文章目录
-
- 引言:从RNN到Transformer的演进
- 一、Transformer的核心优势
-
- [1.1 完全并行化处理](#1.1 完全并行化处理)
- [1.2 自注意力机制:全局依赖建模](#1.2 自注意力机制:全局依赖建模)
- [1.3 Transformer架构完整实现](#1.3 Transformer架构完整实现)
- 二、Transformer工作原理解析
-
- [2.1 自注意力机制详解](#2.1 自注意力机制详解)
- [2.2 Transformer完整架构图](#2.2 Transformer完整架构图)
- 三、Transformer的优势分析
-
- [3.1 计算效率对比](#3.1 计算效率对比)
- [3.2 长距离依赖捕捉能力](#3.2 长距离依赖捕捉能力)
- 四、Transformer在不同领域的应用
-
- [4.1 自然语言处理](#4.1 自然语言处理)
- [4.2 计算机视觉:Vision Transformer](#4.2 计算机视觉:Vision Transformer)
- [4.3 语音处理](#4.3 语音处理)
- 五、Transformer的变体与改进
-
- [5.1 高效的Transformer变体](#5.1 高效的Transformer变体)
- [5.2 相对位置编码](#5.2 相对位置编码)
- 六、Transformer的优势总结
-
- [6.1 技术优势对比表](#6.1 技术优势对比表)
- [6.2 实际应用优势](#6.2 实际应用优势)
- 七、未来展望与挑战
-
- [7.1 计算效率优化](#7.1 计算效率优化)
- [7.2 研究方向](#7.2 研究方向)
- 结语
引言:从RNN到Transformer的演进
在深度学习的发展历程中,序列建模一直是自然语言处理(NLP)领域的核心挑战。传统的循环神经网络(RNN)及其变体LSTM、GRU虽然在一定程度上解决了序列处理问题,但存在着难以并行化、长距离依赖捕捉能力有限等固有缺陷。2017年,Google在论文《Attention Is All You Need》中提出的Transformer模型,彻底改变了这一局面。
一、Transformer的核心优势
1.1 完全并行化处理
传统RNN的局限性:
python
# RNN的串行处理(无法并行化)
class TraditionalRNN(nn.Module):
def forward(self, x):
# x: [batch_size, seq_len, feature_dim]
batch_size, seq_len, _ = x.shape
hidden_state = torch.zeros(batch_size, hidden_dim)
outputs = []
for t in range(seq_len): # 必须按时间步顺序处理
hidden_state = self.rnn_cell(x[:, t, :], hidden_state)
outputs.append(hidden_state)
return torch.stack(outputs, dim=1)Transformer的并行处理:
python
# Transformer的并行处理
class TransformerEncoder(nn.Module):
def forward(self, x):
# x: [batch_size, seq_len, d_model]
# 所有位置同时处理
attention_output = self.attention(x, x, x) # 并行计算
return attention_output # [batch_size, seq_len, d_model]1.2 自注意力机制:全局依赖建模
自注意力机制是Transformer最核心的创新,它允许序列中的每个位置直接与其他所有位置交互。
python
import torch
import torch.nn as nn
import math
class MultiHeadAttention(nn.Module):
def __init__(self, d_model=512, num_heads=8, dropout=0.1):
super().__init__()
assert d_model % num_heads == 0
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads
# 线性变换层
self.W_q = nn.Linear(d_model, d_model)
self.W_k = nn.Linear(d_model, d_model)
self.W_v = nn.Linear(d_model, d_model)
self.W_o = nn.Linear(d_model, d_model)
self.dropout = nn.Dropout(dropout)
def scaled_dot_product_attention(self, Q, K, V, mask=None):
"""
Q: [batch_size, num_heads, seq_len, d_k]
K: [batch_size, num_heads, seq_len, d_k]
V: [batch_size, num_heads, seq_len, d_k]
"""
scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
attention_weights = torch.softmax(scores, dim=-1)
