AI小智后端部分(二)
链接: B站Up
opus编码原理
将 MP3/WAV 格式的音频,转换为 Opus 格式的压缩音频数据,并输出给 ESP32S3 设备使用
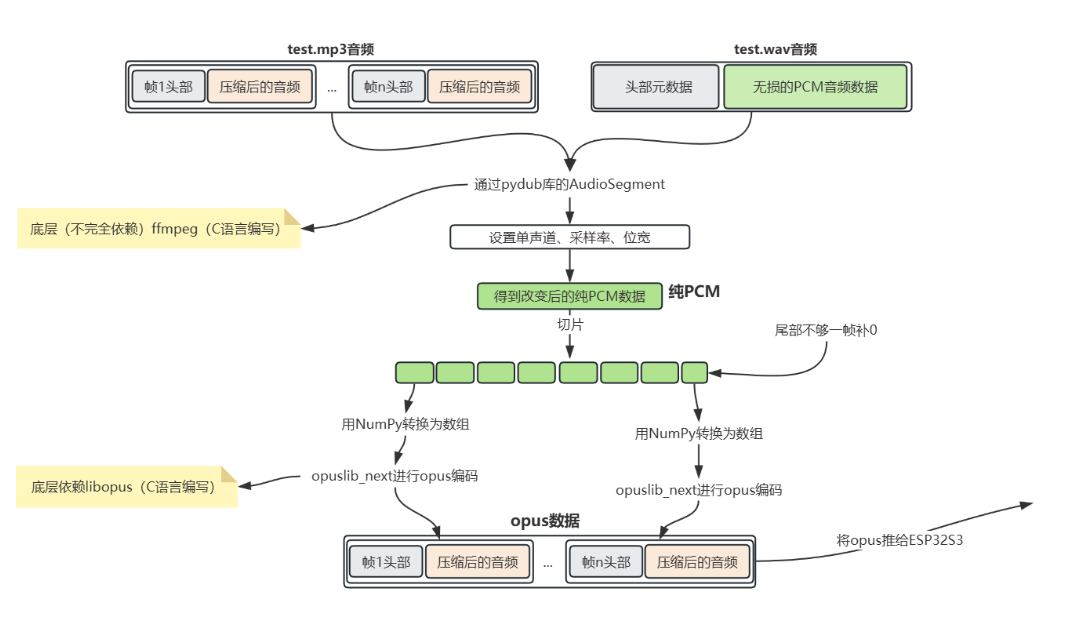
1.输入音频解析:将 MP3(分帧 + 压缩音频)或 WAV(头部元数据 + 无损 PCM)解析为原始音频数据。
2.统一转 PCM:通过 pydub 库(底层依赖 ffmpeg)将输入音频转为指定参数(单声道、采样率、位宽)的纯 PCM 数据。
3.PCM 切片处理:把纯 PCM 切成固定帧,尾部不足一帧则补 0。
4.Opus 编码:用 NumPy 将每帧 PCM 转数组,再通过 libopus 库编码为带帧头的 Opus 压缩数据。
5.输出使用:最终将 Opus 数据推送给 ESP32S3 设备。
opus编码依赖安装
1、安装底层依赖库
bash
conda install conda-forge::ffmpeg -y #把 MP3/WAV 转成 PCM 格式用的C语言写的
conda install conda-forge::libopus -y #将 PCM 数据压缩编码为 Opus 格式(或反向解码)安装异常尝试这些指令
bash
conda config --remove-key channels #先执行这个
#再执行这三个
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge这里的作用是重置并配置 conda 的软件源为清华大学镜像源。
安装好之后验证


2、创建依赖文件 requirements.txt
-记录依赖:把项目需要的所有 Python 库(比如处理音频的 pydub、numpy 等)及其版本号写在这个文件里,明确项目的依赖清单。
-一键安装:其他人拿到项目后,只需执行pip install -r requirements.txt,就能自动安装文件里列出的所有依赖,快速复现项目的运行环境,避免 "缺库、版本不兼容" 的问题。
bash
edge_tts == 7.0.0
openai == 1.70.0添加类似版本说明。
3、添加 opus 编解码的依赖到 requirements.txt
bash
pydub==0.25.1
opuslib_next==1.1.2
numpy==1.26.4
pydub #可以从任意格式的音频(mp3/wav)读取到原始数据,底层依赖ffmpeg(不完全依赖)
opuslib_next #实现opus编解码,底层依赖libopus
numpy #科学计算库,这这里主要操作数组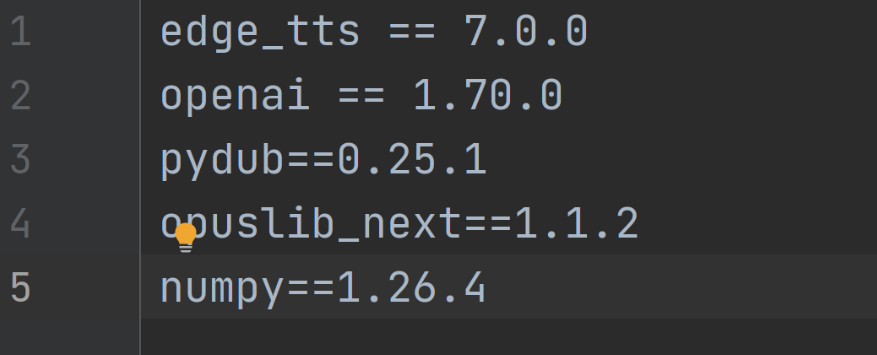
4、安装依赖
bash
pip install -r requirements.txtopus编码实现(一)
