用统计置信度破解AI功能正确性评估难题------SCFC方法详解
论文信息
原标题
Statistical Confidence in Functional Correctness: An Approach for AI Product Functional Correctness Evaluation
主要作者及研究机构
所有作者均来自巴西里约热内卢天主教大学 :
Wallace Albertini、Marina Condé Araújo、Júlia Condé Araújo、Antonio Pedro Santos Alves、Marcos Kalinowski
APA引文格式
Albertini, W., Araújo, M. C., Araújo, J. C., Alves, A. P. S., & Kalinowski, M. (2026). Statistical confidence in functional correctness: An approach for AI product functional correctness evaluation. arXiv preprint arXiv:2602.18357v1.
一段话总结
本文针对AI系统概率性本质导致传统测试方法失效、ISO/IEC 25059标准缺乏实操统计评估手段的行业痛点,提出了统计置信度功能正确性(SCFC) 四步评估方法,通过定义量化规格限值、分层概率抽样、自助法估算置信区间、计算适配非正态分布的能力指数Cₚₖ,实现了AI功能正确性从单一性能点估计到结合均值与变异性的统计置信度评估的转变;作者通过石油平台货舱空间估算、信用卡欺诈检测两个工业级AI系统的案例研究,并结合对四位不同领域AI专家的半结构化访谈,验证了该方法的可行性、实操性和工业价值,专家对其适用性、有用性和采纳意愿均给出高度评价,同时也指出了方法在抽象问题应用、多指标适配等方面的局限性,该研究填补了AI产品功能正确性评估的实操空白,为工业界提供了标准化、可落地的AI质量评估框架。
思维导图
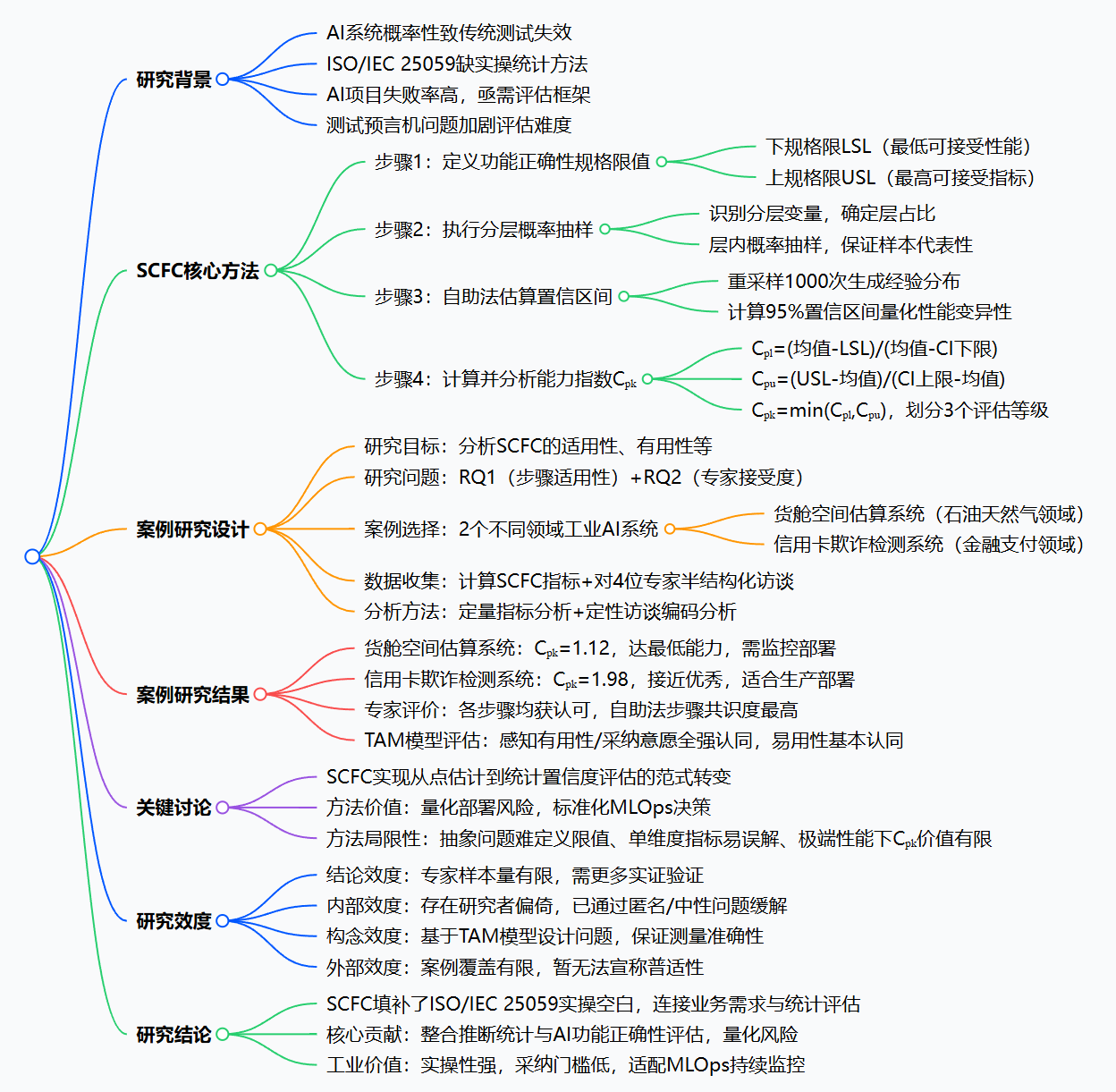
研究背景
在AI技术深度融入医疗诊断、自动驾驶、金融风控等领域的今天,AI系统的决策直接影响人类生活,但AI系统的固有特性让其质量评估成为行业难题,这也是该研究的核心出发点。
1. AI系统的"先天特性"让传统测试方法失灵
传统软件的输入输出是确定性映射 ,比如输入一个指令必然得到固定结果,因此可以用确定性测试方法验证功能正确性;但AI系统是概率性、自适应性的,同一输入可能得到不同输出,比如欺诈检测模型对同一笔交易的判断可能因样本分布变化而不同,传统测试方法根本无法适配这种特性。
同时,AI还面临**"测试预言机问题"**:很多场景下没有明确的"正确答案",比如图像识别的模糊场景、推荐系统的偏好判断,正确输出只能在概率范围内近似,进一步加剧了评估难度。
2. 行业现状:AI项目失败率高,亟需稳健评估框架
有研究显示,约四分之一的企业 报告其AI项目失败率高达50%,而AI系统失效会带来巨大的社会经济成本------比如金融风控模型漏检欺诈会造成资金损失,医疗诊断模型误判会影响患者治疗。但行业内始终缺乏能量化风险、统计稳健的AI功能正确性评估方法,大部分企业仍依靠单一的准确率、召回率等点估计指标做决策,极易造成"虚假自信"。