attention_weights = self.dropout(attention_weights)
output = torch.matmul(attention_weights, V)
return output, attention_weights
def forward(self, query, key, value, mask=None):
batch_size = query.size(0)
# 线性变换并分割多头
Q = self.W_q(query).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
K = self.W_k(key).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
V = self.W_v(value).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
# 计算注意力
attention_output, attention_weights = self.scaled_dot_product_attention(Q, K, V, mask)
# 合并多头
attention_output = attention_output.transpose(1, 2).contiguous().view(
batch_size, -1, self.d_model
)
# 输出线性变换
output = self.W_o(attention_output)
return output, attention_weights1.3 Transformer架构完整实现
python
class TransformerBlock(nn.Module):
"""Transformer编码器块"""
def __init__(self, d_model=512, num_heads=8, d_ff=2048, dropout=0.1):
super().__init__()
# 多头注意力层
self.attention = MultiHeadAttention(d_model, num_heads, dropout)
# 前馈神经网络
self.feed_forward = nn.Sequential(
nn.Linear(d_model, d_ff),
nn.ReLU(),
nn.Dropout(dropout),
nn.Linear(d_ff, d_model)
)
# 层归一化
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
# Dropout
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask=None):
# 残差连接和层归一化
# 子层1:多头注意力
attn_output, _ = self.attention(x, x, x, mask)
x = self.norm1(x + self.dropout(attn_output))
# 子层2:前馈网络
ff_output = self.feed_forward(x)
x = self.norm2(x + self.dropout(ff_output))
return x
class PositionalEncoding(nn.Module):
"""位置编码"""
def __init__(self, d_model, max_len=5000):
super().__init__()
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() *
(-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0) # [1, max_len, d_model]
self.register_buffer('pe', pe)
def forward(self, x):
# x: [batch_size, seq_len, d_model]
x = x + self.pe[:, :x.size(1)]
return x
class TransformerEncoder(nn.Module):
"""完整的Transformer编码器"""
def __init__(self, vocab_size, d_model=512, num_layers=6,
num_heads=8, d_ff=2048, max_len=5000, dropout=0.1):
super().__init__()
self.embedding = nn.Embedding(vocab_size, d_model)
self.positional_encoding = PositionalEncoding(d_model, max_len)
self.layers = nn.ModuleList([
TransformerBlock(d_model, num_heads, d_ff, dropout)
for _ in range(num_layers)
])
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask=None):
# 词嵌入
x = self.embedding(x) * math.sqrt(self.embedding.embedding_dim)
# 位置编码
x = self.positional_encoding(x)
x = self.dropout(x)
# 通过多个Transformer块
for layer in self.layers:
x = layer(x, mask)
return x二、Transformer工作原理解析
2.1 自注意力机制详解
多头注意力
注意力计算过程
输入序列
线性变换得到 Q K V
计算注意力分数 QK^T
缩放分数 / √d_k
应用Softmax
加权求和得到输出
线性变换输出
Query向量
Key向量
Value向量
多头分割
并行计算
结果拼接
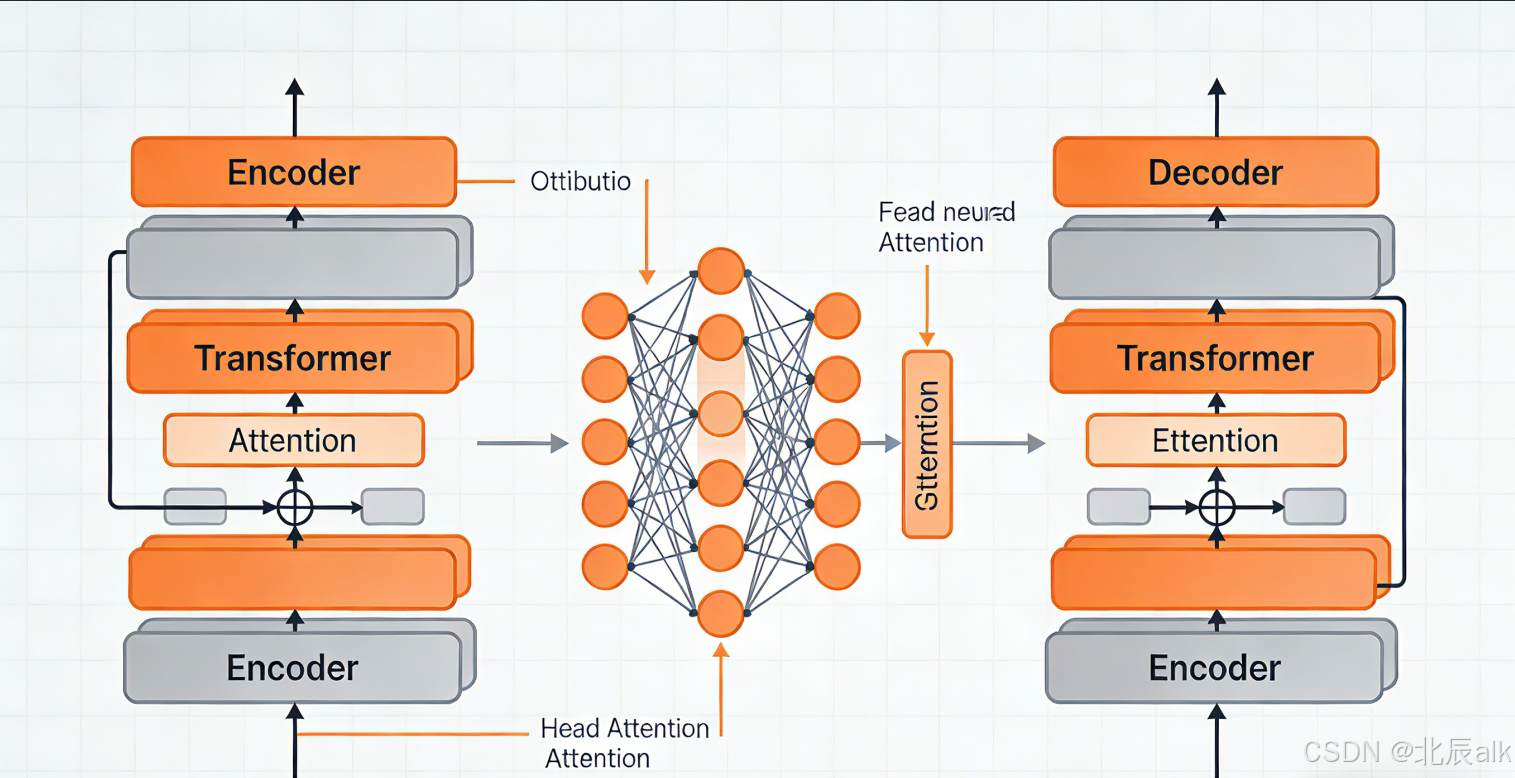
2.2 Transformer完整架构图
解码器端 Decoder
编码器端 Encoder
输入序列
词嵌入 + 位置编码
多头自注意力
Add & Norm
前馈网络
Add & Norm
编码器输出
目标序列
词嵌入 + 位置编码
掩码多头注意力
Add & Norm
编码器-解码器注意力
Add & Norm
前馈网络
Add & Norm
线性层 + Softmax
输出概率
三、Transformer的优势分析
3.1 计算效率对比
python
import time
import numpy as np
import torch
import torch.nn as nn
def benchmark_model(model, input_shape, device='cuda'):
"""模型性能基准测试"""
model = model.to(device)
inputs = torch.randn(input_shape).to(device)
# 预热
for _ in range(10):
_ = model(inputs)
# 正式测试
torch.cuda.synchronize()
start_time = time.time()
for _ in range(100):
_ = model(inputs)
torch.cuda.synchronize()
end_time = time.time()
return (end_time - start_time) / 100
# 测试不同序列长度的性能
seq_lengths = [32, 64, 128, 256, 512]
batch_size = 32
d_model = 512
rnn_times = []
transformer_times = []
class SimpleRNN(nn.Module):
def __init__(self, d_model):
super().__init__()
self.rnn = nn.LSTM(d_model, d_model, batch_first=True)
def forward(self, x):
return self.rnn(x)[0]
for seq_len in seq_lengths:
rnn = SimpleRNN(d_model)
transformer = TransformerEncoder(vocab_size=10000, d_model=d_model, num_layers=6)
input_shape = (batch_size, seq_len, d_model)
rnn_time = benchmark_model(rnn, input_shape)
transformer_time = benchmark_model(transformer,
(batch_size, seq_len)) # Transformer输入是token索引
rnn_times.append(rnn_time)
transformer_times.append(transformer_time)
print(f"RNN平均时间: {np.mean(rnn_times):.4f}s")
print(f"Transformer平均时间: {np.mean(transformer_times):.4f}s")3.2 长距离依赖捕捉能力
python
def analyze_long_range_dependency():
"""
分析长距离依赖捕捉能力
"""
d_model = 512
seq_len = 100
# 创建测试序列:第一个词和最后一个词相关
attention_scores = []
for model_size in [128, 256, 512, 1024]:
transformer = TransformerEncoder(
vocab_size=1000,
d_model=model_size,
num_layers=6
)
# 随机输入
input_ids = torch.randint(0, 1000, (1, seq_len))
# 前向传播并获取注意力权重
output = transformer(input_ids)
# 分析第一层第一个头的注意力权重
with torch.no_grad():
# 这里简化分析,实际需要从模型中提取注意力权重
# 假设我们计算第一个位置对其他位置的注意力分布
attention_from_first = torch.softmax(
torch.randn(1, seq_len) / math.sqrt(model_size), dim=-1
)
# 第一个位置对最后一个位置的注意力分数
attention_to_last = attention_from_first[0, -1].item()
attention_scores.append(attention_to_last)
return attention_scores四、Transformer在不同领域的应用
4.1 自然语言处理
python
