
目录
[一、设计测试用例的总纲:基于需求,让用例有 "根" 可依](#一、设计测试用例的总纲:基于需求,让用例有 “根” 可依)
[1.1 核心逻辑:需求→测试点→用例的闭环](#1.1 核心逻辑:需求→测试点→用例的闭环)
[1.2 具体步骤:手把手教你从需求拆解用例](#1.2 具体步骤:手把手教你从需求拆解用例)
[第一步:需求分析 ------ 先搞懂 "要做什么"](#第一步:需求分析 —— 先搞懂 “要做什么”)
[第二步:提炼测试点 ------ 把需求转化为 "可测试场景"](#第二步:提炼测试点 —— 把需求转化为 “可测试场景”)
[第三步:设计测试用例 ------ 将测试点转化为 "可执行步骤"](#第三步:设计测试用例 —— 将测试点转化为 “可执行步骤”)
[1.3 核心原则:确保用例 "不冗余、无遗漏"](#1.3 核心原则:确保用例 “不冗余、无遗漏”)
[二、6 大核心设计方法:精准拆解场景,高效覆盖无死角](#二、6 大核心设计方法:精准拆解场景,高效覆盖无死角)
[2.1 等价类划分法:解决 "穷举测试" 的效率难题](#2.1 等价类划分法:解决 “穷举测试” 的效率难题)
[操作步骤 + 实战案例](#操作步骤 + 实战案例)
[2.2 边界值分析法:抓住 "最容易出问题的边缘场景"](#2.2 边界值分析法:抓住 “最容易出问题的边缘场景”)
[操作步骤 + 实战案例](#操作步骤 + 实战案例)
[2.3 正交法:解决 "多输入组合" 的冗余问题](#2.3 正交法:解决 “多输入组合” 的冗余问题)
[操作步骤 + 实战案例](#操作步骤 + 实战案例)
[2.4 判定表法:理清 "多条件组合触发不同结果" 的逻辑](#2.4 判定表法:理清 “多条件组合触发不同结果” 的逻辑)
[操作步骤 + 实战案例](#操作步骤 + 实战案例)
[2.5 场景法:模拟 "真实业务流程",覆盖端到端场景](#2.5 场景法:模拟 “真实业务流程”,覆盖端到端场景)
[操作步骤 + 实战案例](#操作步骤 + 实战案例)
[2.6 错误猜测法:基于经验,快速定位 "高频 bug 场景"](#2.6 错误猜测法:基于经验,快速定位 “高频 bug 场景”)
[三、不同场景实战演练:命令行程序 + Web 接口](#三、不同场景实战演练:命令行程序 + Web 接口)
[3.1 命令行程序:zip/unzip 命令的测试用例设计](#3.1 命令行程序:zip/unzip 命令的测试用例设计)
[综合运用方法:等价类 + 边界值 + 错误猜测法](#综合运用方法:等价类 + 边界值 + 错误猜测法)
[3.2 Web 接口:博客详情页接口的测试用例设计](#3.2 Web 接口:博客详情页接口的测试用例设计)
[综合运用方法:等价类 + 边界值 + 场景法 + 错误猜测法](#综合运用方法:等价类 + 边界值 + 场景法 + 错误猜测法)
[接口测试工具:Postman 的使用技巧](#接口测试工具:Postman 的使用技巧)
前言
在上一篇测试用例分享中,我们搞定了 "是什么" 和 "从哪测" 的问题 ------ 明确了测试用例的核心概念,掌握了 "功能 + 界面 + 性能" 的万能设计框架。但实际工作中,面对 "姓名 6~15 位字符""多条件组合触发不同结果" 这类具体需求,很多人还是会犯难:"用例怎么设计才不冗余?""边缘场景怎么才能不遗漏?"
其实,测试用例设计的精髓在于 "精准方法 + 灵活落地"。今天这篇文章,我们就聚焦测试用例的核心设计方法 ------ 从 "基于需求" 的总纲,到 "等价类、边界值" 等 6 大具体技巧,让你的用例既全面又高效,告别 "无效测试" 和 "覆盖不全" 的尴尬!下面就让我们正式开始吧!
