前提conda 环境和安装包都得安装好:
bash
conda create -n qwen310 python=3.10 -y
conda activate qwen310
pip install -U pip
# 临时使用清华源装通用包
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -U transformers accelerate sentencepiece tokenizers
# torch cu124 仍建议官方源(wheel 最全、最不容易缺包)
pip install torch==2.5.1+cu124 torchvision==0.20.1+cu124 torchaudio==2.5.1+cu124 --index-url https://download.pytorch.org/whl/cu124可能会报这个错误:
bash
ImportError: /opt/conda/envs/qwen310/lib/python3.10/site-packages/torch/lib/../../nvidia/cusparse/lib/libcusparse.so.12: undefined symbol: __nvJitLinkComplete_12_4, version libnvJitLink.so.12解决办法:
bash
conda activate qwen310
# 把 conda 的 lib 放最前面(先不要带系统 /usr/local/cuda)
export LD_LIBRARY_PATH="$CONDA_PREFIX/lib:$CONDA_PREFIX/nvidia/nvjitlink/lib:$CONDA_PREFIX/nvidia/cusparse/lib"
# 先验证 nvjitlink 能被加载(不导入 torch)
python -c "import ctypes; ctypes.CDLL('libnvJitLink.so.12'); print('nvjitlink OK')"首先需要安装的包有:
bash
pip install openai transformers datasets pandas peft modelscope swanlab(1)下载模型:Qwen3-4B-Thinking-2507 ----------链接:https://www.modelscope.cn/models/Qwen/Qwen3-4B-Thinking-2507
bash
from modelscope import snapshot_download
model_dir = snapshot_download('Qwen/Qwen3-4B-Thinking-2507', cache_dir='/24085404020/segment/fang/LLM/Qwen1', revision='master')(2) 下载数据集:添加链接描述(链接是:https://github.com/KMnO4-zx/huanhuan-chat/blob/master/dataset/train/lora/huanhuan.json
(3) LoRA SFT 微调脚本
bash
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
LoRA SFT 微调脚本(Transformers Trainer + PEFT + SwanLab 可选)
- 支持 JSON / JSONL 数据
- 自动构造 labels:prompt 部分为 -100,只训练 assistant 回复部分
"""
import os
import json
import torch
from typing import Dict, Any, List
from datasets import Dataset
from transformers import (
AutoTokenizer,
AutoModelForCausalLM,
Trainer,
TrainingArguments,
)
from peft import LoraConfig, TaskType, get_peft_model
# =========================
# 1) 配置:改这里
# =========================
model_path = "/24085404020/segment/fang/LLM/Qwen1/Qwen/Qwen3-4B-Thinking-2507"
data_path = "/24085404020/segment/fang/LLM/Qwen/huanhuan.json" # 支持 .json 或 .jsonl
max_len = 1024
# =========================
# 2) 读数据:同时支持 JSON / JSONL
# =========================
def load_data(path: str) -> List[Dict[str, Any]]:
"""
支持:
1) JSONL:每行一个 JSON
2) JSON:整体是一个 list/dict(常见为 list)
"""
with open(path, "r", encoding="utf-8-sig") as f:
content = f.read().strip()
if not content:
return []
# 先尝试整体 JSON 解析(.json 常见情况)
try:
obj = json.loads(content)
if isinstance(obj, list):
return obj