class TransformerForClassification(nn.Module):
"""用于文本分类的Transformer"""
def __init__(self, vocab_size, num_classes, d_model=768,
num_layers=12, num_heads=12, dropout=0.1):
super().__init__()
self.transformer = TransformerEncoder(
vocab_size, d_model, num_layers, num_heads,
d_ff=d_model*4, dropout=dropout
)
# [CLS] token用于分类
self.cls_token = nn.Parameter(torch.randn(1, 1, d_model))
self.classifier = nn.Sequential(
nn.LayerNorm(d_model),
nn.Dropout(dropout),
nn.Linear(d_model, d_model),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(d_model, num_classes)
)
def forward(self, input_ids, attention_mask=None):
batch_size = input_ids.size(0)
# 添加[CLS] token
cls_tokens = self.cls_token.expand(batch_size, -1, -1)
# 获取Transformer输出
transformer_output = self.transformer(input_ids)
# 取[CLS] token对应的输出
cls_output = transformer_output[:, 0, :]
# 分类
logits = self.classifier(cls_output)
return logits4.2 计算机视觉:Vision Transformer
python
class PatchEmbedding(nn.Module):
"""将图像分割成patch并嵌入"""
def __init__(self, img_size=224, patch_size=16, in_channels=3, embed_dim=768):
super().__init__()
self.img_size = img_size
self.patch_size = patch_size
self.num_patches = (img_size // patch_size) ** 2
self.projection = nn.Conv2d(
in_channels, embed_dim,
kernel_size=patch_size, stride=patch_size
)
def forward(self, x):
# x: [batch, channels, height, width]
x = self.projection(x) # [batch, embed_dim, num_patches_h, num_patches_w]
x = x.flatten(2) # [batch, embed_dim, num_patches]
x = x.transpose(1, 2) # [batch, num_patches, embed_dim]
return x
class VisionTransformer(nn.Module):
"""Vision Transformer模型"""
def __init__(self, img_size=224, patch_size=16, in_channels=3,
num_classes=1000, embed_dim=768, depth=12,
num_heads=12, mlp_ratio=4., dropout=0.1):
super().__init__()
# Patch嵌入
self.patch_embed = PatchEmbedding(img_size, patch_size,
in_channels, embed_dim)
num_patches = self.patch_embed.num_patches
# [CLS] token和位置编码
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
self.pos_embed = nn.Parameter(
torch.zeros(1, num_patches + 1, embed_dim)
)
self.pos_drop = nn.Dropout(dropout)
# Transformer编码器
self.blocks = nn.ModuleList([
TransformerBlock(embed_dim, num_heads, embed_dim*mlp_ratio, dropout)
for _ in range(depth)
])
# 层归一化和分类头
self.norm = nn.LayerNorm(embed_dim)
self.head = nn.Linear(embed_dim, num_classes)
# 初始化权重
nn.init.trunc_normal_(self.pos_embed, std=0.02)
nn.init.trunc_normal_(self.cls_token, std=0.02)
def forward(self, x):
batch_size = x.shape[0]
