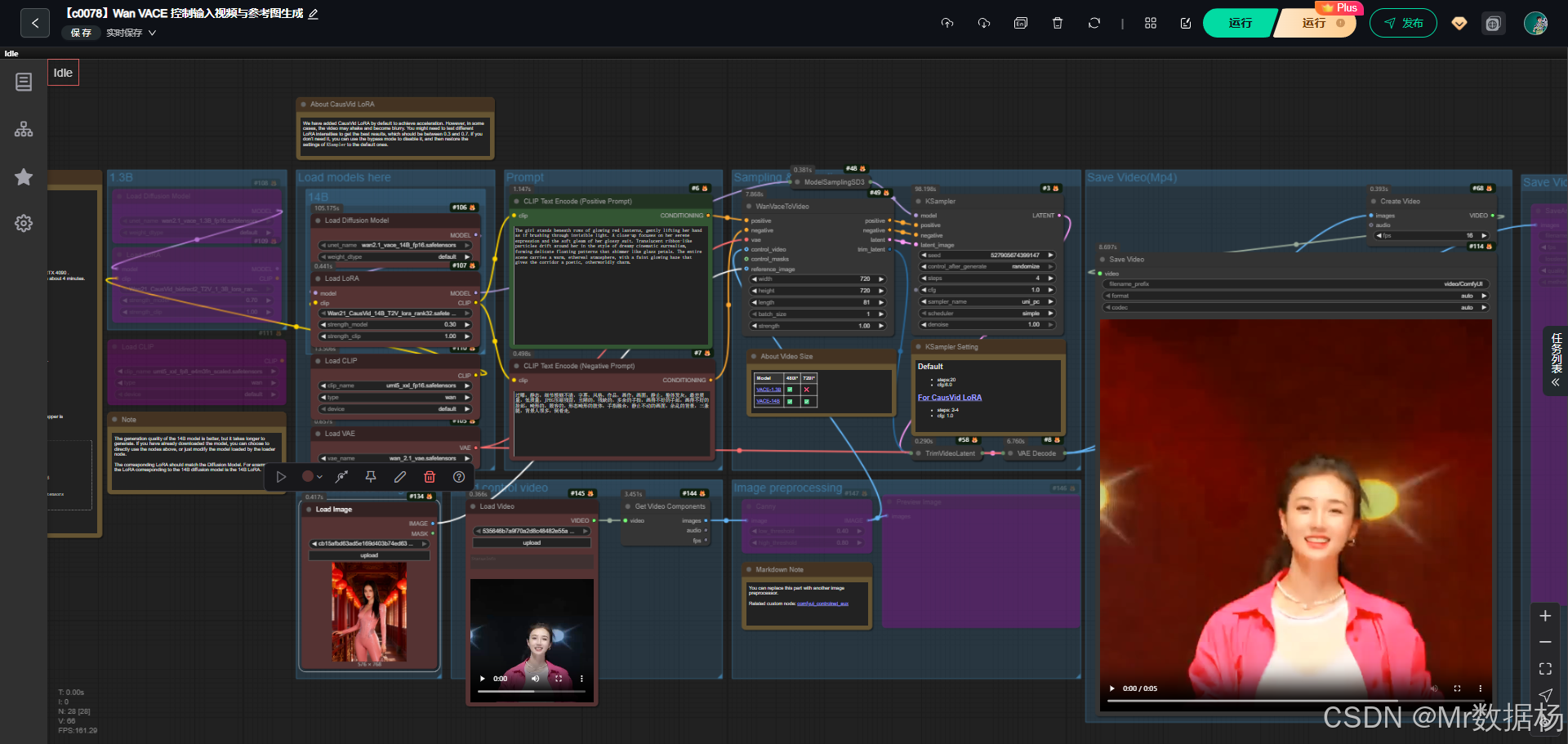
今天演示的案例是一个基于 Wan2.1 VACE 的 ComfyUI 视频生成工作流,整个流程通过加载多种核心模型并结合 CausVid LoRA 加速技术,实现了从文本提示、参考图像与控制视频到动态视频的生成。
该工作流支持 1.3B 与 14B 两种规模的模型,其中 14B 能够输出高质量的 720P 视频,而 1.3B 更适合在资源有限的场景下快速生成 480P 动画。结合正向与负向提示的编码,以及视频边缘检测的控制方式,最终生成的视频具备清晰的动作连贯性和较高的艺术表现力,非常适合在教学、创意短片或 AI 绘画扩展应用中使用。
文章目录
- 工作流介绍
- 工作流程
- 大模型应用
-
- [CLIPTextEncode(Positive Prompt) 视频语义驱动核心](#CLIPTextEncode(Positive Prompt) 视频语义驱动核心)
- [CLIPTextEncode(Negative Prompt) 画面瑕疵抑制](#CLIPTextEncode(Negative Prompt) 画面瑕疵抑制)
- [WanVaceToVideo(Prompt 条件融合) 文本驱动的视频动作生成核心](#WanVaceToVideo(Prompt 条件融合) 文本驱动的视频动作生成核心)
- 使用方法
- 应用场景
- 开发与应用
工作流介绍
这个工作流的设计核心在于模型加载、文本条件编码、采样解码和视频合成环节的协同工作。UNET 模型与 VAE 模型分别承担了扩散推理与图像解码的任务,而 CLIP 编码器负责将文本转化为条件信号。通过 KSampler 的迭代采样生成潜在空间内容,再结合 WanVaceToVideo 节点将参考图像与控制视频融合,最终由解码器还原为逐帧图像,合成完整视频。整个过程不仅可以通过 LoRA 轻量化调整性能,还能在不同分辨率和运行环境中灵活应用。
核心模型
该工作流依赖多个核心模型协同运行,其中扩散模型决定了生成质量与分辨率,VAE 模型负责潜变量与图像之间的解码映射,CLIP 模型则承担文本到条件的语义编码,而 LoRA 模型用于针对视频生成场景进行加速优化。综合这些模型的配合,工作流实现了高效的视频合成能力。
| 模型名称 | 说明 |
|---|---|
| wan2.1_vace_14B_fp16.safetensors | 14B 参数量扩散模型,支持 480P 与 720P 高质量视频生成 |
| wan2.1_vace_1.3B_fp16.safetensors | 1.3B 参数量扩散模型,仅支持 480P 输出,生成速度快 |
| wan_2.1_vae.safetensors | VAE 模型,用于潜变量与图像之间的解码与重构 |
| umt5_xxl_fp16 / fp8.safetensors | 文本编码模型,将正负提示转化为语义条件输入 |
| Wan21_CausVid_14B_T2V_lora_rank32.safetensors | 针对 14B 模型的 LoRA 加速,显著缩短视频生成时间 |
| Wan21_CausVid_bidirect2_T2V_1_3B_lora_rank32.safetensors | 针对 1.3B 模型的 LoRA 优化,提升采样效率与连贯性 |
Node节点
