引言:数据工程新范式"从ETL到ELT的平滑迁移实战指南"
在云原生、存算分离技术浪潮下,数据工程领域正经历一场从传统ETL到现代ELT的范式革命。曾经"抽取-转换-加载"的固化流程,已难以适配企业对数据实时性、灵活性的高要求;而ELT"抽取-加载-转换"的倒置逻辑,凭借其对海量数据的高效处理能力、更低的运维成本,成为越来越多企业的首选。
本文将从实战角度出发,拆解ETL到ELT的平滑迁移全流程,提供可直接复用的dbt+BigQuery技术方案与代码示例,帮助数据工程师快速落地迁移工作。


一、先搞懂:为什么必须从ETL迁移到ELT?
在动手迁移前,我们需要明确范式切换的核心价值------不是为了追逐潮流,而是解决传统ETL的核心痛点。
- 传统ETL的三大致命问题
-
灵活性缺失:转换逻辑固化在加载前,业务需求变更时需重新开发整个数据管道,响应周期长达数周;
-
扩展性不足:面对PB级海量数据时,本地计算资源成为瓶颈,横向扩展成本极高;
-
运维复杂度高:需维护抽取、转换两套独立集群,数据一致性校验依赖复杂的中间件,故障排查难度大。
- ELT的核心优势:适配云时代的数据需求
ELT将"转换"步骤后置到数据加载后,依托云数据仓库的强大计算能力完成转换,完美解决了ETL的痛点:
-
效率提升:数据直接加载至目标仓库,避免中间环节的数据传输损耗,加载速度提升5-10倍;
-
灵活迭代:转换逻辑与数据存储解耦,业务方可基于原始数据自主定义转换规则,响应需求时间缩短至1-2天;
-
成本优化:借助云服务的弹性伸缩能力,按需付费,计算与存储资源可精准匹配业务峰值,综合成本降低30%-50%。
核心差异对比可总结为下表:
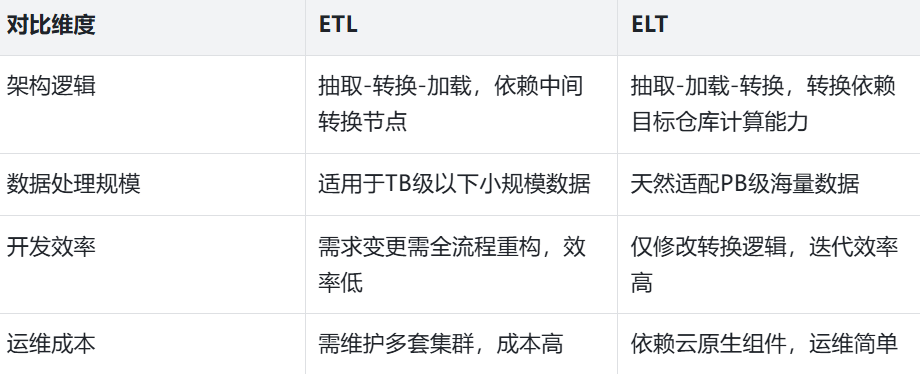
二、平滑迁移全流程:6个月落地路线图
迁移不是一蹴而就的"一刀切",而是分阶段、有节奏的平滑过渡。结合中型互联网公司的实践经验,我们设计了6个月的落地路线图,确保业务无感、数据一致。
第一阶段:调研规划与技术选型
核心目标:明确迁移范围、选定技术栈、完成PoC验证。
-
调研梳理:盘点现有ETL管道(数量、复杂度、核心业务依赖),划分优先级(非核心业务→核心业务);
-
技术选型:确定云原生技术栈,推荐组合:BigQuery(云数据仓库)+ dbt(转换工具)+ Airflow(调度工具)+ Great Expectations(数据质量监控);
-
PoC验证:选取1-2个非核心业务的简单数据管道,完成从ETL到ELT的迁移验证,测算性能与成本收益。
第二阶段:基础设施搭建与试点迁移
核心目标:搭建ELT基础设施,完成试点业务迁移。
-
基础设施搭建:部署dbt环境、配置BigQuery数据集权限、搭建Airflow调度集群、集成Great Expectations数据质量检查;
-
试点迁移:选择优先级最高的非核心业务,按"抽取→加载→转换"三步完成迁移,重点验证数据一致性(通过对比源数据与目标数据的字段值、统计指标);
-
文档沉淀:输出迁移规范、技术手册、运维流程,为大规模迁移做准备。
第三阶段:大规模迁移与全量切换
核心目标:完成核心业务迁移,全量切换至ELT模式。
-
大规模迁移:按业务优先级依次迁移核心业务数据管道,采用"并行运行→对比验证→逐步下线"的策略,避免业务中断;
-
性能优化:针对迁移后的管道,通过dbt的执行计划分析、BigQuery的分区表优化,提升转换效率;
-
全量切换:所有业务管道迁移完成后,下线旧ETL集群,正式切换至ELT模式,进入稳定运维阶段。
三、实战代码:基于dbt+BigQuery的ELT实现
下面以"用户行为日志分析"场景为例,提供完整的ELT代码实现,涵盖数据抽取、加载、转换、质量监控全环节。
- 前置准备:环境配置
首先完成dbt与BigQuery的集成配置,修改dbt项目的profiles.yml文件:
yaml
elt_demo:
target: dev
outputs:
dev:
type: bigquery
method: service-account
project: your-project-id
dataset: user_behavior_dev
keyfile: ./gcp-service-account.json
threads: 4
timeout_seconds: 300
location: asia-east2
priority: interactive- 数据抽取与加载:同步源数据至BigQuery
python
ELT的"抽取-加载"环节无需复杂的转换逻辑,直接将原始日志数据同步至BigQuery的原始数据表(staging层)。这里采用Airflow调度DataFusion完成数据同步,核心调度脚本如下:
from airflow import DAG
