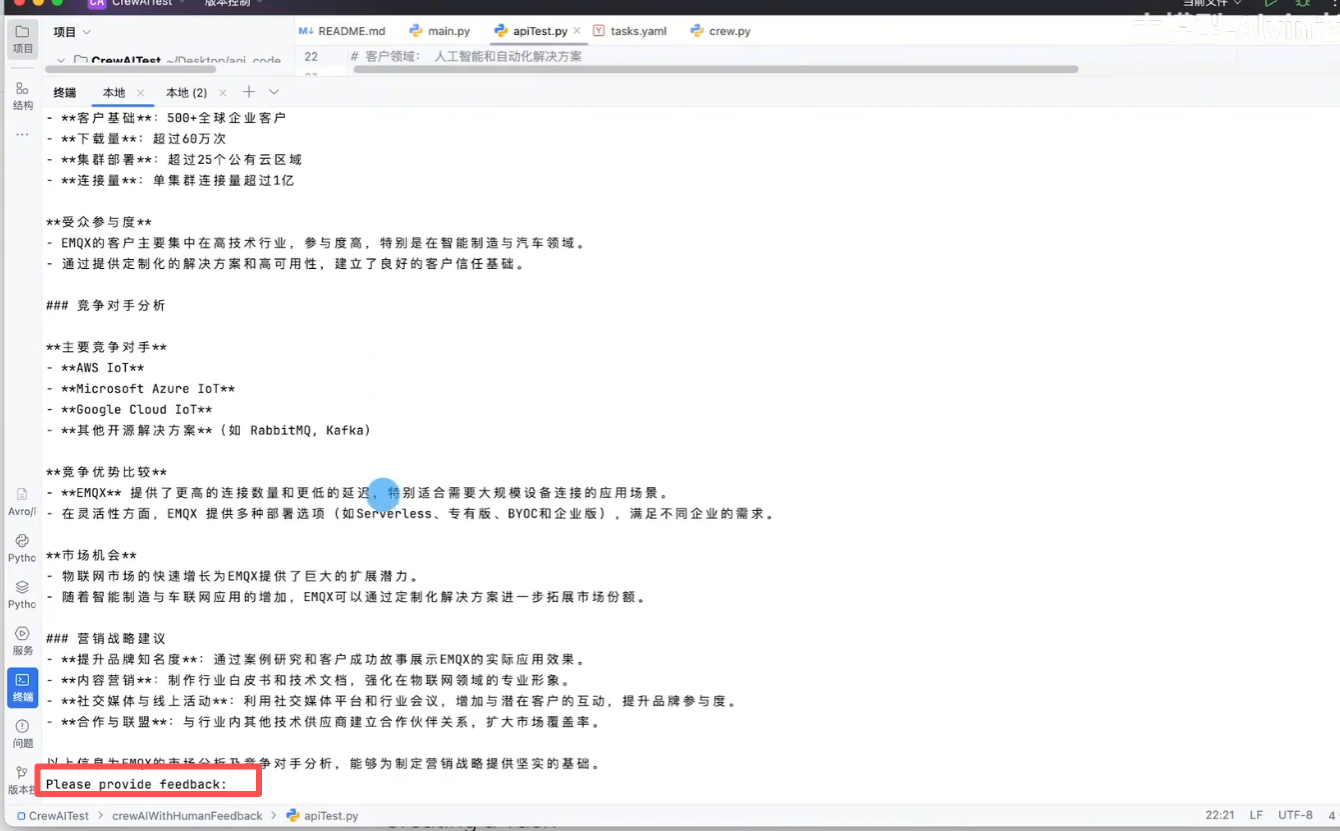
- Human Feedback(人类反馈)是指人类在评估和改进人工智能模型行为过程中提供的反馈信息
- 它通常被用于帮助训练、优化和监督机器学习模型,特别是大规模语言模型
- 通过人类反馈,AI 模型能够更好地理解人类意图、提供更符合预期的响应,并减少生成错误或有害内容的几率
python
# 核心功能:在CrewAI中定义Agent和Task,并通过Crew来管理这些Agent和Task的执行流程
# 导入相关的依赖包
from typing import List
from crewai import Agent, Crew, Process, Task
# CrewBase是一个装饰器,标记一个类为CrewAI项目。agent、task和crew装饰器用于定义agent、task和crew
from crewai.project import CrewBase, agent, crew, task
# 使用CrewAI官方提供的工具
# https://github.com/crewAIInc/crewAI-tools/tree/main/crewai_tools/tools
from crewai_tools import SerperDevTool, ScrapeWebsiteTool
from pydantic import BaseModel, Field
class MarketStrategy(BaseModel):
"""Market strategy model"""
name: str = Field(..., description="市场战略名称")
tatics: List[str] = Field(..., description="市场战略中使用的战术清单")
channels: List[str] = Field(..., description="市场战略中使用的渠道清单")
KPIs: List[str] = Field(..., description="市场战略中使用的关键绩效指标清单")
class CampaignIdea(BaseModel):
"""Campaign idea model"""
name: str = Field(..., description="活动创意名称")
description: str = Field(..., description="Description of the campaign idea")
audience: str = Field(..., description="活动创意说明")
channel: str = Field(..., description="活动创意渠道")
class Copy(BaseModel):
"""Copy model"""