工作流的节点设计体现了从输入到输出的完整链路。模型加载节点保证了必要组件的初始化,CLIPTextEncode 节点将文本转化为条件控制信号,WanVaceToVideo 节点是生成潜变量的关键部分,配合 KSampler 的迭代采样实现动态画面的潜在表示,再通过 VAE 解码得到可视图像,最终交由 SaveVideo 节点合成视频输出。除此之外,还加入了 Canny 节点进行边缘检测,以控制生成视频的结构清晰度,保证了结果的细节表现。
| 节点名称 | 说明 |
|---|---|
| UNETLoader | 加载核心扩散模型,决定视频生成的基底效果 |
| VAELoader | 加载 VAE 模型,用于潜变量与图像的解码映射 |
| CLIPLoader | 加载文本编码模型,将自然语言转为条件输入 |
| LoraLoader | 加载 LoRA 模型,对扩散模型进行加速或性能微调 |
| CLIPTextEncode (Positive/Negative) | 编码正向与负向提示,形成生成约束与优化 |
| WanVaceToVideo | 将提示与参考数据映射到视频潜变量 |
| KSampler | 在潜在空间中进行迭代采样,生成连贯视频帧 |
| VAEDecode | 将潜在变量还原为图像帧 |
| Canny | 对参考视频图像进行边缘检测,提供结构约束 |
| CreateVideo | 将图像帧与音频合成为视频文件 |
| SaveVideo / SaveAnimatedWEBP | 保存输出结果,支持 MP4 与 WebP 格式 |
工作流程
整个工作流围绕视频生成展开,涵盖模型加载、文本编码、采样解码、图像预处理和视频合成等阶段。通过 CLIP 文本提示与反向提示建立生成条件,再结合 Wan VACE 模型和 CausVid LoRA 进行高效视频生成。视频预处理环节引入控制视频和参考图像,利用边缘检测增强细节表现,最后通过 VAE 解码与多种保存方式输出结果。整个过程强调在保证画面质量的同时提升生成速度,并通过不同模型与 LoRA 的组合实现灵活的分辨率支持。
| 流程序号 | 流程阶段 | 工作描述 | 使用节点 |
|---|---|---|---|
| 1 | 模型加载 | 加载 UNet、VAE、CLIP 等基础模型,并附加相应的 LoRA,用于支持不同规模的视频生成。 | UNETLoader、VAELoader、CLIPLoader、LoraLoader |
| 2 | 提示词处理 | 将正向与负向提示词分别编码成条件输入,建立视频生成的语义约束。 | CLIPTextEncode (Positive/Negative) |
| 3 | 条件组合与采样 | 使用 WanVaceToVideo 将提示词与控制视频、参考图像结合,输出潜空间数据,并由 KSampler 完成采样。 | WanVaceToVideo、KSampler |
| 4 | 图像预处理 | 从控制视频提取帧序列,经过边缘检测增强结构信息,为后续合成提供辅助特征。 | LoadVideo、GetVideoComponents、Canny |
| 5 | 解码与生成图像 | 将潜变量通过 VAE 解码成图像序列,结合裁剪模块保证序列完整性。 | TrimVideoLatent、VAEDecode |