if isinstance(obj, dict):
# 兼容 {"data":[...]} 这类结构
if "data" in obj and isinstance(obj["data"], list):
return obj["data"]
return [obj]
except json.JSONDecodeError:
pass # 不是整体 JSON,就当 JSONL
# JSONL:逐行解析
rows = []
with open(path, "r", encoding="utf-8-sig") as f:
for line in f:
line = line.strip()
if not line:
continue
rows.append(json.loads(line))
return rows
# =========================
# 3) 规范化样本(适配常见字段)
# =========================
def normalize_example(ex: Dict[str, Any]) -> Dict[str, str]:
# 1) {"prompt": "...", "response": "..."}
if "prompt" in ex and "response" in ex:
return {"user": str(ex["prompt"]), "assistant": str(ex["response"])}
# 2) {"instruction": "...", "input": "...", "output": "..."}
if "instruction" in ex and "output" in ex:
user = str(ex["instruction"])
if ex.get("input"):
user = f"{user}\n{ex['input']}"
return {"user": user, "assistant": str(ex["output"])}
# 3) OpenAI messages 格式:{"messages":[{"role":"user","content":"..."},...]}
if "messages" in ex and isinstance(ex["messages"], list):
user_parts = []
assistant_parts = []
for m in ex["messages"]:
role = m.get("role")
content = m.get("content", "")
if role == "user":
user_parts.append(content)
elif role == "assistant":
assistant_parts.append(content)
if user_parts and assistant_parts:
return {"user": "\n".join(user_parts), "assistant": "\n".join(assistant_parts)}
# 4) 兜底:{"text":"..."}(不推荐)
if "text" in ex:
return {"user": str(ex["text"]), "assistant": ""}
raise ValueError(f"无法识别的数据格式字段:{list(ex.keys())}")
# =========================
# 4) 构建 SFT features(chat template + labels mask)
# =========================
def build_sft_features(
tokenizer,
user_text: str,
assistant_text: str,
system_prompt: str = None,
enable_thinking: bool = True,
max_len: int = 1024
) -> Dict[str, Any]:
messages_prompt = []
if system_prompt:
messages_prompt.append({"role": "system", "content": system_prompt})
messages_prompt.append({"role": "user", "content": user_text})
# 用于计算 prompt token 长度(包含 generation prompt)
prompt_text = tokenizer.apply_chat_template(
messages_prompt,
tokenize=False,
add_generation_prompt=True,
enable_thinking=enable_thinking
)
# 完整样本:加上 assistant 回复
messages_full = list(messages_prompt) + [{"role": "assistant", "content": assistant_text}]
full_text = tokenizer.apply_chat_template(
messages_full,
tokenize=False,
add_generation_prompt=False,
enable_thinking=enable_thinking
)
prompt_ids = tokenizer(prompt_text, add_special_tokens=False).input_ids