c
import os # 用于文件路径处理
import numpy as np # 数值计算(代码中暂未显式使用,但opus编码常配合numpy处理音频数据)
import opuslib_next # Opus音频编解码核心库
from pydub import AudioSegment # 音频格式转换、参数处理的便捷库
class Opus_Encode:
"""
Opus音频编码类:将MP3/WAV等音频文件转换为ESP32设备可播放的Opus格式音频
核心逻辑:统一音频参数 → 提取PCM原始数据 → 初始化Opus编码器 → (预留编码逻辑)
"""
def __init__(self):
"""初始化音频参数(适配ESP32设备播放要求)"""
# 原始音频统一转换后的参数
self.sample_rate = 16000 # 采样率:16kHz(ESP32常用音频采样率)
self.channel = 1 # 声道数:单声道(嵌入式设备节省资源)
self.sample_width = 2 # 采样宽度:2字节(16位深度,音频常用精度)
# Opus编码专用参数
self.opus_sample_rate = 16000 # Opus编码采样率(需与原始音频采样率一致)
self.opus_channel = 1 # Opus编码声道数(需与原始音频声道数一致)
self.opus_frame_time = 60 # Opus帧时长:60ms(Opus支持2.5/5/10/20/40/60ms,60ms压缩率更高)
# 将音频文件编码为Opus格式,接收音频文件路径如 "./temp/audio.mp3"
def audio_to_opus(self, audio_file_path):
"""
核心方法:音频文件转Opus格式
:param audio_file_path: 输入音频文件路径(支持MP3/WAV等常见格式)
:return: (代码未完成返回,可扩展为返回Opus编码后的数据/保存为文件)
"""
# 1. 解析文件格式:从路径中提取后缀(如.mp3 → mp3)
file_type = os.path.splitext(audio_file_path)[1] # 获取文件后缀(带点,如.mp3)
if file_type:
file_type = file_type.lstrip('.') # 去掉点,得到纯格式名(如mp3)
print("文件格式为: ", file_type)
print("audio_file_path: ", audio_file_path)
# 2. 读取音频文件:根据文件格式加载音频(pydub自动解析格式)
audio = AudioSegment.from_file(audio_file_path, format=file_type)