3. 国际标准有框架,但无实操手段
为解决AI质量评估问题,国际标准化组织推出了ISO/IEC 25059 标准,将传统软件质量模型适配到AI领域,明确了功能正确性是AI产品的核心质量指标。但该标准仅为高层级框架,没有定义具体的量化指标、抽样方法和统计分析手段,企业在实际应用中仍无章可循。
4. 现有研究的不足:只看"平均值",忽略"波动性"
此前有学者提出过AI功能适用性的评估方法,但其核心是通过固定阈值判断性能是否达标,仅关注点估计指标(如平均召回率95%),既没有量化AI系统的性能变异性(比如不同样本下召回率在90%-99%波动),也没有提供统计置信度的衡量手段,无法回答"这个95%的召回率,有多大把握能在生产中持续实现?"这一工业界最关心的问题。
简单来说,现有方法就像只看学生的考试平均分,却忽略了分数的波动范围------平均分90分的学生,可能某次考60分,也可能次次稳定在85-95分,二者的"可靠性"天差地别,而AI工业部署需要的正是对可靠性的量化判断。
创新点
本研究的核心价值在于填补了AI功能正确性评估从"理论框架"到"工业实操"的空白,其创新点体现在四个维度,且所有创新均围绕工业界的实际需求展开:
- 评估范式创新:从"点估计"升级为"统计置信度评估"
打破了传统AI评估仅关注单一性能均值的局限,首次将性能变异性 和统计不确定性纳入功能正确性评估体系,实现了从"知道模型表现好不好"到"知道模型有多大把握持续表现好"的转变,精准解决了工业界对AI部署风险量化的核心需求。 - 方法创新:提出非参数化的能力指数Cₚₖ,适配AI的非正态分布
借鉴六西格玛的Cₚₖ能力指数,但摒弃了传统方法对数据正态分布的假设(AI性能指标往往不满足正态分布),改用自助法得到的置信区间替代标准差计算Cₚₖ,让指标更贴合AI系统的特性,计算结果更可靠。 - 流程创新:设计四步标准化流程,连接"业务需求"与"技术评估"
SCFC方法的第一步就是与利益相关者定义量化规格限值,将模糊的业务需求(如"欺诈检测不能漏检太多")转化为可测量的技术指标(如"欺诈召回率≥98%"),解决了工业界中"业务与技术评估脱节"的痛点,让评估结果直接服务于商业决策。 - 抽样创新:采用分层概率抽样,保证工业数据的代表性
针对工业数据的异质性(如金融交易包含不同地区、不同金额类型),放弃简单随机抽样,采用分层概率抽样,确保少数但关键的子样本(如高金额交易、罕见欺诈类型)被充分覆盖,让测试样本更贴近生产实际,避免因样本偏差导致的评估失真。
研究方法和思路、实验方法等
本研究的方法分为两部分:核心的SCFC评估方法 (理论方法论)和基于工业案例的验证方法(实验设计),二者相互支撑,让方法论既有理论依据,又有工业实操验证。
一、SCFC统计置信度功能正确性评估方法(四步标准化流程)
该方法是研究的核心,全程围绕"量化AI性能的统计置信度,为部署决策提供风险依据"展开,所有步骤均拆解为可落地的操作,无复杂理论门槛,适合工业界应用。
步骤1:定义功能正确性量化规格限值
- 核心目标 :将模糊的业务需求转化为客观、可测量、无歧义的技术指标,建立评估的"基准线"。
- 具体操作 :与业务方、领域专家协作,定义下规格限(LSL)和上规格限(USL) :
- LSL:最低可接受性能,适用于"越高越好"的指标(如召回率、准确率、预测符合率);
- USL:最高可接受指标,适用于"越低越好"的指标(如假阳性率、误差率、延迟)。