full_enc = tokenizer(full_text, add_special_tokens=False)
input_ids = full_enc["input_ids"][:max_len]
attention_mask = full_enc["attention_mask"][:max_len]
prompt_len = min(len(prompt_ids), len(input_ids))
labels = [-100] * prompt_len + input_ids[prompt_len:]
labels = labels[:max_len]
return {"input_ids": input_ids, "attention_mask": attention_mask, "labels": labels}
# =========================
# 5) Data Collator(padding + labels padding(-100))
# =========================
def collate_fn(features: List[Dict[str, Any]], pad_token_id: int):
max_len = max(len(f["input_ids"]) for f in features)
def pad_list(lst, pad_val):
return lst + [pad_val] * (max_len - len(lst))
return {
"input_ids": torch.tensor([pad_list(f["input_ids"], pad_token_id) for f in features], dtype=torch.long),
"attention_mask": torch.tensor([pad_list(f["attention_mask"], 0) for f in features], dtype=torch.long),
"labels": torch.tensor([pad_list(f["labels"], -100) for f in features], dtype=torch.long),
}
def main():
# ====== tokenizer ======
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
# ====== model ======
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map="auto",
torch_dtype=torch.bfloat16 if torch.cuda.is_available() else torch.float32,
trust_remote_code=True
)
# 省显存(建议开)
model.enable_input_require_grads()
model.gradient_checkpointing_enable()
# ====== LoRA ======
lora_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"],
inference_mode=False,
r=8,
lora_alpha=32,
lora_dropout=0.1
)
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()
# ====== dataset ======
if data_path and os.path.exists(data_path):
raw_data = load_data(data_path)
raw = [normalize_example(x) for x in raw_data]
if len(raw) == 0:
raise RuntimeError(f"数据文件为空:{data_path}")
else:
raw = [
{"user": "请把下面这句话改写成学术风格:transformer 很强。", "assistant": "Transformer 是一种在序列建模任务中表现优异的深度学习架构,具有较强的特征表达能力。"},
{"user": "用一句话解释什么是注意力机制?", "assistant": "注意力机制通过为不同输入分配可学习权重,使模型能够聚焦于对当前预测最重要的信息。"},
]
ds = Dataset.from_list(raw)
def preprocess(ex):
return build_sft_features(
tokenizer=tokenizer,
user_text=ex["user"],
assistant_text=ex["assistant"],
system_prompt=None,
enable_thinking=True,
max_len=max_len
)
tokenized_ds = ds.map(preprocess, remove_columns=ds.column_names)
# ====== TrainingArguments ======
bf16_ok = torch.cuda.is_available() and torch.cuda.get_device_capability(0)[0] >= 8
args = TrainingArguments(
output_dir="./qwen3-4b-lora-out",
per_device_train_batch_size=1,
gradient_accumulation_steps=8,
learning_rate=2e-4,