# 3. 统一音频参数:将不同格式的音频标准化(关键步骤)
# 类比:把不同形状/大小的泥巴,压成统一规格的坯料,方便后续编码
audio = audio.set_channels(self.channel) # 强制转为单声道
audio = audio.set_frame_rate(self.sample_rate) # 强制转为16kHz采样率
audio = audio.set_sample_width(self.sample_width) # 强制转为16位采样深度
# 4. 计算音频时长:pydub读取的音频长度单位是毫秒,转成秒
duration = len(audio) / 1000.0
print("音频时长: ", duration)
# 5. 提取PCM原始数据:标准化后的音频裸数据(无格式头,纯音频采样值)
# PCM是音频的"原始素材",Opus编码器只能处理PCM数据
raw_data = audio.raw_data
print("PCM数据: ", raw_data) # 打印二进制PCM数据(调试用)
# 6. 初始化Opus编码器(核心步骤)
# 参数说明:
# - 采样率:16000(必须与前面统一后的采样率一致,否则编码会失真)
# - 声道数:1(单声道)
# - 应用类型:APPLICATION_AUDIO(针对音频播放场景优化,兼顾音质和压缩率)
# 可选值:APPLICATION_VOIP(语音通话)、APPLICATION_RESTRICTED_LOWDELAY(低延迟)
encoder = opuslib_next.Encoder(
self.opus_sample_rate,
self.opus_channel,
opuslib_next.APPLICATION_AUDIO
)
# ========== 代码待补充部分 ==========
# 7. (关键)PCM数据切片+Opus编码(当前代码只初始化了编码器,未执行编码)
# 逻辑:按Opus帧时长(60ms)切割PCM数据 → 逐帧编码 → 拼接编码结果
1.音频参数统一(标准化)
不管输入是 MP3(立体声 / 44.1kHz)还是 WAV(单声道 / 22kHz),都通过pydub转为单声道、16kHz 采样率、16 位深度的统一格式;
目的:适配 ESP32 硬件的播放能力,同时让 Opus 编码器有统一的输入源,避免编码异常。
2.提取 PCM 原始数据(取原料)
audio.raw_data获取的是无格式头的纯音频采样数据(二进制),这是 Opus 编码器能处理的唯一格式;类比:把加工好的 "标准坯料" 拆成编码器能识别的 "原料颗粒"。
Opus 编码(加工成品)
3.初始化opuslib_next.Encoder编码器,指定采样率、声道数和应用场景(APPLICATION_AUDIO适配音乐 / 音频播放)。
