系列文章目录
- 第一章 【大数据环境安装指南】 JDK安装
- 第二章 【大数据环境安装指南】 Python安装
- 第三章 【大数据环境安装指南】VMware虚拟机静态IP及多IP配置
- 第四章 【大数据环境安装指南】 Flume图文安装教程
- 第五章 【大数据环境安装指南】ZooKeeper搭建Hadoop高可用集群教程
前言
运行环境:
- 操作系统:Centos 7、Rocky 9 、Kylin V11
- Hadoop版本:3.4.2
- Zookeeper版本:3.8.4
- Spark版本:3.5.7
- jdk版本:8
Spark 作为大数据领域的核心计算框架,以内存计算为核心优势,兼容批处理、流处理、交互式查询、机器学习等多场景,是大数据分析与处理的主流选择。
一、Spark 核心组件与架构
1.1 核心组件
| 组件 | 功能说明 |
|---|---|
| Spark Core | 核心引擎,提供 RDD、任务调度、内存管理、分布式计算等基础能力,是所有组件的底层支撑; |
| Spark SQL | 结构化数据处理模块,支持 SQL 查询、DataFrame/Dataset API,兼容 Hive(Hive on Spark); |
| Spark Streaming | 准实时流处理(微批处理),基于 RDD 将流数据切分为小批次处理(已逐步被 Structured Streaming 替代); |
| Structured Streaming | 新一代流处理框架,基于 DataFrame/Dataset,支持流批一体、事件时间、状态管理; |
| MLlib | 机器学习库,提供分类、回归、聚类、推荐系统等算法,以及特征工程、模型评估工具; |
| GraphX | 图计算库,支持 PageRank、最短路径等图算法,基于 RDD 实现图的存储与计算; |
1.2 集群架构(Standalone 模式为例)
- Driver:驱动程序,负责应用程序的解析、任务调度(DAG 调度器、任务调度器)、结果返回;
- Master:集群资源管理器(Standalone 模式),管理 Worker 节点,分配资源给 Driver;
- Worker:工作节点,管理 Executor 进程,向 Master 注册;
- Executor:运行在 Worker 节点的进程,负责执行 Task(任务),缓存数据,与 Driver 通信;
- Task:最小执行单元,一个 Stage(阶段)包含多个 Task,并行运行在不同 Executor。
1.3 Spark 集群部署模式对比
| 部署模式 | 适用场景 | 优势 |
|---|---|---|
| Local | 开发测试、小规模数据处理 | 无需集群,配置简单 |
| Standalone | 中小规模集群、独立 Spark 集群 | 部署简单,无需依赖 Hadoop |
| YARN(推荐) | 大规模集群、与 Hadoop 生态集成 | 资源隔离、多框架共享集群(Spark+MapReduce)、HA(基于 YARN RM) |