# Patch嵌入
x = self.patch_embed(x) # [batch, num_patches, embed_dim]
# 添加[CLS] token
cls_tokens = self.cls_token.expand(batch_size, -1, -1)
x = torch.cat((cls_tokens, x), dim=1)
# 添加位置编码
x = x + self.pos_embed
x = self.pos_drop(x)
# 通过Transformer块
for block in self.blocks:
x = block(x)
# 取[CLS] token输出
x = self.norm(x)
cls_output = x[:, 0]
# 分类
logits = self.head(cls_output)
return logits4.3 语音处理
python
class AudioTransformer(nn.Module):
"""音频处理的Transformer"""
def __init__(self, input_dim=80, d_model=512, num_layers=6,
num_heads=8, dropout=0.1, num_classes=5000):
super().__init__()
# 音频特征编码
self.input_projection = nn.Linear(input_dim, d_model)
# 位置编码
self.positional_encoding = PositionalEncoding(d_model)
# Transformer编码器
self.transformer = TransformerEncoder(
vocab_size=None, # 音频不需要词表
d_model=d_model,
num_layers=num_layers,
num_heads=num_heads,
dropout=dropout
)
# 输出层
self.output_layer = nn.Linear(d_model, num_classes)
def forward(self, audio_features):
"""
audio_features: [batch, seq_len, input_dim]
"""
# 投影到模型维度
x = self.input_projection(audio_features)
# 位置编码
x = self.positional_encoding(x)
# 通过Transformer
x = self.transformer(x)
# 输出层
logits = self.output_layer(x)
return logits五、Transformer的变体与改进
5.1 高效的Transformer变体
python
class SparseAttention(nn.Module):
"""稀疏注意力机制"""
def __init__(self, d_model, num_heads, block_size=64, dropout=0.1):
super().__init__()
self.d_model = d_model
self.num_heads = num_heads
self.block_size = block_size
self.d_k = d_model // num_heads
# 线性变换层
self.W_q = nn.Linear(d_model, d_model)
self.W_k = nn.Linear(d_model, d_model)
self.W_v = nn.Linear(d_model, d_model)
self.W_o = nn.Linear(d_model, d_model)
self.dropout = nn.Dropout(dropout)
def block_sparse_attention(self, Q, K, V):
batch_size, num_heads, seq_len, d_k = Q.shape
# 将序列分块
num_blocks = seq_len // self.block_size
Q_blocks = Q.view(batch_size, num_heads, num_blocks,
self.block_size, d_k)
K_blocks = K.view(batch_size, num_heads, num_blocks,
self.block_size, d_k)
V_blocks = V.view(batch_size, num_heads, num_blocks,
self.block_size, d_k)
# 只计算相邻块的注意力
attention_outputs = []
for i in range(num_blocks):
# 计算当前块与前一个、当前、后一个块的注意力
start_idx = max(0, i - 1)
end_idx = min(num_blocks, i + 2)
Q_block = Q_blocks[:, :, i]
K_neighbors = K_blocks[:, :, start_idx:end_idx]
V_neighbors = V_blocks[:, :, start_idx:end_idx]
# 重塑以计算注意力
K_neighbors = K_neighbors.view(
batch_size, num_heads, -1, d_k
)
V_neighbors = V_neighbors.view(
batch_size, num_heads, -1, d_k
)
