《博主简介》
小伙伴们好,我是阿旭。
专注于计算机视觉领域,包括目标检测、图像分类、图像分割和目标跟踪等项目开发,提供模型对比实验、答疑辅导等。
《------往期经典推荐------》
二、机器学习实战专栏【链接】 ,已更新31期,欢迎关注,持续更新中~~
三、深度学习【Pytorch】专栏【链接】
四、【Stable Diffusion绘画系列】专栏【链接】
五、YOLOv8改进专栏【链接】,持续更新中~~
六、YOLO性能对比专栏【链接】,持续更新中~
《------正文------》
目录
- 引言
- 一、为什么要让YOLO与SAM"联手"?
- 二、核心原理:YOLO与SAM的协同逻辑
- 三、实战:从零实现YOLO+SAM的目标检测与分割
-
- [1. 环境配置(关键依赖)](#1. 环境配置(关键依赖))
- [2. 模型准备](#2. 模型准备)
- [3. 核心代码实现](#3. 核心代码实现)
- [4. 关键参数说明](#4. 关键参数说明)
- 四、应用场景与效果提升建议
-
- [1. 典型应用场景](#1. 典型应用场景)
- [2. 效果优化技巧](#2. 效果优化技巧)
- 五、总结
引言
在计算机视觉领域,目标检测与图像分割是两大核心任务------前者负责定位图像中的目标,后者则精准勾勒目标轮廓。而YOLO(You Only Look Once)作为实时目标检测的标杆模型,与Meta提出的SAM(Segment Anything Model)图像分割神器的结合,更是让"检测+分割"流程效率翻倍。本文将带大家从零梳理两者的融合逻辑,使用YOLO进行目标检测,然后使用SAM对检测后的结果进行目标分割,帮你快速上手这一实用技术方案。

一、为什么要让YOLO与SAM"联手"?
YOLO模型以"实时性"和"高准确率"著称,能在毫秒级完成目标定位与类别识别,广泛应用于自动驾驶、监控安防等场景,但它缺乏精准的像素级分割能力;而SAM作为通用分割模型,凭借强大的迁移能力,能对任意目标进行精准分割,却需要明确的目标提示(如边界框、点)才能启动分割。
两者的融合恰好互补短板:用YOLO的检测结果作为SAM的目标提示,无需人工干预,就能自动完成"目标定位→像素级分割"的全流程,既保留了YOLO的高效性,又兼具了SAM的分割精度,大大降低了复杂场景下的应用门槛。
二、核心原理:YOLO与SAM的协同逻辑
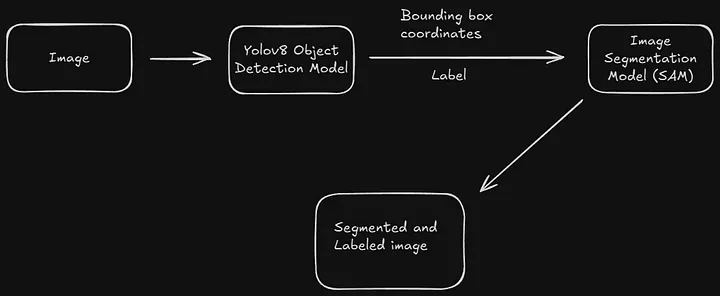
整个融合流程的核心的是"检测提示→分割执行"的闭环,具体逻辑如下:
- YOLO完成目标检测:输入图像后,YOLO模型快速输出目标的边界框(bounding box)、类别标签和置信度,明确"图像中有哪些目标,以及目标在哪里";
- 提取有效检测结果:过滤掉置信度低于阈值的低质量检测框,保留可靠的目标位置信息;
- SAM执行精准分割:将YOLO输出的边界框作为SAM的"目标提示",SAM基于该提示,对目标区域进行像素级分割,输出目标的掩码(mask);
- 结果融合输出:将YOLO的类别信息与SAM的掩码结果结合,最终输出"目标类别+位置+轮廓"的完整结果。
简单来说,YOLO负责"找目标",SAM负责"描轮廓",两者分工明确,协同高效。
三、实战:从零实现YOLO+SAM的目标检测与分割
1. 环境配置(关键依赖)
首先需搭建适配的Python环境,核心依赖如下(建议使用conda创建独立环境):
- Python 3.9+
- PyTorch 1.17+(需支持CUDA,提升推理速度)
- OpenCV(图像读取与预处理)
- Ultralytics
- segment-anything
- Matplotlib(结果可视化)
安装命令示例:
bash
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
pip install ultralytics opencv-python segment-anything matplotlib2. 模型准备
- YOLO模型:直接通过Ultralytics调用自己训练好的检测模型,或者直接使用官方预训练模型(如YOLOv8n、YOLOv8s,n版更轻量化,s版精度更高);
- SAM模型:从官方仓库下载预训练权重(推荐vit_h版,精度最优),需注意模型权重较大(约2.5GB),建议提前预留存储空间。
3. 核心代码实现
(1)导入依赖库
python
import cv2
import torch