| 6 | 视频合成与预览 | 图像序列与音频合成为视频,可保存为 MP4 或 WebP 格式,并支持中间图像预览。 | CreateVideo、SaveVideo、SaveAnimatedWEBP、PreviewImage |
大模型应用
CLIPTextEncode(Positive Prompt) 视频语义驱动核心
正向 CLIPTextEncode 节点负责将用户的 Prompt 转化为语义嵌入,用于指导 Wan VACE 模型理解视频生成的动作节奏、镜头表现和情绪氛围。Prompt 决定生成视频的视觉风格、镜头距离、角色动作以及整体画面表现,是控制视频生成逻辑的核心入口。语义越细,动作越精准;风格描述越清晰,整体画面越统一。
| 节点名称 | Prompt 信息 | 说明 |
|---|---|---|
| CLIP Text Encode (Positive Prompt) | The girl is dancing in a sea of flowers, slowly moving her hands. There is a close - up shot of her upper body. The character is surrounded by other transparent glass flowers in the style of Nicoletta Ceccoli, creating a beautiful, surreal, and emotionally expressive movie scene with a white, transparent feel and a dreamy atmosphere. | 将正向 Prompt 转化为语义向量,用于驱动视频生成模型理解动作、镜头、氛围与风格。 |
CLIPTextEncode(Negative Prompt) 画面瑕疵抑制
负向 Prompt 用于告诉模型哪些内容"不能出现"。它不参与创造性生成,只负责限制错误动作、异常肢体、模糊噪点、多肢畸形等问题。通过语义嵌入的反向约束,确保最终视频保持干净、稳定、无违和。
| 节点名称 | Prompt 信息 | 说明 |
|---|---|---|
| CLIP Text Encode (Negative Prompt) | 过曝,静态,细节模糊不清,字幕,风格,作品,画作,画面,静止,整体发灰,最差质量,低质量,JPEG压缩残留,丑陋的,残缺的,多余的手指,画得不好的手部,画得不好的脸部,畸形的,毁容的,形态畸形的肢体,手指融合,静止不动的画面,杂乱的背景,三条腿,背景人很多,倒着走 | 通过负向 Prompt 的语义嵌入抑制错误动作、低质细节和畸形元素,保证画面自然稳定。 |
WanVaceToVideo(Prompt 条件融合) 文本驱动的视频动作生成核心
该节点是 VACE 视频生成的关键大模型模块。它将正负向 Prompt、参考图像、控制视频(可为 Canny 边缘提取后的视频帧)一起整合,生成统一的条件潜变量。Prompt 在该节点中作为"动作指令",决定动作节奏、风格统一性、镜头叙事与风格融合强度。
| 节点名称 | Prompt 信息 | 说明 |
|---|---|---|
| WanVaceToVideo | 正向与负向 Prompt 由前两个 CLIPTextEncode 提供 | 将文本语义、控制视频、参考图像一起融合成为视频生成潜变量,是整个视频动作迁移与生成的核心大模型节点。 |