from airflow.providers.google.cloud.operators.datafusion import CloudDataFusionStartPipelineOperator
from datetime import datetime, timedelta
default_args = {
'owner': 'data_engineer',
'depends_on_past': False,
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=5)
}
with DAG(
'user_behavior_elt_extract_load',
default_args=default_args,
description='ELT抽取加载:用户行为日志同步至BigQuery',
schedule_interval=timedelta(hours=1),
start_date=datetime(2024, 1, 1),
catchup=False
) as dag:
start_pipeline = CloudDataFusionStartPipelineOperator(
task_id='start_datafusion_pipeline',
location='asia-east2',
pipeline_name='user_behavior_log_extract',
instance_name='datafusion-instance',
gcp_conn_id='google_cloud_default'
)
start_pipeline同步完成后,BigQuery中会生成原始数据表stg_user_behavior_log,包含用户ID、行为类型、访问时间、设备信息等原始字段。
- 数据转换:用dbt实现清洗与建模
转换是ELT的核心环节,借助dbt的SQL模型实现数据清洗、维度建模,生成可用于分析的目标表(warehouse层)。
(1)数据清洗模型:过滤无效数据
创建models/staging/stg_user_behavior_clean.sql,过滤空值、无效时间戳等脏数据:
sql
{{ config(materialized='view') }}
SELECT
user_id,
behavior_type,
visit_time,
device_id,
page_url,
ip_address
FROM {{ source('staging', 'stg_user_behavior_log') }}
-- 过滤无效数据
WHERE
user_id IS NOT NULL
AND visit_time > '2024-01-01 00:00:00'
AND behavior_type IN ('click', 'view', 'purchase', 'cancel')(2)维度建模:生成用户行为宽表
创建models/warehouse/dim_user_behavior.sql,关联用户维度表,生成分析用宽表:
yaml
{{ config(materialized='table', partition_by={'field': 'visit_date', 'data_type': 'date'}) }}
WITH user_behavior_clean AS (
SELECT * FROM {{ ref('stg_user_behavior_clean') }}
),
user_dim AS (
SELECT
user_id,
user_name,
user_level,
register_date
FROM {{ source('dim', 'dim_user') }}
)
SELECT
u.user_id,
u.user_name,
u.user_level,
u.register_date,
b.behavior_type,
b.visit_time,
DATE(b.visit_time) AS visit_date,
b.device_id,
b.page_url,
b.ip_address,
-- 新增行为类型描述
CASE
WHEN b.behavior_type = 'click' THEN '点击'
WHEN b.behavior_type = 'view' THEN '浏览'
WHEN b.behavior_type = 'purchase' THEN '购买'
WHEN b.behavior_type = 'cancel' THEN '取消'
END AS behavior_desc
FROM user_behavior_clean b
LEFT JOIN user_dim u ON b.user_id = u.user_id- 数据质量监控:用dbt测试保障数据可靠
在dbt中添加数据质量测试,确保转换后的数据符合业务规则。创建models/warehouse/schema.yml:
python