import matplotlib.pyplot as plt
from ultralytics import YOLO
from segment_anything import sam_model_registry, SamPredictor(2)加载模型
python
# 加载YOLO预训练模型(以YOLOv8s为例)
yolo_model = YOLO('yolov8s.pt')
# 加载SAM模型(需指定权重路径)
sam_checkpoint = "sam_vit_h_4b8939.pth"
model_type = "vit_h"
device = "cuda" if torch.cuda.is_available() else "cpu"
sam_model = sam_model_registry[model_type](checkpoint=sam_checkpoint).to(device=device)
sam_predictor = SamPredictor(sam_model)(3)执行检测与分割
python
# 读取输入图像
image_path = "test_image.jpg"
image = cv2.imread(image_path)
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) # SAM需RGB格式
# 步骤1:YOLO目标检测
results = yolo_model(image_rgb, conf=0.5) # conf=0.5为置信度阈值
detections = results[0].boxes # 提取检测框信息(xyxy格式)
# 步骤2:处理检测框,转换为SAM所需格式
if detections is not None:
boxes = detections.xyxy.cpu().numpy() # 转为numpy数组
labels = detections.cls.cpu().numpy() # 目标类别标签
else:
print("未检测到目标!")
exit()
# 步骤3:SAM基于检测框分割
sam_predictor.set_image(image_rgb) # 初始化图像
masks, _, _ = sam_predictor.predict(
box=boxes[0], # 取第一个检测框(可循环处理多个目标)
multimask_output=False,
)(4)结果可视化
python
plt.figure(figsize=(12, 6))
# 原始图像
plt.subplot(1, 2, 1)
plt.imshow(image_rgb)
plt.title("原始图像")
plt.axis("off")
# 分割结果
plt.subplot(1, 2, 2)
plt.imshow(image_rgb)
plt.imshow(masks[0], alpha=0.5) # 叠加掩码,alpha控制透明度
plt.title("YOLO+SAM分割结果")
plt.axis("off")
plt.tight_layout()
plt.show()
4. 关键参数说明
conf=0.5:YOLO的置信度阈值,可根据需求调整(如提高到0.7减少误检);multimask_output=False:SAM是否输出多个候选掩码,False时直接输出最优结果;alpha=0.5:掩码叠加透明度,建议0.4-0.6,既能看清轮廓又不遮挡原图。
四、应用场景与效果提升建议
1. 典型应用场景
- 工业质检:检测并分割产品表面缺陷(如划痕、污渍);
- 自动驾驶:定位并分割行人、车辆、路标等目标;
- 医疗影像:辅助病灶检测与轮廓勾勒(需微调模型适配医疗数据);
- 智能安防:识别并分割监控画面中的可疑目标。
2. 效果优化技巧
- 若分割精度不足:更换SAM的vit_h权重,或微调YOLO模型适配特定数据集;
- 若速度较慢:改用YOLOv8n轻量化模型,或降低SAM的输入图像分辨率;
- 处理多目标:通过循环遍历YOLO输出的所有检测框,实现批量分割。
五、总结
YOLO与SAM的融合,完美解决了"快速检测"与"精准分割"的协同问题,无需复杂的模型训练,仅通过简单的代码调用就能实现高效的端到端解决方案。无论是计算机视觉新手入门,还是工程师落地实际项目,这套组合都值得一试。

好了,这篇文章就介绍到这里,喜欢的小伙伴感谢给点个赞和关注,更多精彩内容持续更新~~
关于本篇文章大家有任何建议或意见,欢迎在评论区留言交流!