- 案例示例:欺诈检测系统的业务需求"不能漏检太多欺诈",转化为LSL=0.98(欺诈召回率≥98%);货舱估算系统的需求"预测结果需符合专家判断",转化为LSL=0.70(预测符合率≥70%)。
步骤2:执行分层概率抽样,构建代表性测试样本
- 核心目标:保证测试样本与生产环境的数分布一致,避免样本偏差导致的评估失真。
- 具体操作 :
- 联合领域专家识别分层变量:即影响AI模型行为的核心数据特征(如交易类型、地理区域、图像拍摄环境);
- 基于历史数据/业务知识,确定每个分层在整体数据中的真实占比;
- 在每个分层内进行概率抽样,确保层内样本的随机性,同时保证少数关键分层被充分覆盖。
- 核心优势:相比简单随机抽样,能解决工业数据的"少数关键样本被忽略"问题,比如欺诈检测中欺诈交易仅占0.01%,分层抽样可保证该类样本在测试集中的代表性。
步骤3:应用自助法(Bootstrapping),估算性能指标的95%置信区间
- 核心目标:量化AI系统的性能变异性和统计不确定性,回答"模型的真实性能落在什么范围?"。
- 具体操作 :
- 以步骤2得到的测试样本为基础,进行有放回的重采样,生成1000个与原样本大小相同的新样本(1000为行业验证的有效重采样次数);
- 计算每个新样本的性能指标(如召回率、预测符合率),形成性能指标的经验分布;
- 基于该分布,计算95%置信区间(CI):即有95%的把握认为,模型的真实性能落在该区间内。
- 核心优势:非参数化方法,无需假设数据分布,完美适配AI性能指标的非正态特性,且计算成本低,仅需对模型推理结果重采样,无需重新运行模型。
步骤4:计算并分析非参数化能力指数Cₚₖ,作为最终评估指标
- 核心目标 :将"性能均值"和"性能波动"整合为单一指标,量化模型持续满足业务需求的能力,为部署决策提供清晰依据。
- 具体操作 :
- 根据是否有LSL/USL,选择对应的计算公式(核心为用置信区间替代标准差,适配AI特性):
- 仅LSL(越高越好):Cpk=Cpl=Mean−LSLMean−下限(CI)C_{pk}=C_{pl}=\frac{Mean - LSL}{Mean - 下限(CI)}Cpk=Cpl=Mean−下限(CI)Mean−LSL
- 仅USL(越低越好):Cpk=Cpu=USL−Mean上限(CI)−MeanC_{pk}=C_{pu}=\frac{USL - Mean}{上限(CI) - Mean}Cpk=Cpu=上限(CI)−MeanUSL−Mean
- 双限值:Cpk=min(Cpu,Cpl)C_{pk}=min(C_{pu},C_{pl})Cpk=min(Cpu,Cpl)(取最小值,反映最风险的情况)
- 根据Cₚₖ值划分三个评估等级 ,直接对应部署决策:
- Cpk<1.0C_{pk}<1.0Cpk<1.0:不可接受,模型无法持续满足业务需求;
- Cpk=1.0C_{pk}=1.0Cpk=1.0:最低能力,模型刚好满足需求,仅可部署在非关键场景,需严格监控;
- Cpk>2.0C_{pk}>2.0Cpk>2.0:优秀,模型性能稳定,有足够安全边际,可放心部署。
- 根据是否有LSL/USL,选择对应的计算公式(核心为用置信区间替代标准差,适配AI特性):
二、实验验证方法(工业案例+专家访谈)
为验证SCFC方法的适用性、实操性和工业价值 ,作者设计了探索性案例研究,结合定量指标计算 和定性专家反馈,让验证结果更具说服力。