| Kubernetes | 容器化集群、云原生场景 | 弹性扩缩容、容器隔离、云平台适配 |
1.4 Spark 高可用(HA)实现
Spark HA 核心解决单点故障问题,不同部署模式的 HA 方案不同:
- Standalone 模式(基于 ZooKeeper)
核心:多个 Master 节点(1 Active + N Standby),ZooKeeper 负责 Master 选举、故障检测、元数据存储;
关键配置:spark.deploy.recoveryMode=ZOOKEEPER、spark.deploy.zookeeper.url(ZK 集群地址);
故障切换:Active Master 宕机后,ZK 触发选举,Standby Master 自动切换为 Active,Worker/Driver 重新连接。 - YARN 模式(天然 HA)
依赖 YARN 的 ResourceManager(RM)HA(基于 ZK),Spark 无需额外配置;
Driver 可配置为 YARN Cluster 模式(Driver 运行在 YARN 容器),避免 Driver 单点故障。
二、Spark集群搭建
搭建一个 三节点的 Spark 集群,三台主机上均部署 Worker 服务。为保证高可用,除了在 node1 上部署主 Master 服务外,还在 node2 和 node3 上分别部署备用的 Master 服务,Master 服务由 Zookeeper 集群进行协调管理,如果主 Master 不可用,则备用 Master 会成为新的主 Master。
2.1 Hadoop高可用集群搭建(必要)
在搭建 Spark 集群前,需要确保 JDK 环境、Zookeeper 和 Hadoop 集群已经搭建,详细搭建教程可参考:
【大数据环境安装指南】ZooKeeper搭建Hadoop高可用集群教程
2.2 Spark 搭建
Spark版本选择:
| Spark 版本 | 支持的 JDK 版本 | 推荐 JDK 版本 | 关键说明 |
|---|---|---|---|
| Spark 1.x | JDK 7、JDK 8 | JDK 8 | 仅历史版本,已停止维护 |
| Spark 2.0 - 2.3 | JDK 8 | JDK 8 | 完全仅支持 JDK 8,高版本 JDK 会报兼容错误 |
| Spark 2.4 | JDK 8(主)、JDK 11(实验) | JDK 8 | JDK 11 需额外配置,不建议生产使用 |
| Spark 3.0 - 3.2 | JDK 8、JDK 11 | JDK 8/11 | 3.2 是最后一个完全适配 JDK 8 的主流版本 |
| Spark 3.3 - 3.4 | JDK 8、JDK 11、JDK 17(实验) | JDK 11 | JDK 17 为实验支持,生产建议用 JDK 11 |