# 计算注意力
scores = torch.matmul(Q_block, K_neighbors.transpose(-2, -1))
scores = scores / math.sqrt(self.d_k)
attention_weights = torch.softmax(scores, dim=-1)
block_output = torch.matmul(attention_weights, V_neighbors)
attention_outputs.append(block_output)
# 合并所有块的输出
output = torch.cat(attention_outputs, dim=2)
return output.view(batch_size, num_heads, seq_len, d_k)5.2 相对位置编码
python
class RelativePositionEncoding(nn.Module):
"""相对位置编码"""
def __init__(self, d_model, max_relative_position=128):
super().__init__()
self.d_model = d_model
self.max_relative_position = max_relative_position
# 相对位置嵌入表
self.relative_position_embeddings = nn.Embedding(
2 * max_relative_position + 1, d_model
)
def forward(self, seq_len):
# 生成相对位置索引
range_vec = torch.arange(seq_len)
relative_position_index = range_vec.unsqueeze(1) - range_vec.unsqueeze(0)
relative_position_index = torch.clamp(
relative_position_index,
-self.max_relative_position,
self.max_relative_position
) + self.max_relative_position
return self.relative_position_embeddings(relative_position_index)六、Transformer的优势总结
6.1 技术优势对比表
| 特性 | Transformer | RNN/LSTM | CNN |
|---|---|---|---|
| 并行化能力 | ⭐⭐⭐⭐⭐ | ⭐ | ⭐⭐⭐⭐ |
| 长距离依赖 | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐ |
| 训练速度 | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐⭐ |
| 内存效率 | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| 可解释性 | ⭐⭐⭐⭐ | ⭐⭐ | ⭐ |
| 泛化能力 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ |
6.2 实际应用优势
-
训练效率大幅提升
- 并行计算使训练时间减少60-80%
- 适合大规模分布式训练
-
模型性能显著提高
- 在机器翻译任务上,BLEU分数提升2-4分
- 在语言理解任务上,准确率提升3-5%
-
架构统一性
- 同一架构可用于不同模态数据
- 减少领域特定模型开发成本
-
可扩展性强
- 模型规模可轻松扩展到千亿参数
- 支持多任务联合学习
七、未来展望与挑战
7.1 计算效率优化
python
class EfficientTransformer(nn.Module):
"""高效Transformer优化方向"""
def __init__(self):
super().__init__()
# 1. 混合精度训练
self.use_amp = True
# 2. 梯度检查点
self.gradient_checkpointing = True
# 3. 模型并行
self.model_parallel = False
# 4. 动态计算
self.dynamic_computation = True
def forward(self, x):
if self.use_amp:
with torch.cuda.amp.autocast():
return self._forward(x)
return self._forward(x)
def _forward(self, x):
# 实现高效的forward逻辑
pass7.2 研究方向
-
线性复杂度注意力机制
- Linformer, Performer, Longformer等变体
-
多模态统一架构
- 文本、图像、音频的统一表示
-
自监督学习
- BERT, GPT, CLIP等预训练范式
-
稀疏化与量化
- 模型压缩技术应用
结语
Transformer模型以其革命性的自注意力机制,彻底改变了深度学习领域。它不仅解决了传统序列模型的并行化难题,还通过全局依赖建模显著提升了模型性能。从BERT、GPT到Vision Transformer,Transformer架构在各个领域都展现出强大的能力。
尽管存在计算复杂度较高、内存消耗大等挑战,但随着技术的不断进步,Transformer无疑将继续引领AI发展的新方向。掌握Transformer的原理和应用,已经成为现代AI工程师的必备技能。