- 案例选择 :选取2个不同领域、不同技术架构、不同评估需求 的工业级AI系统,保证结果的代表性:
- 案例1:石油平台货舱空间估算系统(计算机视觉+回归,评估预测符合率);
- 案例2:信用卡欺诈检测系统(二分类,评估欺诈召回率,存在严重类别不平衡)。
- 研究对象 :4位跨领域、有丰富工业/学术经验的AI专家,其中2位为案例项目负责人,2位为独立专家,避免偏倚。
- 数据收集 :
- 定量:对两个案例严格按照SCFC四步法计算指标,得到点估计、置信区间、Cₚₖ值;
- 定性:开展平均41分钟的半结构化访谈,用Miro看板和李克特量表收集专家对SCFC各步骤适用性、感知有用性、易用性、采纳意愿的反馈。
- 分析方法 :
- 定量:解读Cₚₖ值并对应部署决策,对比点估计与Cₚₖ指标的决策价值;
- 定性:对访谈内容进行开放编码,由两位研究者交叉验证,确保分析结果的可靠性。
主要成果和贡献
本研究的成果分为量化的案例实验成果 和行业层面的核心贡献,所有成果均落地于工业实际需求,解决了AI评估领域的真实痛点,让研究不再是"纸上谈兵"。
一、核心实验成果:两个工业案例的SCFC评估结果
通过对两个工业AI系统的实操评估,验证了SCFC方法的可落地性,且清晰展现了其相比传统点估计的风险量化价值,结果如下表:
| 案例名称 | 业务需求(LSL) | 传统点估计性能 | 95%置信区间 | SCFC Cₚₖ值 | 评估等级 | 部署决策 | 核心价值体现 |
|---|---|---|---|---|---|---|---|
| 石油平台货舱空间估算系统 | 预测符合率≥70%(0.70) | 83%(35/42) | 0.7143, 0.9286 | 1.12 | 略高于最低能力 | 可部署,需持续生产监控 | 点估计看似远达标,但Cₚₖ揭示性能下限仅略超LSL,安全边际小,量化了部署风险 |
| 信用卡欺诈检测系统 | 欺诈召回率≥98%(0.98) | 99.1%(8951/9033) | 0.9855, 0.9967 | 1.98 | 接近优秀 | 适合部署,可直接投入生产 | 点估计达标,Cₚₖ验证性能稳定,下限仍超LSL,确认部署无显著风险 |
二、专家反馈成果:高接受度与实操性验证
通过对4位AI专家的访谈,验证了SCFC方法的行业认可度,基于技术接受模型(TAM)的评估结果如下:
- 感知有用性 :4位专家全票强认同,认为其填补了现有AI QA流程的空白,能直接服务于MLOps持续监控;
- 感知易用性:3位强认同,1位部分认同,唯一门槛为自助法的基础学习,且专家均表示计算成本低、易落地;
- 采纳意愿 :4位专家全票强认同,均表示会在未来项目中使用/推荐该方法。
同时,专家对SCFC各步骤的适用性均表示认可,自助法计算置信区间步骤达成全票强认同,是方法中最受认可的环节。
三、研究的核心贡献(理论+工业双维度)
该研究为AI质量评估领域带来了实实在在的价值,无论是理论研究还是工业实操,都填补了关键空白,具体如下:
1. 理论贡献:完善了AI质量评估的统计体系
- 填补了ISO/IEC 25059标准的实操空白,为该标准提供了可落地的统计抽样、推断和评估方法,让国际标准不再是"空中楼阁";
- 首次将非参数化统计推断与AI功能正确性评估深度结合,提出了适配AI概率性特性的评估框架,丰富了AI质量评估的理论研究。