opus编码实现(二)
将统一规格后的纯 PCM 音频数据,按照 Opus 编码要求分帧处理并完成逐帧编码,最终输出可被 ESP32 使用的 Opus 编码数据列表。
c
# 获取每帧的采样数(采样的样本数,一个样本组成为多个通道的字节,这里是单通道,所以一个样本是2个字节)
frame_num = int((self.opus_sample_rate / 1000) * self.opus_frame_time)
# 计算每帧的采样字节数, 每个采样字节为2字节如果是多个声道,则需要乘以声道数
frame_bytes_size = frame_num * self.opus_channel * self.opus_sample_width
opus_datas = []
for i in range(0, len(raw_data), frame_bytes_size):
# 获取当前帧的二进制数据
chunk = raw_data[i:i + frame_bytes_size]
# 计算当前块的长度
chunk_len = len(chunk)
# 如果最后一帧不足,补零
if chunk_len < frame_bytes_size:
chunk += b'\x00' * (frame_bytes_size - chunk_len)
# 转换为numpy数组处理
np_frame = np.frombuffer(chunk, dtype=np.int16)
np_bytes = np_frame.tobytes()
# 编码Opus数据
opus_data = encoder.encode(np_bytes, frame_num)
opus_datas.append(opus_data)
return opus_datas, durationopus编码实现验证
这里用的是之前调用edge_tts,openai生成的test.mp3(输入文字,输出文本回答,再转换成音频文件)。
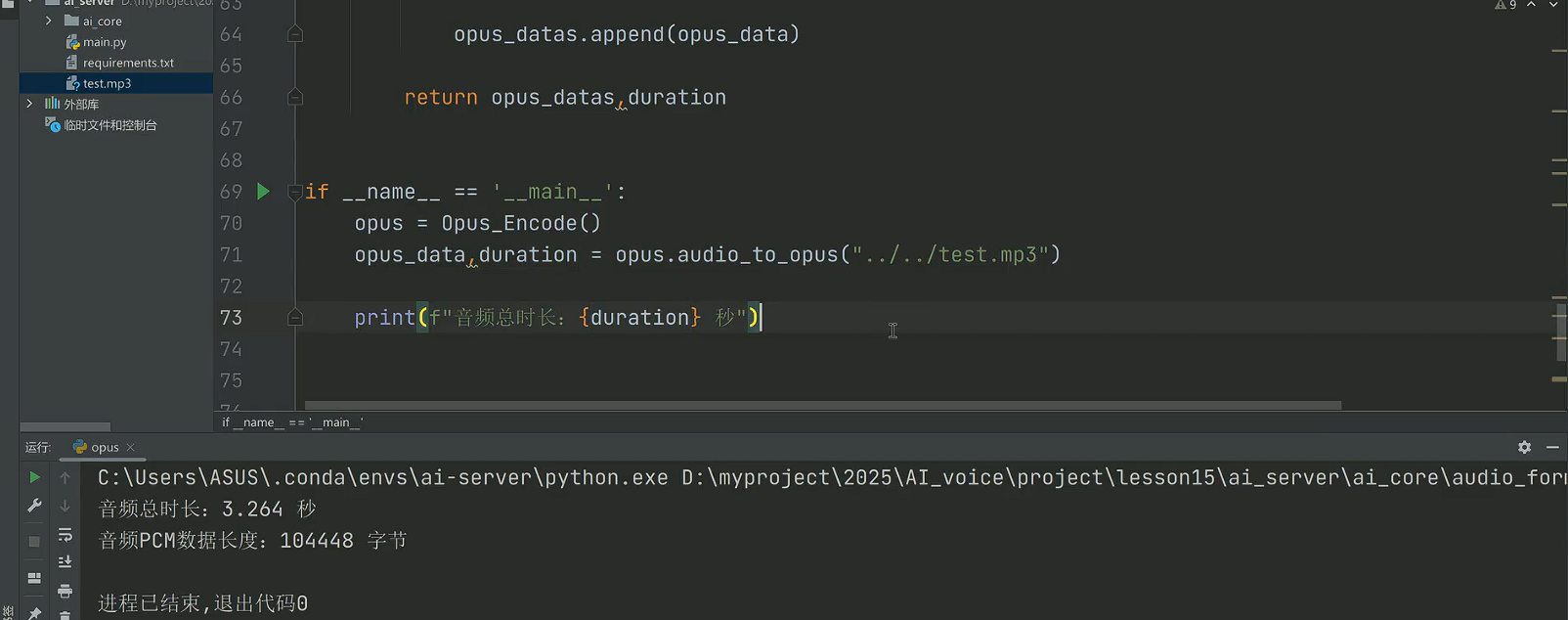
1.代码逻辑:
创建Opus_Encode类的实例,调用audio_to_opus方法,传入.../test.mp3这个音频文件路径,执行 "MP3 转 Opus 编码" 的流程;
打印转换后音频的总时长,同时输出了处理后 PCM 数据的长度。
2.输出结果说明:
音频总时长:3.264 秒:表示输入的test.mp3音频时长是 3.264 秒;
音频PCM数据长度:104448 字节:表示将 MP3 转成 "16kHz、单声道、16 位深" 的 PCM 后,原始数据的总字节数(可验证:16000 采样率 ×3.264 秒 ×1 声道 ×2 字节 / 采样 = 16000×3.264×2 = 104448 字节,和输出一致);