version: 2
models:
- name: dim_user_behavior
description: 用户行为分析宽表
columns:
- name: user_id
description: 用户唯一ID
tests:
- not_null
- unique
- name: visit_time
description: 访问时间
tests:
- not_null
- dbt_expectations.expect_column_values_to_be_between:
min_value: '2024-01-01 00:00:00'
max_value: current_timestamp()
- name: behavior_type
description: 行为类型
tests:
- accepted_values:
values: ['click', 'view', 'purchase', 'cancel']- 执行与调度:触发dbt任务
通过Airflow调度dbt任务,执行转换与测试,核心脚本如下:
python
from airflow import DAG
from airflow.providers.dbt.cloud.operators.dbt import DbtCloudRunJobOperator
from datetime import datetime, timedelta
default_args = {
'owner': 'data_engineer',
'depends_on_past': False,
'email_on_failure': True,
'email': ['data_engineer@example.com'],
'retries': 1,
'retry_delay': timedelta(minutes=5)
}
with DAG(
'user_behavior_elt_transform',
default_args=default_args,
description='ELT转换:dbt处理用户行为数据',
schedule_interval=timedelta(hours=1),
start_date=datetime(2024, 1, 1),
catchup=False
) as dag:
dbt_run = DbtCloudRunJobOperator(
task_id='dbt_run_transform',
dbt_cloud_conn_id='dbt_cloud_default',
job_id=12345, # 替换为你的dbt Cloud Job ID
check_interval=60,
timeout=3600,
)
dbt_test = DbtCloudRunJobOperator(
task_id='dbt_test_data_quality',
dbt_cloud_conn_id='dbt_cloud_default',
job_id=67890, # 替换为你的dbt测试Job ID
check_interval=60,
timeout=3600,
)
dbt_run >> dbt_test四、迁移风险与应对策略
迁移过程中难免遇到各类问题,提前识别风险并制定应对策略,是平滑迁移的关键。
- 数据一致性风险
问题:迁移过程中,新旧管道并行运行时数据结果不一致;
应对:建立数据校验机制,通过dbt测试、自定义SQL脚本对比新旧管道的输出结果,重点校验核心指标(如用户数、订单数),差异率需控制在0.1%以内。
- 团队技能转型风险
问题:原有团队熟悉ETL工具(如DataStage),对dbt、云数据仓库不熟悉;
应对:开展分层培训,先通过PoC项目让核心成员掌握技术栈,再通过内部分享、实战演练带动全员提升,同时可引入外部专家进行指导。
- 业务中断风险
问题:核心业务管道迁移过程中出现故障,导致数据分析中断;
应对:采用"并行运行→灰度切换→全量下线"策略,迁移后的管道先并行运行1-2周,验证稳定后再逐步替代旧管道,保留回滚机制,确保故障时可快速切换回旧方案。
五、总结与展望
从ETL到ELT的迁移,不仅是技术工具的替换,更是数据工程架构理念的升级------从"以转换为核心"转向"以数据为核心",让数据更灵活、更高效地支撑业务决策。
本文提供的6个月迁移路线图与dbt+BigQuery实战代码,已在中型互联网公司验证可行,数据工程师可根据企业实际场景调整细节。未来,随着数据湖仓一体化、数据网格技术的发展,ELT将进一步与这些技术融合,构建更开放、更敏捷的数据工程体系。
如果你在迁移过程中遇到具体问题,欢迎在评论区交流讨论!
✨ 坚持用 清晰的图解 +易懂的硬件架构 + 硬件解析, 让每个知识点都 简单明了 !
🚀 个人主页 :一只大侠的侠 · CSDN
💬 座右铭 : "所谓成功就是以自己的方式度过一生。"