2. 工业贡献:提供了标准化、可落地的AI评估实操指南
- 解决了工业界**"AI部署风险无法量化"**的核心痛点,Cₚₖ指标为AI部署决策提供了清晰、统一的标准,减少工程师的主观判断;
- 设计的四步标准化流程连接了业务需求与技术评估,让非技术的业务方也能理解和参与AI评估,解决了"业务与技术脱节"的行业问题;
- 方法计算成本低、实操性强,无需复杂的算法改造,仅需对现有模型的推理结果进行统计分析,适合各类企业快速落地。
3. 实践贡献:为MLOps提供了持续监控的核心指标
- SCFC方法的Cₚₖ指标可直接融入MLOps流程,作为AI模型生产环境持续监控的核心指标,及时发现模型性能漂移,为模型重训练、迭代提供依据;
- 两个工业案例的实操过程,为不同领域(计算机视觉、金融风控)的企业提供了可参考的落地模板,降低了企业的应用成本。
四、相关开源资源
论文中提及的工业案例相关artifact因涉及企业隐私未开源,但作者提供了合成案例的可运行代码(基于Google Colab),同时开放了访谈相关的匿名转录稿和Miro看板反馈,开源地址:https://doi.org/10.5281/zenodo.17451539
关键问题(问答形式)
问题1:SCFC方法是如何解决AI系统概率性带来的评估难题的?
答:SCFC方法从三个层面破解了AI概率性的评估难题:①抽样层面 ,用分层概率抽样保证测试样本贴近生产实际,避免因样本偏差导致的评估失真,让评估结果能反映模型的真实表现;②统计层面 ,用自助法估算95%置信区间,量化模型性能的变异性和不确定性,不再只看单一的均值,而是明确"真实性能的波动范围";③评估层面 ,用非参数化Cₚₖ指标整合均值和波动,直接量化模型持续满足业务需求的能力 ,将概率性的性能表现转化为可解读的风险等级,为部署决策提供清晰依据。简单来说,SCFC没有回避AI的概率性,而是将概率性纳入评估体系,实现了对风险的量化。
问题2:SCFC方法中的Cₚₖ指标与传统六西格玛的Cₚₖ有什么区别?
答:核心区别在于是否适配AI系统的非正态分布特性 ,具体有两点:①计算基础不同 :传统Cₚₖ以标准差 为核心计算依据,且假设数据满足正态分布 ,但AI系统的性能指标(如召回率、准确率)往往不满足正态分布,用传统方法计算会导致结果失真;SCFC的Cₚₖ摒弃了正态分布假设,改用自助法得到的95%置信区间 替代标准差,属于非参数化方法 ,更贴合AI的特性;②应用场景不同:传统Cₚₖ主要用于制造业的流程质量控制,针对的是确定性的生产流程;SCFC的Cₚₖ专门适配AI系统的概率性,用于评估AI模型的功能正确性,且直接连接业务需求的规格限值,更适合AI的工业部署决策。
问题3:为什么SCFC方法要采用分层概率抽样,而不是简单随机抽样?
答:因为工业场景下的AI训练/测试数据具有高度异质性 ,简单随机抽样极易导致关键少数样本被忽略 ,进而让评估结果失真。比如信用卡欺诈检测中,欺诈交易仅占总交易的0.01%,简单随机抽样可能导致测试集中没有欺诈样本,评估出的召回率毫无意义;而分层概率抽样会先将数据按核心特征(如交易类型、欺诈与否)分层,再按真实占比抽样,确保少数但关键的子样本被充分覆盖,让测试样本的分布与生产环境一致,保证评估结果的可靠性。这一设计让SCFC方法更贴合工业实际,避免了"实验室评估效果好,生产部署拉胯"的行业痛点。
问题4:SCFC方法在工业场景应用的核心优势和主要挑战分别是什么?