num_train_epochs=1,
logging_steps=10,
save_steps=200,
save_total_limit=2,
bf16=bool(bf16_ok),
fp16=bool(torch.cuda.is_available() and not bf16_ok),
report_to="none",
remove_unused_columns=False,
)
# ====== SwanLab(可选)======
callbacks = []
try:
import swanlab
from swanlab.integration.transformers import SwanLabCallback
sw_key = os.getenv("SWANLAB_API_KEY", "lLVDddAG7W4pSeHpKlXRxllf")
if sw_key:
swanlab.login(api_key=sw_key, save=False)
callbacks.append(SwanLabCallback(
project="Qwen3-4B-lora",
experiment_name="Qwen3-4B-experiment"
))
else:
print("[SwanLab] 未检测到环境变量 SWANLAB_API_KEY,跳过 SwanLab 上报。")
except Exception as e:
print(f"[SwanLab] 未启用(可忽略):{e}")
# ====== Trainer ======
trainer = Trainer(
model=model,
args=args,
train_dataset=tokenized_ds,
data_collator=lambda feats: collate_fn(feats, pad_token_id=tokenizer.pad_token_id),
callbacks=callbacks
)
trainer.train()
# 保存 LoRA adapter
trainer.save_model("./qwen3-4b-lora-adapter")
tokenizer.save_pretrained("./qwen3-4b-lora-adapter")
print("✅ 训练完成,已保存到 ./qwen3-4b-lora-adapter")
if __name__ == "__main__":
main()这个里面填自己的API(SWANLAB):https://swanlab.cn/space/~/settings
bash
sw_key = os.getenv("SWANLAB_API_KEY", "lLVDddAG7W4pSeHpKlXRx")
在运行的过程中可以用这个网址去查看:
https://swanlab.cn/@lanfang/Qwen3-4B-lora/runs/g9yjtauw3cz5a8r58t8tx/chart
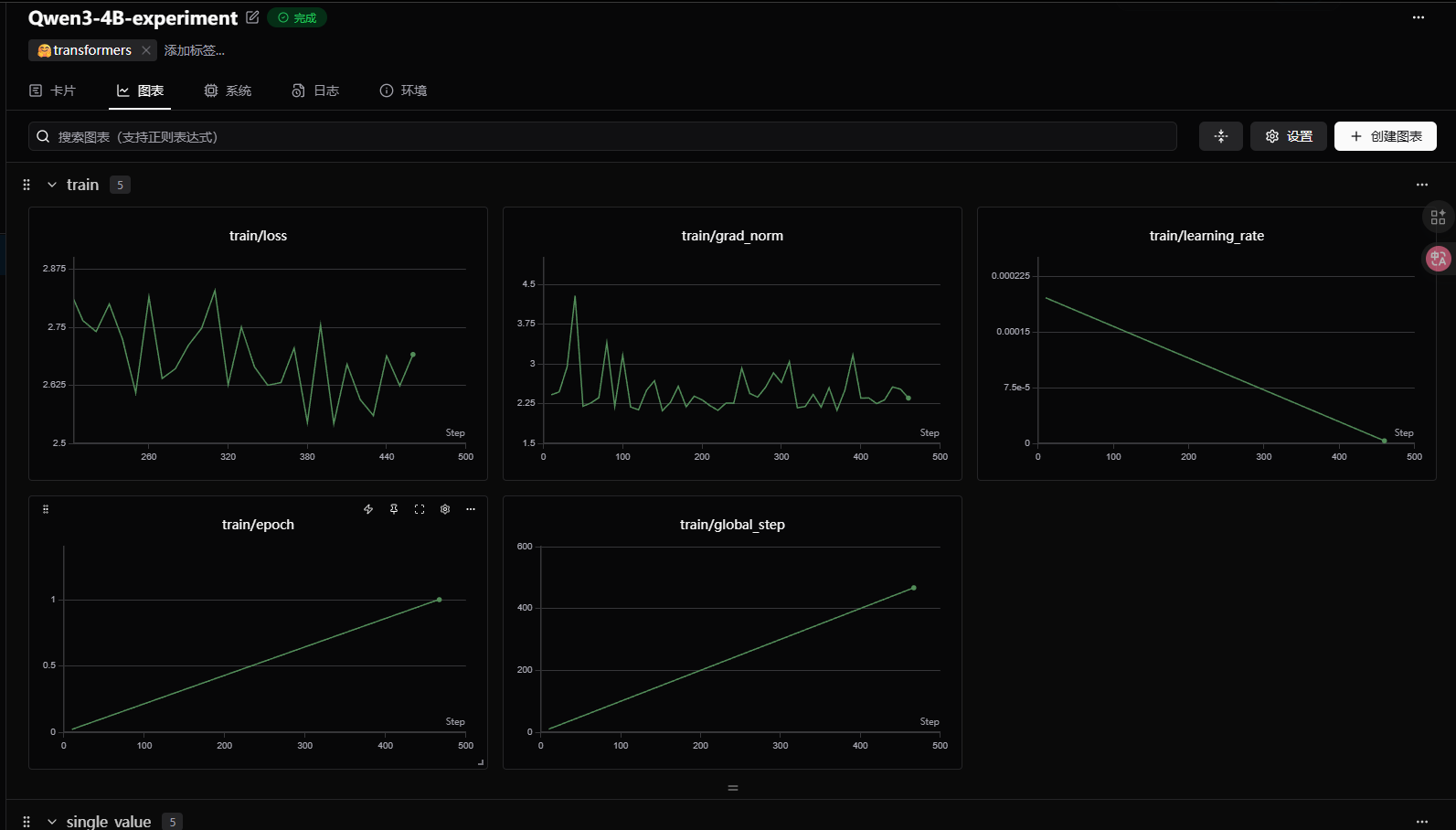
lora模型进行推理:
bash
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
from peft import PeftModel
model_path = '/24085404020/segment/fang/LLM/Qwen1/Qwen/Qwen3-4B-Thinking-2507' # 基座模型路径
lora_path = '/24085404020/segment/fang/LLM/Qwen/qwen3-4b-lora-out/checkpoint-467' # 这里改成你的 Lora 输出对应 checkpoint 地址
# 加载 tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_path)
# 加载模型
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map="auto",
torch_dtype=torch.bfloat16,
trust_remote_code=True
)
# 加载 LoRA 权重
model = PeftModel.from_pretrained(model, model_id=lora_path)
prompt = "你是谁?"
inputs = tokenizer.apply_chat_template(
[{"role": "user", "content": "假设你是智商身边的女人--靓依。"},
{"role": "user", "content": prompt}],
add_generation_prompt=True,
tokenize=True,
return_tensors="pt",
return_dict=True,
enable_thinking=False
)
inputs = inputs.to("cuda")
gen_kwargs = {"max_length": 2500, "do_sample": True, "top_k": 1}
with torch.no_grad():
outputs = model.generate(**inputs, **gen_kwargs)
outputs = outputs[:, inputs["input_ids"].shape[1]:]
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
参考的学习资料:
https://github.com/datawhalechina/llm-preview?tab=readme-ov-file