| Spark 3.5+ | JDK 8(兼容)、JDK 11、JDK 17 | JDK 17 | JDK 8 逐步弃用,官方主推 JDK 17 |
| Spark 4.0 | JDK 11、JDK 17 | JDK 17 | 完全移除 JDK 8 支持,仅支持 11/17(LTS 版本) |
2.2.1 下载Spark
下载所需版本的 Spark,官网地址:https://spark.apache.org/downloads.html
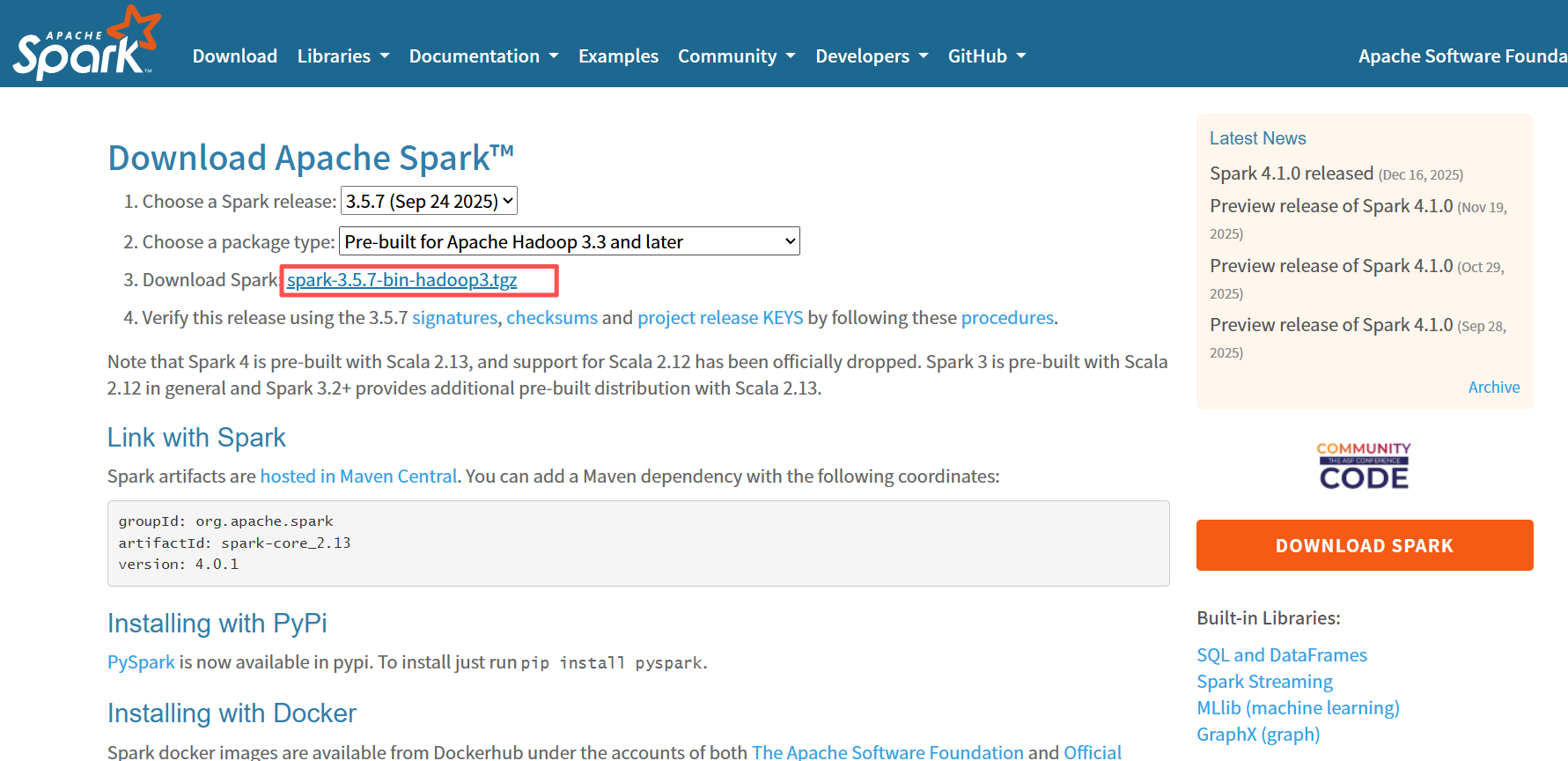
因为采用的是jdk 8环境,所以spark采用3.5.7版本
bash
wget https://dlcdn.apache.org/spark/spark-3.5.7/spark-3.5.7-bin-hadoop3.tgz2.2.2 解压Spark
下载后进行解压:
bash
#解压到/usr/local/app目录下,没有app目录可以新建
tar -zxvf spark-3.5.7-bin-hadoop3.tgz -C /usr/local/app
# 添加软链接
ln -s spark-3.5.7-bin-hadoop3/ spark2.2.3 配置环境变量
bash
#修改配置文件
sudo vim /etc/profile添加如下配置内容
bash
export SPARK_HOME=/usr/local/app/spark
export PATH=${SPARK_HOME}/bin:$PATH环境变量立即生效
bash
source /etc/profile2.2.4 集群配置
进入 ${SPARK_HOME}/conf 目录,拷贝配置样本进行修改:
bash
cd ${SPARK_HOME}/conf- 修改spark-env.sh文件
bash
cp spark-env.sh.template spark-env.sh
vim spark-env.sh添加如下内容
bash
# 配置JDK安装位置
JAVA_HOME=/usr/local/jdk8
# 配置hadoop配置文件的位置
HADOOP_CONF_DIR=/usr/local/app/hadoop/etc/hadoop
# 配置zookeeper地址
SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node1:2181,node2:2181,node3:2181 -Dspark.deploy.zookeeper.dir=/spark"- 增加slaves文件
bash
vim slaves配置所有 Woker 节点的位置:
bash
node1
node2
node32.2.5 安装包分发
将 Spark 的安装包分发到其他服务器
shell
scp -r /usr/local/app/spark node2:/usr/local/app/
scp -r /usr/local/app/spark node3:/usr/local/app/分发后在这两台服务器上也配置一下 Spark 的环境变量,修改/etc/profile文件,添加如下环境变量:
bash
export SPARK_HOME=/usr/local/app/spark
export PATH=${SPARK_HOME}/bin:$PATH三、启动集群
3.1 启动ZooKeeper集群
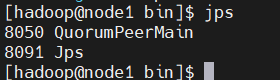
分别启动三台服务器上的ZooKeeper 服务:
bash
#进入zookeeper安装目录
cd /usr/local/app/zookeeper/bin
# 启动zookeeper
./zkServer.sh start可以使用命令jps验证进程是否已经启动,出现 QuorumPeerMain 则代表启动成功。
3.2 启动Hadoop集群
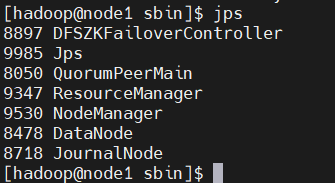
主节点node1执行如下命令:
bash
#进入$HADOOP_HOME/sbin目录
cd $HADOOP_HOME/sbin
# 启动dfs服务
./start-dfs.sh
# 启动yarn服务
./start-yarn.sh命令jps验证进程
3.3 启动Spark集群
- 进入 主节点node1 的
${SPARK_HOME}/sbin目录下,执行下面命令启动集群:
bash
cd ${SPARK_HOME}/sbin
#启动集群
./start-all.sh执行命令后,会在 hadoop001 上启动 Maser 服务,会在 slaves 配置文件中配置的所有节点上启动 Worker 服务。

- 分别在 node2 和 node3 上执行下面的命令,启动备用的
Master服务:
bash
cd ${SPARK_HOME}/sbin
# 在${SPARK_HOME}/sbin 下执行
./start-master.sh四、查看服务
Master 端口分「通信端口(7077)」和「Web UI 端口(默认 8080)」,可以通过日志查看启动的端口,日志路径格式:spark-<用户名>-org.apache.spark.deploy.master.Master-1-<节点名>.out
bash
grep -i "web ui" $SPARK_HOME/logs/spark-hadoop-org.apache.spark.deploy.master.Master-1-node1.out
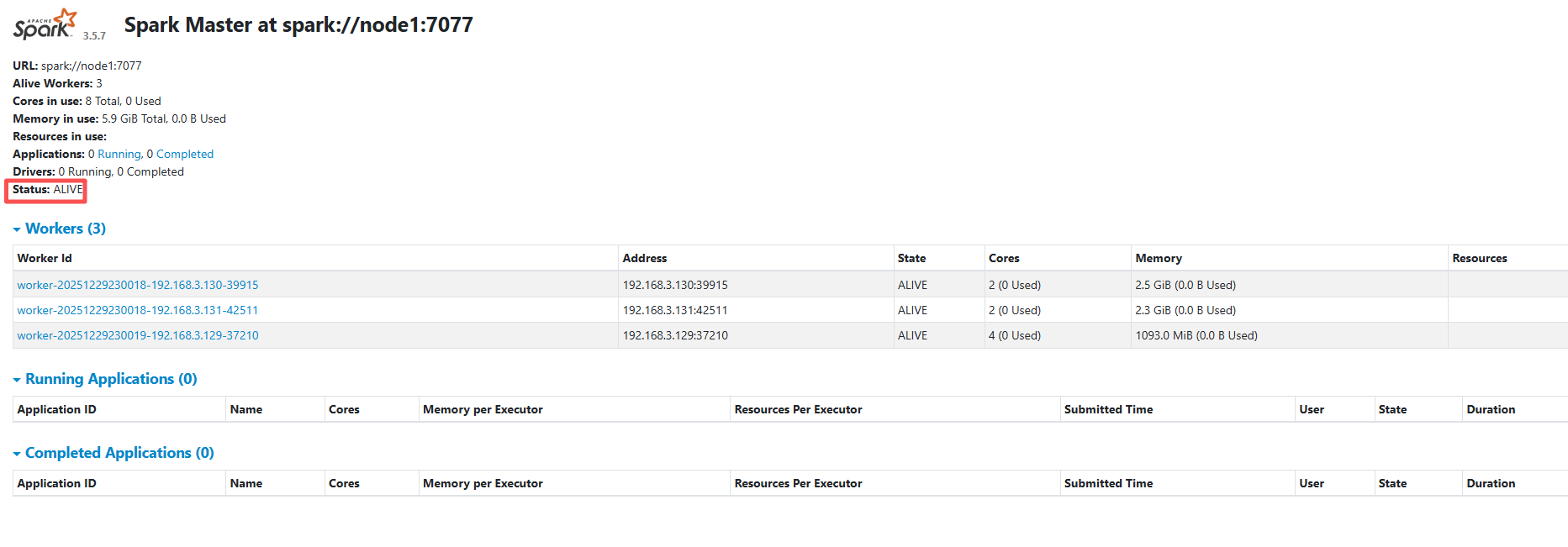
这里Spark 的 Web-UI 页面,端口为 8081。此时可以看到node1 上的 Master 节点处于 ALIVE 状态,并有 3 个可用的 Worker 节点。
通过web访问http://node2:8081和http://node3:8081/,node2 和 node3 上的 Master 节点均处于 STANDBY 状态,没有可用的 Worker 节点。