一、设计测试用例的总纲:基于需求,让用例有 "根" 可依
无论使用哪种具体方法,设计测试用例的核心前提都是 "基于需求"------ 脱离需求的用例,再精巧也只是 "空中楼阁"。很多测试新手容易陷入 "埋头设计用例,却偏离需求核心" 的误区,而基于需求的设计方法,能帮我们从源头把控用例的有效性和针对性。
1.1 核心逻辑:需求→测试点→用例的闭环
基于需求设计用例的本质,是把抽象的需求转化为可执行、可验证的测试步骤,核心逻辑是 "需求分析→测试点提炼→用例设计" 的闭环:
- 需求分析:搞懂 "产品要做什么",提取功能点、约束条件和业务流程;
- 测试点提炼:把需求拆解为 "可测试的最小单元",确保无遗漏;
- 用例设计:将测试点转化为包含测试环境、数据、步骤、预期结果的完整用例。
打个形象的比方:需求文档就像 "建筑图纸",测试点是 "施工细节",测试用例是 "具体的施工步骤"。没有图纸的施工会建成 "危房",脱离需求的用例设计只会做 "无用功"。
1.2 具体步骤:手把手教你从需求拆解用例
第一步:需求分析 ------ 先搞懂 "要做什么"
拿到需求文档后,别急着写用例,先花时间深入分析,具体要做 3 件事:
- 提取核心功能点:包括正常流程和异常流程。以 "邮箱注册" 为例,核心功能点有:同意协议、填写注册信息、验证码校验、发送激活邮件、账号激活等;
- 明确约束条件:找出对输入、输出的限制。比如 "姓名必填,6~15 位字符""密码隐藏显示""激活邮件 24 小时内有效" 等;
- 梳理业务流程:理清功能的执行顺序和依赖关系。比如 "邮箱注册" 的流程是:同意协议→填写信息→提交→发送激活邮件→激活账号→注册完成。
如果需求存在模糊、矛盾的地方,一定要及时和产品、开发沟通澄清 ------ 基于错误的需求设计用例,只会越做越偏。
第二步:提炼测试点 ------ 把需求转化为 "可测试场景"
需求分析完成后,需要将抽象的需求拆解为具体的测试点。一个测试点对应一个需要验证的场景,是用例的 "最小单元"。
以 "邮箱注册" 的 "姓名" 字段为例(需求:必填,6~15 位字符),可提炼出以下测试点:
- 姓名为空,点击提交→提示 "请输入姓名";
- 姓名为 5 位字符(小于 6 位)→提示 "姓名长度需 6~15 位";
- 姓名为 16 位字符(大于 15 位)→提示 "姓名长度需 6~15 位";
- 姓名为 6 位字符(边界值)→无错误提示,可正常提交;
- 姓名为 15 位字符(边界值)→无错误提示,可正常提交;
- 姓名包含特殊字符(如 @、#)→验证是否符合需求(需确认需求是否允许)。
第三步:设计测试用例 ------ 将测试点转化为 "可执行步骤"
每个测试点都需要转化为完整的测试用例,确保包含所有核心要素。以 "姓名为 5 位字符" 的测试点为例,对应的用例如下:
| 用例编号 | test-register-name-001 |
|---|---|
| 标题 | 姓名长度为 5 位时注册失败 |
| 功能模块 | 注册登录模块 |
| 重要性 | 中 |
| 测试前提 | 系统运行正常,邮件服务器已开启 |
| 测试环境 | Win10 + Chrome 103.0.5060.66 |
| 测试数据 | 姓名:张三 12(5 位),邮箱:test@163.com,密码:123456,确认密码:123456,验证码:666666 |
| 测试步骤 | 1. 打开网易注册页面;2. 同意用户协议;3. 输入测试数据;4. 点击 "注册" 按钮 |
| 预期结果 | 页面提示 "姓名长度需 6~15 位",注册失败 |
1.3 核心原则:确保用例 "不冗余、无遗漏"
- 全覆盖:所有功能点、约束条件、业务流程都必须被测试点覆盖;
- 无冗余:不设计与需求无关的用例,避免浪费测试资源;
- 可验证:预期结果必须明确,不能是 "看起来正常" 这种模糊描述;
- 优先级分明:核心功能(如正常注册流程)的用例优先级高,边缘场景(如特殊字符姓名)可适当降低优先级。
二、6 大核心设计方法:精准拆解场景,高效覆盖无死角
基于需求提炼出测试点后,就需要用具体的方法来设计用例。不同场景适合不同的方法,下面我们逐一拆解 6 种最常用的测试用例设计方法,结合实战案例帮你快速掌握。
2.1 等价类划分法:解决 "穷举测试" 的效率难题
适用场景
当需求中存在 "输入范围" 或 "输入格式" 约束时,比如 "姓名 6~15 位字符""手机号 11 位数字""邮箱格式正确",如果用穷举法测试所有可能的输入,效率极低(比如 6~15 位字符需要测试 10 种情况,6~150 位则需要 145 种)。此时用等价类划分法,能以最少的用例覆盖最多的场景。
核心逻辑
等价类划分法的核心思想是:将输入(或输出)划分为若干个 "等价类",每个等价类中的输入具有相同的测试效果。只需从每个等价类中选取一个代表性数据作为测试用例,若该用例通过,则认为整个等价类通过测试。
等价类分为两类:
- 有效等价类:符合需求约束的输入集合,用于验证功能 "是否做了该做的"。比如 "姓名 6~15 位字符" 的有效等价类是 "6 位字符""10 位字符""15 位字符";
- 无效等价类:不符合需求约束的输入集合,用于验证功能 "是否拦截了不该做的"。比如 "姓名 6~15 位字符" 的无效等价类是 "空值""5 位字符""16 位字符""特殊字符"。
生活类比
老师给学生布置作业:"成绩超过 60 分的抄写 1 遍,低于 60 分的抄写 3 遍"。这里可以把学生分为 "超过 60 分""低于 60 分" 两个等价类,无需逐个检查每个学生的成绩,只需从每个类中选一个代表验证即可 ------ 这就是等价类的核心逻辑。
操作步骤 + 实战案例
以 "邮箱注册" 的 "姓名" 字段(需求:必填,6~15 位字符)为例:
-
划分等价类 :
等价类类型 具体场景 代表性数据 有效等价类 6 位字符 张三 123(6 位) 有效等价类 10 位字符 张三李四王五 12(10 位) 有效等价类 15 位字符 张三李四王五 1234567(15 位) 无效等价类 空值 无 无效等价类 5 位字符 张三 12(5 位) 无效等价类 16 位字符 张三李四王五 12345678(16 位) 无效等价类 特殊字符 张三 #123(含 #) -
设计测试用例 :从每个等价类中选取代表性数据,编写用例。

优缺点
- 优点:大幅减少用例数量,提高测试效率,解决穷举法无法覆盖的场景;
- 缺点:只考虑单个输入的分类,不考虑输入之间的组合关系,需要结合其他方法补充。
2.2 边界值分析法:抓住 "最容易出问题的边缘场景"
适用场景
很多软件的 bug 都出在 "边界" 上 ------ 比如 "6~15 位字符" 的需求,可能 6 位、15 位正常,但 5 位、16 位却出现异常;"成绩 60 分及格" 的需求,可能 60 分正常,59 分、61 分却有问题。边界值分析法就是专门针对这些 "边界场景" 设计的方法,通常作为等价类划分法的补充。
核心逻辑
边界值分析法的核心是:对输入或输出的 "边界值" 和 "次边界值" 进行重点测试。边界值是需求明确的临界值(如 6 位、15 位),次边界值是边界值的相邻值(如 5 位、16 位)。
经典案例
老师布置作业:"超过 60 分抄写 1 遍,低于 60 分抄写 3 遍"。小明刚好考了 60 分,结果没写作业 ------ 这就是 "边界漏洞"。如果老师用边界值分析法,提前考虑 "等于 60 分" 的场景,就不会出现这种问题。
常用边界值选取规则
- 输入框长度为 a~b 位:测试 a-1、a、b、b+1 位;
- 数值范围为 a~b:测试 a-1、a、b、b+1;
- 分页场景:每页显示 n 条,测试 0 条、1 条、n 条、n+1 条、总条数。
操作步骤 + 实战案例
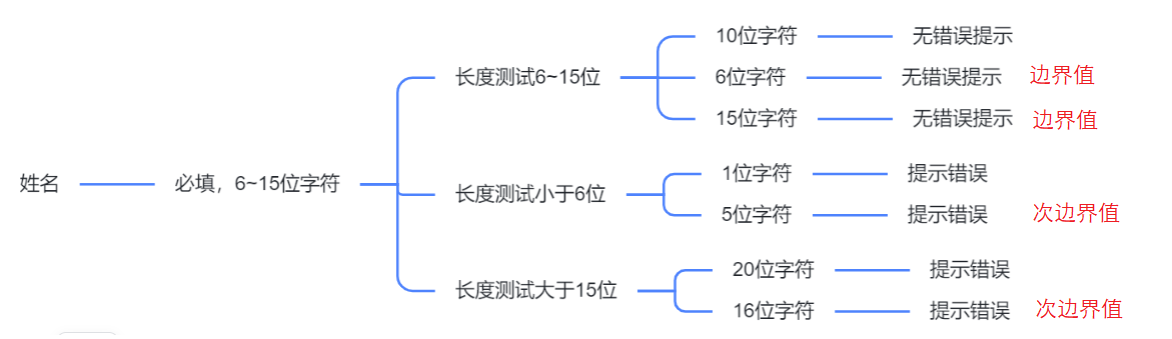
以 "邮箱注册" 的 "姓名" 字段(需求:6~15 位字符)为例:
- 确定边界值和次边界值 :
- 边界值:6 位、15 位;
- 次边界值:5 位(6-1)、16 位(15+1);
- 设计测试用例 :
优缺点
- 优点:针对性强,能快速发现边界处的 bug,补充等价类的不足;
- 缺点:只关注单个输入的边界,不考虑多输入组合的边界场景。
2.3 正交法:解决 "多输入组合" 的冗余问题
适用场景
当测试场景涉及 "多因素、多水平" 的组合时,比如 "邮箱注册" 的 5 个必填项(姓名、邮箱、密码、确认密码、验证码),每个字段都有 "填写" 和 "不填写" 两种状态,若用排列组合法设计用例,需要 2^5=32 个用例,冗余严重。正交法能通过 "选取代表性组合",用最少的用例覆盖所有两两组合,大幅提高测试效率。
核心逻辑
正交法源于 "正交试验设计",核心是:从所有可能的组合中,选取部分有代表性的组合进行测试,这些组合能覆盖所有因素的两两组合,且无重复、无冗余。
正交表是正交法的核心工具,比如最简单的正交表 L₄(2³):
- L:代表正交表;
- 4:表示 4 行,即需要设计 4 个测试用例;
- 2:表示 2 种水平(如 "填写""不填写");
- 3:表示 3 列,即最多支持 3 个因素(如 3 个输入字段)。
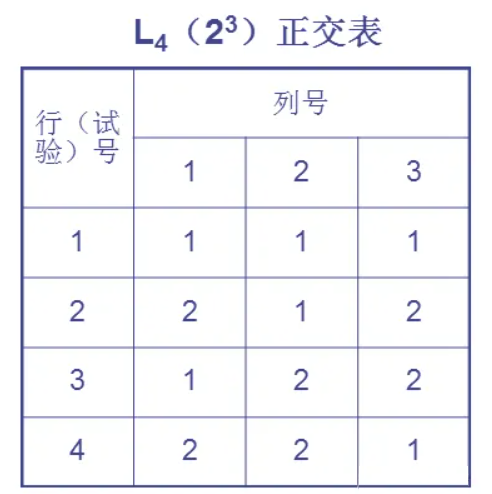
正交表的关键性质:
- 每一列中,不同水平出现的次数相等;
- 任意两列中,水平的组合方式齐全且均衡。
操作步骤 + 实战案例
以 "邮箱注册" 的 5 个必填项(因素:姓名、邮箱、密码、确认密码、验证码;水平:填写、不填写)为例:
- 确定因素和水平 :
- 因素:姓名(A)、邮箱(B)、密码(C)、确认密码(D)、验证码(E);
- 水平:1 = 填写,2 = 不填写;
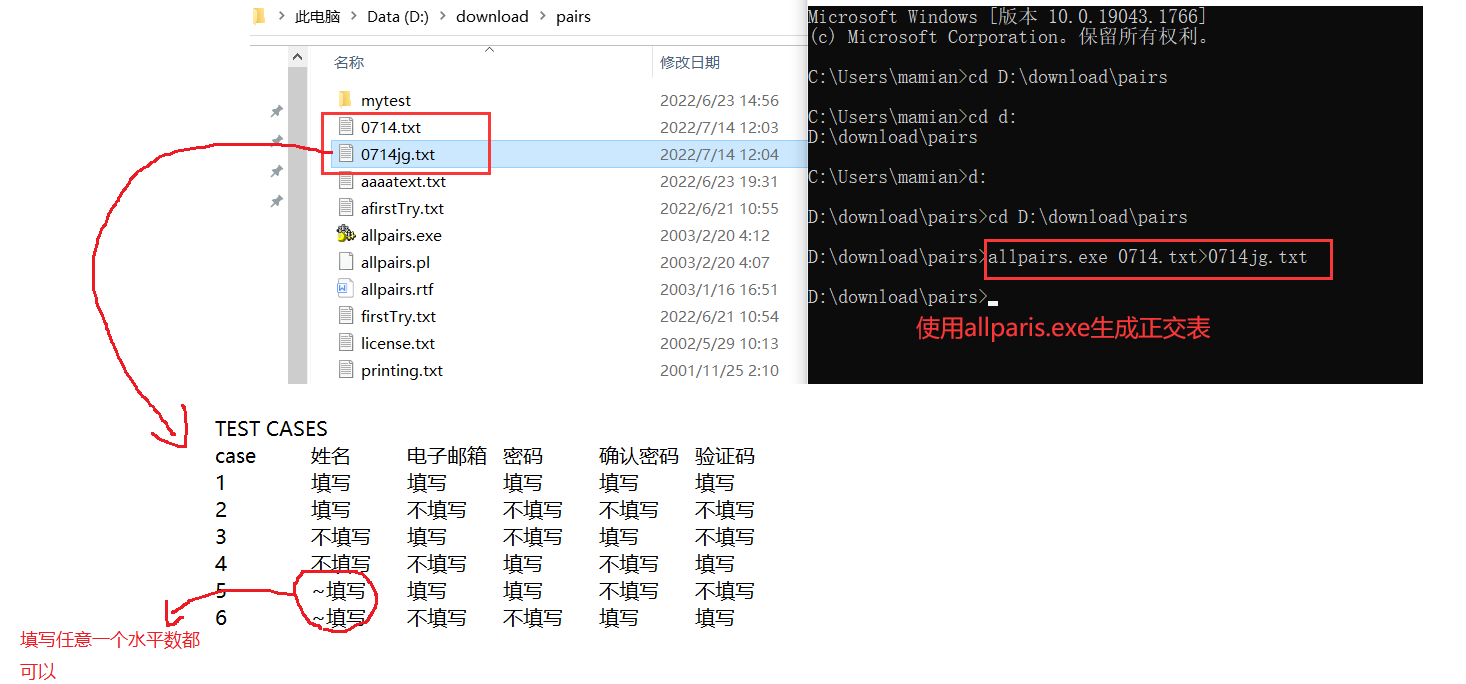
- 生成正交表 :由于手动设计正交表复杂,实际工作中常用 allpairs工具(专门用于生成正交表 的工具)生成:a. 新建 Excel,录入因素和水平;b. 复制到 allpairs 目录下的文本文件(如 0714.txt);c. 执行命令:allparis.exe 0714.txt>0714jg.txt,生成正交表;
 根据正交表编写测试用例 :从生成的正交表中,选取代表性组合,比如:
根据正交表编写测试用例 :从生成的正交表中,选取代表性组合,比如:
- 用例 1:A = 填写,B = 填写,C = 填写,D = 填写,E = 填写(全部填写);
- 用例 2:A = 填写,B = 不填写,C = 填写,D = 填写,E = 填写(不填写邮箱);
- 用例 3:A = 不填写,B = 填写,C = 不填写,D = 填写,E = 填写(不填写姓名、密码);
- 补充遗漏用例:正交表可能遗漏关键组合,此时需要手动补充。
优缺点
- 优点:大幅减少多因素组合的用例数量,覆盖全面且高效;
- 缺点:需要借助工具生成正交表,对新手有一定门槛。
2.4 判定表法:理清 "多条件组合触发不同结果" 的逻辑
适用场景
当需求中存在 "多条件组合触发不同结果" 的逻辑时,比如 "账号包含 admin 字符,或通过内部链接进入注册页面,且点击注册按钮→成为管理员",这种场景用正交法无法清晰表达,而判定表法能通过表格形式,将所有条件组合与结果的对应关系梳理清楚,避免逻辑遗漏。
核心逻辑
判定表法的核心是:将输入条件和输出结果作为表格的行和列,列出所有可能的条件组合,再根据需求明确每个组合对应的结果,最后根据表格编写测试用例。
判定表的构成:
- 条件桩:所有输入条件(如 "账号包含 admin""通过内部链接""点击注册按钮");
- 动作桩:所有输出结果(如 "成为管理员""不成为管理员");
- 条件项:每个条件的取值(如 "是""否");
- 动作项:每个条件组合对应的结果(如 "是""否")。
操作步骤 + 实战案例
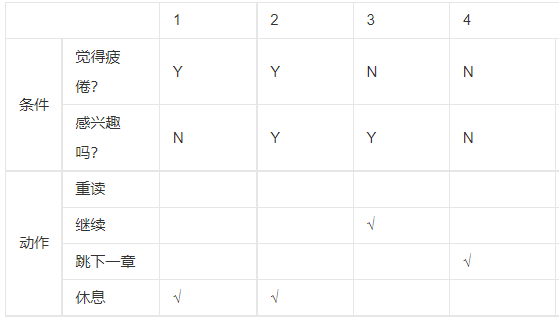
以需求 "账号包含 admin 字符(a),或通过内部链接进入注册页面(b),且点击注册按钮(c)→成为管理员(1);反之→不成为管理员(2)" 为例:
- 确定条件桩和动作桩 :
- 条件桩:a(账号含 admin)、b(内部链接)、c(点击注册);
- 动作桩:1(管理员)、2(非管理员);
- 列出所有条件组合(共 2^3=8 种);
- 明确每个组合对应的动作项 :

- 根据判定表编写测试用例 :
- 用例 1:账号含 admin,通过内部链接,点击注册→成为管理员;
- 用例 2:账号含 admin,通过内部链接,不点击注册→非管理员;
- 用例 3:账号含 admin,非内部链接,点击注册→成为管理员;
- 以此类推,覆盖所有 8 种组合。
优缺点
- 优点:逻辑清晰,无遗漏,能快速覆盖所有条件组合场景;
- 缺点:当条件数量过多时(如超过 5 个),组合数量会呈指数增长,表格会变得庞大。
2.5 场景法:模拟 "真实业务流程",覆盖端到端场景
适用场景
现在的软件大多是 "事件触发" 的流程化产品,比如 "下单→支付→发货→收货""注册→登录→完善信息"。场景法能模拟用户真实使用的业务流程,将孤立的功能点串起来,覆盖端到端的场景,避免陷入 "只测单个功能,忽略流程联动" 的误区。
核心逻辑
场景法的核心是:将业务流程拆分为 "基本流" 和 "备选流",通过遍历所有基本流和备选流的组合,设计测试用例。
- 基本流:正常的业务流程(用户最常使用的流程),比如 "注册→登录→完善信息";
- 备选流:业务流程中出现的异常或分支场景,比如 "注册时验证码错误""登录时密码错误""网络异常"。
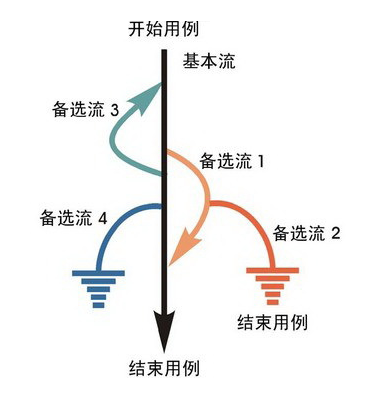
生活类比
以 "逛街买衣服" 为例:
- 基本流:逛街→去服装店→选衣服→买衣服;
- 备选流:逛街时突然下雨(不逛了)、服装店没喜欢的衣服(换一家)、衣服价格太贵(不买了)。场景法就是要覆盖 "基本流 + 所有备选流" 的组合。
操作步骤 + 实战案例
以 "邮箱注册" 的业务流程为例:
- 确定基本流:同意协议→填写正确信息→提交→发送激活邮件→24 小时内激活→注册成功;
- 确定备选流 :
- 备选流 1:不同意协议→无法进入填写页面;
- 备选流 2:填写信息为空→提示重新输入;
- 备选流 3:验证码错误→提示 "验证码错误";
- 备选流 4:未收到激活邮件→重新发送;
- 备选流 5:激活邮件超时(超过 24 小时)→链接失效;
- 备选流 6:网络异常→发送邮件失败;
- 设计测试用例 :遍历基本流和备选流的组合,比如:
- 用例 1:基本流(所有步骤正常)→注册成功;
- 用例 2:备选流 1(不同意协议)→无法进入填写页面;
- 用例 3:基本流到 "填写信息"→触发备选流 2(信息为空)→提示重新输入;
- 用例 4:基本流到 "发送激活邮件"→触发备选流 6(网络异常)→提示 "发送失败,请重试";
- 补充异常场景:比如 "激活邮件已发送,再次发送是否成功""激活后再次点击激活链接是否提示已激活"。
优缺点
- 优点:贴近用户真实使用场景,能发现流程联动中的 bug,覆盖全面;
- 缺点:对业务流程的梳理要求高,需要测试人员具备较强的发散思维。
2.6 错误猜测法:基于经验,快速定位 "高频 bug 场景"
适用场景
错误猜测法没有固定的流程,核心是 "基于对产品的理解、过往经验和直觉,推测出软件可能存在的缺陷,从而针对性地设计测试用例"。这种方法在敏捷开发、探索式测试中非常常用,能快速定位高频 bug 场景。
核心逻辑
错误猜测法的核心是 "换位思考"------ 站在 "开发者可能犯的错误" 和 "用户可能的误操作" 角度,推测 bug 可能出现的地方。比如:
- 开发者可能忽略的场景:特殊字符、空值、重复提交、大小写敏感;
- 用户可能的误操作:输入空格、连续点击按钮、网络中断后重试。
生活类比
提到 "武大郎卖瓜",我们会猜测 "他可能缺斤少两";提到 "张三粗心",我们会猜测 "他的瓜可能被压坏"------ 错误猜测法就是基于 "对事物的了解",推测可能出现的问题。
实战案例
以 "邮箱注册" 为例,错误猜测法可设计以下测试用例:
- 姓名包含空格(如 "张三 李四")→验证是否能正常提交;
- 密码输入时包含大小写(如 "123ABC")→验证是否区分大小写;
- 连续点击 "注册" 按钮→验证是否重复提交;
- 验证码输入时包含空格(如 "6666")→验证是否自动去空格或提示错误;
- 密码传输过程中是否明文显示(如通过抓包查看);
- 注册成功后,用相同邮箱再次注册→验证是否提示 "该邮箱已注册"。
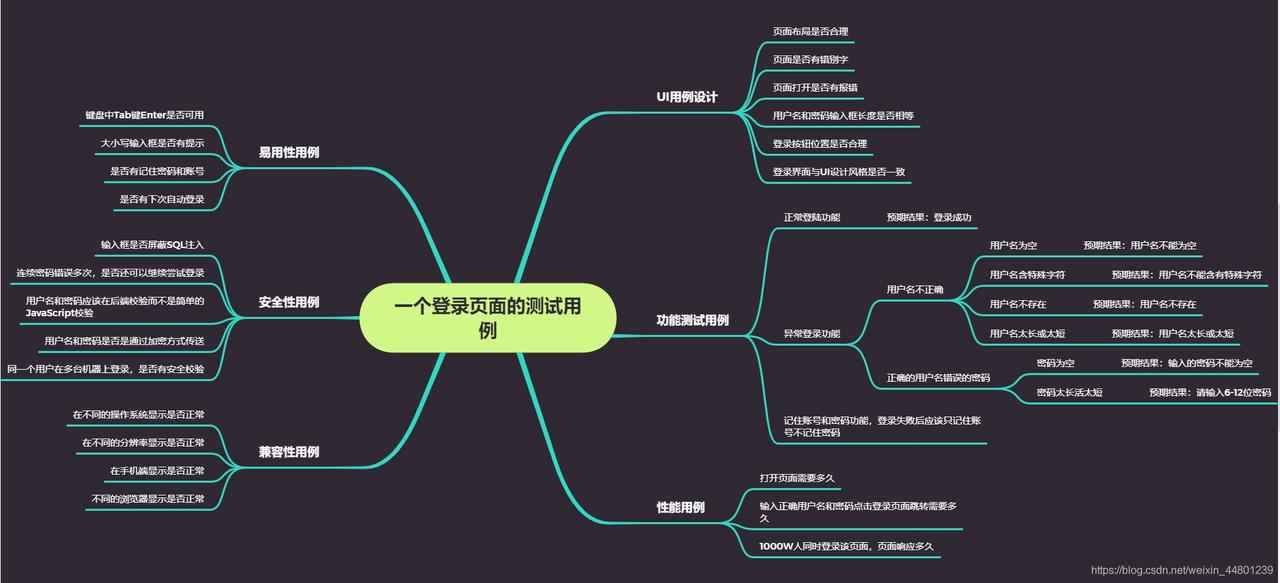
优缺点
- 优点:高效快捷,能快速覆盖高频 bug 场景,投入产出比高;
- 缺点:依赖个人经验和直觉,难以系统化,容易遗漏场景,适合作为其他方法的补充。
三、不同场景实战演练:命令行程序 + Web 接口
掌握了 6 大核心方法后,我们需要结合具体场景灵活运用。下面以 "命令行程序(zip 命令)" 和 "Web 接口(博客详情页)" 为例,演示如何综合运用上述方法设计测试用例。
3.1 命令行程序:zip/unzip 命令的测试用例设计
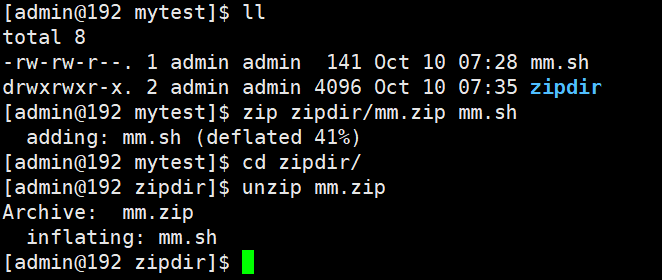
需求分析
功能:通过 zip 命令压缩文件 / 文件夹,unzip 命令解压文件;约束条件:支持多种文件类型(txt、图片、视频等),支持单个 / 多个文件压缩,支持空文件夹压缩。
综合运用方法:等价类 + 边界值 + 错误猜测法
测试用例设计
- 功能测试 :
- 有效等价类 :
- 压缩单个 txt 文件→生成 zip 文件,解压后文件内容一致;
- 压缩多个混合文件(txt + 图片 + 视频)→生成 zip 文件,解压后所有文件完整;
- 压缩空文件夹→生成 zip 文件(大小合理),解压后为空文件夹;
- 解压正常的 zip 文件→文件完整,无损坏;
- 无效等价类 :
- 压缩不存在的文件→提示 "文件不存在";
- 压缩已压缩的 zip 文件→验证是否能正常压缩(覆盖或生成新文件);
- 解压损坏的 zip 文件→提示 "文件损坏,无法解压";
- 错误命令(如 "zip zip""unzip 无文件名")→提示 "命令格式错误";
- 错误猜测法 :
- 压缩超过 1G 的大文件→验证是否能正常压缩,耗时是否合理;
- 压缩路径包含特殊字符(如 @、#)→验证是否能正常压缩;
- 同时压缩多个同名文件→验证是否覆盖或重命名;
- 界面测试(命令行提示) :
- 压缩成功→提示 "adding: 文件名 (deflated xx%)",文案清晰;
- 压缩失败→提示友好(如 "file not found"),无乱码;
- 性能测试 :
- 压缩 1G 文件→耗时≤5 分钟(根据实际情况调整);
- 同时压缩 10 个文件→系统无崩溃,无卡顿;
- 兼容性测试 :
- 在 Windows、Linux、Mac 系统上→均能正常使用;
- 易用性测试 :
- 输入 "zip --help"→显示帮助文档,包含命令格式、参数说明;
- 安全性测试 :
- 压缩加密文件→解压后仍需密码,文件内容不泄露。
3.2 Web 接口:博客详情页接口的测试用例设计
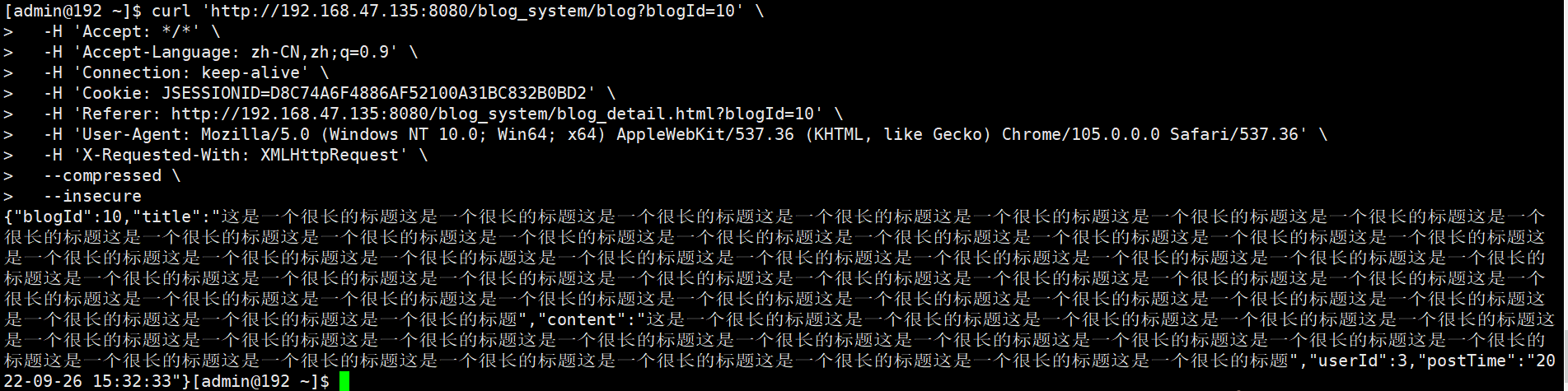
需求分析
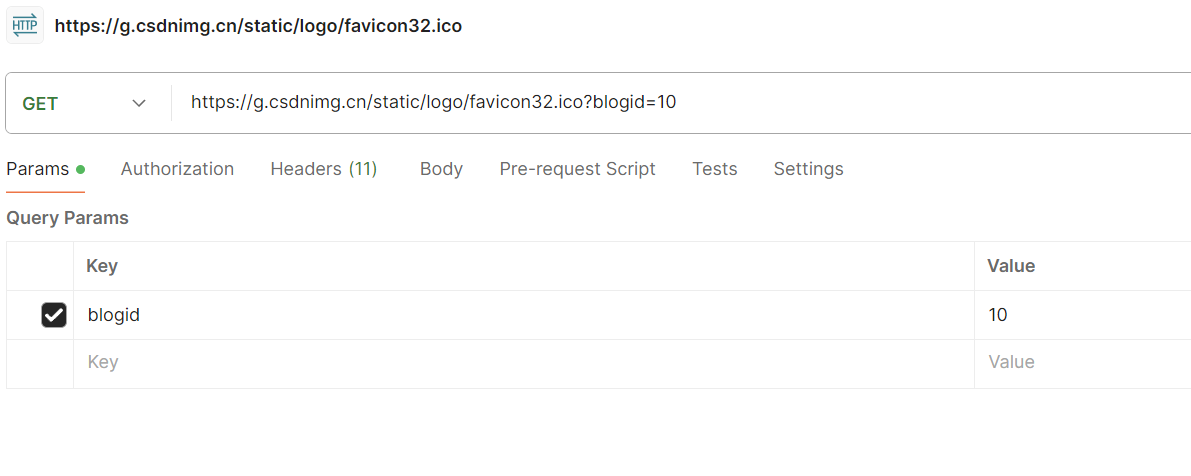
接口地址:http://192.168.47.135:8080/blog_system/blog?blogId=10;功能:通过 blogId 查询博客详情,支持 GET 请求;约束条件:blogId 为数字,必填;博客存在则返回详情,不存在则返回 "博客不存在"。
综合运用方法:等价类 + 边界值 + 场景法 + 错误猜测法
测试用例设计
- 功能测试 :
- 有效等价类 :
- blogId 为存在的数字(如 10)→返回对应博客详情(标题、内容、作者等完整);
- blogId 为存在的边界值(如 1、999)→返回对应博客详情;
- 无效等价类 :
- blogId 为空→返回 "blogId 不能为空";
- blogId 为非数字(如 "abc""123a")→返回 "blogId 格式错误";
- blogId 为不存在的数字(如 9999)→返回 "博客不存在";
- blogId 为负数(如 - 10)→返回 "blogId 格式错误";
- blogId 为超长数字(如 10000000000)→返回 "博客不存在" 或 "格式错误";
- 错误猜测法 :
- blogId 包含空格(如 "10")→返回 "格式错误" 或自动去空格查询;
- 连续发送 1000 次请求→接口无崩溃,返回正常;
- 同时发送 1000 个并发请求→接口响应正常,无数据错乱;
- 接口请求方式 :
- 用 GET 方式请求→返回正常;
- 用 POST 方式请求→返回 "请求方式不支持";
- 参数格式 :
- url 拼参(?blogId=10)→返回正常;
- form-data 格式传递 blogId→返回 "参数格式错误";
- raw 格式(JSON)传递 blogId→返回 "参数格式错误";
- 性能测试 :
- 单次请求响应时间≤200ms;
- 10000 个并发请求→响应时间≤1s,无超时;
- 持续 24 小时请求→接口正常运行,无内存泄漏;
- 兼容性测试 :
- 在 Chrome、Firefox、Safari 等浏览器中→请求正常;
- 在移动端(iOS、Android)→请求正常;
- 安全测试 :
- 传递 SQL 注入语句(如 blogId=10 or 1=1)→接口拦截,返回 "参数非法";
- 传递 XSS 攻击脚本(如 blogId=<script>alert(1)</script>)→接口拦截,返回 "参数非法"。
接口测试工具:Postman 的使用技巧
实际工作中,我们常用 Postman 工具执行接口测试,提高效率:

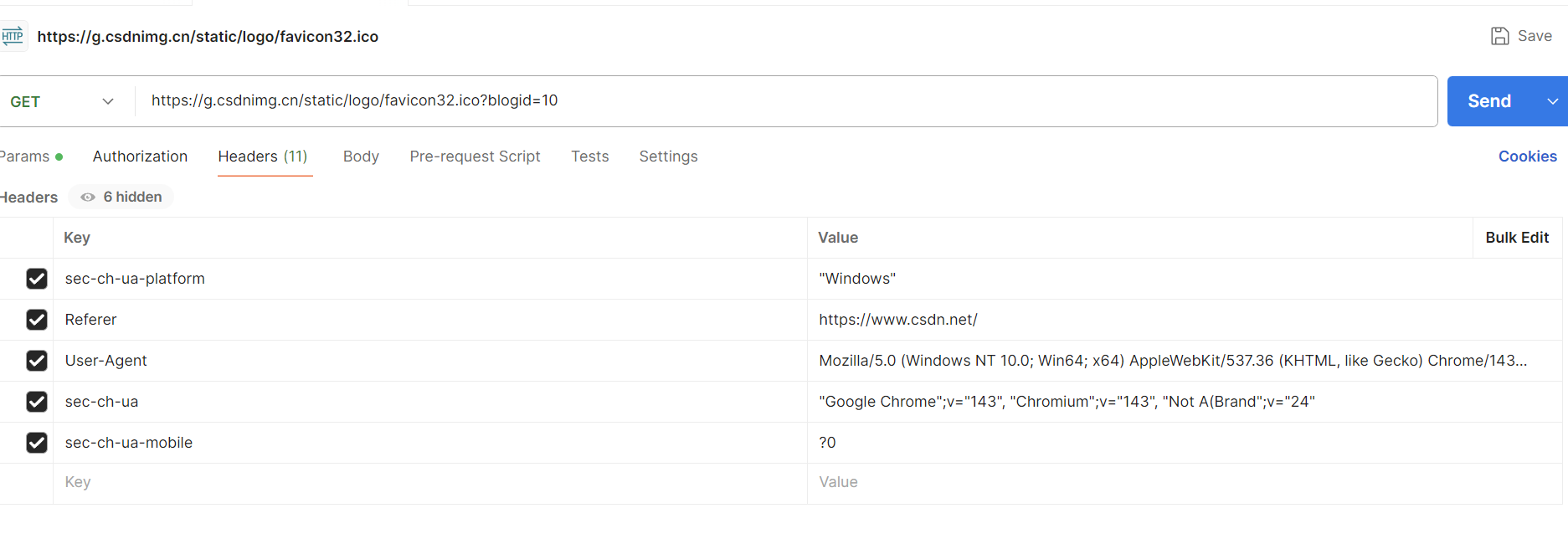
- 导入请求 :
- 打开浏览器开发者工具(右键,选择"检查");
- 选中接口→右键 "Copy as cURL (bash)";
- 打开 Postman→点击 "Import"→选择 "Raw text"→粘贴 cURL 命令→导入成功;
- 编辑参数 :
- 在 "Params" 中修改 blogId 的值(如 10、abc、9999);
- 在 "Headers" 中添加必要的请求头(如 Content-Type、Token);
- 批量执行 :
- 将所有测试用例的参数整理成 CSV 文件;
- 在 Postman 中创建 "Collection"→添加接口→配置 "Data"→运行批量测试;
- 保存接口:测试完成后,将接口保存到对应文件夹(如 "博客系统 - 详情页接口"),方便后续回归测试复用。
总结
核心原则可以总结为:"基于需求定范围,用等价类 + 边界值覆盖单个场景,用正交法 + 判定表覆盖组合场景,用场景法覆盖流程场景,用错误猜测法补充高频 bug"。
掌握了这些方法,无论面对命令行程序、Web 接口、移动端 App 还是 PC 端软件,都能快速设计出全面、高效的测试用例,告别 "测试不全""背锅返工" 的烦恼。
如果觉得这篇文章对你有帮助,欢迎点赞、收藏、转发,也可以在评论区分享你的测试用例设计经验!