使用方法
整个视频生成流程基于 Wan VACE 的文本驱动视频生成架构,通过控制视频、参考图像和 Prompt 的组合实现可控动作生成。用户只需替换参考图像、加载新的控制视频、填入 Prompt,即可自动生成具有指定动作和视觉风格的视频片段。
控制视频用于提供动作流、镜头节奏或位移趋势;Canny 预处理确保结构清晰。参考图像负责角色外观的固定,使生成视频的主角保持统一形象。Prompt 决定角色如何表现、镜头如何叙事、背景如何渲染。模型根据 Prompt 与视频帧同步生成潜变量,经 KSampler 采样后被解码成视频帧,并最终由 CreateVideo 和 SaveVideo 输出为 MP4 或 WebP 动图。
| 注意点 | 说明 |
|---|---|
| Prompt 描述越详细,动作越准确 | 决定镜头、情绪、动作力度和视觉风格 |
| 使用负向 Prompt 抑制瑕疵 | 防止出现多肢、变形、模糊、噪点等问题 |
| 控制视频需干净、结构清晰 | 影响动作迁移的准确度 |
| 参考图像应高分辨、光照清晰 | 确保角色外观统一不漂移 |
| LoRA 强度需按场景调整 | 0.3 到 0.7 范围最稳定,过高可能导致抖动画面 |
| 调整 KSampler 步数与 CFG | 步数过低动作会不连贯,过高生成变慢 |
| 输出分辨率与模型匹配 | 14B 支持 720P,1.3B 仅支持 480P |
应用场景
该工作流的设计面向影视创作、动画生成与实验性视频研究。通过高度可控的提示词与 LoRA 模型组合,可以在保证画面质量的前提下实现快速生成。其应用场景包括艺术创作、广告短片生成、AI 实验教学等,不同用户能够根据需求选择高质量或高速模式。对于研究人员,该流程还可作为模型评测和优化的实验平台,借助边缘检测与参考图像增强生成结果的可控性。
| 应用场景 | 使用目标 | 典型用户 | 展示内容 | 实现效果 |
|---|---|---|---|---|
| 艺术创作 | 借助提示词快速生成具备特定风格的短片 | 插画师、独立动画人 | 超现实风格的动态画面、梦境般的场景 | 提升创意表达效率,增强作品表现力 |
| 广告短片 | 高效生成与产品相关的动态视觉效果 | 广告设计团队 | 产品动态展示、品牌视觉包装 | 降低成本,快速形成视觉方案 |
| 教学实验 | 作为 AI 视频生成的实践案例,用于教学演示 | 高校教师、研究者 | 从提示词到视频的生成链路演示 | 帮助学习者理解 AI 视频生成原理与流程 |
| 研究探索 | 测试不同模型与 LoRA 在视频生成中的表现 | AI 研究人员 | 同一提示下的不同模型输出对比 | 探索模型性能差异,验证优化策略 |
| 社交传播 | 快速生成新颖的短视频内容以提升社交平台影响力 | 自媒体创作者 | 创意短视频、视觉特效场景 | 增加互动与传播力,吸引观众注意 |
开发与应用
更多 AIGC 与 ComfyUI工作流 相关研究学习内容请查阅:
更多内容桌面应用开发和学习文档请查阅:
AIGC工具平台Tauri+Django环境开发,支持局域网使用
AIGC工具平台Tauri+Django常见错误与解决办法
AIGC工具平台Tauri+Django内容生产介绍和使用
AIGC工具平台Tauri+Django开源ComfyUI项目介绍和使用
AIGC工具平台Tauri+Django开源git项目介绍和使用