一、实验代码
百度网盘:
链接:
https://pan.baidu.com/s/1V8CnEWi_BqOsCGqkU3G5Yw?pwd=9999
提取码: 9999二、实验报告
实验一 词法分析
实验名称
词法分析程序的构造
实验内容
对于给定的符合C语言文法所定义的一段程序,使用高级语言(c、c++、java、python)编写程序完成下列内容:
1、根据DFA识别所有的标识符。
2、根据DFA识别所有的常数(至少包含整数)。
3、根据DFA识别C语言中定义的所有关键字(按照32个来做)
4、根据DFA识别C语言中的所有界符。
5、根据DFA识别C语言中的所有运算符。
实验目的
1、了解词法分析的任务。
2、掌握构造识别各类单词自动机的方法及过程。
3、掌握符号表的建立及单词的分类方法。
4、掌握词法分析程序的基本原理与构造方法。
实验程序代码
java
package com.hd.sy1;
import java.util.*;
import java.io.*;
/*
1 关键字2 界符 3 算术运算符
4 关系运算符5 常数 6 标识符
*/
public class WordAnalysisTest {
static String[] k = {"do", "then", "if", "printf", "while", "break", "case", "char", "const","continue", "default", "double", "else", "float", "int", "long", "return", "short","signed", "sizeof", "static", "switch", "typedef", "unsigned", "void", "main"};//1 关键字
static char[] s = {',', ';', '(', ')', '[', ']', '{', '}'};//2 界符
static char[] m = {'+', '-', '*', '/'};//3 算术运算符
static String[] r = {"<", "<=", "=", ">", ">=", "<>"};//4 关系运算符
ArrayList<String> ci = new ArrayList<>();//5 常数
ArrayList<String> id = new ArrayList<>();//6 标识符
int pint;// 搜索指示器
String strToken = "";// 存放构成单词符号的字符串
char ch;// 存放最新读入源程序字符
String inString;// 存放输入源程序
public static void main(String[] args) throws Exception {
WordAnalysisTest one = new WordAnalysisTest();
System.out.println("********** 二 元 组 **********");
one.readText();
}
// 判断字符 c是否是数字
public boolean isDigit(char c) {
return c >= 48 && c <= 57;
}
// 判断字符 c是否是字母
public boolean isLetter(char c) {
return (c > 64 && c < 91) || (c > 96 && c < 123);
}
// 判断字符 c是否是下划线
public boolean isLine(char c) {
return c == '_';
}
public boolean remove() {// 用于在判断关系运算符时,判断是否是要再读一个字符
char b = inString.charAt(pint + 1);
// 当其后的字符是 =或>时, 要再读一个字符。否则不要再读。
return b == '=' || b == '>';
}
public boolean sreMove() {//用于判断算数运算符时,是否需要再读一个字符
char b = inString.charAt(pint);
char bn = inString.charAt(pint + 1);
String s = Character.toString(b) + Character.toString(bn);
return "++".equals(s) || "--".equals(s);
}
public void getBc() {// 检查空白直到读入字符非空白
while (ch == ' ') {
getChar();
}
}
public void getChar() {// 读入下一个字符
pint++;
if (pint <= inString.length() - 1) {// 当指针没有越界时, 可读字符
ch = inString.charAt(pint);
if (ch == '\n') {// 当读到换行符时。再读下一个字符
getChar();
}
} else ch = ' ';// 当指针越界时,置 ch为空白符
}
public void retract() {// 读入前一个字符
pint--;
ch = inString.charAt(pint);
}
public void words() {// 识别字符串
strToken = "";// 先将strToken 置空
while (isLetter(ch) || isDigit(ch) || isLine(ch)) {// 当是字母,数字,下划线时继续识别字符串
strToken = strToken + ch;// 将新识别的字符加到 strToken后
getChar();
}
}
public void num() {// 识别数字串
strToken = "";// 先将strToken 置空
while (isDigit(ch)) {// 当数字时继续识别数字串
strToken = strToken + ch;// 将新识别的字符加到 strToken后
getChar();
}
if (isLetter(ch) || isLine(ch)) {// 识别完数字串而其后是字母,下划线时出错处理
while (isLetter(ch) || isLine(ch) || isDigit(ch)) {// 当是字母,数字,下划线时继续识别错误数字串
strToken = strToken + ch;// 将 新 识 别 的 字 符 加 到strToken 后
getChar();
}
show(0, strToken, ' ');// 输出错误数字串
strToken = "";// 将strToken 置空返回
}
}
public void show(int i, String s, char a) {// 各种输出处理
switch (i) {
case -1:
System.out.println(a + " " + "Error" + " Error ");