title: str = Field(..., description="副本标题")
body: str = Field(..., description="正文")
# 定义了一个CrewtestprojectCrew类并应用了@CrewBase装饰器初始化项目
# 这个类代表一个完整的CrewAI项目
@CrewBase
class CrewtestprojectCrew():
# agents_config和tasks_config分别指向agent和task的配置文件,存放在config目录下
agents_config = 'config/agents.yaml'
tasks_config = 'config/tasks.yaml'
def __init__(self, model):
# Agent使用的大模型
self.model = model
# 通过@agent装饰器定义一个函数researcher,返回一个Agent实例
# 该代理读取agents_config中的researcher配置
# 参数verbose=True用于输出调试信息
# 参数tools=[MyCustomTool()] 可以加载自定义工具
@agent
def lead_market_analyst(self) -> Agent:
return Agent(
config=self.agents_config['lead_market_analyst'],
verbose=True,
llm=self.model,
tools=[SerperDevTool(), ScrapeWebsiteTool()],
)
@agent
def chief_marketing_strategist(self) -> Agent:
return Agent(
config=self.agents_config['chief_marketing_strategist'],
verbose=True,
llm=self.model,
tools=[SerperDevTool(), ScrapeWebsiteTool()],
)
@agent
def creative_content_creator(self) -> Agent:
return Agent(
config=self.agents_config['creative_content_creator'],
verbose=True,
llm=self.model
)
# 通过@task装饰器定义research_task,返回一个Task实例
# 配置文件为tasks.yaml中的research_task部分
@task
def research_task(self) -> Task:
return Task(
config=self.tasks_config['research_task'],
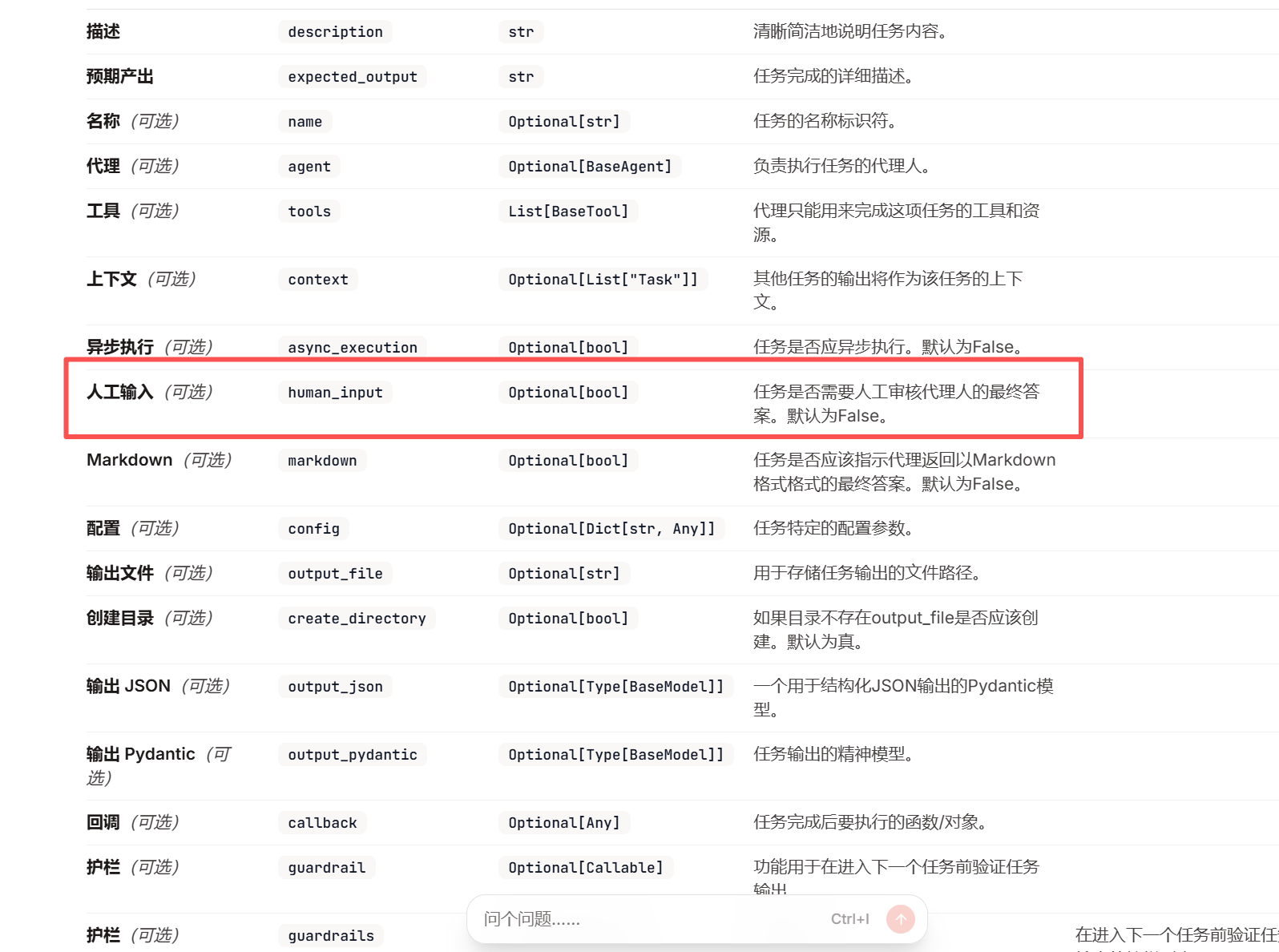