答:核心优势 有三点:①实操性强 ,四步流程标准化,无复杂理论门槛,计算成本低,仅需对现有模型的推理结果进行统计分析,企业可快速落地;②业务贴合度高 ,从第一步就将业务需求转化为量化指标,评估结果直接服务于商业决策,解决了业务与技术脱节的问题;③风险量化清晰 ,Cₚₖ指标和置信区间能明确模型的部署风险等级,为企业提供统一的决策标准,减少主观判断。
主要挑战 有两点:①对领域知识有一定要求 ,对于抽象的业务问题(如生成式AI的内容质量评估),难以定义清晰的LSL/USL,需要业务方和领域专家的深度协作;②存在基础学习曲线,部分工业从业者对自助法、置信区间等统计概念不熟悉,需要简单的基础培训。
问题5:SCFC方法相比传统的AI功能正确性评估方法,核心优势是什么?
答:传统方法的核心是点估计指标 (如准确率、召回率),只能回答"模型在测试集上表现好不好",但无法回答"模型在生产中能持续表现好吗?""表现不好的概率有多大?";而SCFC方法的核心优势是实现了从"性能测量"到"风险量化"的升级 ,不仅能告诉企业模型的平均性能,还能通过置信区间和Cₚₖ指标,明确模型性能的波动范围、真实性能的置信度,以及持续满足业务需求的能力,让企业能基于风险量化结果做部署决策,而不是凭"平均值"盲目上线。比如货舱估算系统的点估计83%远高于70%的要求,但SCFC的Cₚₖ=1.12揭示了其安全边际小,需监控部署,这是传统方法无法做到的。
问题6:SCFC方法能否适配生成式AI、多模态AI等复杂AI系统?
答:论文中虽未直接验证复杂AI系统,但从方法设计来看,具备适配的潜力 ,核心需解决两个问题:①规格限值的定义 :生成式AI、多模态AI的评估指标(如内容质量、语义一致性)更抽象,需要将抽象指标转化为可量化的LSL/USL(如语义一致性评分≥80分);②多指标的整合:复杂AI系统往往需要评估多个指标(如生成式AI的流畅度、准确性、多样性),可对每个指标分别计算Cₚₖ值,再根据业务关键程度进行加权,得到综合的评估结果。作者在论文中也提到,SCFC方法并非仅支持单维度指标,只是本次研究为了验证方便选择了单指标,未来可进一步完善多指标适配方案。
总结
本研究针对AI系统概率性本质导致的功能正确性评估难题,以及ISO/IEC 25059标准缺乏实操统计方法的行业痛点,提出并验证了统计置信度功能正确性(SCFC) 四步评估方法。该方法通过定义量化规格限值、执行分层概率抽样、应用自助法估算置信区间、计算非参数化能力指数Cₚₖ,将AI功能正确性评估从单一的点估计升级为结合性能均值与变异性的统计置信度评估,实现了对AI部署风险的量化。
为验证方法的可行性和工业价值,作者在石油平台货舱空间估算、信用卡欺诈检测两个不同领域的工业级AI系统中进行了实操应用,结果显示SCFC方法能清晰量化模型的部署风险,为决策提供精准依据;同时,对四位跨领域AI专家的半结构化访谈验证了该方法的高适用性、有用性和采纳意愿,专家均认可其对AI质量评估的实际价值。
该研究的核心贡献在于填补了ISO/IEC 25059标准的实操空白,提出了一套标准化、可落地的AI功能正确性评估框架,为工业界提供了量化AI部署风险的有效手段。同时,方法设计贴合工业实际,计算成本低、实操性强,可直接融入MLOps流程,为AI模型的持续监控和迭代提供支撑。当然,该方法在抽象问题的规格限值定义、复杂AI系统的多指标适配等方面仍有完善空间,未来需在更多领域开展实证研究,进一步提升方法的普适性。
总体而言,SCFC方法是AI质量评估领域的一次重要突破,让AI功能正确性评估从"凭感觉"走向"靠数据、靠统计",为AI技术的安全、可靠落地提供了关键的方法论支撑。