break;
case 0:
System.out.println(s + " " + "Error" + " Error ");
break;
case 1:
System.out.println(s + " \t" + " (1," + s + ") " + " 关键字");
break;
case 2:
System.out.println(a + " \t" + " (2," + a + ") " + " 界符");
break;
case 3:
System.out.println(a + " \t" + " (3," + a + ") " + " 算术运算符");
break;
case 4:
System.out.println(s + " \t" + " (4," + s + ") " + " 关系运算符");
break;
case 5:
System.out.println(s + " \t" + " (5," + s + ") " + " 常数");
break;
case 6:
System.out.println(s + " \t" + " (6," + s + ") " + " 标识符");
break;
}
}
public void handle() {// 输入串处理
pint = -1;// 将搜索指示器置 -1
System.out.println("-----要处理的语句为: " + inString);
getChar();// 读入一个字符
while (pint < inString.length()) {// 当搜索指示器没有越界时
getBc();// 检查空白直到读入读入非空
if (isDigit(ch)) {// 当ch为数字时进行数字串识别
num();// 数字串识别
if (strToken.length() != 0) {// 经过数字串识别后,如果strToken 不为空
// 输出数字串
if (reservesCi(strToken) == -1) {// 如果 strToken 不在 ci 中,将 strToken 加入ci 表中
ci.add(strToken);// 将strToken 加入ci 表中
}
show(5, strToken, ' ');// 输出数字串
// 拼出数字串
}
} else if (isLetter(ch)) {// 当ch为字母时进行字符串识别
words();// 字符串识别
if (reserve(strToken) == -1) {// 如果 strToken 不在 k表中
// 输出标识串
if (reservedId(strToken) == -1) {// 如果 strToken 不 在id 表中
id.add(strToken);// 将strToken 加入id 表中
}
show(6, strToken, ' ');// 输出标识串
} else {// 如果strToken 在k表中
show(1, strToken, ' ');// 输出关键字
}
// 拼出字符串
} else if (in_s(ch) != -1) {
// 分界符处理包含在 in_s(ch) 中
} else if (in_m(ch) != -1) {
// 算术运算符处理包含在 in_m(ch) 中
} else if (in_k(ch) != -1) {
// 关系运算符处理包含在 in_k(ch) 中
} else {
show(-1, "", ch);//error
getChar();// 读下一位
}
}
}
public int reserve(String s) {// 判断字符串是否是关键字
int i;
for (i = 0; i < k.length; i++) {
if (s.equals(k[i])) {
return i;// 是保留字,就返回编码
}
}
return -1;// 不是保留字,就返回 -1
}
public int reservedId(String s) {// 判断识别的标志符是否已经在 id 表 中
int i;
for (i = 0; i < id.size(); i++) {
if (s.equals(id.get(i)))
return i;// 识别的标志符已经在 id 表中,返回位置
}
return -1;// 识别的标志符不在 id 表中,返回 -1
}
public int reservesCi(String s) {// 判断识别的数字串是否已经在 ci 表 中
int i;
for (i = 0; i < ci.size(); i++) {
if (s.equals(ci.get(i)))
return i;// 识别的数字串已经在 ci 表中,返回位置
}
return -1;// 识别的数字串不在 ci 表中,返回 -1
}
public int in_s(char c) {// 查找界符
int i;
for (i = 0; i < s.length; i++) {
if (c == s[i]) {// 与某个分界符配备时
show(2, "", c);// 输出分界符
getChar();// 读下一位
return i;// 返回所在位置
}
}
return -1;// 不在分界符表中
}
public int in_m(char c) {// 查找算术运算符
int i;
if (!sreMove()) {
for (i = 0; i < m.length; i++)
if (c == m[i]) {// 与某个算术运算符配备时
show(3, "", c);// 输出算术运算符
getChar();// 读下一位
return i;// 返回所在位置
}
} else {
char[] a = new char[2];// 将两位字符放入 a中
a[0] = c;
getChar();
a[1] = ch;
show(0, String.valueOf(a), ' ');
getChar();
return 0;
}
return -1;// 不在算术运算符表中
}
public int in_k(char b) {// 查找关系运算符
int i;
if (!remove()) {// 读下一位为假时, 进行一位关系运算符识别
for (i = 0; i < r.length; i++)
if (r[i].length() == 1) {// 当关系运算符为一位时,尝试匹配
if (r[i].equals(Character.toString(b))) {
show(4, r[i], ' ');// 输出关系运算符
getChar();// 读下一位
return i;// 返回所在位置
}
}
} else {// 读下一位为真时,进行两位关系运算符识别
char[] a = new char[2];// 将两位字符放入 a中
a[0] = b;
getChar();
a[1] = ch;
for (i = 0; i < r.length; i++)
if (r[i].length() == 2) {// 当关系运算符为两位时, 尝试匹配
if (r[i].equals(String.copyValueOf(a))) {
show(4, r[i], ' ');// 输出关系运算符
getChar();// 读下一位
return i;// 返回所在位置
}
}
retract();// 两位关系运算符匹配失败,读入前一个字符
}
return -1;// 不在关系运算表中
}
public void readText() throws Exception {// 从文本读入源程序
BufferedReader f = new BufferedReader(new FileReader("D:\\experimentDemo\\rjGouZao\\test.txt"));
inString = f.readLine();
while (inString != null) {
handle();// 处理读入的源程序
inString = f.readLine();
}
f.close();
}
}实验数据及结果
1、实验数据
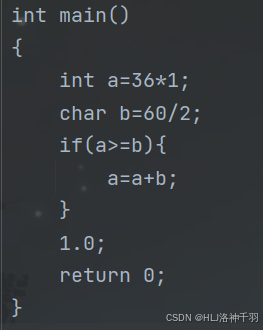
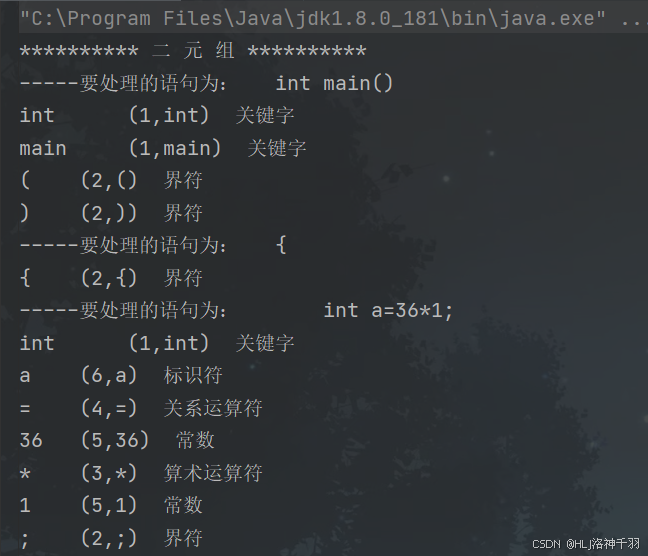
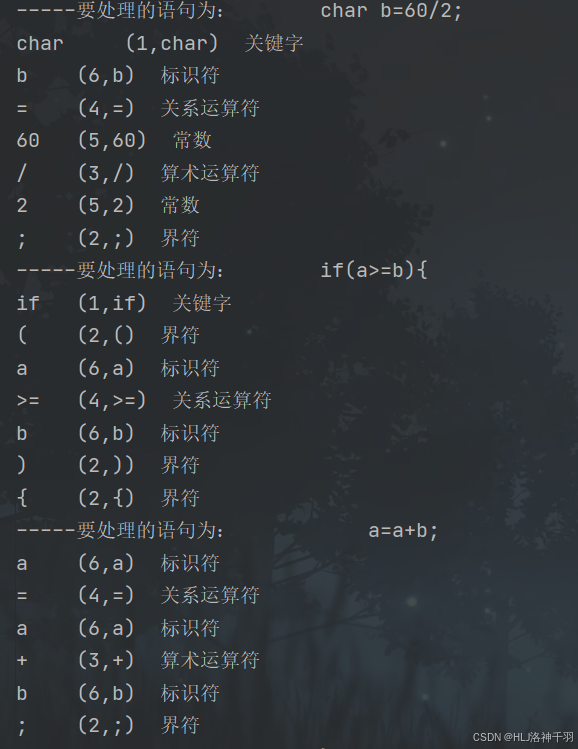
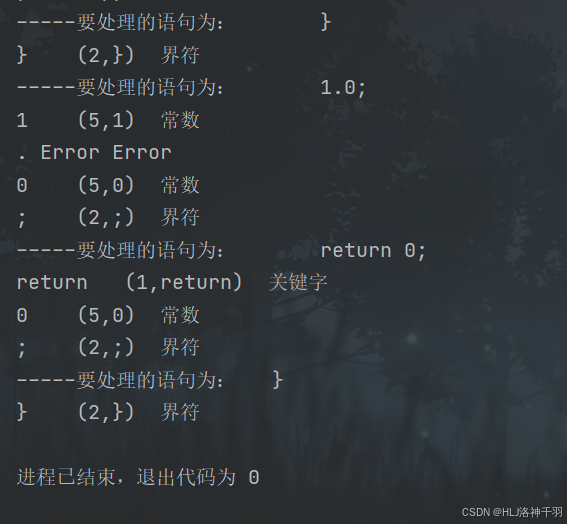
2、实验结果
实验小结
通过这次实验,我对词法分析有了更深的理解,词法分析程序简单来说就是"读单词程序",该程序扫描高级语言编写的源程序,将源程序中由"单词符号"组成的字符串分解出一个个单词来。
单词符号分为5种:
1、保留字:例如C语言中的if、else、while、do等等
2、标识符:通常由用户自己定义。用来标记常量、数组、变量、类型等等。a,b,c等
3、常数:整型常数369、布尔常数TRUE等
4、运算符:如"+、-、*、/、<、>"
5、界符:在语言中是作为语法上的分界符号使用的,如","";""("")"等
词法分析器例子:
输入内容:源程序字符串。
例如"int a=1;a++;"
输出内容:输出的是与源程序等价的单词符号序列,并且所输出的单词符号通常表示成如下的二元式:
(单词种别,单词自身的词)
实验二 语法分析
实验名称
语法分析程序的构造
实验内容
对于某个给定的表达式文法(满足LL(1)文法的条件),使用高级语言(c、c++、java、python)编写程序,完成下列内容:
1、计算文法中每个文法符号以及每个产生式右部符号串的FIRST集。
2、计算文法中每个非终结符的FOLLOW集。
3、计算文法中每个产生式的SELECT集。
4、构造预测分析表设计算法编程实现判断输入的符号串是否满足文法定义。
实验目的
1、掌握LL(1)分析法的基本原理。
2、掌握FIRST集、FOLLOW集、SELECT集的计算方法和过程。
3、掌握预测分析表的构造方法。
4、掌握使用预测分析表进行语法分析的过程。
实验程序代码
java
package com.hd.sy2;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Iterator;
import java.util.LinkedList;
import java.util.Queue;
import java.util.Scanner;
import java.util.Set;
import java.util.Stack;
public class Parser {
public static final String PATH = "src/com/hd/sy2/b.txt";// 文法
private static String START; // 开始符号
private static HashSet<String> VN, VT; // 非终结符号集、终结符号集
private static HashMap<String, ArrayList<ArrayList<String>>> MAP;// key:产生式左边 value:产生式右边(含多条)
private static HashMap<String, String> oneLeftFirst;// "|" 分开的单条产生式对应的FIRST集合,用于构建预测分析表
private static HashMap<String, HashSet<String>> FIRST, FOLLOW; // FIRST、FOLLOW集合
private static String[][] FORM; // 存放预测分析表的数组,用于输出
private static HashMap<String, String> preMap;// 存放预测分析表的map,用于快速查找
public static void main(String[] args) {
init(); // 初始化变量
identifyVnVt(readFile(new File(PATH)));// 符号分类,并以key-value形式存于MAP中
reformMap();// 消除左递归和提取左公因子
findFirst(); // 求FIRST集合
findFollow(); // 求FOLLOW集合
if (isLL1()) {
preForm(); // 构建预测分析表
System.out.println("请输入要分析的单词串:");
Scanner in = new Scanner(System.in);
printAutoPre(in.nextLine());
in.close();
}
}
// 变量初始化
private static void init() {
VN = new HashSet<>();
VT = new HashSet<>();
MAP = new HashMap<>();
FIRST = new HashMap<>();
FOLLOW = new HashMap<>();
oneLeftFirst = new HashMap<>();
preMap = new HashMap<>();
}
// 判断是否是LL(1)文法
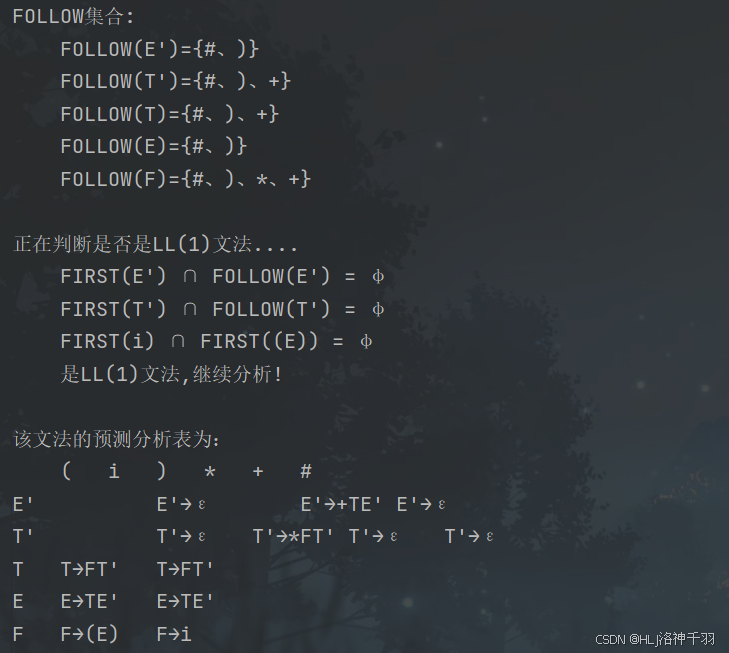
private static boolean isLL1() {
System.out.println("\n正在判断是否是LL(1)文法....");
boolean flag = true;// 标记是否是LL(1)文法
Iterator<String> it = VN.iterator();
while (it.hasNext()) {
String key = it.next();
ArrayList<ArrayList<String>> list = MAP.get(key);// 单条产生式
if (list.size() > 1) // 如果单条产生式的左边包含两个式子以上,则进行判断
for (int i = 0; i < list.size(); i++) {
String aLeft = String.join("", list.get(i).toArray(new String[0]));
for (int j = i + 1; j < list.size(); j++) {
String bLeft = String.join("", list.get(j).toArray(new String[0]));
if (aLeft.equals("ε") || bLeft.equals("ε")) { // (1)若b=ε,则要FIRST(A)∩FOLLOW(A)=φ
HashSet<String> retainSet = new HashSet<>();
// retainSet=FIRST.get(key);//需要要深拷贝,否则修改retainSet时FIRST同样会被修改
retainSet.addAll(FIRST.get(key));
if (FOLLOW.get(key) != null)
retainSet.retainAll(FOLLOW.get(key));
if (!retainSet.isEmpty()) {
flag = false;// 不是LL(1)文法,输出FIRST(a)FOLLOW(a)的交集
System.out.println("\tFIRST(" + key + ") ∩ FOLLOW(" + key + ") = {"
+ String.join("、", retainSet.toArray(new String[0])) + "}");
break;
} else {
System.out.println("\tFIRST(" + key + ") ∩ FOLLOW(" + key + ") = φ");
}
} else { // (2)b!=ε若,则要FIRST(a)∩FIRST(b)= Ф
HashSet<String> retainSet = new HashSet<>();
retainSet.addAll(FIRST.get(key + "→" + aLeft));
retainSet.retainAll(FIRST.get(key + "→" + bLeft));
if (!retainSet.isEmpty()) {
flag = false;// 不是LL(1)文法,输出FIRST(a)FIRST(b)的交集
System.out.println("\tFIRST(" + aLeft + ") ∩ FIRST(" + bLeft + ") = {"
+ String.join("、", retainSet.toArray(new String[0])) + "}");
break;
} else {
System.out.println("\tFIRST(" + aLeft + ") ∩ FIRST(" + bLeft + ") = φ");
}
}
}
}
}
if (flag)
System.out.println("\t是LL(1)文法,继续分析!");
else
System.out.println("\t不是LL(1)文法,退出分析!");
return flag;
}
// 构建预测分析表FORM
public static void preForm() {
HashSet<String> set = new HashSet<>(VT);
set.remove("ε");
FORM = new String[VN.size() + 1][set.size() + 2];
Iterator<String> itVn = VN.iterator();
Iterator<String> itVt = set.iterator();
// (1)初始化FORM,并根据oneLeftFirst(VN$VT,产生式)填表
for (int i = 0; i < FORM.length; i++)
for (int j = 0; j < FORM[0].length; j++) {
if (i == 0 && j > 0) {// 第一行为Vt
if (itVt.hasNext()) {
FORM[i][j] = itVt.next();
}
if (j == FORM[0].length - 1)// 最后一列加入#
FORM[i][j] = "#";
}
if (j == 0 && i > 0) {// 第一列为Vn
if (itVn.hasNext())
FORM[i][j] = itVn.next();
}
if (i > 0 && j > 0) {// 其他情况先根据oneLeftFirst填表
String oneLeftKey = FORM[i][0] + "$" + FORM[0][j];// 作为key查找其First集合
FORM[i][j] = oneLeftFirst.get(oneLeftKey);
}
}
// (2)如果有推出了ε,则根据FOLLOW填表
for (int i = 1; i < FORM.length; i++) {
String oneLeftKey = FORM[i][0] + "$ε";
if (oneLeftFirst.containsKey(oneLeftKey)) {
HashSet<String> followCell = FOLLOW.get(FORM[i][0]);
Iterator<String> it = followCell.iterator();
while (it.hasNext()) {
String vt = it.next();
for (int j = 1; j < FORM.length; j++)
for (int k = 1; k < FORM[0].length; k++) {
if (FORM[j][0].equals(FORM[i][0]) && FORM[0][k].equals(vt))
FORM[j][k] = oneLeftFirst.get(oneLeftKey);
}
}
}
}
// 打印预测表,并存于Map的数据结构中用于快速查找
System.out.println("\n该文法的预测分析表为:");
for (int i = 0; i < FORM.length; i++) {
for (int j = 0; j < FORM[0].length; j++) {
if (FORM[i][j] == null)
System.out.print(" " + "\t");
else {
System.out.print(FORM[i][j] + "\t");
if (i > 0 && j > 0) {
String[] tmp = FORM[i][j].split("→");
preMap.put(FORM[i][0] + "" + FORM[0][j], tmp[1]);
}
}
}
System.out.println();
}
System.out.println();
}
// 输入的单词串分析推导过程
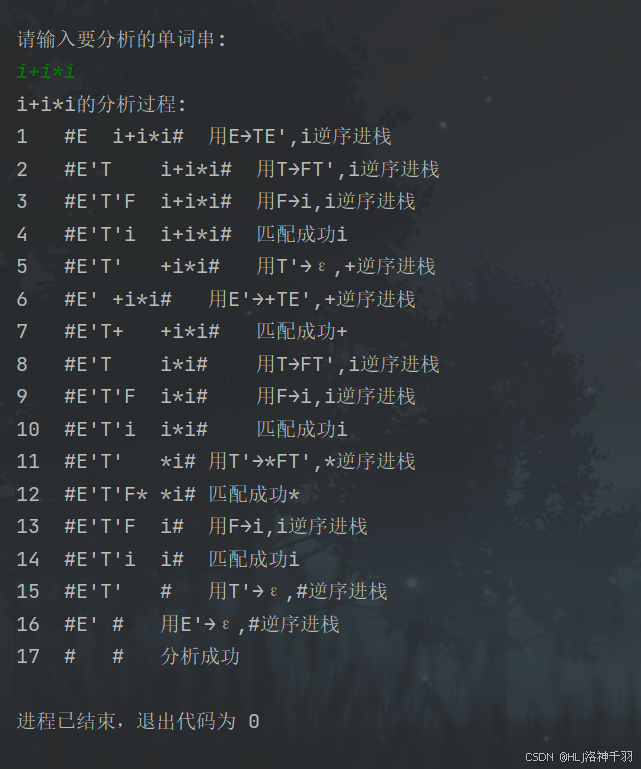
public static void printAutoPre(String str) {
System.out.println(str + "的分析过程:");
Queue<String> queue = new LinkedList<>();// 句子拆分存于队列
for (int i = 0; i < str.length(); i++) {
String t = str.charAt(i) + "";
if (i + 1 < str.length() && (str.charAt(i + 1) == '\'' || str.charAt(i + 1) == ''')) {
t += str.charAt(i + 1);
i++;
}
queue.offer(t);
}
queue.offer("#");// "#"结束
// 分析栈
Stack<String> stack = new Stack<>();
stack.push("#");// "#"开始
stack.push(START);// 初态为开始符号
boolean isSuccess = false;
int step = 1;
while (!stack.isEmpty()) {
String left = stack.peek();
String right = queue.peek();
// (1)分析成功
if (left.equals(right) && right.equals("#")) {
isSuccess = true;
System.out.println((step++) + "\t#\t#\t" + "分析成功");
break;
}
// (2)匹配栈顶和当前符号,均为终结符号,消去
if (left.equals(right)) {
String stackStr = String.join("", stack.toArray(new String[0]));
String queueStr = String.join("", queue.toArray(new String[0]));
System.out.println((step++) + "\t" + stackStr + "\t" + queueStr + "\t匹配成功" + left);
stack.pop();
queue.poll();
continue;
}
// (3)从预测表中查询
if (preMap.containsKey(left + right)) {
String stackStr = String.join("", stack.toArray(new String[0]));
String queueStr = String.join("", queue.toArray(new String[0]));
System.out.println((step++) + "\t" + stackStr + "\t" + queueStr + "\t用" + left + "→"
+ preMap.get(left + right) + "," + right + "逆序进栈");
stack.pop();
String tmp = preMap.get(left + right);
for (int i = tmp.length() - 1; i >= 0; i--) {// 逆序进栈
String t;
if (tmp.charAt(i) == '\'' || tmp.charAt(i) == ''') {
t = tmp.charAt(i - 1) + "" + tmp.charAt(i);
i--;
} else {
t = tmp.charAt(i) + "";
}
if (!t.equals("ε"))
stack.push(t);
}
continue;
}
break;// (4)其他情况失败并退出
}
if (!isSuccess)
System.out.println((step++) + "\t#\t#\t" + "分析失败");
}
// 符号分类
public static void identifyVnVt(ArrayList<String> list) {
START = list.get(0).charAt(0) + "";// 存放开始符号
for (String oneLine : list) {
String[] vent = oneLine.split("→");// 用定义符号分割
String left = vent[0].trim(); // 文法的左边
VN.add(left);
// 文法右边
ArrayList<ArrayList<String>> mapValue = new ArrayList<>();
ArrayList<String> right = new ArrayList<>();
for (int j = 0; j < vent[1].length(); j++) { // 用 "|"分割右边
if (vent[1].charAt(j) == '|') {
VT.addAll(right);
mapValue.add(right);
right = new ArrayList<>();
continue;
}
// 如果产生式某字符的左边含有中文或英文的单引号,则视为同一个字符
if (j + 1 < vent[1].length() && (vent[1].charAt(j + 1) == '\'' || vent[1].charAt(j + 1) == ''')) {
right.add(vent[1].charAt(j) + "" + vent[1].charAt(j + 1));
j++;
} else {
right.add(vent[1].charAt(j) + "");
}
}
VT.addAll(right);
mapValue.add(right);
MAP.put(left, mapValue);
}
VT.removeAll(VN); // 从终结字符集中移除非终结符
// 打印Vn、Vt
System.out.println("\nVn集合:\t{" + String.join("、", VN.toArray(new String[0])) + "}");
System.out.println("Vt集合:\t{" + String.join("、", VT.toArray(new String[0])) + "}");
}
// 求每个非终结符号的FIRST集合 和 分解单个产生式的FIRST集合
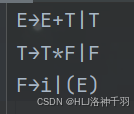
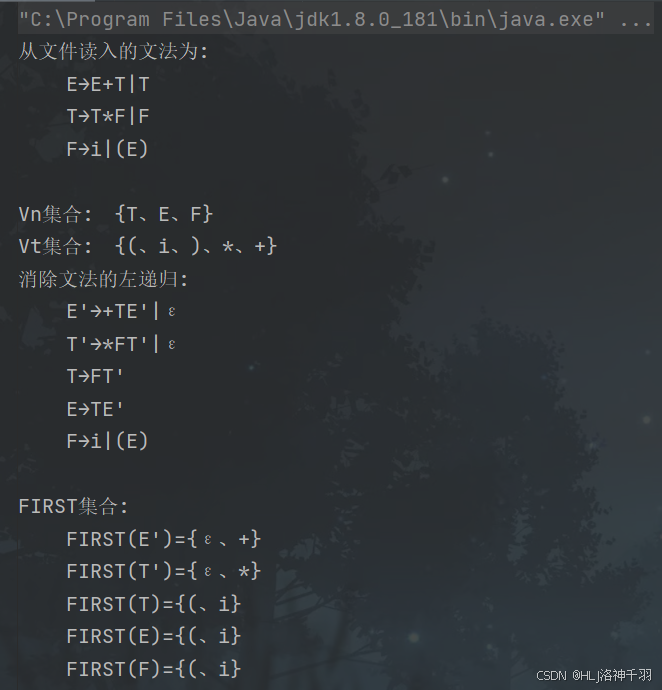
public static void findFirst() {
System.out.println("\nFIRST集合:");
Iterator<String> it = VN.iterator();
while (it.hasNext()) {
HashSet<String> firstCell = new HashSet<>();// 存放单个非终结符号的FIRST
String key = it.next();
ArrayList<ArrayList<String>> list = MAP.get(key);
// 遍历单个产生式的左边
for (int i = 0; i < list.size(); i++) {
ArrayList<String> listCell = list.get(i);// listCell为"|"分割出来
HashSet<String> firstCellOne = new HashSet<>();// 产生式左边用" | "分割的单个式子的First(弃用)
String oneLeft = String.join("", listCell.toArray(new String[0]));
if (VT.contains(listCell.get(0))) {
firstCell.add(listCell.get(0));
firstCellOne.add(listCell.get(0));
oneLeftFirst.put(key + "$" + listCell.get(0), key + "→" + oneLeft);
} else {
boolean[] isVn = new boolean[listCell.size()];// 标记是否有定义为空,如果有则检查下一个字符
isVn[0] = true;// 第一个为非终结符号
int p = 0;
while (isVn[p]) {
if (VT.contains(listCell.get(p))) {
firstCell.add(listCell.get(p));
firstCellOne.add(listCell.get(p));
oneLeftFirst.put(key + "$" + listCell.get(p), key + "→" + oneLeft);
break;
}
String vnGo = listCell.get(p);//
Stack<String> stack = new Stack<>();
stack.push(vnGo);
while (!stack.isEmpty()) {
ArrayList<ArrayList<String>> listGo = MAP.get(stack.pop());
for (ArrayList<String> listGoCell : listGo) {
if (VT.contains(listGoCell.get(0))) { // 如果第一个字符是终结符号
if (listGoCell.get(0).equals("ε")) {
if (!key.equals(START)) { // 开始符号不能推出空
firstCell.add(listGoCell.get(0));
firstCellOne.add(listGoCell.get(0));
oneLeftFirst.put(key + "$" + listGoCell.get(0), key + "→" + oneLeft);
}
if (p + 1 < isVn.length) {// 如果为空,可以查询下一个字符
isVn[p + 1] = true;
}
} else { // 非空的终结符号加入对应的FIRST集合
firstCell.add(listGoCell.get(0));
firstCellOne.add(listGoCell.get(0));
oneLeftFirst.put(key + "$" + listGoCell.get(0), key + "→" + oneLeft);
}
} else {// 不是终结符号,入栈
stack.push(listGoCell.get(0));
}
}
}
p++;
if (p > isVn.length - 1)
break;
}
}
FIRST.put(key + "→" + oneLeft, firstCellOne);
}
FIRST.put(key, firstCell);
// 输出key的FIRST集合
System.out.println(
"\tFIRST(" + key + ")={" + String.join("、", firstCell.toArray(new String[0])) + "}");
}
}
// 求每个非终结符号的FOLLOW集合
public static void findFollow() {
System.out.println("\nFOLLOW集合:");
Iterator<String> it = VN.iterator();
HashMap<String, HashSet<String>> keyFollow = new HashMap<>();
ArrayList<HashMap<String, String>> vn_VnList = new ArrayList<>();// 用于存放/A->...B 或者 A->...Bε的组合
HashSet<String> vn_VnListLeft = new HashSet<>();// 存放vn_VnList的左边和右边
HashSet<String> vn_VnListRight = new HashSet<>();
// 开始符号加入#
keyFollow.put(START, new HashSet<String>() {
private static final long serialVersionUID = 1L;
{
add(new String("#"));
}
});
while (it.hasNext()) {
String key = it.next();
ArrayList<ArrayList<String>> list = MAP.get(key);
ArrayList<String> listCell;
// 先把每个VN作为keyFollow的key,之后在查找添加其FOLLOW元素
if (!keyFollow.containsKey(key)) {
keyFollow.put(key, new HashSet<>());
}
keyFollow.toString();
for (ArrayList<String> strings : list) {
listCell = strings;
// (1)直接找非总结符号后面跟着终结符号
for (int j = 1; j < listCell.size(); j++) {
HashSet<String> set = new HashSet<>();
if (VT.contains(listCell.get(j))) {
// System.out.println(listCell.get(j - 1) + ":" + listCell.get(j));
set.add(listCell.get(j));
if (keyFollow.containsKey(listCell.get(j - 1)))
set.addAll(keyFollow.get(listCell.get(j - 1)));
keyFollow.put(listCell.get(j - 1), set);
}
}
// (2)找...VnVn...组合
for (int j = 0; j < listCell.size() - 1; j++) {
HashSet<String> set = new HashSet<>();
if (VN.contains(listCell.get(j)) && VN.contains(listCell.get(j + 1))) {
set.addAll(FIRST.get(listCell.get(j + 1)));
set.remove("ε");
if (keyFollow.containsKey(listCell.get(j)))
set.addAll(keyFollow.get(listCell.get(j)));
keyFollow.put(listCell.get(j), set);
}
}
// (3)A->...B 或者 A->...Bε(可以有n个ε)的组合存起来
for (int j = 0; j < listCell.size(); j++) {
HashMap<String, String> vn_Vn;
if (VN.contains(listCell.get(j)) && !listCell.get(j).equals(key)) {// 是VN且A不等于B
boolean isAllNull = false;// 标记VN后是否为空
if (j + 1 < listCell.size())// 即A->...Bε(可以有n个ε)
for (int k = j + 1; k < listCell.size(); k++) {
if ((FIRST.containsKey(listCell.get(k)) && FIRST.get(listCell.get(k)).contains("ε"))) {// 如果其后面的都是VN且其FIRST中包含ε
isAllNull = true;
} else {
isAllNull = false;
break;
}
}
// 如果是最后一个为VN,即A->...B
if (j == listCell.size() - 1) {
isAllNull = true;
}
if (isAllNull) {
vn_VnListLeft.add(key);
vn_VnListRight.add(listCell.get(j));
// 往vn_VnList中添加,分存在和不存在两种情况
boolean isHaveAdd = false;
for (int x = 0; x < vn_VnList.size(); x++) {
HashMap<String, String> vn_VnListCell = vn_VnList.get(x);
if (!vn_VnListCell.containsKey(key)) {
vn_VnListCell.put(key, listCell.get(j));
vn_VnList.set(x, vn_VnListCell);
isHaveAdd = true;
break;
} else {
// 去重
if (vn_VnListCell.get(key).equals(listCell.get(j))) {
isHaveAdd = true;
break;
}
}
}
if (!isHaveAdd) {// 如果没有添加,表示是新的组合
vn_Vn = new HashMap<>();
vn_Vn.put(key, listCell.get(j));
vn_VnList.add(vn_Vn);
}
}
}
}
}
}
keyFollow.toString();
// (4)vn_VnListLeft减去vn_VnListRight,剩下的就是入口产生式,
vn_VnListLeft.removeAll(vn_VnListRight);
Queue<String> keyQueue = new LinkedList<>();// 用栈或者队列都行
Iterator<String> itVnVn = vn_VnListLeft.iterator();
while (itVnVn.hasNext()) {
keyQueue.add(itVnVn.next());
}
while (!keyQueue.isEmpty()) {
String keyLeft = keyQueue.poll();
for (int t = 0; t < vn_VnList.size(); t++) {
HashMap<String, String> vn_VnListCell = vn_VnList.get(t);
if (vn_VnListCell.containsKey(keyLeft)) {
HashSet<String> set = new HashSet<>();
// 原来的FOLLOW加上左边的FOLLOW
if (keyFollow.containsKey(keyLeft))
set.addAll(keyFollow.get(keyLeft));
if (keyFollow.containsKey(vn_VnListCell.get(keyLeft))) set.addAll(keyFollow.get(vn_VnListCell.get(keyLeft)));
keyFollow.put(vn_VnListCell.get(keyLeft), set);
keyQueue.add(vn_VnListCell.get(keyLeft));
// 移除已处理的组合
vn_VnListCell.remove(keyLeft);
vn_VnList.set(t, vn_VnListCell);
}
}
}
// 此时keyFollow为完整的FOLLOW集
FOLLOW = keyFollow;
// 打印FOLLOW集合
Iterator<String> itF = keyFollow.keySet().iterator();
while (itF.hasNext()) {
String key = itF.next();
HashSet<String> f = keyFollow.get(key);
System.out.println("\tFOLLOW(" + key + ")={" + String.join("、", f.toArray(new String[0])) + "}");
}
}
// 消除直接左递归
public static void reformMap() {
boolean isReForm = false;// MAP是否被修改
Set<String> keys = new HashSet<>();
keys.addAll(MAP.keySet());
Iterator<String> it = keys.iterator();
ArrayList<String> nullSign = new ArrayList<>();
nullSign.add("ε");
while (it.hasNext()) {
String left = it.next();
boolean flag = false;// 是否有左递归
ArrayList<ArrayList<String>> rightList = MAP.get(left);
ArrayList<String> oldRightCell = new ArrayList<>(); // 旧产生的右边
ArrayList<ArrayList<String>> newLeftNew = new ArrayList<>();// 存放新的左边和新的右边
// 消除直接左递归
for (int i = 0; i < rightList.size(); i++) {
ArrayList<String> newRightCell = new ArrayList<>(); // 新产生式的右边
if (rightList.get(i).get(0).equals(left)) {
for (int j = 1; j < rightList.get(i).size(); j++) {
newRightCell.add(rightList.get(i).get(j));
}
flag = true;
newRightCell.add(left + "\'");
newLeftNew.add(newRightCell);
} else {
for (int j = 0; j < rightList.get(i).size(); j++) {
oldRightCell.add(rightList.get(i).get(j));
}
oldRightCell.add(left + "\'");
}
}
if (flag) {// 如果有左递归,则更新MAP
isReForm = true;
newLeftNew.add(nullSign);
MAP.put(left + "\'", newLeftNew);
VN.add(left + "\'"); // 加入新的VN
VT.add("ε"); // 加入ε到VT
ArrayList<ArrayList<String>> newLeftOld = new ArrayList<>();// 存放原先,但是产生新的右边
newLeftOld.add(oldRightCell);
MAP.put(left, newLeftOld);
}
}
// 如果文法被修改,则输出修改后的文法
if (isReForm) {
System.out.println("消除文法的左递归:");
Set<String> kSet = new HashSet<>(MAP.keySet());
Iterator<String> itk = kSet.iterator();
while (itk.hasNext()) {
String k = itk.next();
ArrayList<ArrayList<String>> leftList = MAP.get(k);
System.out.print("\t" + k + "→");
for (int i = 0; i < leftList.size(); i++) {
System.out.print(String.join("", leftList.get(i).toArray(new String[0])));
if (i + 1 < leftList.size())
System.out.print("|");
}
System.out.println();
}
}
}
// 从文件读文法
public static ArrayList<String> readFile(File file) {
System.out.println("从文件读入的文法为:");
ArrayList<String> result = new ArrayList<>();
try {
BufferedReader br = new BufferedReader(new FileReader(file));
String s;
while ((s = br.readLine()) != null) {
System.out.println("\t" + s);
result.add(s.trim());
}
br.close();
} catch (Exception e) {
e.printStackTrace();
}
return result;
}
}实验数据及结果
1、实验数据
2、实验结果
实验小结
通过本次实验,我对语法分析有了更深的理解。语法分析的方法是LL(1)文法。设计思路如下:
1、构造单个文法符号X的first集:
如果X为终结符,First(X)=X;如果X->ε是产生式,把ε加入First(X);如果X是非终结符,如X->YZW。从左往右扫描产生式右部,把First(Y)加入First(X); 如果First(Y)不包含ε,表示Y不可为空,便不再往后处理;如果First(Y)包含ε,表示Y可为空,则处理Z,依次类推。构造文法符号串的first集,如:X->YZW;求YZW的first集。从左往右扫描该式,加入其非空first集:把First(Y)加入First(YZW)。若包含空串,处理下一个符号:如果First(Y)包含空串,便处理Z;不包含就退出;处理到尾部,即所有符号的first集都包含空串 把空串加入First(YZW)。
2、在计算First(X)集之后的基础上:
(1)$属于FOLLOW(S),S是开始符;
(2)查找输入的所有产生式,确定X后紧跟的终结符;
(3)如果存在A->αBβ,(α、β是任意文法符号串,A、B为非终结符),把first(β)的非空符号加入follow(B);
(4)如果存在A->αB或A->αBβ 但first(β)包含空,把follow(A)加入follow(B)。
3、构造预测分析表:
对于每个产生式A->α,first(α)中的终结符a,把A->α加入MA,a。如果空串在first(α)中,说明可为空,找它的follow集,对于follow(A)中的终结符b,把A->α加入MA,b;如果空串在first(α)中,且 ""也在follow(A)中,说明A后可以接终结符,故把A-\>α加入M\[A,]中。
4、执行分析:
输入一个串,文法G的预测分析表,输出推导过程:$ 和 开始符S入栈,栈顶符号X,index指向分析串的待分析符号a。栈非空执行以下循环:如果X==a,表示匹配,符号栈弹出一个,index++指向下一个符号;否则,如果X是终结符,出错;否则,如果查表为error,出错;否则,查表正确,弹出栈顶符号,把其右部各个符号进栈,令X为栈顶符号。
若觉得有帮助,欢迎点赞关注,一起成长进步~
声明:本文仅供学习交流,禁作商用;禁篡改、歪曲及有偿传播,引用需标明来源。侵权必究。