human_input=True #开启人工反馈
)
@task
def project_understanding_task(self) -> Task:
return Task(
config=self.tasks_config['project_understanding_task'],
human_input=True #开启人工反馈
)
@task
def marketing_strategy_task(self) -> Task:
return Task(
config=self.tasks_config['marketing_strategy_task'],
output_json=MarketStrategy,
human_input=True #开启人工反馈
)
@task
def campaign_idea_task(self) -> Task:
return Task(
config=self.tasks_config['campaign_idea_task'],
output_json=CampaignIdea,
human_input=True #开启人工反馈
)
@task
def copy_creation_task(self) -> Task:
return Task(
config=self.tasks_config['copy_creation_task'],
context=[self.marketing_strategy_task(), self.campaign_idea_task()],
output_json=Copy,
human_input=True #开启人工反馈
)
# Crew类将agent和task组合成一个执行队列,并根据指定的执行流程进行任务调度
# 通过@crew装饰器定义crew,创建一个Crew实例
# agents=self.agents和tasks=self.tasks分别自动获取@agent和@task装饰器生成的agent和task
# process=Process.sequential指定agent执行顺序为顺序执行模式
# process=Process.hierarchical指定agent执行顺序为层次化执行
@crew
def crew(self) -> Crew:
return Crew(
agents=self.agents,
tasks=self.tasks,
process=Process.sequential,
verbose=True
)当代码运行到某个任务时,有响应结果后,会将结果信息反馈给人类进行审核,从而是得到的答案更加精确。
项目代码地址:
https://github.com/NanGePlus/CrewAITest/tree/main/crewAIWithMarketingStrategy
crewai官网地址:
Pydantic模型类的使用文档: